文章目录
- CPU 架构
- EU(执行单元)
- BIU(总线接口单元)
- 小结一下
- 模拟内存
- 模拟 BIU
- 模拟 EU
- 模拟 CPU
- 总结
要模拟 8086 CPU 运行,必须知道 CPU 的一些知识。下文的知识点都来自《Intel_8086_Family_Users_Manual 》。
CPU 架构
微处理器通常通过重复循环执行以下步骤来执行程序(此描述有所简化):
- 从内存中取出下一条指令。
- 读取操作数(如果指令需要)。
- 执行指令。
- 写入结果(如果指令需要)。
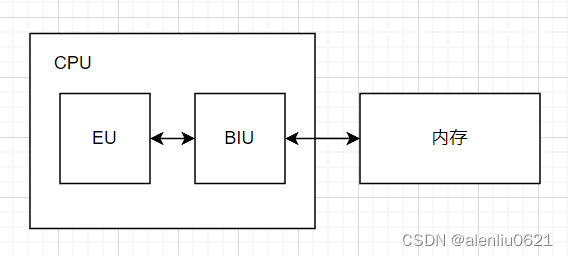
在以前的 CPU 中,大多数这些步骤都是串行执行的,或者只有一个总线周期取指重叠。 8086 和 8088 CPU 的架构也执行相同步骤,但是是将它们分配给 CPU 内两个独立的处理单元。执行单元(EU)执行指令;总线接口单元 (BIU) 获取指令、读取操作数并写入结果。
这两个单元可以彼此独立运行,并且在大多数情况下能够广泛地重叠取指令和执行。结果是,在大多数情况下,通常获取指令所需的时间“消失”了,因为 EU 执行的指令已经被 BIU 提前预取了。
8086 CPU 内部组成如下:
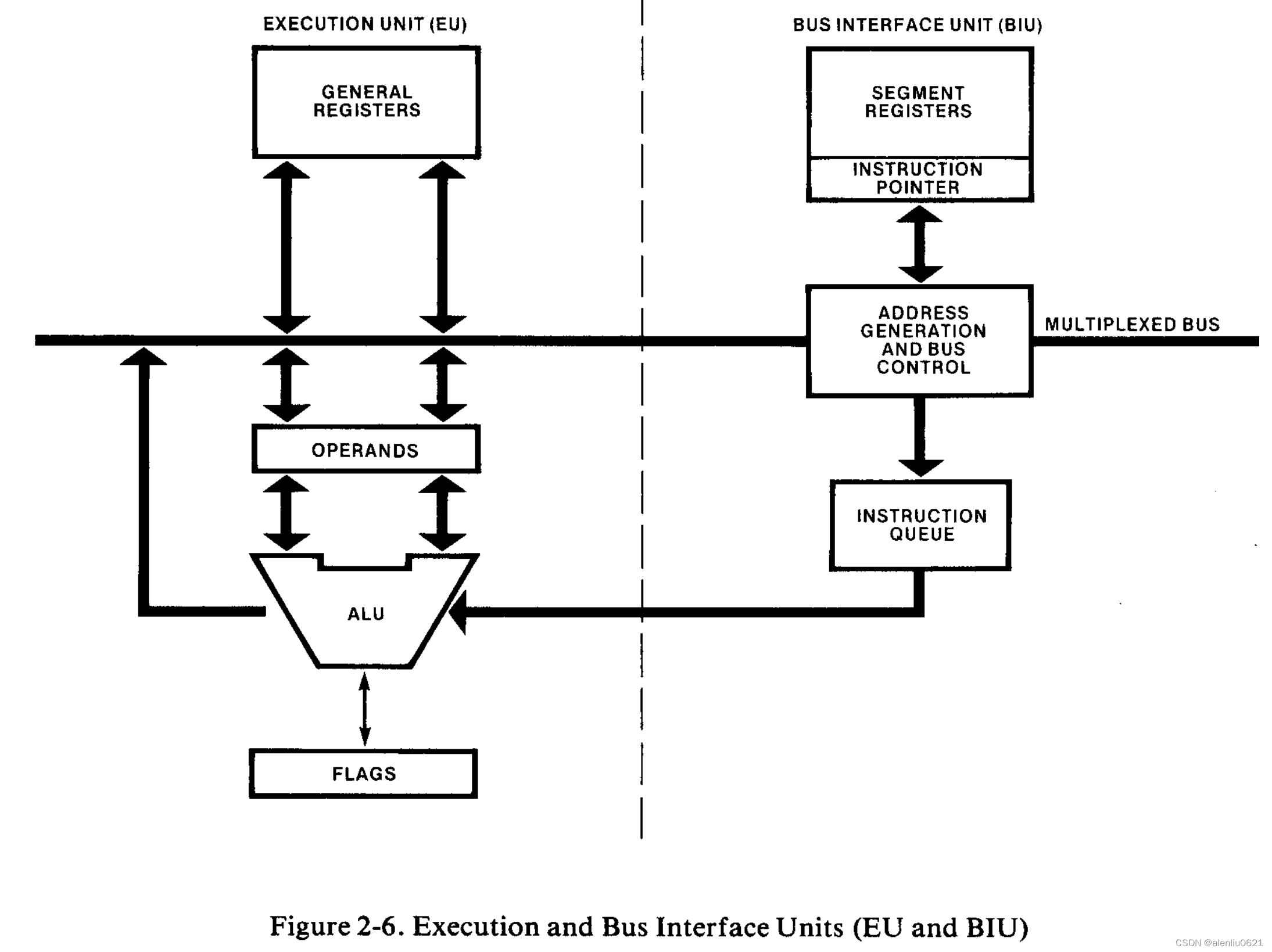
更详细的结构如下:
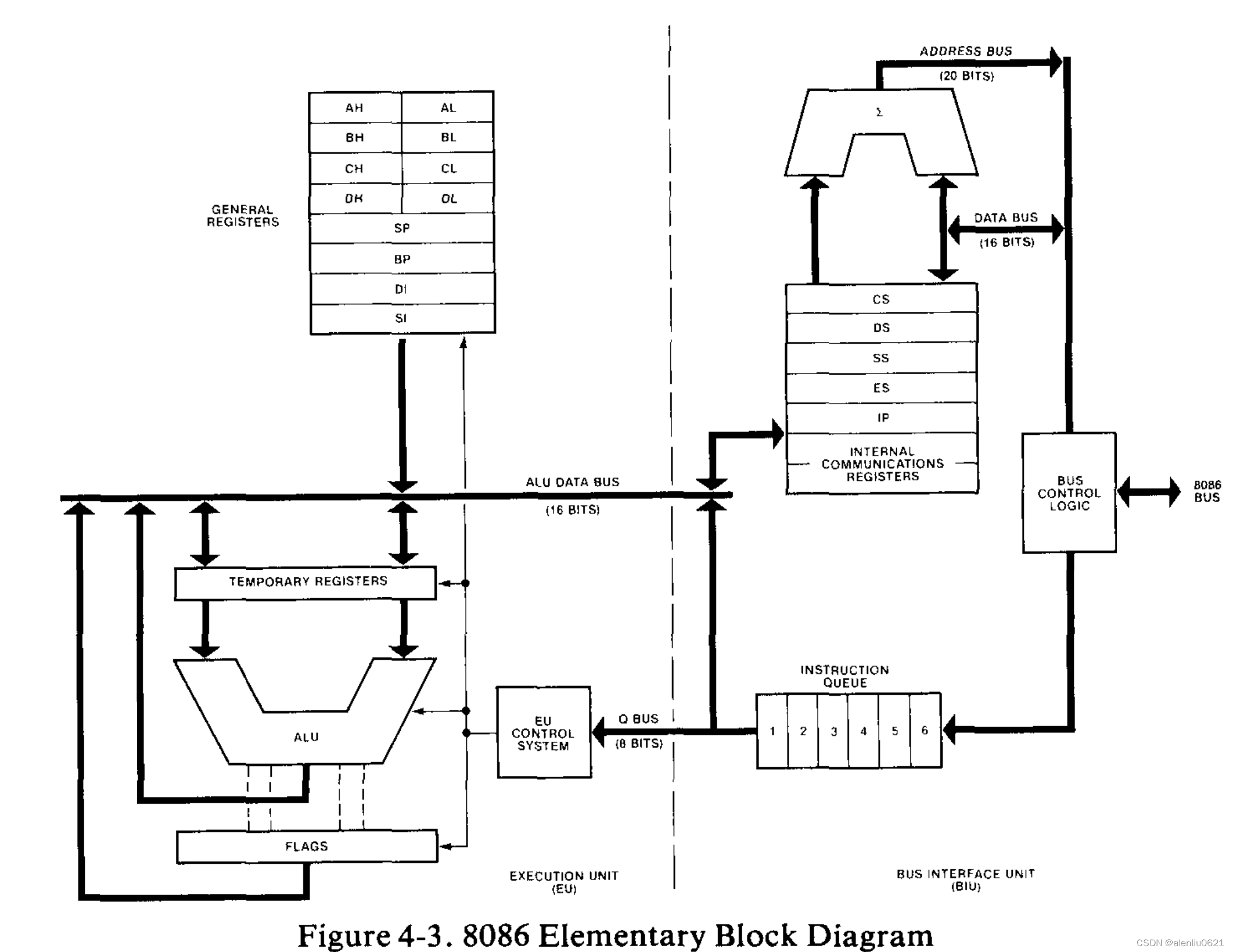
EU(执行单元)
EU 中的一个 16 位算术/逻辑单元 (ALU) 维护 CPU 状态和控制标志,并操纵通用寄存器和指令操作数。 EU 中的所有寄存器和数据通路都是 16 位宽的,用于快速内部传输。EU与系统总线(即“外面的世界”)没有任何联系。它从 BIU 维护的队列中获取指令。当指令需要访问内存或外围设备时,EU 会请求 BIU 获取或存储数据。EU 使用的所有地址都是 16 位宽。然而,BIU 执行地址重定位【段地址左移4位加上偏移地址】,使 EU 可以访问完整的1 M字节的内存空间。
BIU(总线接口单元)
BIU 为 EU 执行所有总线操作。数据在 CPU 和内存或 I/O 设备之间传输。
此外,在 EU 忙于执行指令期间,BIU 会“向前看”并从内存中获取更多指令【指令预取】。指令存储在称为指令流队列的内部 RAM 阵列中。 8086 队列最多可存放六个指令字节。 这些队列大小允许 BIU 在大多数情况下为 EU 提供预取的指令,而无需独占系统总线。
8088 BIU在指令队列中还剩余 1 字节空间并且没有来自 EU 的总线请求访问时才获取下一个字节指令。8086 BIU 的操作与此类似,只是它直到指令队列中还剩余 2 字节空间时才开始读取操作。
在大多数情况下,指令队列中至少包含指令流的一个字节,并且 EU 无需等待就可获取。队列中的指令是存储在紧邻且高于当前正在执行的指令的内存位置中的指令。也就是说,只要执行顺序进行,它们就是下一条要被执行的指令。如果 EU 执行一个指令时将控制转移到另一个位置,BIU 将重置队列,从新地址获取指令,立即将其传递给 EU,然后开始从新位置重新填充队列。此外,只要 EU 请求内存或 I/O 读取或写入,BIU 就会暂停获取指令。
小结一下
BIU:
- 包含 ES,CS,SS,DS 这4个段寄存器和 IP 寄存器,可以读取和修改这些寄存器
- 包含一个指令队列,可从内存获取指令放入队列
- 可以读写内存【可以向内存芯片发起读或写请求】
- 可以接收 EU 的请求并处理
EU:
- 包含 AX,CX,DX,BX,SP,BP,SI,DI 这 8 个16 位通用寄存器和 16 位的 EFLAGS 寄存器,可以读取和修改这些寄存器
- 从 BIU 获取指令【可以向 BIU 发起获取指令的请求】
- 可以向 BIU 发起读写内存的请求
- 可以向 BIU 发起读写 4 个段寄存器和 IP 寄存器的请求
- 可以将二进制格式的指令解码成 EU 可以识别的指令格式并执行指令
模拟内存
由于 BIU 要和内存打交道,先用代码来模拟下内存芯片。
简单地说,内存就是一个大数组。但是为了模拟它是一个芯片,且有与 BIU 的交互行为,自然地就可以把它实现为可以接收 BIU 请求的对象,请求和数据都通过 channel 发送:
type memoryOpType uint8
// 支持的操作
const (
// 读一个字节
memoryOpReadByte memoryOpType = iota
// 读一个字
memoryOpReadWord
// 写一个字节
memoryOpWriteByte
// 写一个字
memoryOpWriteWord
)
// 8086 CPU 地址总线为20位,最大支持1M内存
const maxMemorySize = 1 << 20
type Memory struct {
size uint32
memory []byte
// 与 BIU 的通信接口
CtrlBus chan memoryOpType
AddrBus chan uint32
DataBus chan uint16
}
func (m *Memory) Init(size uint32) {
if m.size != 0 {
log.Fatal("Memory reinit!")
}
if size > maxMemorySize {
log.Fatal("memory size exceeds max!")
}
m.memory = make([]byte, size)
m.size = size
m.CtrlBus = make(chan memoryOpType)
m.AddrBus = make(chan uint32)
m.DataBus = make(chan uint16)
// 内存的工作函数
go func() {
for op := range m.CtrlBus {
switch op {
case memoryOpReadByte:
addr := <-m.AddrBus
m.DataBus <- uint16(m.memory[addr])
case memoryOpReadWord:
addr := <-m.AddrBus
m.DataBus <- uint16(m.memory[addr]) | uint16(m.memory[addr+1])<<8
case memoryOpWriteByte:
addr := <-m.AddrBus
data := <-m.DataBus
m.memory[addr] = byte(data & 0xff)
case memoryOpWriteWord:
addr := <-m.AddrBus
data := <-m.DataBus
m.memory[addr] = byte(data)
m.memory[addr+1] = byte(data >> 8)
}
}
}()
}
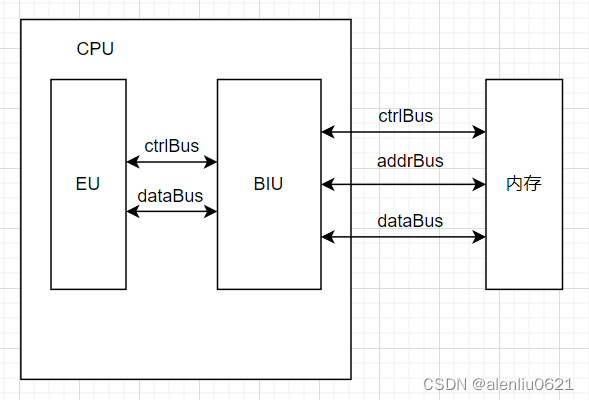
CtrlBus 表示控制总线,AddrBus 表示地址总线,DataBus 表示数据总线。这些总线与下文的 BIU “相连”。
从控制总线获取操作命令,从地址总线获取地址,当为读操作时,数据通过数据总线返回,当为写操作时,要写入的数据从数据总线获取。
内存对象的使用也很简单:
m := Memory{}
m.Init(1 << 20)
模拟 BIU
模拟 BIU 也是类似的,它主要包含一个指令队列,与内存芯片的通信接口,与 EU的通信接口:
// 表示无效的段前缀
const invalidSegPrefix uint8 = 0xff
// 段寄存器ID
const (
ES uint8 = iota
CS
SS
DS
)
// 指令队列大小
const instructionQueueSize = 6
const instructionQueueEmptySize = 2
type BIU struct {
es, cs, ss, ds uint16
ip uint16
// 指令队列
instructionQueue [instructionQueueSize]byte
// 指令队列剩余空间大小
nEmpty uint8
// 取指令索引
// 存指令索引
getIndex, putIndex uint8
// 与内存芯片的通信接口
ctrlBus chan memoryOpType
addrBus chan uint32
dataBus chan uint16
// 与EU的通信接口
InnerCtrlBus chan BIURequest
InnerDataBus chan uint16
// 虚拟IP指针
virtIP uint16
// 内存操作使用的段前缀
segPrefix uint8
}
再把它支持的操作定义出来:
type BIURequest uint16
// 支持的操作
const (
// 取指令
FetchInstruction BIURequest = iota
// 读内存
ReadMemory
// 读写段寄存器
ReadSegReg
WriteSegReg
// 读写IP寄存器
ReadIPReg
WriteIPReg
// 读写栈内存
ReadStackMemory
WriteStackMemory
ReadVariable
WriteVariable
// 改变段前缀
ChangeSegPrefix
// 未实现
// StringSource
// StringDestination
// BPAsBaseRegister
)
这些操作要满足 EU 的需求,比如需要有读写段寄存器和读写 IP 寄存器的操作,需要有读写内存的操作等等。
ReadStackMemory
WriteStackMemory
ReadVariable
WriteVariable
// 未实现
// StringSource
// StringDestination
// BPAsBaseRegister
这几种是手册中定义的不同的内存访问类型:

因为不同的内存访问操作使用不同的段寄存器和偏移地址【逻辑地址】。
比如读取指令使用的是 CS 段寄存器,偏移地址放在 IP 寄存器中。栈操作使用的 SS 寄存器,偏移地址放在 SP 寄存器中。普通的数据访问使用的 DS 段寄存器,偏移地址是 EU 传入的地址。
16 位段寄存器地址左移 4 位加上偏移地址就得到 20 位的物理地址。所以 BIU 在这里要根据访问类型计算物理地址。
我在实现时,偏移地址是由 EU 根据内存类型操作传入的。举例来说,EU 要执行栈操作时传入的偏移地址就是 SP 寄存器的值,BIU 并不关心偏移地址的来源,它只关心如果是栈操作,那么段寄存器就使用 SS。
读写内存的实现如下:
func (b *BIU) readMemoryByte(addr uint32) byte {
b.ctrlBus <- memoryOpReadByte
b.addrBus <- addr
return byte(<-b.dataBus)
}
func (b *BIU) readMemoryWord(addr uint32) uint16 {
b.ctrlBus <- memoryOpReadWord
b.addrBus <- addr
return <-b.dataBus
}
func (b *BIU) writeMemoryByte(addr uint32, data byte) {
b.ctrlBus <- memoryOpWriteByte
b.addrBus <- addr
b.dataBus <- uint16(data)
}
func (b *BIU) writeMemoryWord(addr uint32, data uint16) {
b.ctrlBus <- memoryOpWriteWord
b.addrBus <- addr
b.dataBus <- data
}
就是通过通信接口向内存芯片发起请求。
与取指令相关的几个函数实现如下:
// 清空指令队列
func (b *BIU) emptyInstructionQueue() {
b.nEmpty = instructionQueueSize
b.getIndex = 0
b.putIndex = 0
}
// 尝试预取指令
func (b *BIU) prefetchInstructions() {
for b.nEmpty >= instructionQueueEmptySize {
phyAddress := uint32(b.cs)<<4 + uint32(b.virtIP)
instruction := b.readMemoryByte(phyAddress)
b.instructionQueue[b.putIndex] = instruction
b.nEmpty--
b.putIndex++
if b.putIndex == instructionQueueSize {
b.putIndex = 0
}
// 虚拟IP指针加1
b.virtIP++
}
}
// 从指令队列取出一个字节的指令给EU
func (b *BIU) fetchOneInstruction() byte {
if b.nEmpty == instructionQueueSize {
return 0x0f // 未使用的指令
}
instruction := b.instructionQueue[b.getIndex]
b.nEmpty++
b.getIndex++
if b.getIndex == instructionQueueSize {
b.getIndex = 0
}
// 取得一个字节指令后,IP指针加1
b.ip++
return instruction
}
我在实现时 EU 从 BIU 获取的是一条指令中的 1 字节数据而不是完整的一条指令。因为 BIU 每次都是从内存读取 1 字节指令,BIU 做不到每次从内存读取一条完整的指令。 而 BIU 做指令解码的工作又很奇怪,所以我将指令的解码工作放在 EU 里实现。
BIU 的工作流程就是不停地:
- 尝试预取指令
- 处理来自EU的各种请求
实现如下:
func (b *BIU) run() {
if b.nEmpty == 0 {
log.Fatal("not init!!!")
}
go func() {
for {
// 预取指令
b.prefetchInstructions()
// 处理EU的请求
req := <-b.InnerCtrlBus
switch req {
// 取指令
case FetchInstruction:
b.InnerDataBus <- uint16(b.fetchOneInstruction())
// 读内存
case ReadMemory:
addrLow := <-b.InnerDataBus
addrHigh := <-b.InnerDataBus
size := <-b.InnerDataBus
phyAddr := uint32(addrHigh)<<16 | uint32(addrLow)
if size == 8 {
b.InnerDataBus <- uint16(b.readMemoryByte(phyAddr))
} else {
b.InnerDataBus <- b.readMemoryWord(phyAddr)
}
// 读段寄存器
case ReadSegReg:
reg := uint8(<-b.InnerDataBus)
switch reg {
case ES:
b.InnerDataBus <- b.es
case CS:
b.InnerDataBus <- b.cs
case SS:
b.InnerDataBus <- b.ss
case DS:
b.InnerDataBus <- b.ds
default:
log.Fatal("error")
}
// 读IP寄存器
case ReadIPReg:
b.InnerDataBus <- b.ip
// 写段寄存器
case WriteSegReg:
reg := uint8(<-b.InnerDataBus)
val := <-b.InnerDataBus
switch reg {
case ES:
b.es = val
case CS:
b.cs = val
// 先修改IP,再修改CS,可能从旧的代码段取了指令,所以需要清空指令队列
b.virtIP = b.ip
b.emptyInstructionQueue()
case SS:
b.ss = val
case DS:
b.ds = val
default:
log.Fatal("error")
}
// 写IP寄存器
case WriteIPReg:
val := <-b.InnerDataBus
b.ip = val
b.virtIP = val
b.emptyInstructionQueue()
fmt.Printf("change Ip to 0x%X\n", val)
// 读栈内存,读普通数据内存
case ReadStackMemory, ReadVariable:
offset := <-b.InnerDataBus
size := <-b.InnerDataBus
var phyAddress uint32
if req == ReadStackMemory {
phyAddress = uint32(b.ss)<<4 + uint32(offset)
} else {
//cs es ss
if b.segPrefix == invalidSegPrefix {
phyAddress = uint32(b.ds)<<4 + uint32(offset)
} else {
switch b.segPrefix {
case ES:
phyAddress = uint32(b.es)<<4 + uint32(offset)
case CS:
phyAddress = uint32(b.cs)<<4 + uint32(offset)
case SS:
phyAddress = uint32(b.ss)<<4 + uint32(offset)
case DS:
phyAddress = uint32(b.ds)<<4 + uint32(offset)
default:
log.Fatal("error")
}
}
}
if size == 8 {
b.InnerDataBus <- uint16(b.readMemoryByte(phyAddress))
} else {
b.InnerDataBus <- b.readMemoryWord(phyAddress)
}
if req == ReadVariable && b.segPrefix != invalidSegPrefix {
b.segPrefix = invalidSegPrefix
}
// 写栈内存,写普通数据内存
case WriteStackMemory, WriteVariable:
offset := <-b.InnerDataBus
size := <-b.InnerDataBus
val := <-b.InnerDataBus
var phyAddress uint32
if req == WriteStackMemory {
phyAddress = uint32(b.ss)<<4 + uint32(offset)
} else {
//cs es ss
if b.segPrefix == invalidSegPrefix {
phyAddress = uint32(b.ds)<<4 + uint32(offset)
} else {
switch b.segPrefix {
case ES:
phyAddress = uint32(b.es)<<4 + uint32(offset)
case CS:
phyAddress = uint32(b.cs)<<4 + uint32(offset)
case SS:
phyAddress = uint32(b.ss)<<4 + uint32(offset)
case DS:
phyAddress = uint32(b.ds)<<4 + uint32(offset)
default:
log.Fatal("error")
}
}
}
if size == 8 {
b.writeMemoryByte(phyAddress, byte(val))
} else {
b.writeMemoryWord(phyAddress, val)
}
if req == WriteVariable && b.segPrefix != invalidSegPrefix {
b.segPrefix = invalidSegPrefix
}
// case StringSource:
// phyAddress = uint32(b.ds<<4) + uint32(req.Offset)
// case StringDestination:
// phyAddress = uint32(b.es<<4) + uint32(req.Offset)
// case BPAsBaseRegister:
// phyAddress = uint32(b.ss<<4) + uint32(req.Offset)
// 改变段前缀
case ChangeSegPrefix:
if b.segPrefix != invalidSegPrefix {
log.Fatal("error: invalid ")
}
b.segPrefix = uint8(<-b.InnerDataBus)
default:
log.Fatal("erer")
}
}
}()
}
模拟 EU
模拟 EU 也是和模拟 BIU 类似,可用如下的结构体表示:
type EU struct {
// 8 个 16位通用寄存器
ax uint16
cx uint16
dx uint16
bx uint16
sp uint16
bp uint16
si uint16
di uint16
eflags uint16
//与 BIU 的通信接口
biuCtrl chan BIURequest
biuData chan uint16
// 当前正在执行的指令
currentInstruction byte
// 是否停止执行的标志位
stop bool
// 略去了与中断相关的字段
}
它定义了如下读写寄存器的方法:
// 16位通用寄存器的ID
const (
AL uint8 = iota
CL
DL
BL
AH
CH
DH
BH
)
// 8 位通用寄存器的ID
const (
AX uint8 = iota
CX
DX
BX
SP
BP
SI
DI
)
// 标志寄存器的各种标志位
const (
cfFlag uint8 = 0 //
pfFlag uint8 = 2 //
afFlag uint8 = 4
zfFlag uint8 = 6 //
sfFlag uint8 = 7 //
tfFlag uint8 = 8
ifFlag uint8 = 9
dfFlag uint8 = 10
ofFlag uint8 = 11 //
)
// 写16位通用寄存器
func (e *EU) writeReg16(reg uint8, value uint16) {
switch reg {
case AX:
e.ax = value
case CX:
e.cx = value
case DX:
e.dx = value
case BX:
e.bx = value
case SP:
e.sp = value
case BP:
e.bp = value
case SI:
e.si = value
case DI:
e.di = value
default:
log.Fatal()
}
}
// 读16位通用寄存器
func (e *EU) readReg16(reg uint8) uint16 {
var value uint16
switch reg {
case AX:
value = e.ax
case CX:
value = e.cx
case DX:
value = e.dx
case BX:
value = e.bx
case SP:
value = e.sp
case BP:
value = e.bp
case SI:
value = e.si
case DI:
value = e.di
default:
log.Fatal()
}
return value
}
// 写 8 位通用寄存器
func (e *EU) writeReg8(reg uint8, value uint8) {
switch reg {
case AL:
e.ax &= 0xff00
e.ax |= uint16(value)
case CL:
e.cx &= 0xff00
e.cx |= uint16(value)
case DL:
e.dx &= 0xff00
e.dx |= uint16(value)
case BL:
e.bx &= 0xff00
e.bx |= uint16(value)
case AH:
e.ax &= 0x00ff
e.ax |= uint16(value) << 8
case CH:
e.cx &= 0x00ff
e.cx |= uint16(value) << 8
case DH:
e.dx &= 0x00ff
e.dx |= uint16(value) << 8
case BH:
e.bx &= 0x00ff
e.bx |= uint16(value) << 8
default:
log.Fatal()
}
}
// 读 8 位通用寄存器
func (e *EU) readReg8(reg uint8) uint8 {
var value uint8
switch reg {
case AL:
value = uint8(e.ax)
case CL:
value = uint8(e.cx)
case DL:
value = uint8(e.dx)
case BL:
value = uint8(e.bx)
case AH:
value = uint8(e.ax >> 8)
case CH:
value = uint8(e.cx >> 8)
case DH:
value = uint8(e.dx >> 8)
case BH:
value = uint8(e.bx >> 8)
}
return value
}
// 设置标志寄存器的某一位
func (e *EU) writeEFLAGS(bitOffset uint8, value uint8) {
if value == 0 {
e.eflags &= ^uint16(1 << bitOffset)
} else {
e.eflags |= uint16(1 << bitOffset)
}
}
// 读取标志寄存器的某一位
func (e *EU) readEFLAGS(bitOffset uint8) uint8 {
value := uint8(e.eflags>>bitOffset) & 0x1
return value
}
定义了如下和 BIU 通信的方法【比如读写段寄存器,读写 IP 寄存器,读写内存等】:
func (e *EU) writeIP(val uint16) {
e.biuCtrl <- WriteIPReg
e.biuData <- val
}
func (e *EU) readIP() uint16 {
e.biuCtrl <- ReadIPReg
return <-e.biuData
}
func (e *EU) readSeg(reg uint8) uint16 {
e.biuCtrl <- ReadSegReg
e.biuData <- uint16(reg)
return <-e.biuData
}
func (e *EU) writeSeg(reg uint8, val uint16) {
e.biuCtrl <- WriteSegReg
e.biuData <- uint16(reg)
e.biuData <- val
}
func (e *EU) readMemoryWord(phyAddr uint32) uint16 {
e.biuCtrl <- ReadMemory
e.biuData <- uint16(phyAddr)
e.biuData <- uint16(phyAddr >> 16)
e.biuData <- 16
return <-e.biuData
}
func (e *EU) readDataMemmoryByte(effectiveAddr uint16) uint8 {
e.biuCtrl <- ReadVariable
e.biuData <- effectiveAddr
e.biuData <- 8
return uint8(<-e.biuData)
}
func (e *EU) readDataMemmoryWord(effectiveAddr uint16) uint16 {
e.biuCtrl <- ReadVariable
e.biuData <- effectiveAddr
e.biuData <- 16
return <-e.biuData
}
func (e *EU) writeDataMemmoryByte(effectiveAddr uint16, val uint8) {
e.biuCtrl <- WriteVariable
e.biuData <- effectiveAddr
e.biuData <- 8
e.biuData <- uint16(val)
}
func (e *EU) writeDataMemmoryWord(effectiveAddr uint16, val uint16) {
e.biuCtrl <- WriteVariable
e.biuData <- effectiveAddr
e.biuData <- 16
e.biuData <- val
}
func (e *EU) readStackMemory() uint16 {
e.biuCtrl <- ReadStackMemory
e.biuData <- e.sp
e.biuData <- 16
return <-e.biuData
}
func (e *EU) writeStackMemory(val uint16) {
e.biuCtrl <- WriteStackMemory
e.biuData <- e.sp
e.biuData <- 16
e.biuData <- val
}
func (e *EU) changeSegPrefix(newPrefix uint8) {
e.biuCtrl <- ChangeSegPrefix
e.biuData <- uint16(newPrefix)
}
定义了最关键的执行指令的方法:
func (e *EU) execute(instructions []byte) {
// 指令格式的第一字节表示指令类型
instruction := instructions[0]
e.currentInstruction = instruction
// 根据指令类型执行不同的操作
switch instruction {
case InstructionMov:
e.executeMov(instructions[1:])
case InstructionAdd, InstructionOr, InstructionAdc, InstructionSbb,
InstructionAnd, InstructionSub, InstructionXor, InstructionCmp:
e.executeAddEtc(instructions[1:])
case InstructionInc, InstructionDec, InstructionNot, InstructionNeg,
InstructionMul, InstructionImul, InstructionDiv, InstructionIdiv:
e.executeIncEtc(instructions[1:])
case InstructionSegPrefix:
e.executeSegPrefix(instructions[1:])
case InstructionPush:
e.executePush(instructions[1:])
case InstructionPop:
e.executePop(instructions[1:])
case InstructionJmp:
e.executeJmp(instructions[1:])
case InstructionCall:
e.executeCall(instructions[1:])
case InstructionRet:
e.executeRet(instructions[1:])
case InstructionLoop:
e.executeLoop(instructions[1:])
case InstructionInt:
e.executeInt(instructions[1:])
case InstructionNop:
e.executeNop(instructions[1:])
default:
log.Fatal("unsupported inssss---")
}
}
EU 的工作流程就是不停地从 BIU 获取指令执行,直到程序终止。
实现如下:
func (e *EU) run() {
var instructions []byte
for {
// 从BIU获取一个字节指令
e.biuCtrl <- FetchInstruction
instruction := byte(<-e.biuData)
// 拼接指令
instructions = append(instructions, instruction)
// 解码当前的指令字节序列
decodedInstructions := Decode(instructions)
// 当前是一条有效的指令
if decodedInstructions != nil {
// 执行指令
e.execute(decodedInstructions)
// 清空指令字节序列
instructions = instructions[:0]
// 如果要求程序终止,则退出循环
if e.stop {
e.stop = false
break
}
}
}
}
前面说过,一条指令通常包含多个字节,而从 BIU 获取的只是指令中的一个字节,所以需要拼接起来解码,看能否形成一条完整的指令!
模拟 CPU
模拟完 BIU 和 EU 之后,模拟 CPU 就很简单了:
type CPU struct {
eu EU
biu BIU
}
为了将程序写入内存,为它实现了如下读写内存的方法:
func (c *CPU) writeMemory(addr uint32, data []byte) {
for i, v := range data {
c.biu.writeMemoryByte(addr+uint32(i), v)
}
}
func (c *CPU) readMemory(addr uint32, data []byte) {
for i, _ := range data {
data[i] = c.biu.readMemoryByte(addr + uint32(i))
}
}
为了将它与内存芯片相连,实现了 ConnectMemory 方法:
func (c *CPU) ConnectMemory(m *Memory) {
c.biu.connectMemory(m)
}
它就是调用 BIU 的connectMemory方法,它实现如下:
func (b *BIU) connectMemory(m *Memory) {
b.ctrlBus = m.CtrlBus
b.addrBus = m.AddrBus
b.dataBus = m.DataBus
}
就是将 BIU 的控制总线、地址总线、数据总线与内存芯片的相连!
CPU 的初始化方法实现如下:
func (c *CPU) Init() {
c.biu.Init()
// 将 EU 的控制总线和 BIU 相连
c.eu.biuCtrl = c.biu.InnerCtrlBus
c.eu.biuData = c.biu.InnerDataBus
}
其中 BIU 的初始化方法实现如下:
func (b *BIU) Init() {
// 情况指令序列
b.emptyInstructionQueue()
// 设置段前缀为无效
b.segPrefix = invalidSegPrefix
// 创建控制总线和数据总线
b.InnerCtrlBus = make(chan BIURequest)
b.InnerDataBus = make(chan uint16)
}
在 CPU 初始化,并与内存相连后,它们之间的通信数据流如下:
CPU 的工作函数实现如下:
func (c *CPU) Run(cs, ip uint16, debug bool) {
// 让 BIU 开始工作
c.biu.run()
if debug {
c.eu.writeEFLAGS(tfFlag, 1)
}
// 设置CS和IP寄存器的值
c.eu.writeSeg(CS, cs)
c.eu.writeIP(ip)
// 让 EU 开始工作
c.eu.run()
}
再回头看上篇文章 main 函数里面的加载并执行程序这段代码就很容易明白了:
// 4. 初始化一个CPU和内存芯片
// 初始化一个内存芯片,大小为1M
m := Memory{}
m.Init(1 << 20)
// 初始化一个CPU
c := CPU{}
c.Init()
// 将CPU与内存相连
c.ConnectMemory(&m)
// 5. 将程序写入内存
// 计算出程序在内存中的起始地址
var phyAddr uint32 = uint32(cs)<<4 - programHeader.codeSegProgOffset
// 将程序加载到内存
c.writeMemory(phyAddr, program)
// 6. CPU 开始执行程序
// 第一个参数是CPU开始执行时CS寄存器的值,第二个参数是IP寄存器的值
c.Run(uint16(cs), uint16(programHeader.codeEntryProgOffset))
总结
本文介绍了怎样使用程序模拟 CPU 和内存,至此读者可以窥见 8086 虚拟机内部详细工作原理。 后续文章将介绍 EU 中最核心的部分——指令解码和执行的实现。


![有序表的应用:[Leetcode 327] 区间和的个数](https://img-blog.csdnimg.cn/c7eaf13dc11348c49d7c610f3ececa9d.jpeg)