哨兵集群
单节点的哨兵还是可能会发生故障,需要部署集群。
部署哨兵时,只需要下面的命令,那哨兵是如果互相发现的?
sentinel monitor <master-name> <ip> <redis-port> <quorum>
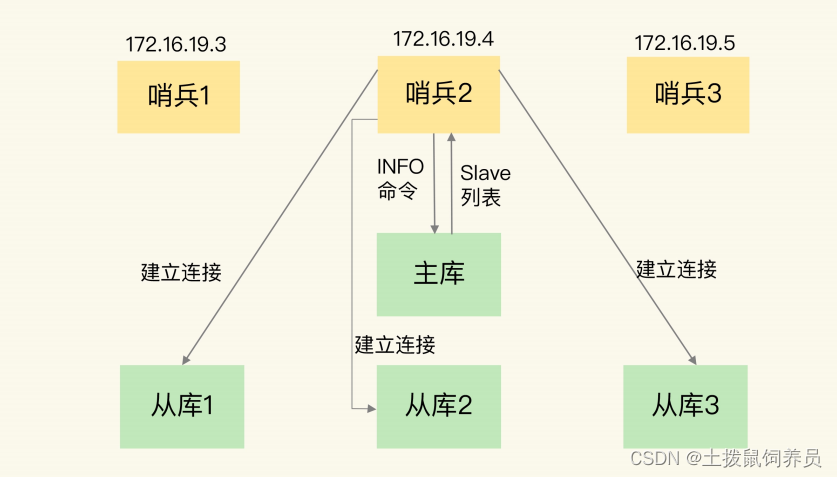
基于 pub/sub 机制的哨兵集群组成
- 哨兵和主库建立连接,可以在主库发布信息,也可以在主库订阅信息,这样可以互相知道信息
- redis只有订阅了同一频道的信息才能进行信息交换。
- 哨兵就是通过
__sentinel__:hello频道进行消息交换的。 - 哨兵通过对频道发布订阅消息就与主库建立了连接
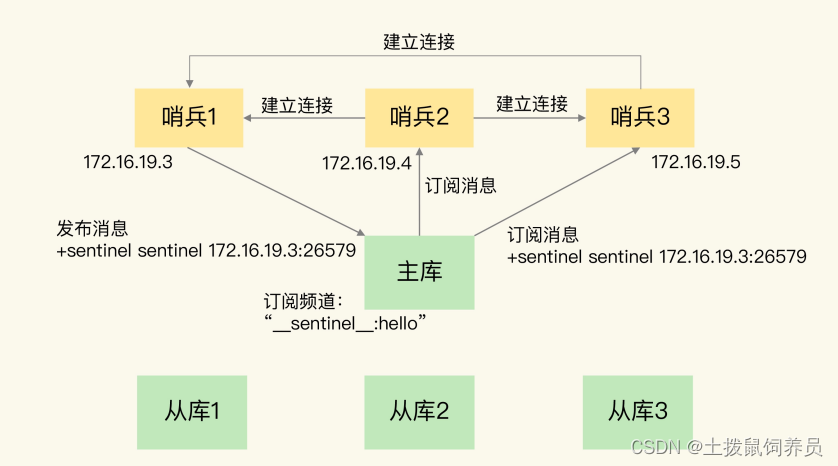
- 哨兵与从库建立连接是 哨兵向主库发送INFO命令来完成的,哨兵向主库发送命令,主库就会把从库列表发给哨兵,这样哨兵就可以与从库建立连接。
通过pub/sub,实现哨兵和客户端信息同步
客户端通过哨兵了解到切换的过程。 客户端从哨兵订阅消息。
- 客户端获取哨兵的配置文件后,可以获得哨兵的地址和端口,和哨兵建立连接,通过执行命令,获取不同事件。
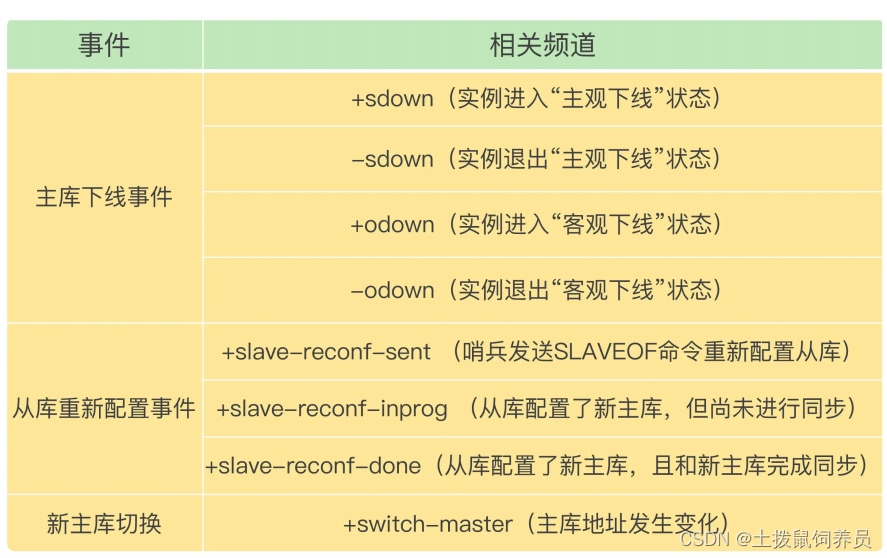
SUBSCRIBE +odown订阅所有实例客观下线事件。PSUBSCRIBE *订阅所有事件- 当哨兵选完主库之后,客户端会看见
switch-master事件:switch-master <master name> <oldip> <oldport> <newip> <newport>
选择什么哨兵执行主从切换
哨兵集群判断主库下线的过程
- 任何一个实例只要自身判断主库“主观下线”后,就会给其他实例发送 is-master-down-byaddr 命令。接着,其他实例会根据自己和主库的连接情况,做出 Y 或 N 的响应,Y 相当于赞成票,N 相当于反对票。
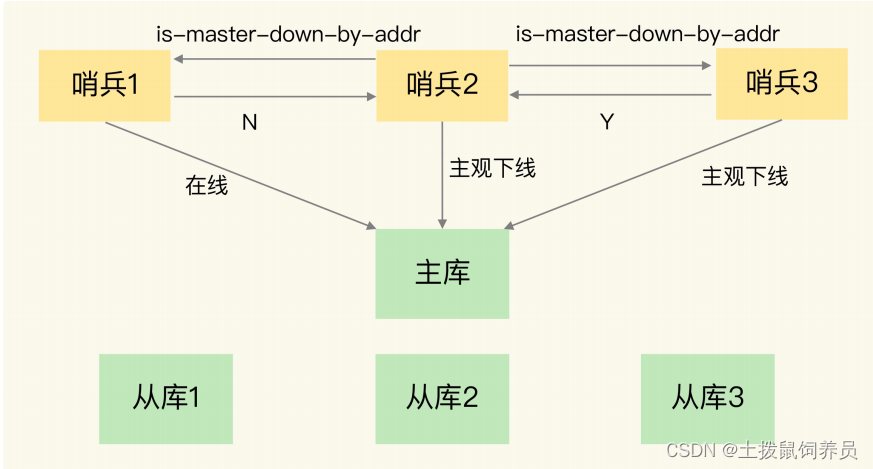
- 哨兵获得了仲裁需要的赞成票数后(配置的
quorum设定),可以标记主库 “客观下线” - 这个哨兵向其他哨兵发送命令,表明想要自己来执行主从切换,(Leader选举)
- 想要成为哨兵需要满足2个条件(第一,拿到半数以上的赞成票;第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。)
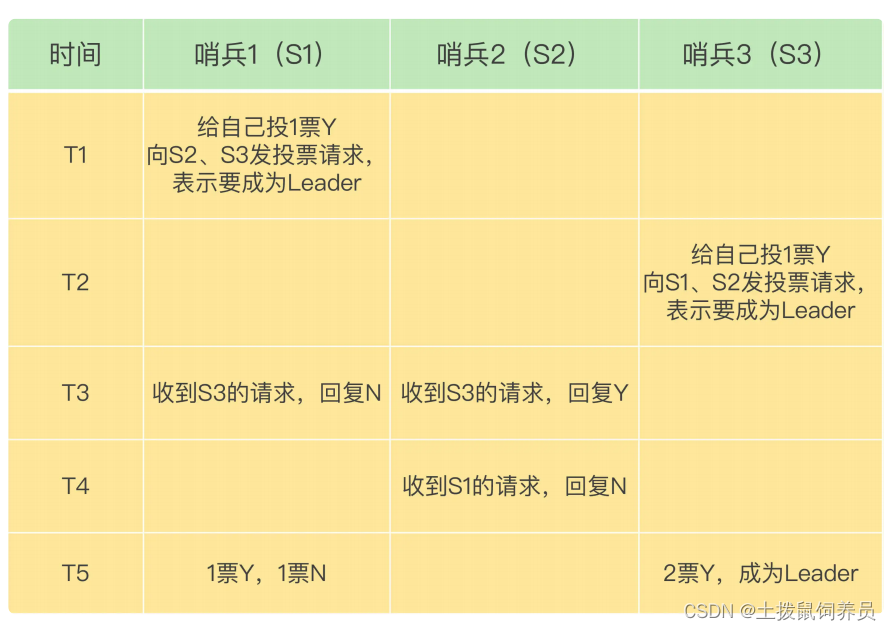
- 如果没有成功选举,会在哨兵故障转移超时时间的 2 倍,重新进行选举。
- 哨兵如果没有给自己投票,就会把票投给第一个给它发送投票请求的哨兵。后续再有投
票请求来,哨兵就拒接投票了。
需要注意的是,如果哨兵集群只有 2 个实例,此时,一个哨兵要想成为 Leader,必须获得 2票,而不是 1 票。所以,如果有个哨兵挂掉了,那么,此时的集群是无法进行主从库切换的。因此,通常我们至少会配置 3 个哨兵实例。
要保证所有哨兵实例的配置是一致的,尤其是主观下线的判断值 down-after-milliseconds。不然哨兵集群一直没有对有故障的主库形成共识,也就没有及时切换主库,最终的结果就是集群服务不稳定。
- 假设有一个 Redis 集群,是“一主四从”,同时配置了包含 5 个哨兵实例的集群,quorum
值设为 2。在运行过程中,如果有 3 个哨兵实例都发生故障了,此时,Redis 主库如果有故
障,还能正确地判断主库“客观下线”吗?如果可以的话,还能进行主从库自动切换吗?
- 大于等于quorum的值 2, 所以可以判断 主观下线。
- 不能完成主从切换,哨兵需要达到(5/2+1)的票,但是2个哨兵,没有达到要求
- 此外,哨兵实例是不是越多越好呢,如果同时调大 down-after-milliseconds 值,对减少误判
是不是也有好处呢?
- 不是越多越好,哨兵越多,通讯越多,选举时间可能边长,切换主从时间变久
- 适当调大down-after-milliseconds值,可以减低误判,但是也可能对业务的影响会增加,各有利弊
redis切片
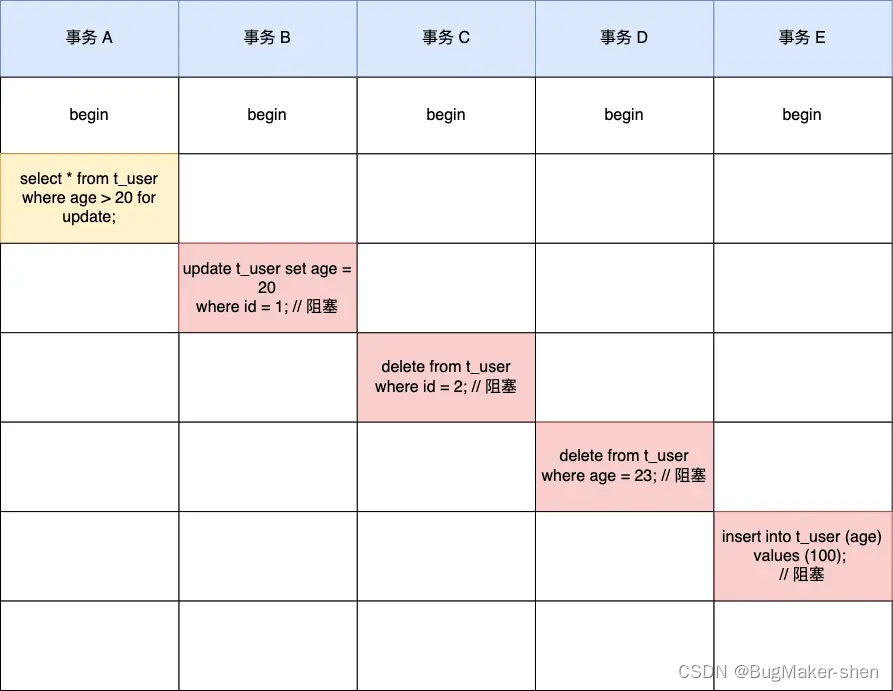
增加单机的物理内存,简单,但是内存大,主线程fork直接阻塞了。
redis切片,复杂,可以保存大量数据,对主线程阻塞小
-
Redis Cluster 方案采用哈希槽(Hash Slot,接下来我会直接称之为 Slot),来处理数据和实例之间的映射关系。一个切片集群有16384个哈希槽,键值对根据key,映射哈希槽
-
映射过程:根据key的CRC16算法 计算16bit值, 16bit值对16384取模,一个模数代表一个哈希槽。
-
在部署Redis Cluster时,使用cluter create创建集群,redis会自动把槽分布到实例上。
-
也可以使用 cluster meet 命令手动建立实例间的连接,形成集群,再使用cluster addslots 命令,指定每个实例上的哈希槽个数。
-
在手动分配哈希槽时,需要把 16384 个槽都分配完,否则Redis 集群无法正常工作。

-
集群刚建立的时候,实例只知道自己分配了哪些哈希槽,不知道其他实例的哈希槽信息。
-
redis实例会把自己的哈希槽信息发送给其他实例,完成哈希信息的扩散,当实例直接相互链接,每个实例就有哈希槽的映射信息了
-
客户端收到哈希槽的信息后,会缓存到本地,客户端请求键值对时,会计算哈希槽,给对应实例发送请求
-
但是集群中,实例可能会增删,实例间可以互相传递信息,客户端无法感知变化。redis cluster 提供了重定向机制(客户端给实例发送读写操作时,没有对应的数据会给新实例发送操作)
GET hello:key
(error)MOVED 13320 172.16.19.5:6379
(如果这个实例上并没有这个键值对映射的哈希槽,那么,这个实例就会给客户端返回下面的 MOVED 命令响应结果,这个结果中就包含了新实例的访问地址。)
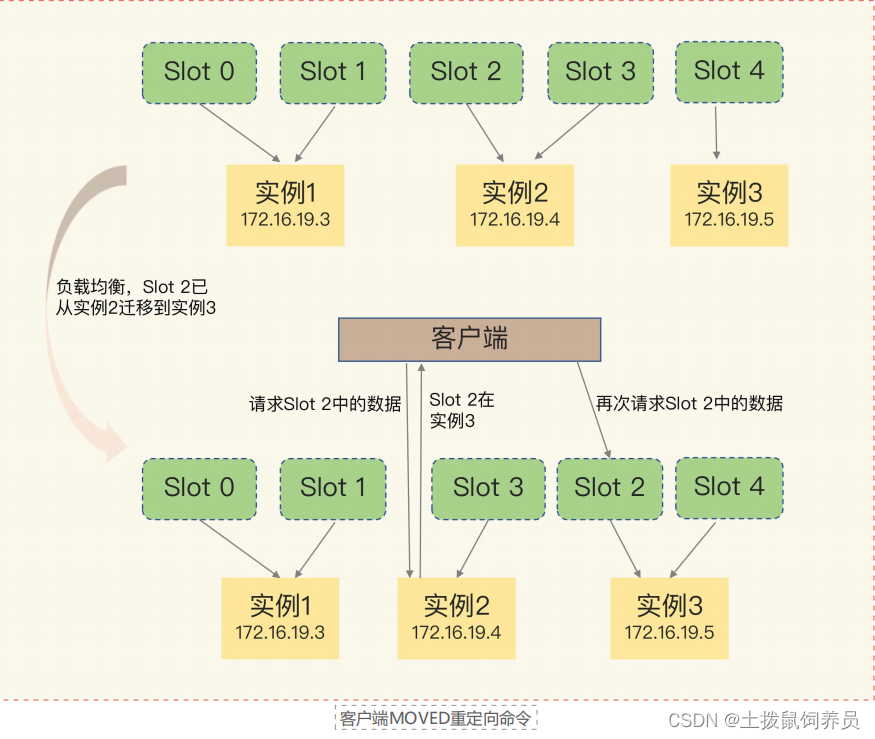
- 还可能出现一种情况,由于Slot2数据多,像slot2请求的时候,还有部分数据没有迁移完成,客户端会受到ASK报错
GET hello:key
(error)ASK 13320 172.16.19.5:6379
- ASK 命令表示两层含义:第一,表明 Slot 数据还在迁移中;第二,ASK 命令把客户端所请求数据的最新实例地址返回给客户端,此时,客户端需要给实例 3 发送 ASKING 命令,然后再发送操作命令。
- 和 MOVED 命令不同,ASK 命令并不会更新客户端缓存的哈希槽分配信息。
Redis Cluster不采用把key直接映射到实例的方式,而采用哈希槽的方式原因:
- key数量无法预估,key映射会很大。
- redis cluster 客户端与服务端直连,如果key不在这个节点上,节点需要纠正错误节点,需要交换路由表,如果保存对应关系,交换的信息会很大。
- 当集群扩容,缩容时,需要修改对应的映射关系。
- 通过哈希槽,key通过hash计算,只需要关系槽,通过让槽找到对应节点,让映射变的小
1.Redis 什么时候做 rehash?
装载因子 = entry数 / 哈希桶个数
出发rehash的条件
- 装载因子>=1 ,同时 哈希表被允许进行rehash(在RDB和AOF时,禁止rehash)
- 装载因子>= 5,立马进行rehash
如果装载因子<1 , 或者>1但是<5(同时实例在生成RDB和AOF)不会进行rehash
2. 采用渐进式 hash 时,如果实例暂时没有收到新请求,是不是就不做 rehash 了?
redis会进行定时任务,rehash被触发后,没有新请求,也会定时rehash,每次执行不会超过1ms
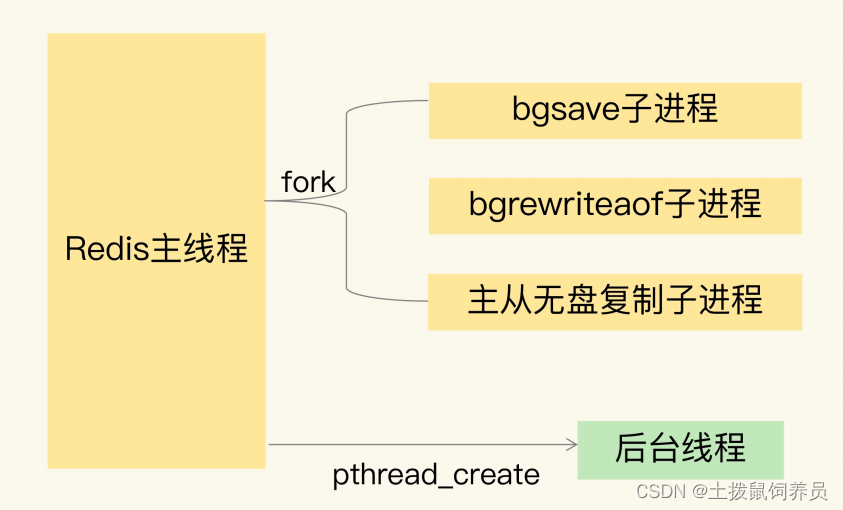
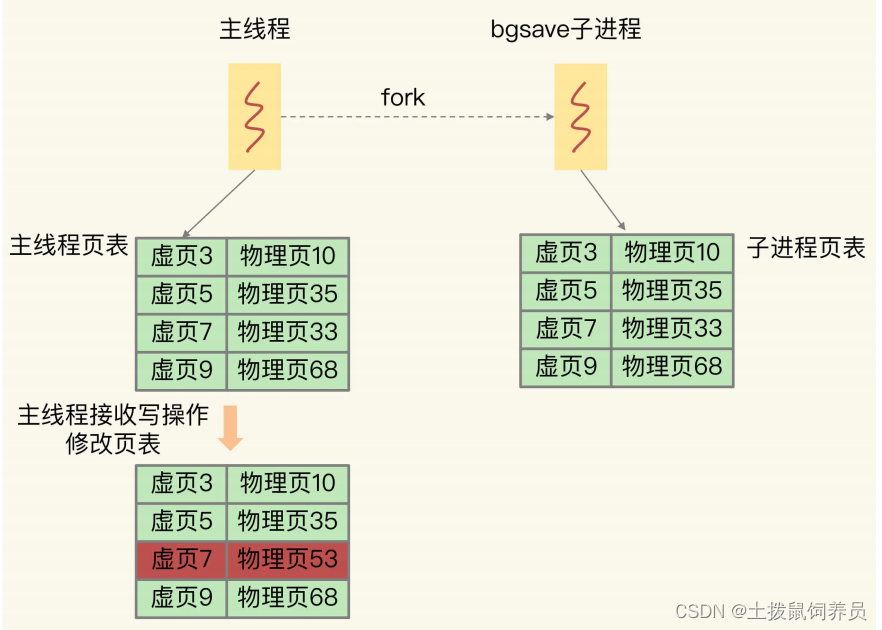
bgsave 子进程复制主线程的页表以后,假如主线程需要修改虚页 7 里的数据,那么,主线程就需要新分配一个物理页(假设是物理页 53),然后把修改后的虚页 7 里的数据写到物理页53 上,而虚页 7 里原来的数据仍然保存在物理页 33 上。这个时候,虚页 7 到物理页 33 的映射关系,仍然保留在 bgsave 子进程中。所以,bgsave 子进程可以无误地把虚页 7 的原始数据写入 RDB 文件。
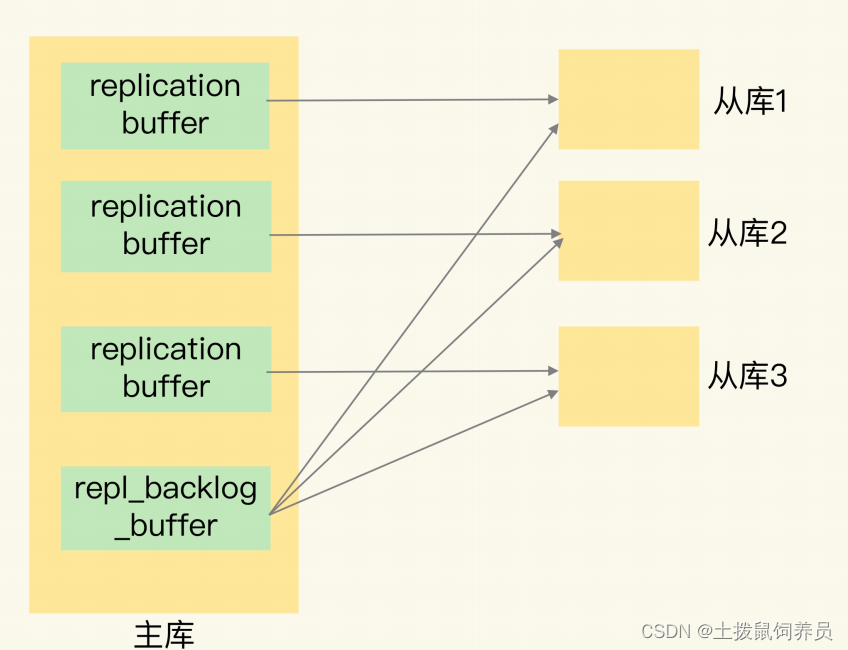
replication buffer 和 repl_backlog_buffer 的区别
- replication buffer 是主从库在进行全量复制时,主库上用于和从库连接的客户端的 buffer,而 repl_backlog_buffer 是为了支持从库增量复制,主库上用于持续保存写操作的一块专用 buffer。
- Redis 主从库在进行复制时,当主库要把全量复制期间的写操作命令发给从库时,主库会先创建一个客户端,用来连接从库,然后通过这个客户端,把写操作命令发给从库。在内存中,主库上的客户端就会对应一个 buffer,这个 buffer 就被称为 replication buffer。Redis 通过client_buffer 配置项来控制这个 buffer 的大小。主库会给每个从库建立一个客户端,所以replication buffer 不是共享的,而是每个从库都有一个对应的客户端。
- repl_backlog_buffer 是一块专用 buffer,在 Redis 服务器启动后,开始一直接收写操作命令,这是所有从库共享的。主库和从库会各自记录自己的复制进度,所以,不同的从库在进行恢复时,会把自己的复制进度(slave_repl_offset)发给主库,主库就可以和它独立同步。


![有序表的应用:[Leetcode 327] 区间和的个数](https://img-blog.csdnimg.cn/c7eaf13dc11348c49d7c610f3ececa9d.jpeg)