【Redis 高级】- 持久化 - RDB
👑什么是持久化呢?
- 那当然是够持久呀,这个持久如果在你不主动去删除的情况下,它就一直存在的。
🎷那么这有什么用呢?
-
举个栗子:我们在用 PowerPoint 在写价值 2 个亿的 PPT ,要求明天一大早就要去展示,今天加班到凌晨都必须搞出来,表面很开心,内心在奔腾的你接受了这个,老板的强行建议。
加班到了凌晨 2 点终于搞完了,正准备休息一会,突然不小心把电源线一脚踢掉了,你颤抖的手点击了一下电源开机键,当屏幕的 win 界面加载出来后,整个人到傻了。桌面干净的只剩下了桌面,这个时候你的内心已经完全奔溃了,想着自己当时,如果保存到文件夹中,就不会出现这样的问题了。一时间你受不了自己的这种行为,自己扇了自己一巴掌,哎!不疼~,原来是在做梦呀。
赶紧从梦里醒来,才发现原来自己的已经把文件,保存到了文件夹了呀。
通过上面的例子,可以看到 Ctrl+S 的重要性了吧,其实哈,对于我们的 Redis 也是可以进行 Ctrl+S 的,只是方式有些许的不同而已。但目的都是一样 ,PPT 进行保存,是将内存中的数据保存到磁盘中,而对于 Redis 而言,也是将内存中的数据保存到磁盘中。
这就是所谓的持久化,其实目的就是为了提高数据的抗风险能力。
🎸Redis 的持久化都是怎么进行处理的呢?-
-
哎,对于一个数据要将其中内存保存到磁盘中,首先能想到的是那种方式呢?
当然是最简单粗暴的,直接将数据的本身进行保存呀,就相当于从内存中复制一份一模一样的数据,直接写到磁盘中呀。
是呢,确实是这样,我们的 Redis 中的一种持久化的策略中,就用到了上述所猜想的一种理念,直接暴力的保存数据即可。
这种方式有个名字叫做 RDB(保存的是数据),有点原汁原味的感觉赖
-
emmm,那有没有其他的什么方式呢?
哎,这个还真有,我们每一次操作的时候,是不是后台都会生成一个操作的记录结果呀,对咯,这个操作的记录结果其实就是我们常常说的 日志 ,既然我们的日志中记录了,我们每一次的操作的过程,那我们可不可以想办法,在 Redis 启动的时候,将日志中的所有的操作都读取出来,然后将所有的指令都执行一遍,这样就可以保证,我们的所有的数据都会刷新到我们的内存中呢?
是的没错,这样的方式其实就是 AOF (保存的操作的过程)
RDB 的启动方式:
- ♈ save 手动执行一次保存
RDB 启动方式 – save 指令的相关配置
- 设置本地数据库的文件名,默认为 dump.rdb ,通常设置为 dump-端口号.rdb
dbfilename filename
-
设置存储 .rdb 文件路径,通常设置为存储空间较大的目录,目录名为 data
dir path
-
设置存储至本地数据库时是否数据压缩,默认为 yes ,设置为 no ,节省 CPU 的运行时间,但存储文件变大
rdbcomperession yes|no
-
设置读写文件过程中是否进行 RDB 格式校验,默认 yes ,设置为 no,节约读写 10% 时间消耗,单存存在数据损坏的风险
rdbchecksum yes|no
bind 192.168.10.101 port 6379 logfile "6379.log" dir /redis/data dbfilename "dump-6379.rdb"在每一次执行完毕所有的命名之后,执行 save 指令,就会自动的将数据压缩,存储到 dir 指定的目录下,在每一次的开机之后,会自动的加载数据到 Redis 当中。
RDB启动方式 – save 执行的工作原理
-
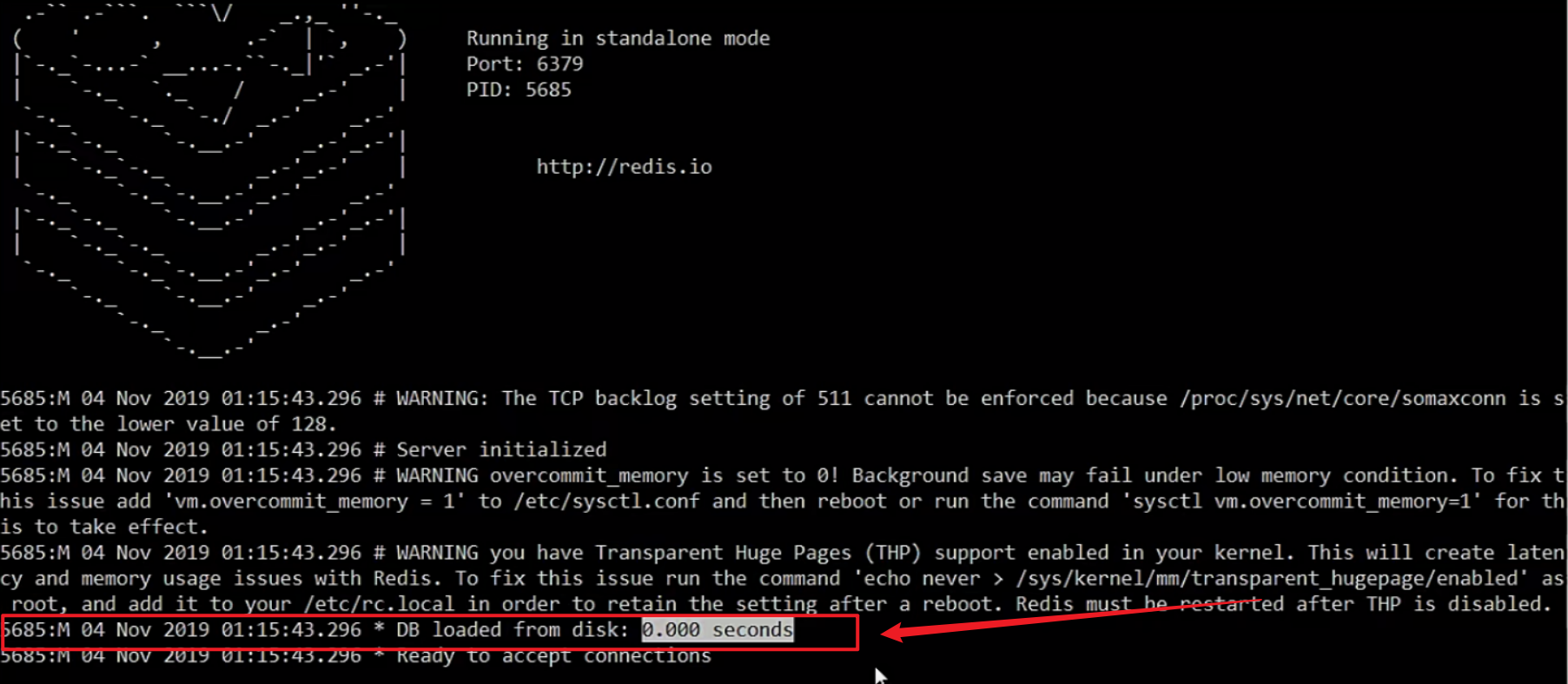
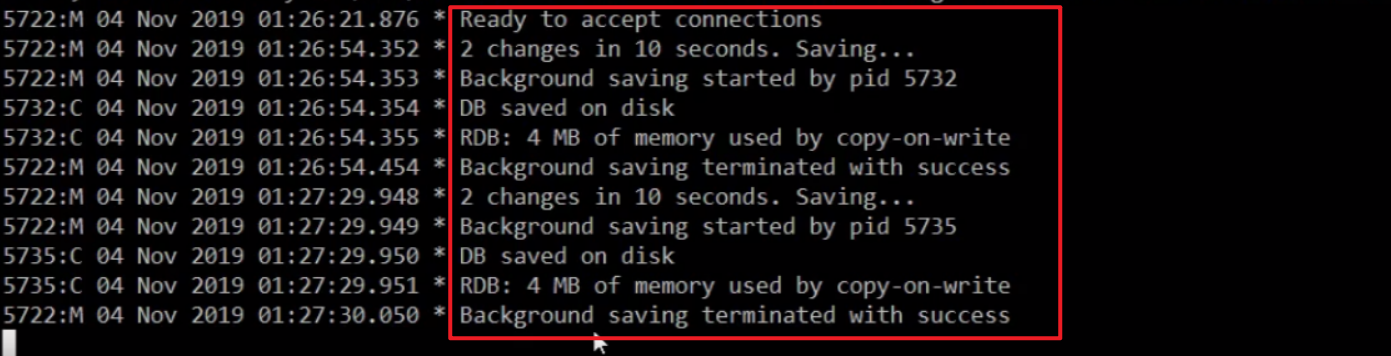
在上面的我们可以看到,当我们执行 save 指令后,Redis 有一个数据压缩并保存的时间。
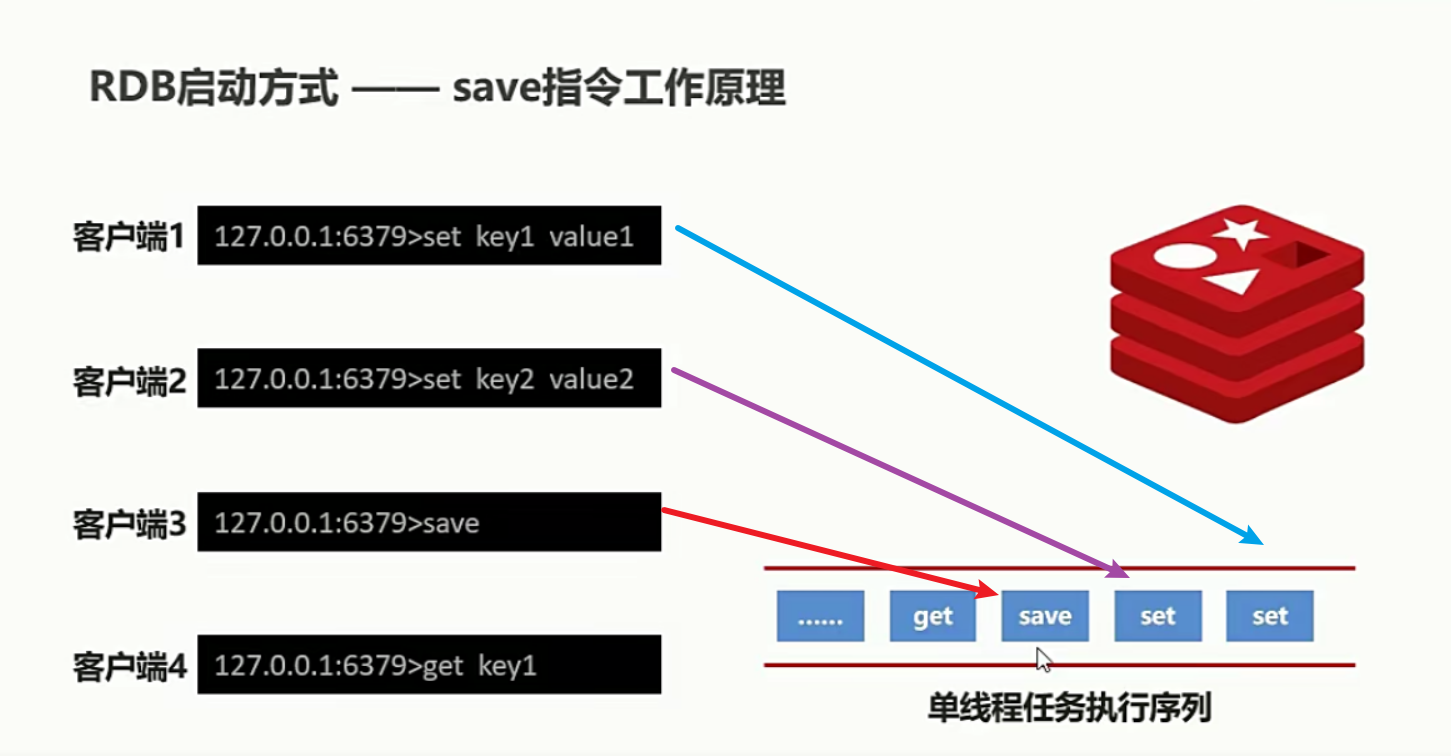
有与 Redis 是一个单线程的数据库,所以当我们执行 save 指令的时候,如果说此时我们的数量量是比较大的,那么在执行任务的队列中就会出现阻塞的状态,导致后的获取数据的 get 执行,一直处于等待,知道 save 指令执行完毕。
🏹 那么对于如果数据库过大,单线程执行的而效率会变低那么有没有解决的办法呢?
-
手动启动后台保存操作,但不是立即执行
bgsave
RDB启动方式 – bgsave 指令的相关配置
-
后台存储过程当中如果出现错误现象,是否停止保存操作,默认 yes
stop-writes-on-bgsave-error yes|no
-
其他
dbfilename filename
dir path
rdbcopression yes
rdbchecksum yes|no
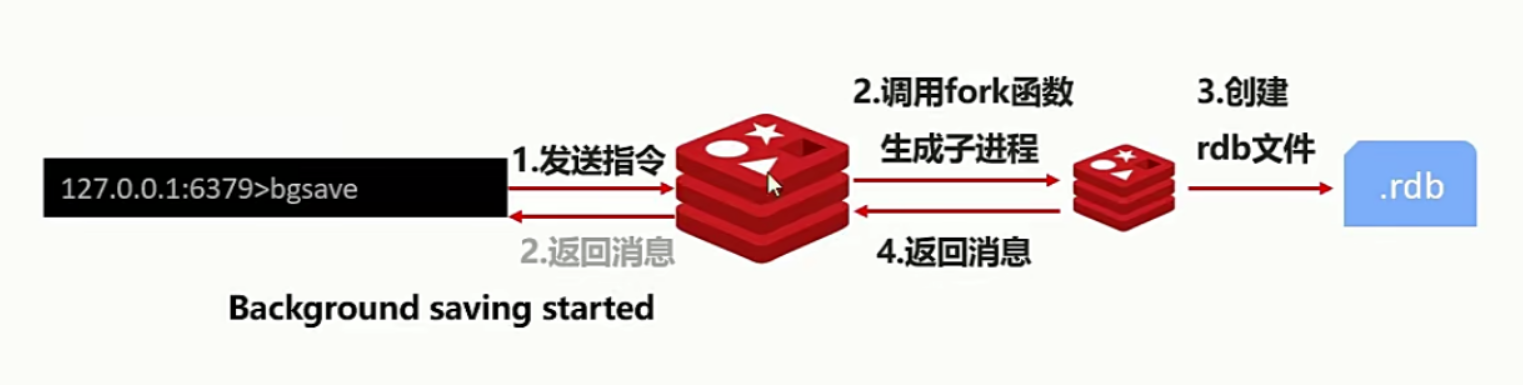

bgseve 的执行原理,其实就是后台开启了一个子线程,而子线程负责对我们的文件进行生成,然后将保存成功的消息,返回给我们的主进程并展示。
RDB启动方式 – 自动持久化
- 设置自动持久化的条件,满足限定时间范围内 key 变化的次数,当达到指定时进行持久化
save second changes
- 参数
second: 监控的时间范围
changes: 监控时间范围内 key 的变化量
- 示例
save 900 1
save 300 10
save 60 10000
自动持久化的原理
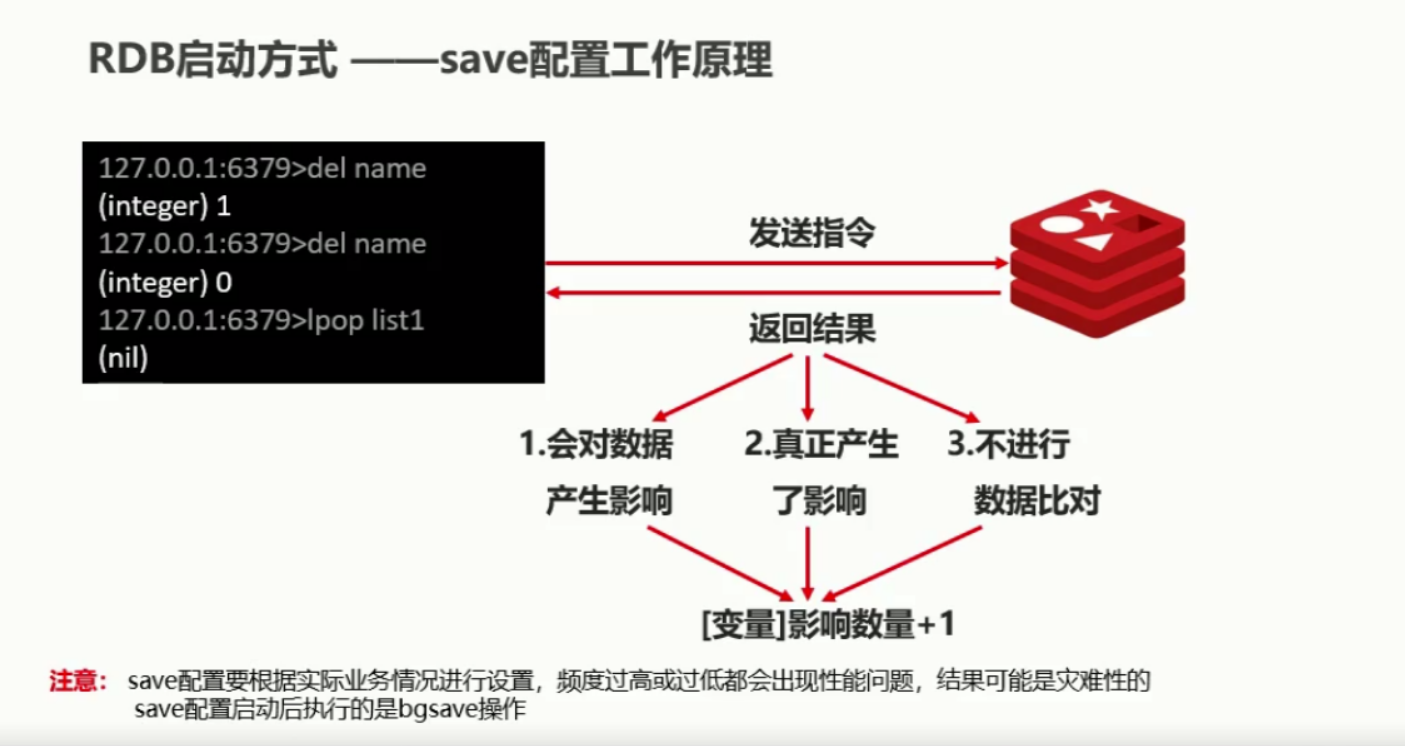
在我们执行每一条命令的时候,首先会对执行的命令进行判断,如果说一条命令满足了
1、操作会对数据产生影响 (执行了 del 操作,但执行失败)
2、真正产生了影响 (执行了 del 操作,执行成功)
3、是否进行数据上的对比 (该数据删除没有什么影响,但 set 的操作会有影响)
只有满足了以上三点,那么就会将影响的数量 +1
注意:save 配置要根据实际的业务情况而进行设置,如果你设置的过高,或者过低可能都会造成,业务上性能的影响。
👾 其实对于 save 的自动执行,最终执行的也是 bgsave 的操作,只是将原来的手动,变为了自动。
RDB 三种启动方式的对比
| 方式 | save指令 | bgsave指令 |
|---|---|---|
| 读写 | 同步 | 异步 |
| 阻塞客户端指令 | 是 | 否 |
| 额外内存消耗 | 否 | 是 |
| 启动新进程 | 否 | 是 |
RDB 优缺点
优点
- RDB是一个紧凑压缩的二进制文件,存储效率较高
- RDB内部存储的是redis在某个时间点的数据快照,非常适合用于数据备份,全量复制等场景
- RDB恢复数据的速度要比AOF快很多
- 应用:服务器中每X小时执行bgsave备份,并将RDB文件拷贝到远程机器中,用于灾难恢复。
缺点
- RDB方式无论是执行指令还是利用配置,无法做到实时持久化,具有较大的可能性丢失数据
- bgsave指令每次运行要执行fork操作创建子进程,要牺牲掉一些性能
- Redis的众多版本中未进行RDB文件格式的版本统一,有可能出现各版本服务之间数据格式无法兼容现象