9.循环神经网络
目录
-
序列模型
-
统计工具
-
自回归模型
-
马尔可夫模型
-
-
训练
-
预测
-
-
文本预处理
-
读取数据集
-
词元化
-
词表
-
整合所有功能
-
总结
-
-
语言模型和数据集
-
学习语言模型
-
马尔可夫模型与m元语法
-
自然语言统计
-
读取长序列数据
-
随机采样
-
顺序分区
-
-
总结
-
-
循环神经网络
-
无隐状态的神经网络
-
有隐状态的循环神经网络
-
基于循环神经网络的字符级语言模型
-
困惑度(Perplexity)
-
梯度剪裁
-
-
循环神经网络的从零开始实现
-
独热编码
-
初始化模型参数
-
循环神经网络模型
-
预测
-
梯度裁剪
-
训练
-
总结
-
-
循环神经网络的简洁实现
-
定义模型
-
训练与预测
-
序列模型
想象一下有人正在看网飞(Netflix,一个国外的视频网站)上的电影。 一名忠实的用户会对每一部电影都给出评价, 毕竟一部好电影需要更多的支持和认可。 然而事实证明,事情并不那么简单。 随着时间的推移,人们对电影的看法会发生很大的变化。 事实上,心理学家甚至对这些现象起了名字:
- 锚定(anchoring)效应:基于其他人的意见做出评价。 例如,奥斯卡颁奖后,受到关注的电影的评分会上升,尽管它还是原来那部电影。 这种影响将持续几个月,直到人们忘记了这部电影曾经获得的奖项。 结果表明( (Wu et al., 2017)),这种效应会使评分提高半个百分点以上。
- 享乐适应(hedonic adaption):人们迅速接受并且适应一种更好或者更坏的情况 作为新的常态。 例如,在看了很多好电影之后,人们会强烈期望下部电影会更好。 因此,在许多精彩的电影被看过之后,即使是一部普通的也可能被认为是糟糕的。
- 季节性(seasonality):少有观众喜欢在八月看圣诞老人的电影。
- 有时,电影会由于导演或演员在制作中的不当行为变得不受欢迎。
- 有些电影因为其极度糟糕只能成为小众电影。_Plan9from Outer Space_和_Troll2_就因为这个原因而臭名昭著的。
简而言之,电影评分决不是固定不变的。 因此,使用时间动力学可以得到更准确的电影推荐 (Koren, 2009)。 当然,序列数据不仅仅是关于电影评分的。 下面给出了更多的场景。
- 在使用程序时,许多用户都有很强的特定习惯。 例如,在学生放学后社交媒体应用更受欢迎。在市场开放时股市交易软件更常用。
- 预测明天的股价要比过去的股价更困难,尽管两者都只是估计一个数字。 毕竟,先见之明比事后诸葛亮难得多。 在统计学中,前者(对超出已知观测范围进行预测)称为_外推法_(extrapolation), 而后者(在现有观测值之间进行估计)称为_内插法_(interpolation)。
- 在本质上,音乐、语音、文本和视频都是连续的。 如果它们的序列被我们重排,那么就会失去原有的意义。 比如,一个文本标题“狗咬人”远没有“人咬狗”那么令人惊讶,尽管组成两句话的字完全相同。
- 地震具有很强的相关性,即大地震发生后,很可能会有几次小余震, 这些余震的强度比非大地震后的余震要大得多。 事实上,地震是时空相关的,即余震通常发生在很短的时间跨度和很近的距离内。
- 人类之间的互动也是连续的,这可以从微博上的争吵和辩论中看出。
统计工具
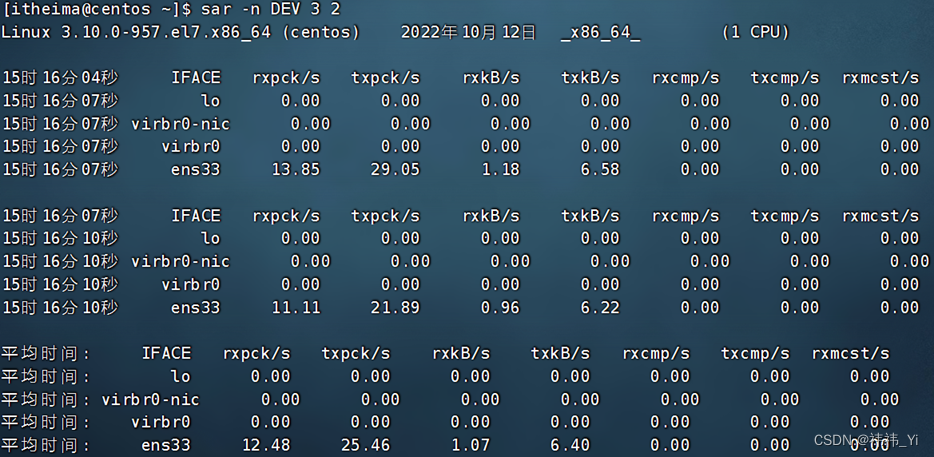
处理序列数据需要统计工具和新的深度神经网络架构。 为了简单起见,我们以图所示的股票价格(富时100指数)为例。

自回归模型
为了实现这个预测,交易员可以使用回归模型。仅有一个主要问题:输入数据的数量, 输入 x t − 1 , … , x 1 x_{t-1}, \ldots, x_1 xt−1,…,x1本身因 t t t而异。 也就是说,输入数据的数量这个数字将会随着我们遇到的数据量的增加而增加, 因此需要一个近似方法来使这个计算变得容易处理。 本章后面的大部分内容将围绕着如何有效估计$ P(x_t \mid x_{t-1}, \ldots, x_1) $展开。 简单地说,它归结为以下两种策略。
第一种策略,假设在现实情况下相当长的序列 x t − 1 , … , x 1 x_{t-1}, \ldots, x_1 xt−1,…,x1可能是不必要的, 因此我们只需要满足某个长度为 τ \tau τ的时间跨度, 即使用观测序列 x t − 1 , … , x t − τ x_{t-1}, \ldots, x_{t-\tau} xt−1,…,xt−τ。 当下获得的最直接的好处就是参数的数量总是不变的, 至少在 t > τ t > \tau t>τ时如此,这就使我们能够训练一个上面提及的深度网络。 这种模型被称为_自回归模型_(autoregressive models), 因为它们是对自己执行回归。

第二种策略,如图所示, 是保留一些对过去观测的总结 h t h_t ht, 并且同时更新预测 x ^ t \hat{x}_t x^t和总结 h t h_t ht。 这就产生了基于 x ^ t = P ( x t ∣ h t ) \hat{x}_{t}=P\left(x_{t} \mid h_{t}\right) x^t=P(xt∣ht) t ) {t}) t)估计 x t x_t xt, 以及公式 h t = g ( h t − 1 , x t − 1 ) h_t = g(h_{t-1}, x_{t-1}) ht=g(ht−1,xt−1)更新的模型。 由于 h t h_t ht从未被观测到,这类模型也被称为 隐变量自回归模型(latent autoregressive models)。


这两种情况都有一个显而易见的问题:如何生成训练数据? 一个经典方法是使用历史观测来预测下一个未来观测。 显然,我们并不指望时间会停滞不前。 然而,一个常见的假设是虽然特定值 x t x_t xt可能会改变, 但是序列本身的动力学不会改变。 这样的假设是合理的,因为新的动力学一定受新的数据影响, 而我们不可能用目前所掌握的数据来预测新的动力学。 统计学家称不变的动力学为静止的(stationary)。 因此,整个序列的估计值都将通过以下的方式获得:
P ( x 1 , … , x T ) = ∏ t = 1 T P ( x t ∣ x t − 1 , … , x 1 ) P\left(x_{1}, \ldots, x_{T}\right)=\prod_{t=1}^{T} P\left(x_{t} \mid x_{t-1}, \ldots, x_{1}\right) P(x1,…,xT)=t=1∏TP(xt∣xt−1,…,x1)
注意,如果我们处理的是离散的对象(如单词), 而不是连续的数字,则上述的考虑仍然有效。 唯一的差别是,对于离散的对象, 我们需要使用分类器而不是回归模型来估计 P ( x t ∣ x t − 1 , … , x 1 ) P(x_t \mid x_{t-1}, \ldots, x_1) P(xt∣xt−1,…,x1)。
马尔可夫模型

训练
在了解了上述统计工具后,让我们在实践中尝试一下! 首先,我们生成一些数据:使用正弦函数和一些可加性噪声来生成序列数据, 时间步为 1 , 2 , … , 1000 1, 2, \ldots, 1000 1,2,…,1000。
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
T = 1000 # 总共产生1000个点
time = torch.arange(1, T + 1, dtype=torch.float32)
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T,)) # 正弦函数和一些可加性噪声来生成序列数据x
d2l.plot(time, [x], 'time', 'x', xlim=[1, 1000], figsize=(6, 3))
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T9gaMFE9-1676882122662)(image/image_isaAt2OaA8.png)]
接下来,我们将这个序列转换为模型的特征-标签(feature-label)对。 基于嵌入维度 τ \tau τ,我们将数据映射为数据对 y t = x t y_t = x_t yt=xt和 x t = [ x t − τ , … , x t − 1 ] 。 \mathbf{x}_{t}=\left[x_{t-\tau}, \ldots, x_{t-1}\right]_{\text {。 }} xt=[xt−τ,…,xt−1]。 。 这比我们提供的数据样本少了 τ \tau τ个, 因为我们没有足够的历史记录来描述前 τ \tau τ个数据样本。 一个简单的解决办法是:如果拥有足够长的序列就丢弃这几项; 另一个方法是用零填充序列。 在这里,我们仅使用前600个“特征-标签”对进行训练。
tau = 4
features = torch.zeros((T - tau, tau))# T - tau为样本数,tau为特征数,维数为(996,4)
for i in range(tau):
features[:, i] = x[i: T - tau + i]
labels = x[tau:].reshape((-1, 1)) # 维数为(996,1)
batch_size, n_train = 16, 600 # 批量大小和训练样本数
# 只有前n_train个样本用于训练
train_iter = d2l.load_array((features[:n_train], labels[:n_train]),
batch_size, is_train=True)
这段代码是用于生成训练数据的,其中:
- 定义了变量
tau和features。tau的值为 4,而features是一个二维的张量,其行数为T - tau,列数为tau。 - 使用了一个循环,以此生成
features矩阵中的每一行。每一行的数据都是从x数组中取得的,列数从第 i i i 个元素取到第 T − t a u + i T - tau + i T−tau+i 个元素。 - 变量
labels是从x数组中取得的,起始元素为第 t a u tau tau 个,是一个二维的张量,其行数由x[tau:]的形状决定,而列数为 1。 - 变量
batch_size和n_train分别为批量大小和训练样本数。 - 变量
train_iter使用d2l.load_array函数生成训练数据迭代器,该迭代器将前n_train个样本按批量大小分组并生成训练数据。
在这里,我们使用一个相当简单的架构训练模型: 一个拥有两个全连接层的多层感知机,ReLU激活函数和平方损失。
# 初始化网络权重的函数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
# 一个简单的多层感知机
def get_net():
net = nn.Sequential(nn.Linear(4, 10),
nn.ReLU(),
nn.Linear(10, 1))
net.apply(init_weights)
return net
# 平方损失。注意:MSELoss计算平方误差时不带系数1/2
loss = nn.MSELoss(reduction='none')
现在,准备训练模型了。
def train(net, train_iter, loss, epochs, lr):
trainer = torch.optim.Adam(net.parameters(), lr)
for epoch in range(epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.sum().backward()
trainer.step()
print(f'epoch {epoch + 1}, '
f'loss: {d2l.evaluate_loss(net, train_iter, loss):f}')
net = get_net()
train(net, train_iter, loss, 5, 0.01)
这段代码定义了一个训练函数 train ,该函数的输入有:
net:网络模型train_iter:训练数据的迭代器loss:用于计算损失函数的对象epochs:训练的轮数lr:学习率
在训练函数内部,定义了一个优化器 trainer ,其使用 PyTorch 库的 Adam 算法来优化网络模型的参数。
在训练的过程中,通过迭代轮数来控制循环,每一轮迭代都需要迭代训练数据,在每一次训练中:
- 使用优化器的
zero_grad函数清空网络模型的梯度信息 - 使用网络模型对当前的训练数据进行预测,并计算预测结果与真实结果的误差
- 计算误差的梯度,并使用
backward函数进行反向传播 - 使用优化器的
step函数来更新网络模型的参数
最后,在每一轮迭代结束后,使用 d2l.evaluate_loss 函数计算训练集上的误差,并打印出每一轮的误差值。
epoch 1, loss: 0.063133
epoch 2, loss: 0.053832
epoch 3, loss: 0.051174
epoch 4, loss: 0.050547
epoch 5, loss: 0.047369
预测
由于训练损失很小,因此我们期望模型能有很好的工作效果。 让我们看看这在实践中意味着什么。 首先是检查模型预测下一个时间步的能力, 也就是单步预测(one-step-ahead prediction)。
onestep_preds = net(features)
d2l.plot([time, time[tau:]],
[x.detach().numpy(), onestep_preds.detach().numpy()], 'time',
'x', legend=['data', '1-step preds'], xlim=[1, 1000],
figsize=(6, 3))

正如我们所料,单步预测效果不错。 即使这些预测的时间步超过了600+4(n_train + tau), 其结果看起来仍然是可信的。 然而有一个小问题:如果数据观察序列的时间步只到604, 我们需要一步一步地向前迈进:
x ^ 605 = f ( x 601 , x 602 , x 603 , x 604 ) , x ^ 606 = f ( x 602 , x 603 , x 604 , x ^ 605 ) , x ^ 607 = f ( x 603 , x 604 , x ^ 605 , x ^ 606 ) , x ^ 608 = f ( x 604 , x ^ 605 , x ^ 606 , x ^ 607 ) , x ^ 609 = f ( x ^ 605 , x ^ 606 , x ^ 607 , x ^ 608 ) , \begin{array}{l}\hat{x}_{605}=f\left(x_{601}, x_{602}, x_{603}, x_{604}\right), \\ \hat{x}_{606}=f\left(x_{602}, x_{603}, x_{604}, \hat{x}_{605}\right), \\ \hat{x}_{607}=f\left(x_{603}, x_{604}, \hat{x}_{605}, \hat{x}_{606}\right), \\ \hat{x}_{608}=f\left(x_{604}, \hat{x}_{605}, \hat{x}_{606}, \hat{x}_{607}\right), \\ \hat{x}_{609}=f\left(\hat{x}_{605}, \hat{x}_{606}, \hat{x}_{607}, \hat{x}_{608}\right),\end{array} x^605=f(x601,x602,x603,x604),x^606=f(x602,x603,x604,x^605),x^607=f(x603,x604,x^605,x^606),x^608=f(x604,x^605,x^606,x^607),x^609=f(x^605,x^606,x^607,x^608),
通常,对于直到 x t x_t xt的观测序列,其在时间步 t + k t+k t+k处的预测输出 x ^ t + k \hat{x}_{t+k} x^t+k** 称为** k k k步预测( k k k-step-ahead-prediction)。 由于我们的观察已经到了 x 604 x_{604} x604,它的 k k k步预测是 x ^ 604 + k \hat{x}_{604+k} x^604+k。 换句话说,我们必须使用我们自己的预测(而不是原始数据)来进行多步预测。 让我们看看效果如何。
multistep_preds = torch.zeros(T)
multistep_preds[: n_train + tau] = x[: n_train + tau]
for i in range(n_train + tau, T):
multistep_preds[i] = net(
multistep_preds[i - tau:i].reshape((1, -1)))
d2l.plot([time, time[tau:], time[n_train + tau:]],
[x.detach().numpy(), onestep_preds.detach().numpy(),
multistep_preds[n_train + tau:].detach().numpy()], 'time',
'x', legend=['data', '1-step preds', 'multistep preds'],
xlim=[1, 1000], figsize=(6, 3))

如上面的例子所示,绿线的预测显然并不理想。 经过几个预测步骤之后,预测的结果很快就会衰减到一个常数。 为什么这个算法效果这么差呢?事实是由于错误的累积: 假设在步骤1之后,我们积累了一些错误 ϵ 1 = ϵ ˉ \epsilon_1 = \bar\epsilon ϵ1=ϵˉ。 于是,步骤2的输入被扰动了 ϵ 1 \epsilon_1 ϵ1, 结果积累的误差是依照次序的 ϵ 2 = ϵ ˉ + c ϵ 1 \epsilon_2 = \bar\epsilon + c \epsilon_1 ϵ2=ϵˉ+cϵ1, 其中 c c c为某个常数,后面的预测误差依此类推。 因此误差可能会相当快地偏离真实的观测结果。 例如,未来24小时的天气预报往往相当准确, 但超过这一点,精度就会迅速下降。 我们将在本章及后续章节中讨论如何改进这一点。
基于 k = 1 , 4 , 16 , 64 k = 1, 4, 16, 64 k=1,4,16,64,通过对整个序列预测的计算, 让我们更仔细地看一下 k k k步预测的困难。
max_steps = 64
features = torch.zeros((T - tau - max_steps + 1, tau + max_steps))
# 列i(i<tau)是来自x的观测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau):
features[:, i] = x[i: i + T - tau - max_steps + 1]
# 列i(i>=tau)是来自(i-tau+1)步的预测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau, tau + max_steps):
features[:, i] = net(features[:, i - tau:i]).reshape(-1)
steps = (1, 4, 16, 64)
d2l.plot([time[tau + i - 1: T - max_steps + i] for i in steps],
[features[:, tau + i - 1].detach().numpy() for i in steps], 'time', 'x',
legend=[f'{i}-step preds' for i in steps], xlim=[5, 1000],
figsize=(6, 3))

以上例子清楚地说明了当我们试图预测更远的未来时,预测的质量是如何变化的。 虽然“4步预测”看起来仍然不错,但超过这个跨度的任何预测几乎都是无用的。
文本预处理
对于序列数据处理问题,我们在上节中 评估了所需的统计工具和预测时面临的挑战。 这样的数据存在许多种形式,文本是最常见例子之一。 例如,一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 本节中,我们将解析文本的常见预处理步骤。
这些步骤通常包括:
- 将文本作为字符串加载到内存中。
- 将字符串拆分为词元(如单词和字符)。
- 建立一个词表,将拆分的词元映射到数字索引。
- 将文本转换为数字索引序列,方便模型操作。
import collections
import re
from d2l import torch as d2l
读取数据集
首先,我们从H.G.Well的时光机器中加载文本。 这是一个相当小的语料库,只有30000多个单词,但足够我们小试牛刀, 而现实中的文档集合可能会包含数十亿个单词。 下面的函数将数据集读取到由多条文本行组成的列表中,其中每条文本行都是一个字符串。 为简单起见,我们在这里忽略了标点符号和字母大写。
#@save
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine(): #@save
"""将时间机器数据集加载到文本行的列表中"""
with open(d2l.download('time_machine'), 'r') as f:
lines = f.readlines()
# 使用正则表达式re.sub来清除每一行中除了字母以外的字符,并将所有字符全部转换为小写
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
lines = read_time_machine()
print(f'# 文本总行数: {len(lines)}')
print(lines[0])
print(lines[10])
这行代码中,re.sub('[^A-Za-z]+', ' ', line) 使用正则表达式替换文本行中的除了大写字母和小写字母以外的所有字符,用空格代替。 strip() 去掉字符串开头和结尾的空格,lower() 把文本行转换成小写。这个方法比较暴力
📌可以使用Python的字符串处理函数,例如replace和translate,来替换或删除不需要的字符。如下面的代码:
import string lines = [line.translate(str.maketrans("", "", string.punctuation)).strip().lower() for line in lines]这将删除所有的标点符号,并将每行文本转换为小写形式。
Downloading ../data/timemachine.txt from http://d2l-data.s3-accelerate.amazonaws.com/timemachine.txt...
# 文本总行数: 3221
the time machine by h g wells
twinkled and his usually pale face was flushed and animated the
词元化
下面的tokenize函数将文本行列表(lines)作为输入, 列表中的每个元素是一个文本序列(如一条文本行)。 每个文本序列又被拆分成一个词元列表,词元**(token)是文本的基本单位**。 最后,返回一个由词元列表组成的列表,其中的每个词元都是一个字符串(string)。
def tokenize(lines, token='word'): #@save
"""将文本行拆分为单词或字符词元"""
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:' + token)
tokens = tokenize(lines)
for i in range(11):
print(tokens[i])
['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
[]
[]
[]
[]
['i']
[]
[]
['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him']
['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and']
['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']
这段代码的意思是对文本进行分词处理,把每一行文本拆分为单词。默认分词类型为“word”,即将每一行文本按空格分开,把每一个单词作为一个词元。如果词元类型为“char”,则把每一行文本中的每一个字符作为一个词元。
词表
词元的类型是字符串,而模型需要的输入是数字,因此这种类型不方便模型使用。 现在,让我们构建一个字典,通常也叫做词表(vocabulary), 用来将字符串类型的词元映射到从0开始的数字索引中。
我们先将训练集中的所有文档合并在一起,对它们的唯一词元进行统计, 得到的统计结果称之为语料(corpus)。 然后根据每个唯一词元的出现频率,为其分配一个数字索引。 很少出现的词元通常被移除,这可以降低复杂性。 另外,语料库中不存在或已删除的任何词元都将映射到一个特定的未知词元“<unk>”。
我们可以选择增加一个列表,用于保存那些被保留的词元, 例如:填充词元(“<pad>”); 序列开始词元(“<bos>”); 序列结束词元(“<eos>”)。
class Vocab: #@save
"""文本词表"""
# 将文本单词映射为整数索引。它通过token_to_idx和idx_to_token两个字典实现了这一功能。
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None): # min_freq最低频率
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
'''初始化了三个成员变量:idx_to_token, token_to_idx, _token_freqs'''
# 按出现频率排序
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1], reverse=True)
# 将编号为0的词元置为未知词元,并将预留词元作为下一个词元的编号。预留词元可以是任意的字符串列表,如开头或结尾的标记等。
self.idx_to_token = ['<unk>'] + reserved_tokens # 根据词元索引,索引对应的词元。
# 根据词元,词元对应的索引。
self.token_to_idx = {token: idx for idx, token in enumerate(self.idx_to_token)}
''' 构建词典的索引。首先对于所有的词元,按照词频从高到低排序。对于每一个词元,
如果它的词频小于 min_freq 则退出循环。如果词元还不存在词典中,则加入词典。
最后,更新词元到索引的映射 self.token_to_idx 和索引到词元的映射 self.idx_to_token。'''
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
# 返回词表中词元的数量
def __len__(self):
return len(self.idx_to_token)
'''首先检查传入的参数tokens是否是列表或元组类型,如果是则进行循环,把每一个token都调用__getitem__方法转换成编号,
最后返回转换后的编号列表。如果传入的参数不是列表或元组,则说明是一个词元,直接通过字典self.token_to_idx获取该词元对应的编号。
如果该词元不在字典中,则返回self.unk。'''
# 返回词元在词表中的索引,如果词元不在词表中,则返回未知词元的索引
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # 未知词元的索引为0
return 0
@property
def token_freqs(self):
return self._token_freqs
def count_corpus(tokens): #@save
"""统计词元的频率"""
# 这里的tokens是1D列表或2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 将词元列表展平成一个列表
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
这段代码定义了一个count_corpus函数,用于统计词元的频率。
它的参数tokens是一个词元的列表,可能是一维列表,也可能是二维列表。
首先,通过if len(tokens) == 0 or isinstance(tokens[0], list):语句判断tokens是否是二维列表,如果是二维列表,则将词元列表展平成一个列表。
isinstance(tokens[0], list)是一个判断语句,用于判断变量 tokens[0] 是否是列表类型。如果是,则说明 tokens 是一个二维列表;否则,则说明 tokens 是一个一维列表。
然后,使用Python标准库中的collections模块中的Counter函数对tokens中的词元进行统计,返回一个字典,键为词元,值为词元的出现次数。
例如,假设输入的tokens为:['dog', 'cat', 'dog', 'dog', 'bird', 'cat'],则调用count_corpus函数后的返回结果为:{'dog': 3, 'cat': 2, 'bird': 1}。
我们首先使用时光机器数据集作为语料库来构建词表,然后打印前几个高频词元及其索引。
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[:10])
[('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4), ('a', 5), ('to', 6), ('was', 7), ('in', 8), ('that', 9)]
现在,我们可以将每一条文本行转换成一个数字索引列表。
for i in [0, 10]:
print('文本:', tokens[i])
print('索引:', vocab[tokens[i]])
文本: ['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
索引: [1, 19, 50, 40, 2183, 2184, 400]
文本: ['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']
索引: [2186, 3, 25, 1044, 362, 113, 7, 1421, 3, 1045, 1]
整合所有功能
在使用上述函数时,我们将所有功能打包到load_corpus_time_machine函数中, 该函数返回corpus(词元索引列表)和vocab(时光机器语料库的词表)。 我们在这里所做的改变是:
- 为了简化后面章节中的训练,我们使用字符(而不是单词)实现文本词元化;
- 时光机器数据集中的每个文本行不一定是一个句子或一个段落,还可能是一个单词,因此返回的
corpus仅处理为单个列表,而不是使用多词元列表构成的一个列表。
def load_corpus_time_machine(max_tokens=-1): #@save
"""返回时光机器数据集的词元索引列表和词表"""
lines = read_time_machine()
tokens = tokenize(lines, 'char')
vocab = Vocab(tokens)
# 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落,
# 所以将所有文本行展平到一个列表中
corpus = [vocab[token] for line in tokens for token in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus, vocab
corpus, vocab = load_corpus_time_machine()
len(corpus), len(vocab)
这段代码定义了一个函数load_corpus_time_machine,该函数的作用是读取时光机器数据集并返回词元索引列表和词表。
首先,使用read_time_machine函数读取时光机器数据集中的每一行文本,然后使用tokenize函数将每一行文本分割成字符级别的词元。然后创建一个Vocab对象,并使用该对象将词元转换为索引。
接着,创建一个列表corpus,其中包含所有词元的索引,并将其展平到一个列表中。如果max_tokens大于0,那么只保留语料中的前max_tokens个词元。最后,返回词元索引列表corpus和词表vocab。
最后,调用函数load_corpus_time_machine,并将返回的结果赋值给corpus和vocab,最后计算并输出词元索引列表和词表的长度。
(170580, 28)
总结
- 文本是序列数据的一种最常见的形式之一。
- 为了对文本进行预处理,我们通常将文本拆分为词元,构建词表将词元字符串映射为数字索引,并将文本数据转换为词元索引以供模型操作
语言模型和数据集
在 上节中, 我们了解了如何将文本数据映射为词元, 以及将这些词元可以视为一系列离散的观测,例如单词或字符。 假设长度为 T T T的文本序列中的词元依次为 x 1 , x 2 , … , x T x_1, x_2, \ldots, x_T x1,x2,…,xT。 于是, x t x_t xt$ 1 \leq t \leq T ∗ ∗ 可以被认为是文本序列在时间步 ∗ ∗ **可以被认为是文本序列在时间步** ∗∗可以被认为是文本序列在时间步∗∗t$处的观测或标签。 在给定这样的文本序列时,语言模型**(language model)的目标是估计序列的联合概率**
P ( x 1 , x 2 , … , x T ) . P(x_1, x_2, \ldots, x_T). P(x1,x2,…,xT).
例如,只需要一次抽取一个词元 x t ∼ P ( x t ∣ x t − 1 , … , x 1 ) x_t \sim P(x_t \mid x_{t-1}, \ldots, x_1) xt∼P(xt∣xt−1,…,x1), 一个理想的语言模型就能够基于模型本身生成自然文本。 与猴子使用打字机完全不同的是,从这样的模型中提取的文本 都将作为自然语言(例如,英语文本)来传递。 只需要基于前面的对话片断中的文本, 就足以生成一个有意义的对话。 显然,我们离设计出这样的系统还很遥远, 因为它需要“理解”文本,而不仅仅是生成语法合理的内容。
尽管如此,语言模型依然是非常有用的。 例如,短语“to recognize speech”和“to wreck a nice beach”读音上听起来非常相似。 这种相似性会导致语音识别中的歧义,但是这很容易通过语言模型来解决, 因为第二句的语义很奇怪。 同样,在文档摘要生成算法中, “狗咬人”比“人咬狗”出现的频率要高得多。
学习语言模型
显而易见,我们面对的问题是如何对一个文档, 甚至是一个词元序列进行建模。 假设在单词级别对文本数据进行词元化, 我们可以依靠对序列模型的分析。 让我们从基本概率规则开始:
P ( x 1 , x 2 , … , x T ) = ∏ t = 1 T P ( x t ∣ x 1 , … , x t − 1 ) . P(x_1, x_2, \ldots, x_T) = \prod_{t=1}^T P(x_t \mid x_1, \ldots, x_{t-1}). P(x1,x2,…,xT)=t=1∏TP(xt∣x1,…,xt−1).
例如,包含了四个单词的一个文本序列的概率是:
P ( deep , learning , is , fun ) = P ( deep ) P ( learning ∣ deep ) P ( is ∣ deep , learning ) P ( fun ∣ deep , learning , is ) . P(\text{deep}, \text{learning}, \text{is}, \text{fun}) = P(\text{deep}) P(\text{learning} \mid \text{deep}) P(\text{is} \mid \text{deep}, \text{learning}) P(\text{fun} \mid \text{deep}, \text{learning}, \text{is}). P(deep,learning,is,fun)=P(deep)P(learning∣deep)P(is∣deep,learning)P(fun∣deep,learning,is).
为了训练语言模型,我们需要计算单词的概率, 以及给定前面几个单词后出现某个单词的条件概率。 这些概率本质上就是语言模型的参数。
这里,我们假设训练数据集是一个大型的文本语料库。 比如,维基百科的所有条目、 古登堡计划, 或者所有发布在网络上的文本。 训练数据集中词的概率可以根据给定词的相对词频来计算。 例如,可以将估计值 P ^ ( deep ) \hat{P}(\text{deep}) P^(deep)计算为任何以单词“deep”开头的句子的概率。 一种(稍稍不太精确的)方法是统计单词“deep”在数据集中的出现次数, 然后将其除以整个语料库中的单词总数。 这种方法效果不错,特别是对于频繁出现的单词。 接下来,我们可以尝试估计
P ^ ( learning ∣ deep ) = n ( deep, learning ) n ( deep ) , \hat{P}(\text{learning} \mid \text{deep}) = \frac{n(\text{deep, learning})}{n(\text{deep})}, P^(learning∣deep)=n(deep)n(deep, learning),
其中 n ( x ) n(x) n(x)和 n ( x , x ′ ) n(x, x') n(x,x′)分别是单个单词和连续单词对的出现次数。 不幸的是,由于连续单词对“deep learning”的出现频率要低得多, 所以估计这类单词正确的概率要困难得多。 特别是对于一些不常见的单词组合,要想找到足够的出现次数来获得准确的估计可能都不容易。 而对于三个或者更多的单词组合,情况会变得更糟。 许多合理的三个单词组合可能是存在的,但是在数据集中却找不到。 除非我们提供某种解决方案,来将这些单词组合指定为非零计数, 否则将无法在语言模型中使用它们。 如果数据集很小,或者单词非常罕见,那么这类单词出现一次的机会可能都找不到。
一种常见的策略是执行某种形式的拉普拉斯平滑(Laplace smoothing), 具体方法是在所有计数中添加一个小常量。 用 n n n表示训练集中的单词总数,用 m m m表示唯一单词的数量。 此解决方案有助于处理单元素问题,例如通过:
P ^ ( x ) = n ( x ) + ϵ 1 / m n + ϵ 1 , P ^ ( x ′ ∣ x ) = n ( x , x ′ ) + ϵ 2 P ^ ( x ′ ) n ( x ) + ϵ 2 , P ^ ( x ′ ′ ∣ x , x ′ ) = n ( x , x ′ , x ′ ′ ) + ϵ 3 P ^ ( x ′ ′ ) n ( x , x ′ ) + ϵ 3 . \begin{aligned} \hat{P}(x) & =\frac{n(x)+\epsilon_{1} / m}{n+\epsilon_{1}}, \\ \hat{P}\left(x^{\prime} \mid x\right) & =\frac{n\left(x, x^{\prime}\right)+\epsilon_{2} \hat{P}\left(x^{\prime}\right)}{n(x)+\epsilon_{2}}, \\ \hat{P}\left(x^{\prime \prime} \mid x, x^{\prime}\right) & =\frac{n\left(x, x^{\prime}, x^{\prime \prime}\right)+\epsilon_{3} \hat{P}\left(x^{\prime \prime}\right)}{n\left(x, x^{\prime}\right)+\epsilon_{3}} .\end{aligned} P^(x)P^(x′∣x)P^(x′′∣x,x′)=n+ϵ1n(x)+ϵ1/m,=n(x)+ϵ2n(x,x′)+ϵ2P^(x′),=n(x,x′)+ϵ3n(x,x′,x′′)+ϵ3P^(x′′).
其中, ϵ 1 , ϵ 2 \epsilon_1,\epsilon_2 ϵ1,ϵ2和 ϵ 3 \epsilon_3 ϵ3是超参数。 以 ϵ 1 \epsilon_1 ϵ1为例:当 ϵ 1 = 0 \epsilon_1 = 0 ϵ1=0时,不应用平滑; 当 ϵ 1 \epsilon_1 ϵ1接近正无穷大时, P ^ ( x ) \hat{P}(x) P^(x)接近均匀概率分布 1 / m 1/m 1/m。 上面的公式是 (Wood et al., 2011) 的一个相当原始的变形。
然而,这样的模型很容易变得无效,原因如下: 首先,我们需要存储所有的计数; 其次,这完全忽略了单词的意思。 例如,“猫”(cat)和“猫科动物”(feline)可能出现在相关的上下文中, 但是想根据上下文调整这类模型其实是相当困难的。 最后,长单词序列大部分是没出现过的, 因此一个模型如果只是简单地统计先前“看到”的单词序列频率, 那么模型面对这种问题肯定是表现不佳的。
马尔可夫模型与m元语法
在讨论包含深度学习的解决方案之前,我们需要了解更多的概念和术语。 回想一下我们对马尔可夫模型的讨论, 并且将其应用于语言建模。 如果 P ( x t + 1 ∣ x t , … , x 1 ) = P ( x t + 1 ∣ x t ) P(x_{t+1} \mid x_t, \ldots, x_1) = P(x_{t+1} \mid x_t) P(xt+1∣xt,…,x1)=P(xt+1∣xt), 则序列上的分布满足一阶马尔可夫性质。 阶数越高,对应的依赖关系就越长。 这种性质推导出了许多可以应用于序列建模的近似公式:
P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 2 ) P ( x 4 ∣ x 3 ) P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 1 , x 2 ) P ( x 4 ∣ x 2 , x 3 ) . \begin{array}{l}P\left(x_{1}, x_{2}, x_{3}, x_{4}\right)=P\left(x_{1}\right) P\left(x_{2}\right) P\left(x_{3}\right) P\left(x_{4}\right) \\ P\left(x_{1}, x_{2}, x_{3}, x_{4}\right)=P\left(x_{1}\right) P\left(x_{2} \mid x_{1}\right) P\left(x_{3} \mid x_{2}\right) P\left(x_{4} \mid x_{3}\right) \\ P\left(x_{1}, x_{2}, x_{3}, x_{4}\right)=P\left(x_{1}\right) P\left(x_{2} \mid x_{1}\right) P\left(x_{3} \mid x_{1}, x_{2}\right) P\left(x_{4} \mid x_{2}, x_{3}\right) .\end{array} P(x1,x2,x3,x4)=P(x1)P(x2)P(x3)P(x4)P(x1,x2,x3,x4)=P(x1)P(x2∣x1)P(x3∣x2)P(x4∣x3)P(x1,x2,x3,x4)=P(x1)P(x2∣x1)P(x3∣x1,x2)P(x4∣x2,x3).
通常,涉及一个、两个和三个变量的概率公式分别被称为 一元语法(unigram)、二元语法(bigram)和_三元语法_(trigram)模型。 下面,我们将学习如何去设计更好的模型。
自然语言统计
我们看看在真实数据上如果进行自然语言统计。 根据时光机器数据集构建词表, 并打印前10个最常用的(频率最高的)单词。
import random
import torch
from d2l import torch as d2l
tokens = d2l.tokenize(d2l.read_time_machine())
# 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus)
vocab.token_freqs[:10] # 打印前10个最常用的(频率最高的)单词
[('the', 2261),
('i', 1267),
('and', 1245),
('of', 1155),
('a', 816),
('to', 695),
('was', 552),
('in', 541),
('that', 443),
('my', 440)]
正如我们所看到的,最流行的词看起来很无聊, 这些词通常被称为停用词(stop words),因此可以被过滤掉。 尽管如此,它们本身仍然是有意义的,我们仍然会在模型中使用它们。 此外,还有个明显的问题是词频衰减的速度相当地快。 例如,最常用单词的词频对比,第10个还不到第1个的1/5。 为了更好地理解,我们可以画出的词频图:
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vuWTgY0f-1676882122665)(image/image_M1LPy_Weac.png)]
通过此图我们可以发现:词频以一种明确的方式迅速衰减。 将前几个单词作为例外消除后,剩余的所有单词大致遵循双对数坐标图上的一条直线。 这意味着单词的频率满足齐普夫定律(Zipf’s law), 即第i个最常用单词的频率 n i n_i ni为:
n i ∝ 1 i α , n_i \propto \frac{1}{i^\alpha}, ni∝iα1,
等价于
log n i = − α log i + c , \log n_i = -\alpha \log i + c, logni=−αlogi+c,
其中 α \alpha α是刻画分布的指数, c c c是常数。 这告诉我们想要通过计数统计和平滑来建模单词是不可行的, 因为这样建模的结果会大大高估尾部单词的频率,也就是所谓的不常用单词。 那么其他的词元组合,比如二元语法、三元语法等等,又会如何呢? 我们来看看二元语法的频率是否与一元语法的频率表现出相同的行为方式。
bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])]
bigram_vocab = d2l.Vocab(bigram_tokens)
bigram_vocab.token_freqs[:10]
这段代码用于创建一个语料库中的二元词组。
首先,它使用zip函数将语料库中相邻的两个单词配对成二元词组,并将它们存储在bigram_tokens列表中。
zip(corpus[:-1], corpus[1:])是一种将语料库中相邻两个单词配对成二元词组的方法。
例如,如果语料库为:
corpus = [‘I’, ‘like’, ‘machine’, ‘learning’]
那么zip(corpus[:-1], corpus[1:])的结果将是:
[(‘I’, ‘like’), (‘like’, ‘machine’), (‘machine’, ‘learning’)]
即相邻的两个单词被配对成二元词组。
接下来,它使用d2l.Vocab类创建一个词汇表,该词汇表的构造函数接收二元词组列表作为参数。
最后,它打印了二元词组词汇表中前10个词项的频率。
[(('of', 'the'), 309),
(('in', 'the'), 169),
(('i', 'had'), 130),
(('i', 'was'), 112),
(('and', 'the'), 109),
(('the', 'time'), 102),
(('it', 'was'), 99),
(('to', 'the'), 85),
(('as', 'i'), 78),
(('of', 'a'), 73)]
这里值得注意:在十个最频繁的词对中,有九个是由两个停用词组成的, 只有一个与“the time”有关。 我们再进一步看看三元语法的频率是否表现出相同的行为方式。
trigram_tokens = [triple for triple in zip(
corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
trigram_vocab.token_freqs[:10]
[(('the', 'time', 'traveller'), 59),
(('the', 'time', 'machine'), 30),
(('the', 'medical', 'man'), 24),
(('it', 'seemed', 'to'), 16),
(('it', 'was', 'a'), 15),
(('here', 'and', 'there'), 15),
(('seemed', 'to', 'me'), 14),
(('i', 'did', 'not'), 14),
(('i', 'saw', 'the'), 13),
(('i', 'began', 'to'), 13)]
最后,我们直观地对比三种模型中的词元频率:一元语法、二元语法和三元语法。
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fqj9gPFD-1676882122666)(image/image_7es-3-FhvC.png)]
这张图非常令人振奋!原因有很多:
- 除了一元语法词,单词序列似乎也遵循齐普夫定律, 尽管公式 中的指数 α \alpha α更小 (指数的大小受序列长度的影响);
- 词表中n元组的数量并没有那么大,这说明语言中存在相当多的结构, 这些结构给了我们应用模型的希望;
- 很多n元组很少出现,这使得拉普拉斯平滑非常不适合语言建模。 作为代替,我们将使用基于深度学习的模型。
读取长序列数据
由于序列数据本质上是连续的,因此我们在处理数据时需要解决这个问题。 在 之前我们以一种相当特别的方式做到了这一点: 当序列变得太长而不能被模型一次性全部处理时, 我们可能希望拆分这样的序列方便模型读取。
在介绍该模型之前,我们看一下总体策略。 假设我们将使用神经网络来训练语言模型, 模型中的网络一次处理具有预定义长度 (例如n个时间步)的一个小批量序列。 现在的问题是如何随机生成一个小批量数据的特征和标签以供读取。
首先,由于文本序列可以是任意长的, 例如整本《时光机器》(The Time Machine), 于是任意长的序列可以被我们划分为具有相同时间步数的子序列。 当训练我们的神经网络时,这样的小批量子序列将被输入到模型中。 假设网络一次只处理具有n个时间步的子序列。 下图画出了 从原始文本序列获得子序列的所有不同的方式, 其中n=5,并且每个时间步的词元对应于一个字符。 请注意,因为我们可以选择任意偏移量来指示初始位置,所以我们有相当大的自由度。

事实上,他们都一样的好。 然而,如果我们只选择一个偏移量, 那么用于训练网络的、所有可能的子序列的覆盖范围将是有限的。 因此,我们可以从随机偏移量开始划分序列, 以同时获得_覆盖性_(coverage)和_随机性_(randomness)。 下面,我们将描述如何实现_随机采样_(random sampling)和 顺序分区(sequential partitioning)策略。
随机采样
在随机采样中,每个样本都是在原始的长序列上任意捕获的子序列。 在迭代过程中,来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻。 对于语言建模,目标是基于到目前为止我们看到的词元来预测下一个词元, 因此标签是移位了一个词元的原始序列。
下面的代码每次可以从数据中随机生成一个小批量。 在这里,参数batch_size指定了每个小批量中子序列样本的数目, 参数num_steps是每个子序列中预定义的时间步数。
def seq_data_iter_random(corpus, batch_size, num_steps): #@save
"""使用随机抽样生成一个小批量子序列"""
# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 减去1,是因为我们需要考虑标签
num_subseqs = (len(corpus) - 1) // num_steps # 确定从随机偏移量开始的语料库中有多少个长度为num_steps的子序列
# 长度为num_steps的子序列的起始索引
initial_indices = list(range(0, num_subseqs * num_steps, num_steps)) # 计算出每个子序列的起始索引
# 在随机抽样的迭代过程中,
# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻
random.shuffle(initial_indices)
def data(pos):
# 返回从pos位置开始的长度为num_steps的序列
return corpus[pos: pos + num_steps]
# 将每个小批量中的每对相邻的子序列以tensor的形式输出,并以迭代的方式返回
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
# 在这里,initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch] # 每个序列下一个
yield torch.tensor(X), torch.tensor(Y)
这段代码实现了一个随机生成小批量子序列的函数 seq_data_iter_random,该函数可以从给定的语料库(corpus)中生成随机的小批量子序列,并以迭代的方式输出。
该函数的输入参数包括语料库(corpus),批量大小(batch_size)和步长(num_steps)。在生成小批量子序列的过程中,语料库将被随机偏移,以确保每个小批量中的子序列不一定在原始语料库上相邻。
具体来说,该函数首先通过随机偏移量对语料库进行分区,其随机范围包括num_steps-1。然后,它确定了从随机偏移量开始的语料库中有多少个长度为num_steps的子序列,并计算出每个子序列的起始索引。接下来,该函数通过随机抽样生成了小批量的子序列。在随机抽样的过程中,来自两个相邻的、随机的、小批量中的子序列不一定在原始语料库上相邻。
最后,该函数将每个小批量中的每对相邻的子序列以tensor的形式输出,并以迭代的方式返回。
**下面我们生成一个从0到34的序列。 假设批量大小为2,时间步数为5,这意味着可以生成 ** ⌊ ( 35 − 1 ) / 5 ⌋ = 6 \lfloor (35 - 1) / 5 \rfloor= 6 ⌊(35−1)/5⌋=6个“特征-标签”子序列对。 如果设置小批量大小为2,我们只能得到3个小批量
my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
X: tensor([[27, 28, 29, 30, 31],
[ 2, 3, 4, 5, 6]])
Y: tensor([[28, 29, 30, 31, 32],
[ 3, 4, 5, 6, 7]])
X: tensor([[17, 18, 19, 20, 21],
[ 7, 8, 9, 10, 11]])
Y: tensor([[18, 19, 20, 21, 22],
[ 8, 9, 10, 11, 12]])
X: tensor([[12, 13, 14, 15, 16],
[22, 23, 24, 25, 26]])
Y: tensor([[13, 14, 15, 16, 17],
[23, 24, 25, 26, 27]])
例如:给一个27预测28,然后给一个27,28预测29,给一个27,28,29预测30,最多预测五个
顺序分区
在迭代过程中,除了对原始序列可以随机抽样外, 我们还可以保证两个相邻的小批量中的子序列在原始序列上也是相邻的。 这种策略在基于小批量的迭代过程中保留了拆分的子序列的顺序,因此称为顺序分区。
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save
"""使用顺序分区生成一个小批量子序列"""
# 从随机偏移量开始划分序列
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
这段代码定义了一个名为seq_data_iter_sequential的函数,该函数生成一个小批量子序列。该函数通过从随机偏移量开始划分序列来实现此目的。
在代码中,使用random.randint(0, num_steps)生成一个随机的偏移量。然后,使用该偏移量,计算出序列中有多少个单词可以被分为整个小批量,即**num_tokens**。
接下来,从语料库中分别提取****Xs和Ys两个子序列。接着,通过使用reshape函数将其转换为形状为(batch_size, -1)**的张量。最后,通过循环迭代分割出多个小批量,并使用****yield**语句将这些小批量的输入和标签分别作为函数的输出。
基于相同的设置,通过顺序分区读取每个小批量的子序列的特征X和标签Y。 通过将它们打印出来可以发现: 迭代期间来自两个相邻的小批量中的子序列在原始序列中确实是相邻的。
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
X: tensor([[ 2, 3, 4, 5, 6],
[18, 19, 20, 21, 22]])
Y: tensor([[ 3, 4, 5, 6, 7],
[19, 20, 21, 22, 23]])
X: tensor([[ 7, 8, 9, 10, 11],
[23, 24, 25, 26, 27]])
Y: tensor([[ 8, 9, 10, 11, 12],
[24, 25, 26, 27, 28]])
X: tensor([[12, 13, 14, 15, 16],
[28, 29, 30, 31, 32]])
Y: tensor([[13, 14, 15, 16, 17],
[29, 30, 31, 32, 33]])
顺序的意思是:第一个batch是tensor([[ 2, 3, 4, 5, 6],到下一个batch接着tensor([[ 7, 8, 9, 10, 11]
现在,我们将上面的两个采样函数包装到一个类中, 以便稍后可以将其用作数据迭代器。
class SeqDataLoader: #@save
"""加载序列数据的迭代器"""
def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
if use_random_iter:
self.data_iter_fn = d2l.seq_data_iter_random # 随机
else:
self.data_iter_fn = d2l.seq_data_iter_sequential # 顺序
self.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)
self.batch_size, self.num_steps = batch_size, num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
这是一个用于加载序列数据的类SeqDataLoader。该类的作用是生成一个迭代器,这个迭代器能够不断生成小批量子序列,以用于训练模型。
通过在构造函数中的use_random_iter参数的值,确定使用顺序分区还是随机抽样,进而确定生成数据的方式。该类还记录了批量大小和序列长度,并且加载了语料库和词汇表。
在该类的内部,使用了一个生成器函数,它是由data_iter_fn变量指向的。该变量可以指向函数seq_data_iter_random或者seq_data_iter_sequential,以确定生成数据的方法。
在类的__iter__方法中,调用了data_iter_fn来生成迭代器,并返回该迭代器。
最后,我们定义了一个函数load_data_time_machine, 它同时返回数据迭代器和词表, 因此可以与其他带有load_data前缀的函数类似地使用。
def load_data_time_machine(batch_size, num_steps, #@save
use_random_iter=False, max_tokens=10000):
"""返回时光机器数据集的迭代器和词表"""
data_iter = SeqDataLoader(
batch_size, num_steps, use_random_iter, max_tokens)
return data_iter, data_iter.vocab
load_data_time_machine函数用于加载时光机器数据集的迭代器和词表。
该函数接收以下参数:
batch_size:每个小批量的样本数num_steps:每个样本中时间步数use_random_iter:布尔值,表示是否使用随机划分序列。max_tokens:最多加载的标记数(即词数)。
函数内部创建一个SeqDataLoader类的实例,该类的实例代表时光机器数据集的迭代器。函数返回该实例和该实例对应的词表。
总结
- 语言模型是自然语言处理的关键。
- n元语法通过截断相关性,为处理长序列提供了一种实用的模型。
- 长序列存在一个问题:它们很少出现或者从不出现。
- 齐普夫定律支配着单词的分布,这个分布不仅适用于一元语法,还适用于其他n元语法。
- 通过拉普拉斯平滑法可以有效地处理结构丰富而频率不足的低频词词组。
- 读取长序列的主要方式是随机采样和顺序分区。在迭代过程中,后者可以保证来自两个相邻的小批量中的子序列在原始序列上也是相邻的。
循环神经网络

循环神经网络(recurrent neural networks,RNNs) 是具有隐状态的神经网络。 在介绍循环神经网络模型之前, 我们首先回顾多层感知机模型。
无隐状态的神经网络

有隐状态的循环神经网络


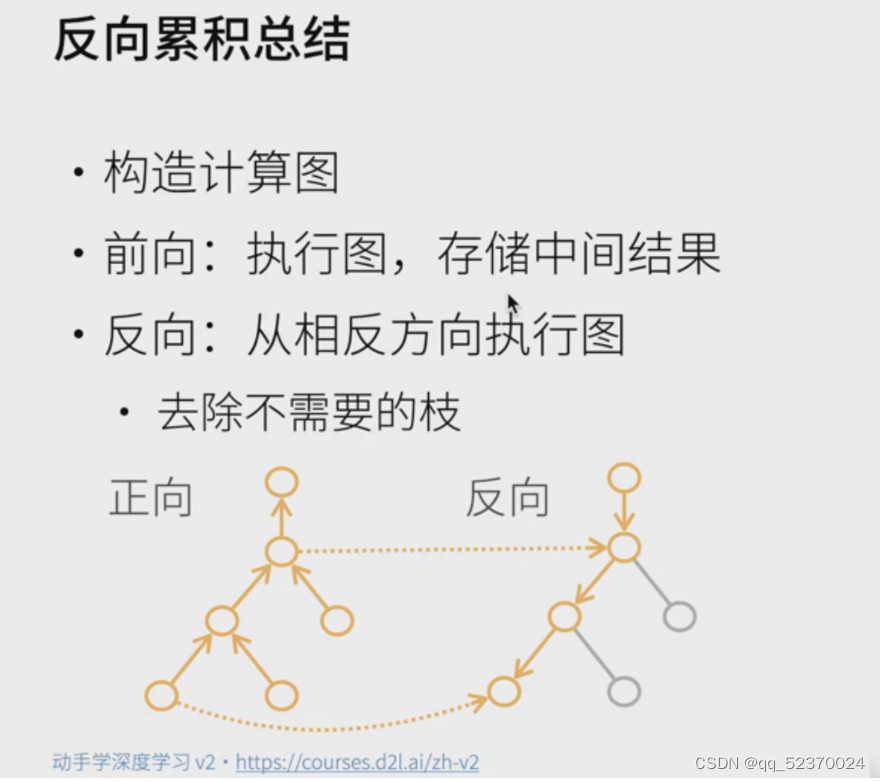
下图展示了循环神经网络在三个相邻时间步的计算逻辑。 在任意时间步 t t t,隐状态的计算可以被视为:
- 拼接当前时间步 t t t的输入 X t \mathbf{X}_t Xt和前一时间步 t − 1 t−1 t−1的隐状态 H t − 1 \mathbf{H}_{t-1} Ht−1;
- 将拼接的结果送入带有激活函数 ϕ \phi ϕ的全连接层。 全连接层的输出是当前时间步 t t t的隐状态 H t \mathbf{H}_t Ht。
在本例中,模型参数是 W x h \mathbf{W}_{xh} Wxh和 W h h \mathbf{W}_{hh} Whh的拼接, 以及 b h \mathbf{b}_h bh的偏置,所有这些参数都来自 (8.4.5)。 当前时间步 t t t的隐状态$ \mathbf{H}t 将参与计算下一时间步 将参与计算下一时间步 将参与计算下一时间步t+1 的隐状态 的隐状态 的隐状态\mathbf{H}{t+1} 。而且 。 而且 。而且\mathbf{H}_t 还将送入全连接输出层,用于计算当前时间步 还将送入全连接输出层, 用于计算当前时间步 还将送入全连接输出层,用于计算当前时间步t 的输出 的输出 的输出\mathbf{O}_t$。

我们刚才提到,隐状态中
X
t
W
x
h
+
H
t
−
1
W
h
h
\mathbf{X}_{t} \mathbf{W}_{x h}+\mathbf{H}_{t-1} \mathbf{W}_{h h}
XtWxh+Ht−1Whh的计算, 相当于
X
t
\mathbf{X}_t
Xt和
H
t
−
1
\mathbf{H}_{t-1}
Ht−1的拼接 与
W
x
h
\mathbf{W}_{xh}
Wxh和
W
h
h
\mathbf{W}_{hh}
Whh的拼接的矩阵乘法。 虽然这个性质可以通过数学证明, 但在下面我们使用一个简单的代码来说明一下。 首先,我们定义矩阵X、W_xh、H和W_hh, 它们的形状分别为(3,1)、,(1,4)、,(3,4)和,(4,4)。 分别将X乘以W_xh,将H乘以W_hh, 然后将这两个乘法相加,我们得到一个形状为(3,4)的矩阵。
import torch
from d2l import torch as d2l
X, W_xh = torch.normal(0, 1, (3, 1)), torch.normal(0, 1, (1, 4))
H, W_hh = torch.normal(0, 1, (3, 4)), torch.normal(0, 1, (4, 4))
torch.matmul(X, W_xh) + torch.matmul(H, W_hh)
tensor([[ 0.2321, -0.9882, -1.6137, -1.0731],
[-2.1590, -4.5628, -2.4992, -1.6673],
[ 0.9875, 3.9260, 4.5676, 0.8728]])
现在,我们沿列(轴1)拼接矩阵X和H, 沿行(轴0)拼接矩阵W_xh和W_hh。 这两个拼接分别产生形状(3,5)和形状(5,4)的矩阵。 再将这两个拼接的矩阵相乘, 我们得到与上面相同形状(3,4)的输出矩阵。
torch.matmul(torch.cat((X, H), 1), torch.cat((W_xh, W_hh), 0))
tensor([[ 0.2321, -0.9882, -1.6137, -1.0731],
[-2.1590, -4.5628, -2.4992, -1.6673],
[ 0.9875, 3.9260, 4.5676, 0.8728]])
基于循环神经网络的字符级语言模型
我们的目标是根据过去的和当前的词元预测下一个词元, 因此我们将原始序列移位一个词元作为标签。 Bengio等人首先提出使用神经网络进行语言建模 (Bengio et al., 2003)。 接下来,我们看一下如何使用循环神经网络来构建语言模型。 设小批量大小为1,批量中的文本序列为“machine”。 为了简化后续部分的训练,我们考虑使用 字符级语言模型(character-level language model), 将文本词元化为字符而不是单词。 下图演示了 如何通过基于字符级语言建模的循环神经网络, 使用当前的和先前的字符预测下一个字符。

在训练过程中,我们对每个时间步的输出层的输出进行softmax操作, 然后利用交叉熵损失计算模型输出和标签之间的误差。 由于隐藏层中隐状态的循环计算, 图中的第3个时间步的输出 O 3 \mathbf{O}_3 O3 由文本序列“m”“a”和“c”确定。 由于训练数据中这个文本序列的下一个字符是“h”, 因此第3个时间步的损失将取决于下一个字符的概率分布, 而下一个字符是基于特征序列“m”“a”“c”和这个时间步的标签“h”生成的。
在实践中,我们使用的批量大小为 n > 1 n>1 n>1, 每个词元都由一个 d d d维向量表示。 因此,在时间步 t t t输入 X t \mathbf X_t Xt将是一个 n × d n\times d n×d矩阵。
困惑度(Perplexity)

1 n ∑ t = 1 n − log P ( x t ∣ x t − 1 , … , x 1 ) \frac{1}{n} \sum_{t=1}^{n}-\log P\left(x_{t} \mid x_{t-1}, \ldots, x_{1}\right) n1t=1∑n−logP(xt∣xt−1,…,x1)
其中 P P P由语言模型给出, x t x_t xt是在时间步 t t t从该序列中观察到的实际词元。 这使得不同长度的文档的性能具有了可比性。 由于历史原因,自然语言处理的科学家更喜欢使用一个叫做困惑度(perplexity)的量。
exp ( − 1 n ∑ t = 1 n log P ( x t ∣ x t − 1 , … , x 1 ) ) \exp \left(-\frac{1}{n} \sum_{t=1}^{n} \log P\left(x_{t} \mid x_{t-1}, \ldots, x_{1}\right)\right) exp(−n1t=1∑nlogP(xt∣xt−1,…,x1))
困惑度的最好的理解是“下一个词元的实际选择数的调和平均数”。 我们看看一些案例。
- 在最好的情况下,模型总是完美地估计标签词元的概率为1。 在这种情况下,模型的困惑度为1。
- 在最坏的情况下,模型总是预测标签词元的概率为0。 在这种情况下,困惑度是正无穷大。
- 在基线上,该模型的预测是词表的所有可用词元上的均匀分布。 在这种情况下,困惑度等于词表中唯一词元的数量。 事实上,如果我们在没有任何压缩的情况下存储序列, 这将是我们能做的最好的编码方式。 因此,这种方式提供了一个重要的上限, 而任何实际模型都必须超越这个上限。
梯度剪裁

循环神经网络的从零开始实现
从头开始基于循环神经网络实现字符级语言模型。 这样的模型将在H.G.Wells的时光机器数据集上训练。 我们先读取数据集。
%matplotlib inline
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 批量大小、长度
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
独热编码
回想一下,在train_iter中,每个词元都表示为一个数字索引, 将这些索引直接输入神经网络可能会使学习变得困难。 我们通常将每个词元表示为更具表现力的特征向量。 最简单的表示称为_独热编码_(one-hot encoding)。
简言之,将每个索引映射为相互不同的单位向量: 假设词表中不同词元的数目为
N
N
N(即****len(vocab)****), 词元索引的范围为0到
N
−
1
N-1
N−1。 如果词元的索引是整数
i
i
i, 那么我们将创建一个长度为
N
N
N的全0向量, 并将第
i
i
i处的元素设置为1。 此向量是原始词元的一个独热向量。 索引为0和2的独热向量如下所示:
F.one_hot(torch.tensor([0, 2]), len(vocab))
tensor([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0]])
我们每次采样的小批量数据形状是二维张量: (批量大小,时间步数)。 one_hot函数将这样一个小批量数据转换成三维张量, 张量的最后一个维度等于词表大小(len(vocab))。 我们经常转换输入的维度,以便获得**形状为 (时间步数,批量大小,词表大小)**的输出。 这将使我们能够更方便地通过最外层的维度, 一步一步地更新小批量数据的隐状态。
X = torch.arange(10).reshape((2, 5))
F.one_hot(X.T, 28).shape # 转置
torch.Size([5, 2, 28]) # 时间步数,批量大小,词表大小
初始化模型参数
接下来,我们初始化循环神经网络模型的模型参数。 隐藏单元数**num_hiddens**是一个可调的超参数。 当训练语言模型时,输入和输出来自相同的词表。 因此,它们具有相同的维度,即词表的大小。
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size # 输入输出具有相同的维度:词表的大小
# 生成指定形状的随机数矩阵
def normal(shape):
return torch.randn(size=shape, device=device) * 0.01
# 隐藏层参数
W_xh = normal((num_inputs, num_hiddens)) # (num_inputs, num_hiddens) 就是 shape 参数的值
W_hh = normal((num_hiddens, num_hiddens))
b_h = torch.zeros(num_hiddens, device=device) # 偏置
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
这个函数定义了一组参数,用于构造循环神经网络模型。
首先,根据词汇表大小和隐藏单元数量,计算输入和输出的维度。然后,定义了一个 normal 函数,用于生成指定形状的随机数矩阵。该函数中使用了 PyTorch 函数 torch.randn 和 torch.zeros。其中,torch.randn 用于生成均值为 0,标准差为 1 的随机数矩阵;torch.zeros 用于生成全 0 矩阵。
接下来,分别定义了隐藏层的 W_xh(输入层到隐藏层的权重)、W_hh(隐藏层到隐藏层的权重)、b_h(隐藏层的偏移);输出层的 W_hq(隐藏层到输出层的权重)和 b_q(输出层的偏移)。
最后,将所有参数组成的列表 params 返回。注意到,在定义参数时,通过调用 param.requires_grad_ 函数,将 requires_grad 参数设置为 True,表示在计算梯度时要对这些参数进行求导。
循环神经网络模型
为了定义循环神经网络模型, 我们首先需要一个init_rnn_state函数在初始化时返回隐状态。 这个函数的返回是一个张量,张量全用0填充, 形状为(批量大小,隐藏单元数)。 在后面的章节中我们将会遇到隐状态包含多个变量的情况, 而使用元组可以更容易地处理些。
# 初始隐藏状态,形状为(批量大小,隐藏单元数)
def init_rnn_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
下面的rnn函数定义了如何在一个时间步内计算隐状态和输出。 循环神经网络模型通过****inputs最外层的维度实现循环, 以便逐时间步更新小批量数据的隐状态H。 此外,这里使用tanh函数作为激活函数。当元素在实数上满足均匀分布时,tanh函数的平均值为0。
def rnn(inputs, state, params):
# inputs的形状:(时间步数量,批量大小,词表大小),state初始化的隐藏层状态
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
# X的形状:(批量大小,词表大小)
for X in inputs:
H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)
Y = torch.mm(H, W_hq) + b_q # 当前时刻
outputs.append(Y) # 所有时刻
return torch.cat(outputs, dim=0), (H,) # 输出和当前的隐藏状态
# 按照dim=0输出就是变成2维,假设循环5词,每次生成2*vocab_size的矩阵,拼在一起后就是10*vocab_size,即包含了10个词的信息
rnn函数的输入有三个部分:inputs,state,params。
- inputs:时间步数量的一维词表,形状为(时间步数量,批量大小,词表大小)
- state:初始化的隐藏层状态,是一个元组,仅有一个元素
- params:参数,是一个元组,包含五个参数:W_xh,W_hh,b_h,W_hq,b_q。
首先,从params中获取参数,并初始化输出列表outputs。接着,遍历inputs中的每一时间步,用当前时刻的X和上一时刻的隐藏状态H计算当前隐藏状态H。最后,用H和W_hq以及b_q计算当前时刻的输出Y。将Y加入outputs列表。
最后,把outputs列表按照dim=0组合成一个张量,并返回。输出的形状为(时间步数量 * 批量大小,词表大小),当前隐藏状态H以元组的形式返回。
定义了所有需要的函数之后,接下来我们创建一个类来包装这些函数, 并存储从零开始实现的循环神经网络模型的参数。
class RNNModelScratch: #@save
"""从零开始实现的循环神经网络模型"""
def __init__(self, vocab_size, num_hiddens, device,
get_params, init_state, forward_fn):
self.vocab_size, self.num_hiddens = vocab_size, num_hiddens
self.params = get_params(vocab_size, num_hiddens, device)
self.init_state, self.forward_fn = init_state, forward_fn
def __call__(self, X, state): # x为(批量大小*时间步数)
X = F.one_hot(X.T, self.vocab_size).type(torch.float32)
return self.forward_fn(X, state, self.params)
# 初始化
def begin_state(self, batch_size, device):
return self.init_state(batch_size, self.num_hiddens, device)
首先,这是一个自定义的类RNNModelScratch,表示一个从零开始实现的循环神经网络模型。在初始化函数__init__中,它接收四个参数:vocab_size,num_hiddens,device和三个函数:get_params,init_state和forward_fn。
vocab_size和num_hiddens分别表示词汇表的大小和隐藏层单元数。device是指定使用的设备(GPU或CPU)。
get_params是一个函数,用于初始化模型的参数,并将它们存储在类的参数属性params中。
init_state是一个函数,用于初始化隐藏层的状态。它将存储在类的参数属性init_state中。
forward_fn是一个函数,用于计算循环神经网络的前向计算。它将存储在类的参数属性forward_fn中。
在类的__call__方法中,它接收两个参数:X和state。首先,X被转换为词索引的独热编码,然后将该编码作为输入,通过调用forward_fn函数计算输出和最终隐藏层状态。
最后,begin_state方法用于初始化隐藏层状态。它接收两个参数:batch_size和device
让我们检查输出是否具有正确的形状。 例如,隐状态的维数是否保持不变。
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
init_rnn_state, rnn)
state = net.begin_state(X.shape[0], d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state)
Y.shape, len(new_state), new_state[0].shape
(torch.Size([10, 28]), 1, torch.Size([2, 512]))
我们可以看到输出形状是(时间步数*批量大小,词表大小), 而隐状态形状保持不变,即(批量大小,隐藏单元数)。
预测
让我们首先定义预测函数来生成****prefix之后的新字符, 其中的prefix是一个用户提供的包含多个字符的字符串。 在循环遍历prefix中的开始字符时, 我们不断地将隐状态传递到下一个时间步,但是不生成任何输出。 这被称为_预热_(warm-up)期, 因为在此期间模型会自我更新(例如,更新隐状态), 但不会进行预测。 预热期结束后,隐状态的值通常比刚开始的初始值更适合预测, 从而预测字符并输出它们。
def predict_ch8(prefix, num_preds, net, vocab, device): #@save # prefix给定的字符、num_preds生成多少词
"""在prefix后面生成新字符"""
#生成初始的隐藏状态
state = net.begin_state(batch_size=1, device=device)
outputs = [vocab[prefix[0]]] # prefix中第一个字符在vocab中的下标,因为第一个是不能进行预测的
get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1)) # 最近的词作为输入
for y in prefix[1:]: # 预热期
_, state = net(get_input(), state)
outputs.append(vocab[y])
for _ in range(num_preds): # 预测num_preds步
y, state = net(get_input(), state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])
这个predict_ch8函数用于生成新的字符。具体来说,它接受四个参数:
prefix:给定的字符,用于生成新字符的前导。
num_preds:要生成的字符数量。
net:训练好的模型。
vocab:字符级词典。
device: 存储模型的设备,例如 CPU 或 GPU。
首先,函数调用模型的begin_state函数生成初始的隐藏状态,该隐藏状态的大小为(1,隐藏层大小)。
接下来,我们将prefix中的字符编码为在字符级词典中对应的下标,并保存在outputs列表中。
接下来,通过循环预热,并使用每次循环的最后一个输出来作为下一个字符的输入。预热期的长度是**prefix**的长度减1。
📌预热期(Warm-Up)是指在开始预测前,用一些输入数据来初始化模型的隐藏状态。比如在语言模型中,如果在生成新字符前,我们先使用一些已知的字符来更新模型的隐藏状态,那么就是一个预热期。预热期可以帮助模型更好地预测下一个字符。
最后,我们使用num_preds循环进行预测,将每次预测结果加入到outputs列表中,并将字符级词典的下标转换为对应的字符,返回它们的字符串。
现在我们可以测试predict_ch8函数。 我们将前缀指定为time traveller, 并基于这个前缀生成10个后续字符。 鉴于我们还没有训练网络,它会生成荒谬的预测结果。
predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu())
'time traveller vxs dyhmat'
梯度裁剪
g ← min ( 1 , θ ∥ g ∥ ) g \mathbf{g} \leftarrow \min \left(1, \frac{\theta}{\|\mathbf{g}\|}\right) \mathbf{g} g←min(1,∥g∥θ)g
下面我们定义一个函数来裁剪模型的梯度, 模型是从零开始实现的模型或由高级API构建的模型。 我们在此计算了所有模型参数的梯度的范数。
def grad_clipping(net, theta): #@save
"""裁剪梯度"""
if isinstance(net, nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
这是一个裁剪梯度的函数,它的作用是当梯度的范数超过阈值θ时,将梯度缩放为阈值θ,从而避免梯度爆炸。
该函数接受两个参数:
- net:网络模型
- theta:阈值θ
首先通过判断传入的net变量是否是nn.Module的实例来确定参数的获取方式,如果是,就将所有需要求导的参数加入列表params中;如果不是,就从net中直接获取参数params。
接下来,程序计算出所有参数的梯度平方和的平方根,即梯度的范数。
最后,当梯度范数大于阈值θ时,对于所有参数,将它们的梯度缩放为阈值θ除以梯度范数。
训练
在训练模型之前,让我们定义一个函数在一个迭代周期内训练模型。
- 序列数据的不同采样方法(随机采样和顺序分区)将导致隐状态初始化的差异。
- 我们在更新模型参数之前裁剪梯度。 这样的操作的目的是,即使训练过程中某个点上发生了梯度爆炸,也能保证模型不会发散。
- 我们用困惑度来评价模型。
具体来说,当使用顺序分区时, 我们只在每个迭代周期的开始位置初始化隐状态。 由于下一个小批量数据中的第i个子序列样本 与当前第i个子序列样本相邻, 因此当前小批量数据最后一个样本的隐状态, 将用于初始化下一个小批量数据第一个样本的隐状态。 这样,存储在隐状态中的序列的历史信息 可以在一个迭代周期内流经相邻的子序列。 然而,在任何一点隐状态的计算, 都依赖于同一迭代周期中前面所有的小批量数据, 这使得梯度计算变得复杂。 为了降低计算量,在处理任何一个小批量数据之前, 我们先分离梯度,使得隐状态的梯度计算总是限制在一个小批量数据的时间步内。
当使用随机抽样时,因为每个样本都是在一个随机位置抽样的, 因此需要为每个迭代周期重新初始化隐状态。
#@save
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):
"""训练网络一个迭代周期"""
state, timer = None, d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失之和,词元数量
for X, Y in train_iter:
if state is None or use_random_iter:
# 在第一次迭代或使用随机抽样时初始化state
state = net.begin_state(batch_size=X.shape[0], device=device)
else:
if isinstance(net, nn.Module) and not isinstance(state, tuple):
# state对于nn.GRU是个张量
state.detach_()
else:
# state对于nn.LSTM或对于我们从零开始实现的模型是个张量
for s in state:
s.detach_()
y = Y.T.reshape(-1)
X, y = X.to(device), y.to(device)
y_hat, state = net(X, state)
l = loss(y_hat, y.long()).mean()
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad()
l.backward()
grad_clipping(net, 1) # 梯度剪裁
updater.step()
else:
l.backward()
grad_clipping(net, 1)
# 因为已经调用了mean函数
updater(batch_size=1)
metric.add(l * y.numel(), y.numel())
return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
train_epoch_ch8 函数首先定义了一些初始变量:
- state:初始的隐藏状态;
- timer:d2l.Timer 类的实例,用于计时;
- metric:d2l.Accumulator 类的实例,用于累加训练中的损失和词元数量。
然后进入循环,循环的每一步对应了一个批量的数据。在循环内部,如果 state 变量为 None,或者 use_random_iter 为 True,那么我们会重新初始化 state。
接下来,我们将 X 和 Y 转换成 PyTorch 张量,并在 GPU 上运算。然后我们调用 net 函数,传入 X 和 state,得到 y_hat 和 state。
最后,我们使用 mean() 函数计算这一批量的损失,并使用 grad_clipping 函数裁剪梯度。如果 updater 是 torch.optim.Optimizer 的实例,那么我们使用 torch.optim.Optimizer 的接口:zero_grad(),backward(),step() 更新参数;否则,我们直接调用 updater 函数。
在一个迭代周期结束后,函数会返回训练的平均损失和词元速度。
循环神经网络模型的训练函数既支持从零开始实现, 也可以使用高级API来实现。
#@save
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,
use_random_iter=False):
"""训练模型"""
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
# 初始化
if isinstance(net, nn.Module):
updater = torch.optim.SGD(net.parameters(), lr)
else:
updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)
predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)
# 训练和预测
for epoch in range(num_epochs):
ppl, speed = train_epoch_ch8(
net, train_iter, loss, updater, device, use_random_iter)
if (epoch + 1) % 10 == 0:
print(predict('time traveller'))
animator.add(epoch + 1, [ppl])
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
print(predict('time traveller'))
print(predict('traveller'))
该代码为最终的训练代码。它训练一个网络并使用困惑度评估模型的性能。
第一步是定义一个交叉熵损失函数(loss)。
接下来,它初始化了一个动画对象(animator),它将显示每个迭代周期的困惑度。
接下来,它判断了网络的类型是否是nn.Module,并相应地初始化了优化器(updater)。如果网络是nn.Module,则使用随机梯度下降(SGD)作为优化器,否则使用自定义的SGD函数。
最后,对于每个迭代周期,它调用train_epoch_ch8函数训练网络并计算困惑度,然后显示困惑度的动画。在每个迭代周期的末尾,它也预测了以’time traveller’和’ traveller’为前缀的词语。
现在,我们训练循环神经网络模型。 因为我们在数据集中只使用了10000个词元, 所以模型需要更多的迭代周期来更好地收敛。
num_epochs, lr = 500, 1
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())
困惑度 1.0, 72303.8 词元/秒 cuda:0
time travelleryou can show black is white by argument said filby
traveller with a slight accession ofcheerfulness really thi

最后,让我们检查一下使用随机抽样方法的结果。
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
init_rnn_state, rnn)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),
use_random_iter=True)
困惑度 1.4, 70725.7 词元/秒 cuda:0
time travellerit s against reason said filbywhan seane of the fi
travellerit s against reason said filbywhan seane of the fi

总结
- 我们可以训练一个基于循环神经网络的字符级语言模型,根据用户提供的文本的前缀生成后续文本。
- 一个简单的循环神经网络语言模型包括输入编码、循环神经网络模型和输出生成。
- 循环神经网络模型在训练以前需要初始化状态,不过随机抽样和顺序划分使用初始化方法不同。
- 当使用顺序划分时,我们需要分离梯度以减少计算量。
- 在进行任何预测之前,模型通过预热期进行自我更新(例如,获得比初始值更好的隐状态)。
- 梯度裁剪可以防止梯度爆炸,但不能应对梯度消失。
循环神经网络的简洁实现
本节将展示如何使用深度学习框架的高级API提供的函数更有效地实现相同的语言模型。 我们仍然从读取时光机器数据集开始。
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
定义模型
高级API提供了循环神经网络的实现。 我们构造一个具有256个隐藏单元的单隐藏层的循环神经网络层****rnn_layer。 事实上,我们还没有讨论多层循环神经网络的意义。 现在仅需要将多层理解为一层循环神经网络的输出被用作下一层循环神经网络的输入就足够了。
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
我们使用张量来初始化隐状态,它的形状是(隐藏层数,批量大小,隐藏单元数)。
state = torch.zeros((1, batch_size, num_hiddens)) # 隐藏层数相当于时序数据T
state.shape
torch.Size([1, 32, 256])
通过一个隐状态和一个输入,我们就可以用更新后的隐状态计算输出。 需要强调的是,rnn_layer的“输出”(Y)不涉及输出层的计算: 它是指每个时间步的隐状态,这些隐状态可以用作后续输出层的输入。
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
Y.shape, state_new.shape
(torch.Size([35, 32, 256]), torch.Size([1, 32, 256]))
我们为一个完整的循环神经网络模型定义了一个RNNModel类。 注意,rnn_layer只包含隐藏的循环层,我们还需要创建一个单独的输出层。
#@save
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size) # 输出层
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device)
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
训练与预测
在训练模型之前,让我们基于一个具有随机权重的模型进行预测。
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
d2l.predict_ch8('time traveller', 10, net, vocab, device)
'time traveller
很明显,这种模型根本不能输出好的结果。 接下来,我们使用 定义的超参数调用train_ch8,并且使用高级API训练模型。
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
perplexity 1.3, 286908.2 tokens/sec on cuda:0
time traveller came the time traveller but now you begin to spen
traveller pork acong wa canome precable thig thit lepanchat
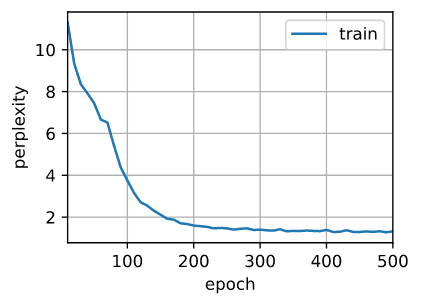
与上一节相比,由于深度学习框架的高级API对代码进行了更多的优化, 该模型在较短的时间内达到了较低的困惑度。