One Fuzzing Strategy to Rule Them All

文章目录
- One Fuzzing Strategy to Rule Them All
- 相关链接
- 概述
- 背景
- 实验测试
- RQ1:
- RQ2
- 相关工作总结
- 最后
相关链接
One Fuzzing Strategy to Rule Them All
参考链接
概述
在本文中作者提出了对变异策略havoc的研究,通过调查在不同模糊测试器上havoc的实际执行时间与边覆盖的关系、以及havoc在不同模糊测试器下执行相同时间后边覆盖的差异,作者提出只要给havoc足够的执行时间,就能带来更高的边覆盖,同时也会降低不同模糊器之间的边覆盖差异。同时作者测试了stack size ,以及不同的变异策略(单元变异和块变异)对havoc性能的影响,并基于此提出了一个多臂老虎机模型。
背景
在进行漏洞挖掘中,模糊测试已经成为了一种主流的漏洞挖掘工具。而在此期间出现的很多fuzzer都使用了一种havoc的随机搜索机制,以提高代码的覆盖率。
然而,作者发现,在这些使用了havoc的模糊器中,大部分采用的都是havoc的默认设置,基于此,带着havoc是否还能在fuzzer中表现出更大的潜能这一问题,作者进行了本文的实验研究。
基于覆盖的模糊测试过程如下:
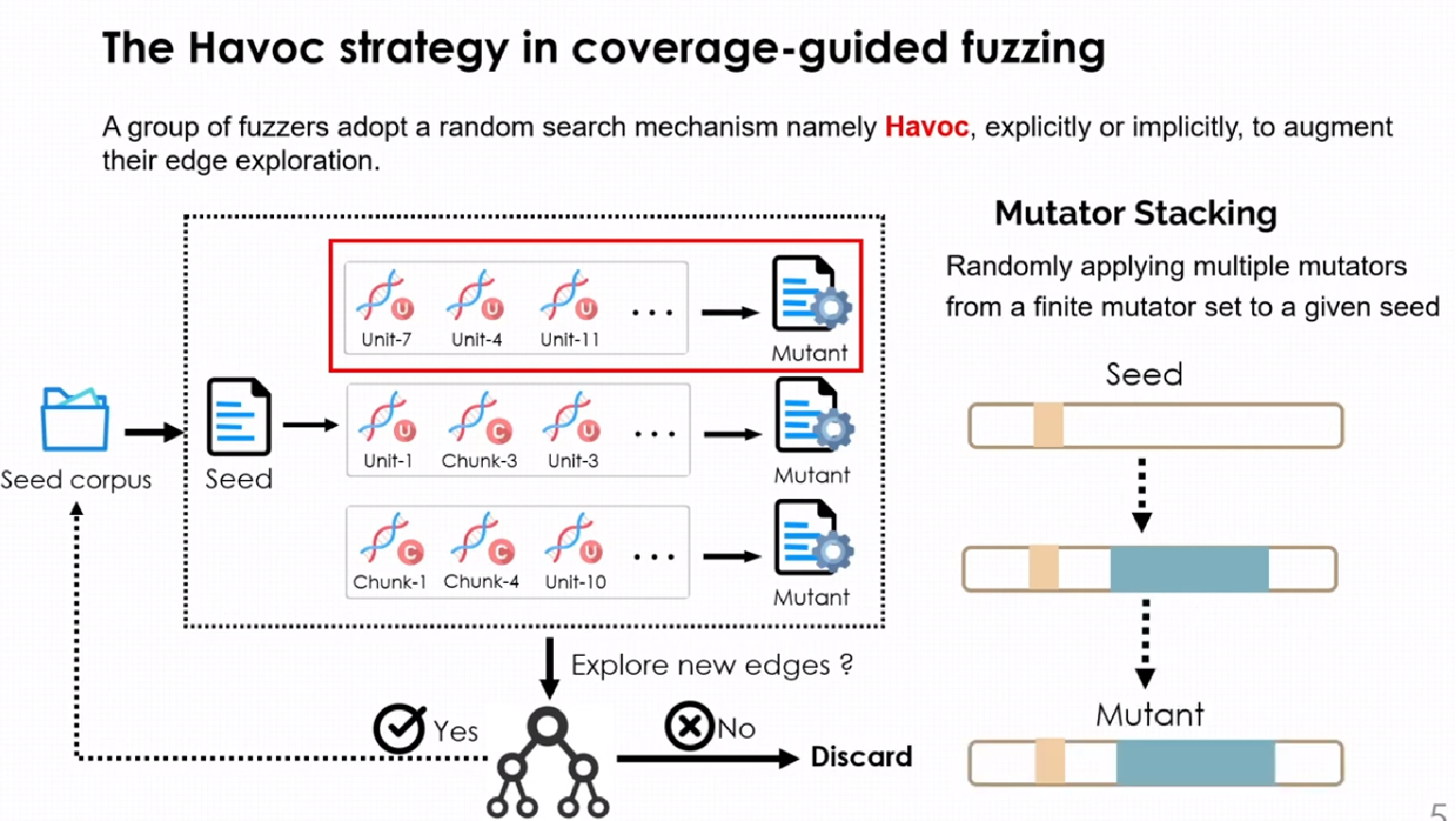
模糊测试器会从语料库中选定一个种子并传递给havov进行变异,havoc的变异由变异次数和编译器叠加次数决定。havoc会根据种子的实时信息决定种子的变异次数,即模糊器需要执行多少次havoc操作。确定havoc的变异次数后,在每次变异之前havoc还需要确定一个变异器叠加次数,并根据该次数从变异策略中随机选择变异方法进行叠加,havoc的变异策略如下所示:
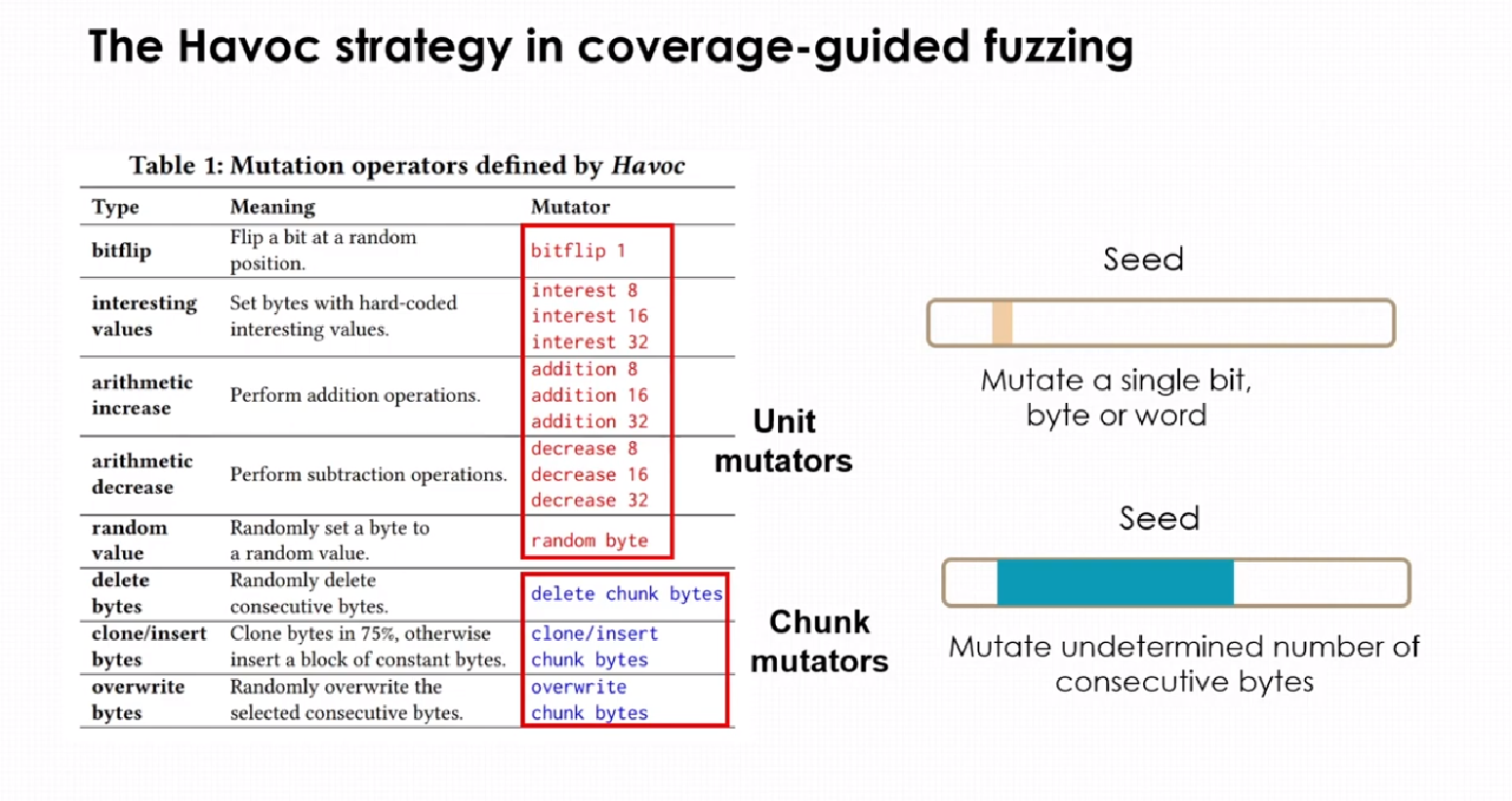
其中红色字体部分为单元变异,表示编译单个字节或单词,而蓝色部分则表示块变异,变异非确定性数量的字节。havoc同时是随机选择变异策略叠加在一起最后生成一个新的种子。
在将havoc集成到模糊器上时,不同的fuzzer之间也存在一定的差别,主要有两种集成方式,顺序执行和多线程并行的方式,其执行过程如下:
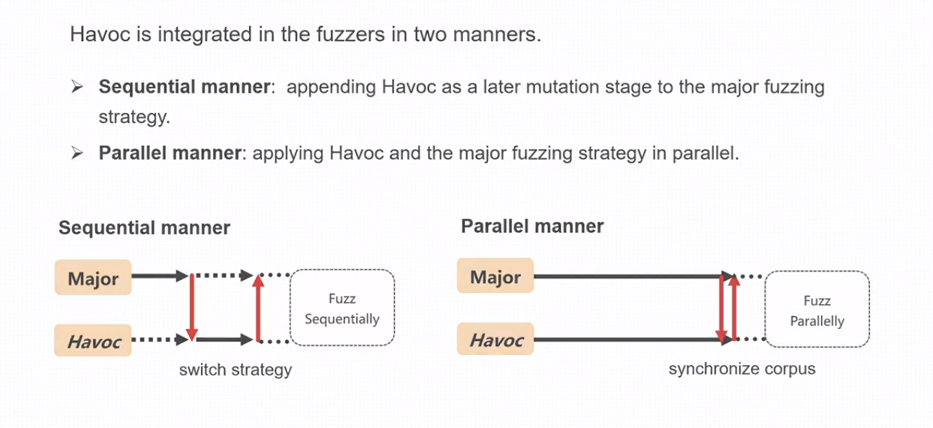
在顺序执行行为中,fuzzer的其他编译策略和havoc的变异策略交替执行,而在并行行为中,则存在多个线程,并存在单独的线程来实现havoc变异。
为了压榨havoc的性能,同时也为了使得实验更加科学准确,作者在挑选模糊器时,优先选择了已经发表在顶会上且代码已经开源的fuzzer,包括AFL,AFL++,MOPT,FairFuzz,QSYM。同时,为了验证未使用havoc的fuzzer在集成了havoc后性能是否能有所提升,作者又挑选了两个未使用havoc策略但是能将havoc集成到模糊器上的fuzzer,包括Neuzz和MTFuzz。为了设置对照组,作者还增加了一个没有集成到模糊器上的havoc,记为Pure Havoc。
在挑选测试样本时,作者优先挑选了以上七个fuzzer都覆盖的benchmark,同时,作者还考虑到了代码量的覆盖范围和程序的功能,挑选了以下几个benchmark。

实验测试
在对havoc做测试前作者提到了以下两个问题:
- 使用 Havoc的默认设置机制在不同的模糊器上性能如何?
- 在修改了havoc的参数设置后havoc在不同模糊器上的表现会怎样呢?
带着这两个问题,作者进行了以下实验,为了保证实验的可靠性,作者执行了五轮测试,每轮测试执行24小时,取平均值作为最后的测试结果。
RQ1:
如下图所示,original表示在默认havoc设置下不同fuzzer的边覆盖效果,Major则是集成了havoc的模糊器在禁用了havoc功能后的表现,integration则是对于未使用havoc的模糊器集成了havoc以后的边覆盖表现效果。
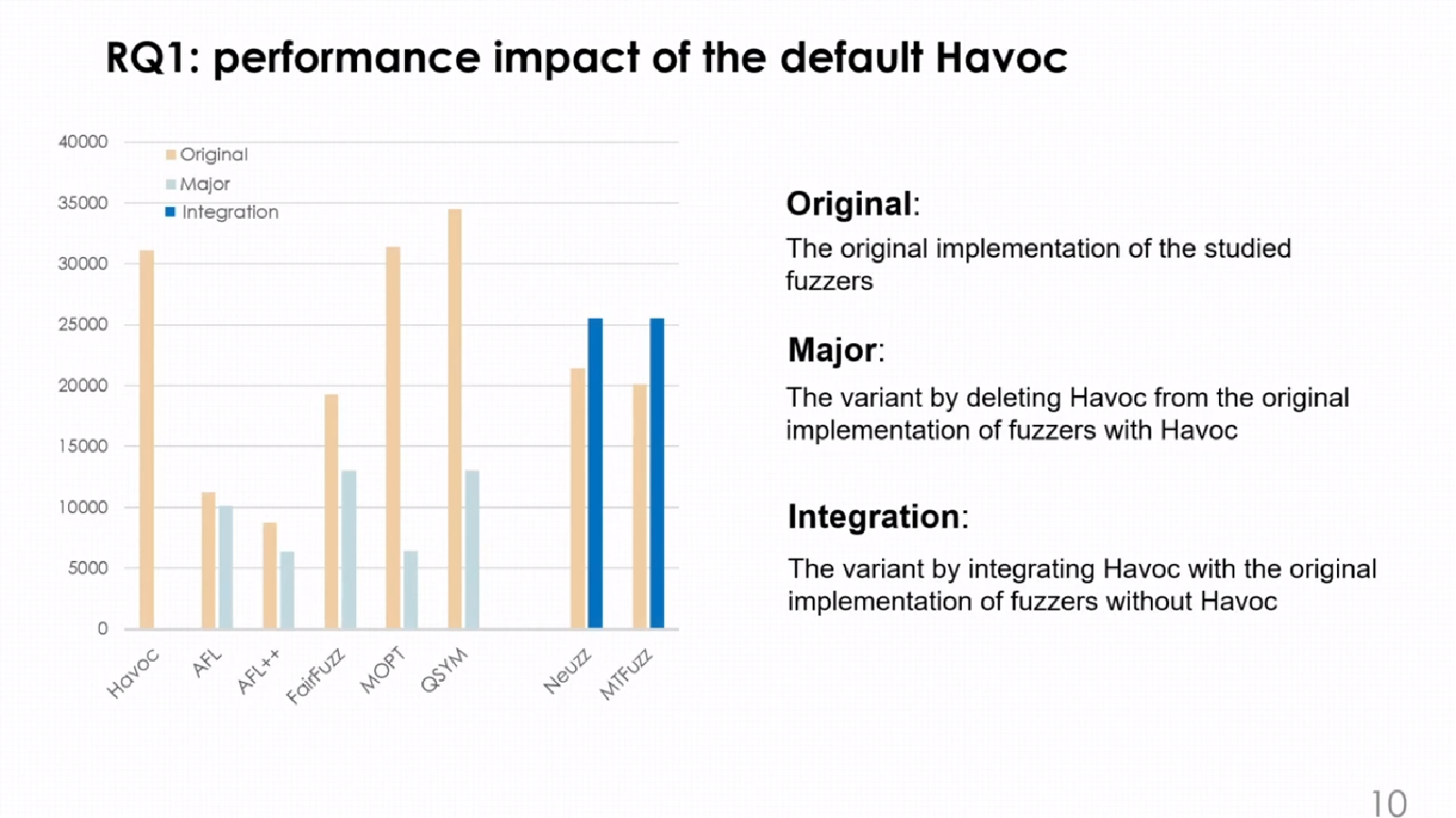
禁用了havoc以后,MOPT和QSYM的的边覆盖影响最大,分别下降了79.4%和62.2%。而使用了havoc以后,Neuzz和MTFuzz的性能分别提高了19.3%和26.6%。基于此,作者得出了第一个结论:
-
结论一
使用默认设置的havoc就能在很大程度上提高边覆盖
接下来作者测试了havoc在每个fuzzer中的实际执行时间,如下图所示:

红色框部分表示Pure havoc在仅仅使用一个种子时的表现,带来的边覆盖比AFL高出177%,比AFL++高出257%,比Neuzz高出45%,可以达到和MTFuzz和QSYM差不多的性能。基于此,作者提出了以下结论
-
结论二
Havoc 是一个非常有效的工具,仅仅给havoc一个种子就能带来超过已有的一些fuzzer的边覆盖率
-
结论三
通过对比各个模糊器中havoc的实际执行时间和带来的边覆盖,可以发现,在一个模糊器中,给havoc足够的执行时间,将可以得到更好的边覆盖结果
RQ2
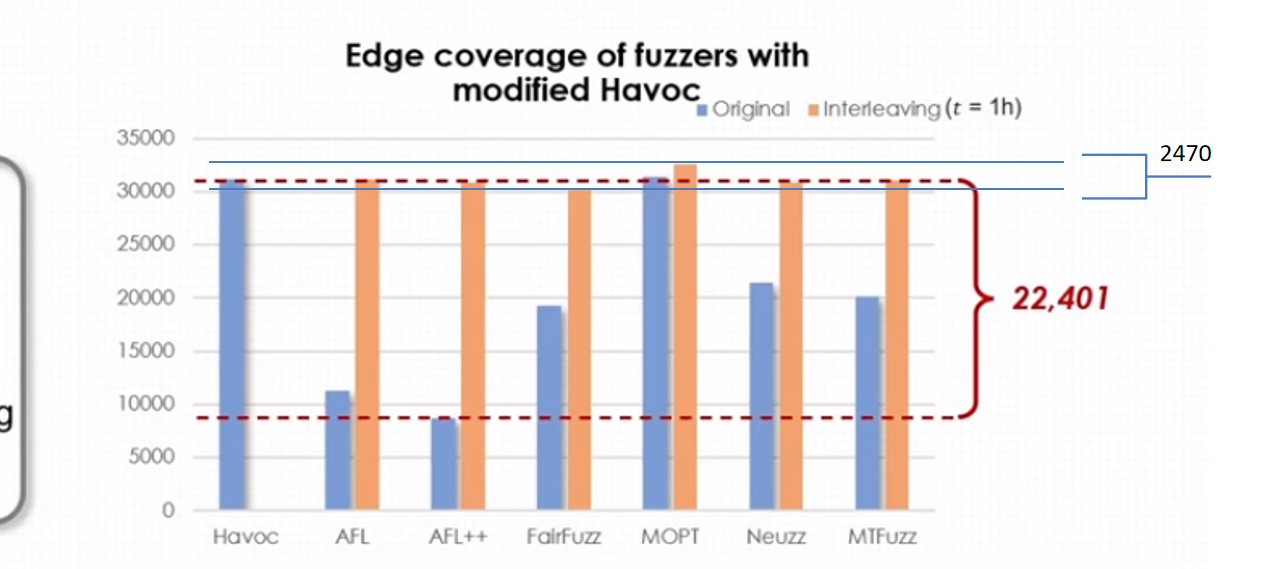
为了了解havoc在不同的参数设置下在不同的fuzzer中的实际表现效果,作者引入了socket来控制havoc的实际执行时间,其中havoc每次迭代中执行1小时和使用havoc的默认设置情况对比如下图所示:
-
通过执行havoc足够时间后,可以看到不同fuzzer在每次迭代中执行1小时的havoc后边覆盖差距只有2470,基于此作者得出结论三:
给havoc充足的执行时间将降低各个fuzzer之间性能的差异
接下来作者测试了AFL在每次迭代中havoc分别执行1小时,2小时,4小时和12小时的情况:

-
结论五
只要能给havoc足够的执行时间,在每次迭代中分配给havoc的时间对边覆盖的性能影响并不大
接下来作者还测试了将havoc等几个模糊策略并行执行的方式,看是否能更大限度提高fuzzer的性能,其测试结果如下:
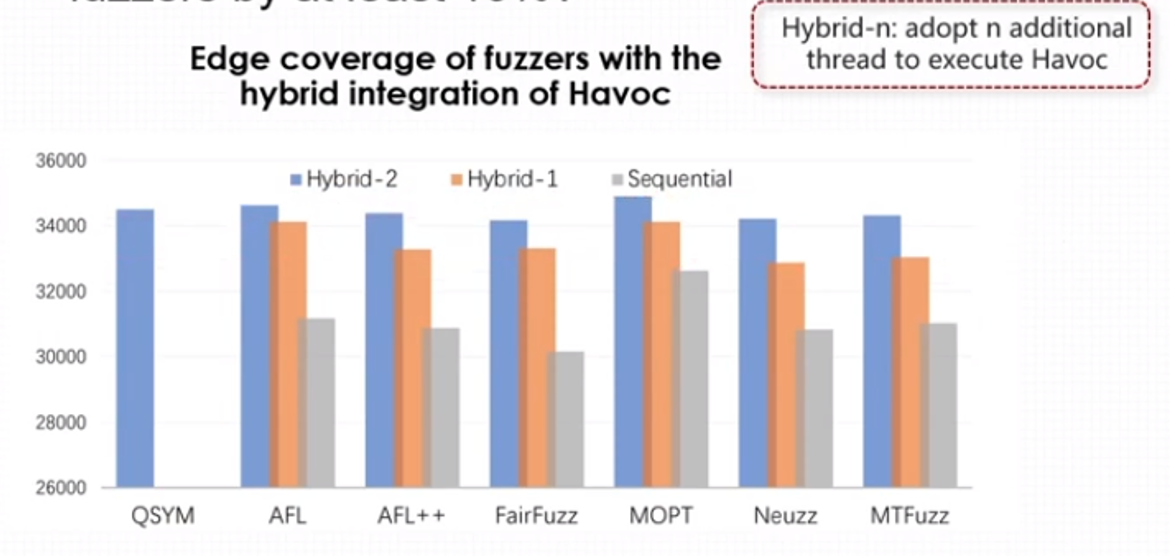
Sequential保证使用的是修改后的havoc,保证havoc的执行时间在一轮测试中能达到12小时,Hybrid-2和Hybrid-3中的havoc执行时间为24小时。
-
结论六
给予havoc更多的计算资源虽然能减少程序的执行时间,但性价比并不高
通过以上测试作者已经得出结论,只要给havoc足够的执行时间,不同fuzzer之间的性能差异并不明显,那这个fuzzer的边覆盖相似度到底有多高呢,为了验证这个问题,作者引入了一个参数Jaccard Distance来计算不同fuzzer之间边覆盖的不相似度,其比较结果如下:
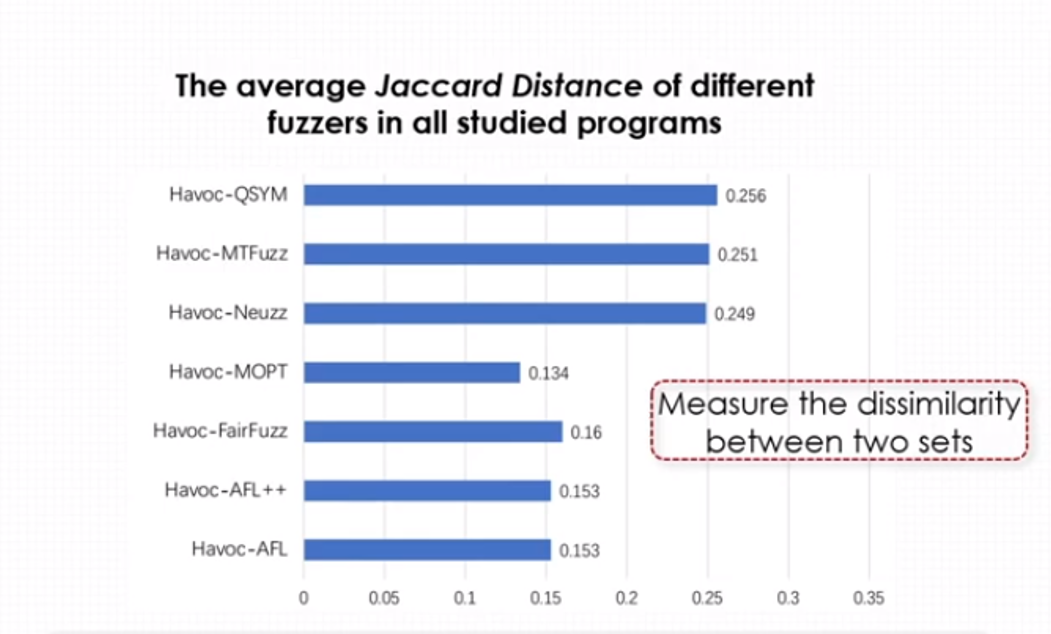
通过对以上结果进行分析可以发现四个fuzzer的不相似度极低,而另外的三个fuzzer不相似度高一点的原因作者分析认为是由于它们还采用了符号执行或神经网络的模糊测试方法导致的,因此作者得出以下结论:
-
结论七
使用havoc在不同的模糊测试器中依然会发现大量相似的边,而如果使用基于符号执行或神经网络指导的havoc则能更好的实现havoc
但仅仅使用边覆盖这一维度来对havoc的性能进行测试并不全面,因此作者对fuzzer中havoc发现的unique crashes进行测试,测试结果如下:

基于以上表格作者得出如下结论:
-
结论八
Havoc在发现潜在的程序漏洞中依然发挥着重要作用
接下来,作者还测试了使用不同的编译器叠加次数(stacking size)和使用不同的变异方法(单元变异和块变异)对Havoc的影响,实验直接在havoc上进行,stacking size的值为2的n次幂,最高位128(AFL支持的最大值)测试结果如下:

通过以上比较可以发现,Stacking size,单元变异或块变异在不同程序中的表现效果并不相同,而它们的实际性能取决于不同的程序,基于此,作者提出了以stacking size 和变异方法为臂,建立一个多臂老虎机模型,记为HavocMAB,其代码模型和设计框架如下所示:


如上图所示,作者建立以一个两层的多臂老虎机,一层表示stack size,存在7个臂,值分别为2,4, 8,…128。Mutator Type则有两个臂,表示选择单元变异或块变异,作者使用了已经被广泛使用的UCB1-Tuned算法来解决多臂老虎机问题,算法如下:
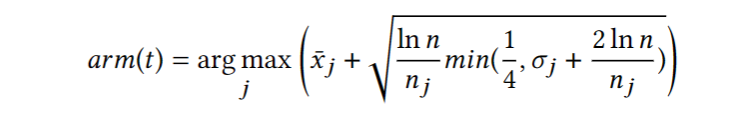
对于给定的时间t,x-j 表示armj 到时间t获取的reward的平均值,n表示多臂老虎机的总执行数,nj 表示armj 执行的次数,o-j 表示样本的变化情况。使用多臂老虎机模型后多个程序的平均边覆盖性能如下所示:


其中Havoc3MAB 表示使用3个线程并行执行的情况,以和同样使用了三个线程并行执行的QSYM对比,可以发现使用了多臂老虎机模型后Havoc的性能提高了11.1%,而和同样使用三个线程的QSYM相比,Havoc3MAB 性能提高了9%。
相关工作总结
在本文中作者的贡献如下:
- 研究了havoc在真实世界中的程序的实际性能
- 发现对于所有的fuzzer来说,只要给havoc足够的执行时间都可以提高边覆盖同时发现更多的crash
- 在技术层面上,作者提出了一个基于多臂老虎机的havoc模型
最后
以上为阅读这篇论文的笔记,然而由于本人水平有限,若文中存在一些技术问题说明错误,欢迎评论区留言更正!