Multi-Task Deep Recommender Systems: A Survey
最近看到一篇多任务学习的综述,觉得总结的不错,记录一下。
1. 简介
推荐系统天然具有多任务学习的需求,以视频推荐为例,用户具有点赞、评论、转发等不同的行为。多任务学习相比单个任务的好处有2个,一是多个任务对数据的利用增强了各个任务学习的表现,二是在计算和存储上面有更高的效率。同时多任性也面对三个挑战,一是不同的任务必须获取到有用的信息,二是数据稀疏性问题,例如转化率问题,三是独特的序列依赖,例如各个任务中存在的用户行为依赖。
2. 问题定义
给定K个任务,数据集D
:
=
{
x
n
,
(
y
,
1
,
y
n
2
,
.
.
.
,
y
n
k
)
}
n
=
1
N
:=\{ \mathbf x_n , (y^1_,, y^2_n, ..., y^k_n) \}^N_{n=1}
:={xn,(y,1,yn2,...,ynk)}n=1N,即N条交互记录,K个label,各任务的模型参数
{
θ
1
,
θ
2
,
.
.
.
,
θ
k
}
\{\theta^1, \theta^2, ..., \theta^k\}
{θ1,θ2,...,θk}以及共享参数
θ
s
\theta^s
θs,损失函数定义为各个任务损失函数的加权和
arg
min
{
θ
1
,
θ
2
,
.
.
.
,
θ
k
}
L
(
θ
s
,
θ
1
,
θ
2
,
.
.
.
,
θ
k
)
=
arg
min
{
θ
1
,
θ
2
,
.
.
.
,
θ
k
}
∑
k
=
1
K
w
k
L
k
(
θ
s
,
θ
k
)
\underset{ \{\theta^1, \theta^2, ..., \theta^k \} } {\arg \min} L (\theta^s, \theta^1, \theta^2, ..., \theta^k) = \underset{ \{\theta^1, \theta^2, ..., \theta^k \} } {\arg \min} \sum^K_{k=1} w^kL^k(\theta^s, \theta^k)
{θ1,θ2,...,θk}argminL(θs,θ1,θ2,...,θk)={θ1,θ2,...,θk}argmink=1∑KwkLk(θs,θk)
这里有个特例是PLE模型中有个初始权重,根据训练阶段进行更新,
w
t
k
=
w
0
k
∗
γ
k
t
w^k_t = w^k_0*\gamma^t_k
wtk=w0k∗γkt
每个任务的损失函数如下,以BEC为例
L
k
(
θ
s
,
θ
k
)
=
−
∑
n
=
1
N
[
y
n
k
log
(
y
^
n
k
)
+
(
1
−
y
n
k
)
log
(
1
−
y
^
n
k
)
]
L^k(\theta^s, \theta^k) = - \sum^N_{n=1}[y^k_n \log (\hat y^k_n) + (1-y^k_n) \log (1-\hat y^k_n)]
Lk(θs,θk)=−n=1∑N[ynklog(y^nk)+(1−ynk)log(1−y^nk)]
和多目标推荐(multi-Objective Recommendation)的区别:多目标重在多个目标之间的平衡,像推荐的多样性、公平性等目标。多目标也是实现多任务深度推荐系统的一种方式。
和多场景推荐(multi-scenario Recommendation)的区别:多场景推荐使用多个场景的数据训练统一模型解决数据稀疏性问题,也可以视作多个场景跨域推荐。多场景推荐的label空间在不同的场景是一样的,但是在不同的场景的数据分布是不一样的。多任务学习的label空间不同的任务是不一样的。
3. 分类
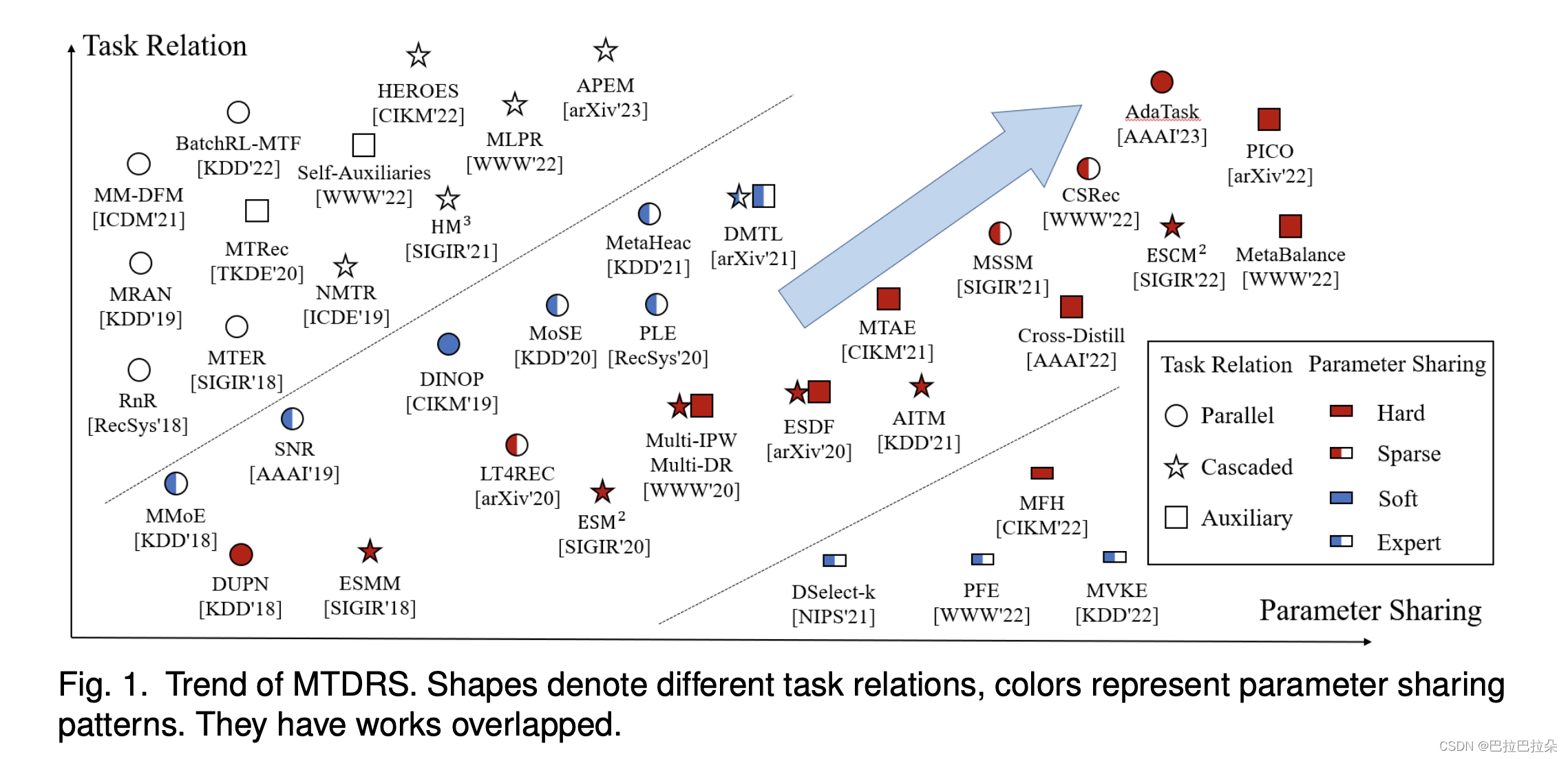
3.1 任务关系
3.1.1 并行式 各个任务之间没有相互依赖关系,彼此独立损失函数通常是各个任务loss的加权和。通过目标和挑战来分组。
按目标
Rank and rate: multi-task learning for recommender systems 将排序和评分预测两个任务合并起来。
Explainable recommendation via multi-task learning in opinionated text data 和 Co-attentive
multi-task learning for explainable recommendation 结合了推荐和解释任务。
Multi-task based sales predictions for online promotions 结合了多个销量预估任务。
按挑战,主要解决特征选择和任务共享的方式
Perceive your users in depth: Learning universal user representations from multiple e-commerce tasks 结合多任性学习、RNN结合的attention机制来抽取泛化特征。
Multiple relational attention network for multi-task learning 提出用attention机制做特征交叉及任务的特征分配。
RevMan: Revenue-aware Multi-task Online Insurance Recommendation 提出在多任务学习中基于注意力的自适应特征共享机制。
MSSM: a multiple-level sparse sharing model for efficient multi-task learning 提出在输出层应用一个特征域的系数mask。
CFS-MTL: A Causal Feature Selection Mechanism for Multi-task Learning via Pseudo-intervention 从因果视角选择稳定的因果特征。
3.1.2 级联式
针对的事有序列依赖的多任务,当前任务的计算依赖前一个任务。这一类基本都是转化预估任务。
y
^
n
k
(
θ
s
,
θ
k
)
−
y
^
n
k
−
1
(
θ
s
,
θ
k
)
=
P
(
ϵ
k
=
0
,
ϵ
k
−
1
=
1
)
\hat y^k_n( \theta^s, \ \theta^k) - \hat y^{k-1}_n( \theta^s, \ \theta^k) = P(\epsilon_k = 0, \epsilon_{k-1} = 1)
y^nk(θs, θk)−y^nk−1(θs, θk)=P(ϵk=0,ϵk−1=1)
其中
ϵ
k
\epsilon_k
ϵk是任务k的指示变量,当任务k-1没有发生时,任务k不会发生。
下表中除了AITM和APEM是广告和金融服务领域,其他的都是电子商务领域。同时这些基本都在解决样本选择问题(SSB)和数据稀疏性问题(DS),而且都是基于“曝光” -> “点击” -> “转化” 这样的假设。

ESMM:Entire space multi-task model: An effective approach for estimating post-click conversion rate
ESM
2
^2
2: Entire space multi-task modeling via post-click behavior decomposition for conversion rate prediction
Multi-IPW & DR:Large-scale causal approaches to debiasing post-click conversion rate estimation with multi-task learning
ESDF:Delayed feedback modeling for the entire space conversion rate prediction
HM
3
^3
3:Hierarchically modeling micro and macro behaviors via multi-task learning for conversion rate prediction
AITM:Modeling the sequential dependence among audience multi-step conversions with multi-task learning in targeted display advertising
MLPR:Multi-task Learning Framework for Product Ranking with BERT
ESCM
2
^2
2:Entire Space Counterfactual Multi-Task Model for Post-Click Conversion Rate Estimation
HEROES:Multi-Scale User Behavior Network for Entire Space Multi-Task Learning
APEM:Task Aware Feature Extraction Framework for Sequential Dependence Multi-Task Learning
3.1.3 辅助任务式
通过添加辅助任务的方式实现多任务学习。
MetaBalance: Improving Multi-Task Recommendations via Adapting Gradient Magnitudes of Auxiliary Tasks
Delayed feedback modeling for the entire space conversion rate prediction
Distillation based Multi-task Learning: A Candidate Generation Model for Improving Reading Duration
Multi-DR:Large-scale causal approaches to debiasing post-click conversion rate estimation with multi-task learning
还有一些通过一些特殊的设定设计不同的辅助任务。
Multi-task learning for recommendation over heterogeneous information network
Cross-task knowledge distillation in multi-task recommendation
Multi-task Learning for Bias-Free Joint CTR Prediction and Market Price Modeling in Online Advertising
通过对比学习的方式增加辅助任务。
Personalized Inter-Task Contrastive Learning for CTR&CVR Joint Estimation
A Contrastive Sharing Model for Multi-Task Recommendation
以上都是通过人工设置辅助任务,还有通过自动设置的方式。
Can Small Heads Help? Understanding and Improving Multi-Task Generalization
3.2 学习方法
按照参数共享、优化方法、训练机制分成三类
3.2.1 参数共享
示意图如下
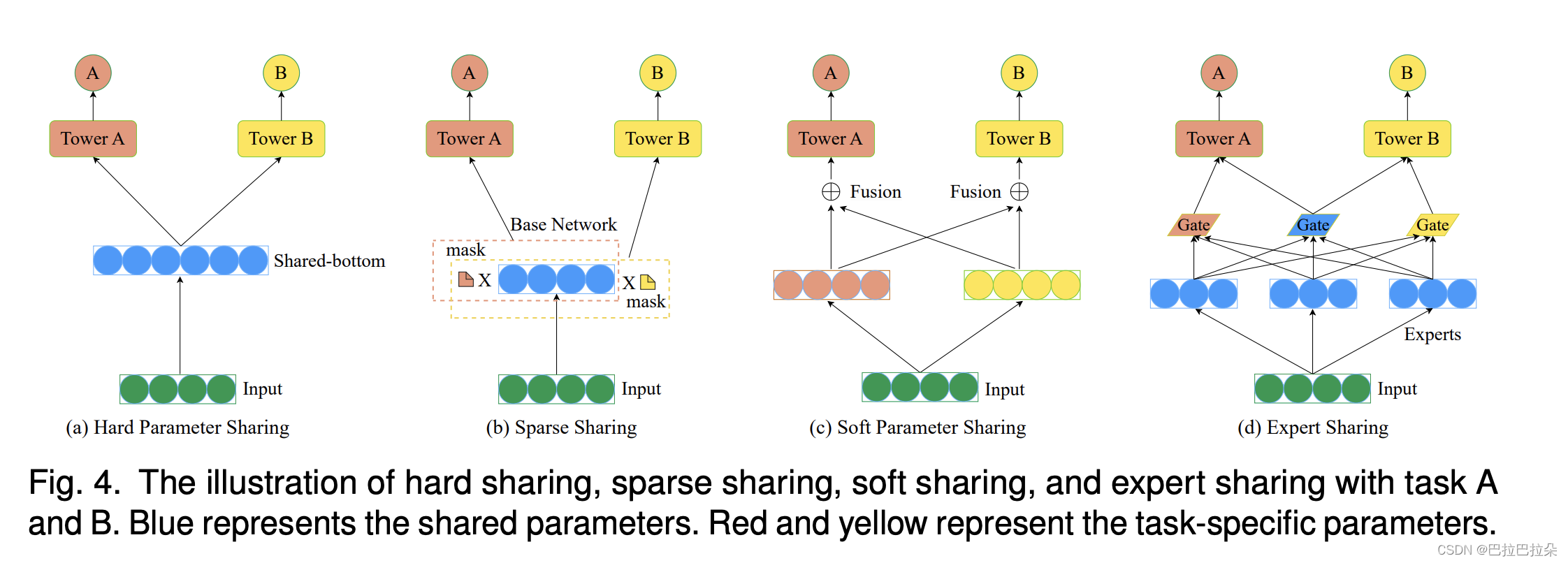
hard sharing
MetaBalance: Improving Multi-Task Recommendations via Adapting Gradient Magnitudes of Auxiliary Tasks
Multi-Faceted Hierarchical Multi-Task Learning for Recommender Systems
AdaTask: A Task-aware Adaptive Learning Rate Approach to Multi-task Learning
sparse sharing
从基础网络中通过参数mask抽取出子网络。
LT4REC: A Lottery Ticket Hypothesis Based Multi-task Practice for Video Recommendation System.
MSSM: a multiple-level sparse sharing model for efficient multi-task learning
A Contrastive Sharing Model for Multi-Task Recommendation
soft sharing
每个任务有自己的网络结构,但是各自任务的网络结构互相之间有连接,通过任务的相关性的权重来融合。
Multi-task based sales predictions for online promotions
expert sharing
MoE:Adaptive mixtures of local experts
MMoE:Modeling task relationships in multi-task learning with multi-gate mixture-of-experts
SNR:: Sub-network routing for flexible parameter sharing in multi-task learning
PLE:Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations
DMTL:Distillation based Multi-task Learning: A Candidate Generation Model for Improving Reading Duration
PFE:Prototype Feature Extraction for Multi-task Learning
MVKE:Mixture of virtual-kernel experts for multi-objective user profile modeling.
MoSE:Multitask mixture of sequential experts for user activity streams
3.2.2 优化方法
多任务的优化需要解决2个问题,一是多个任务训练的冲突,二是多个目标之间的平衡。前者和负向迁移(negative transfor)有关,后者和多目标平衡(trade-off)有关。
不同任务的梯度有巨大的不同,有任务的梯度主导了模型的更新,解决这个议题的有
Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks.
Gradient surgery for multi-task learning.
AdaTask: A Task-aware Adaptive Learning Rate Approach to Multi-task Learning
共享参数
θ
s
\theta^s
θs的冲突,不同的任务的对于共享参数的更新可能是相反的梯度方向,很有可能出现跷跷板效应。
Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations
A Contrastive Sharing Model for Multi-Task Recommendation.
多个目标之间的trade-off
Understanding and improving fairness-accuracy trade-offs in multi-task learning
Can Small Heads Help? Understanding and Improving Multi-Task Generalization
3.2.3 训练机制
分为三类,联合训练、强化学习、辅助任务学习。
联合训练
Incorporating user micro-behaviors and item knowledge into multi-task learning for session-based recommendation
Incorporating Global Context into Multi-task Learning for Session-Based Recommendation
M2TRec: Metadata-aware Multi-task Transformer for Large-scale and Cold-start free Session-based Recommendations
MARRS: A Framework for multi-objective risk-aware route recommendation using MultitaskTransformer
Multi-task feature learning for knowledge graph enhanced recommendation
Why I like it: multi-task learning for recommendation and explanation
Explainable recommendation via multi-task learning in opinionated text data
A multi-task multi-view graph representation learning framework for web-scale recommender systems
A Contrastive Sharing Model for Multi-Task Recommendation
强化学习
Learning and adaptivity in interactive recommender systems
Multi-Task Fusion via Reinforcement Learning for Long-Term User Satisfaction in Recommender Systems
Optimizing ranking algorithm in recommender
system via deep reinforcement learning
辅助任务
上述级联式的基本都是
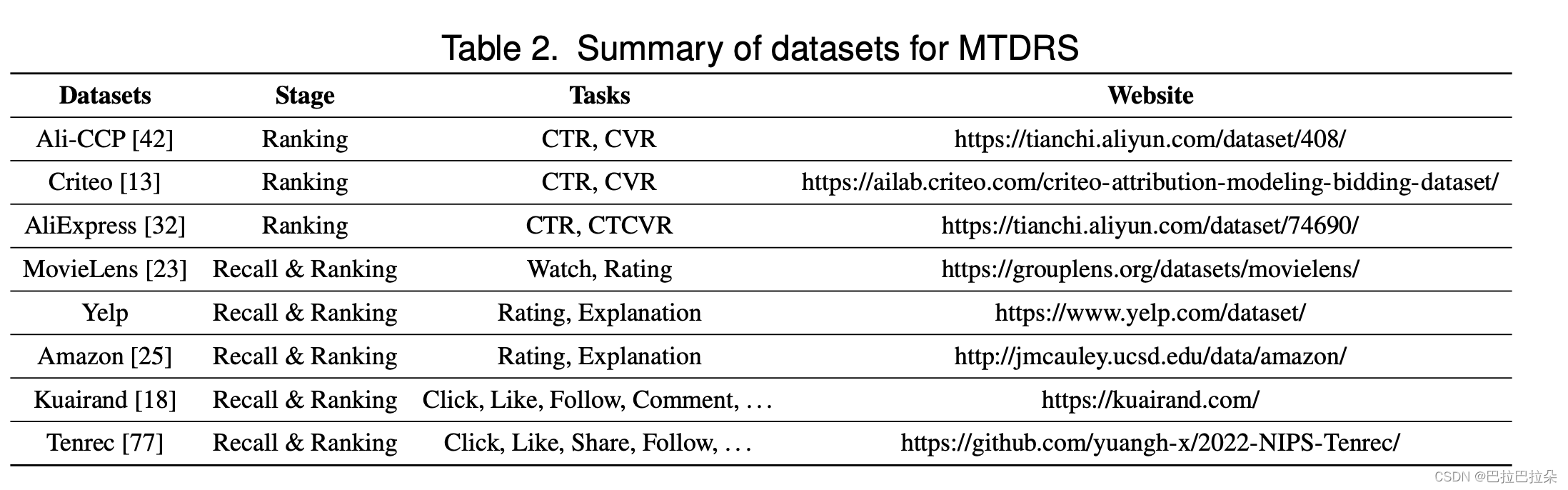
4. 应用和数据集
4.1 数据集
4.2 多任务融合
多任务融合权重通过Grid Search
Deep multifaceted transformers for multi-objective ranking in large-scale e-commerce recommender systems
Multiple objective optimization in recommender systems
进化算法
Multiobjective pareto-efficient approaches for recommender systems.
贝叶斯优化算法
Hyperparameter optimization for recommender systems through Bayesian optimization
sota的解决方案是强化学习
Optimizing ranking algorithm in recommender system via deep reinforcement learning
Multi-Task Fusion via Reinforcement Learning for Long-Term User Satisfaction in Recommender Systems
多任务的未来方向
论文给出了几个可能的方向。
解决负向迁移的问题,一个新的解决思路是通过因果推断的方式
CFS-MTL: A Causal Feature Selection Mechanism for Multi-task Learning via Pseudo-intervention
还有使用大型预训练模型,例如
Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5).
M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems
M6: A chinese multimodal pretrainer
A Unified Multi-task Learning Framework for Multi-goal Conversational Recommender Systems.
还有使用AutoML的方式,Automated Machine Learning for Deep Recommender Systems: A Survey
特定任务的偏差bias,很多任务只关注特定的偏差,像样本选择偏差(ESMM)、隐式选择偏差(Recommending what video to watch next: a multitask ranking system),预估偏差(ESCM2: Entire Space Counterfactual Multi-Task Model for Post-Click Conversion Rate Estimation),怎样解决不同任务的偏差还须要进一步的研究。




![[LeetCode周赛复盘] 第 333 场周赛20230219](https://img-blog.csdnimg.cn/29f6f204ccfb4ecf90a7b04f6c94d905.png)