1. 背景
公司需要迁移一个老 spark 项目,之前是消费阿里 LogStore 中的实时数据,处理之后将结果落库。使用的是 spark streaming,batch 时间为 2 分钟。迁移后,需要将 LogStore 切换为 kafka,涉及到了对代码的改动。公司的 kafka 上游生产者发送数据,由于细节的设计需要,生产者开启了事务,以确保数据准且一次的写入 kafka。
2. 遇到的问题
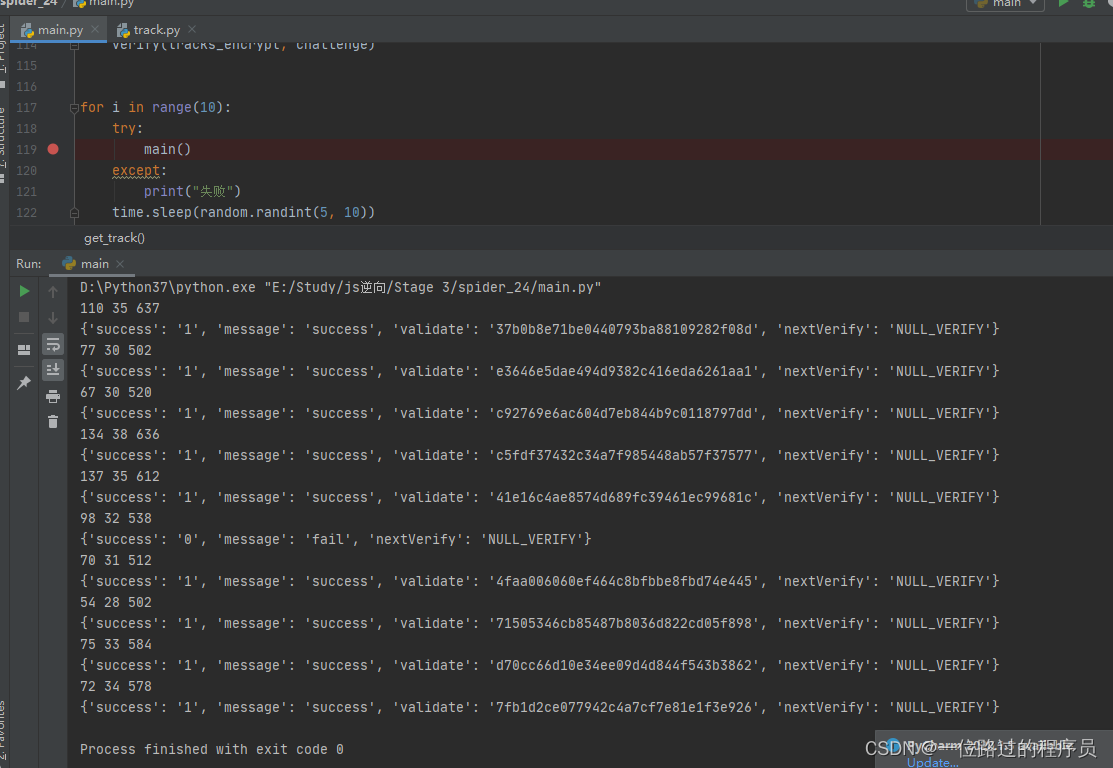
新项目重构完成之后进行上线,线上运行时发现,每批次数据处理,连接 kafka 代码,每次都要执行很长很长时间,而且经常执行超时,然后数据处理也停止了,具体截图如下:
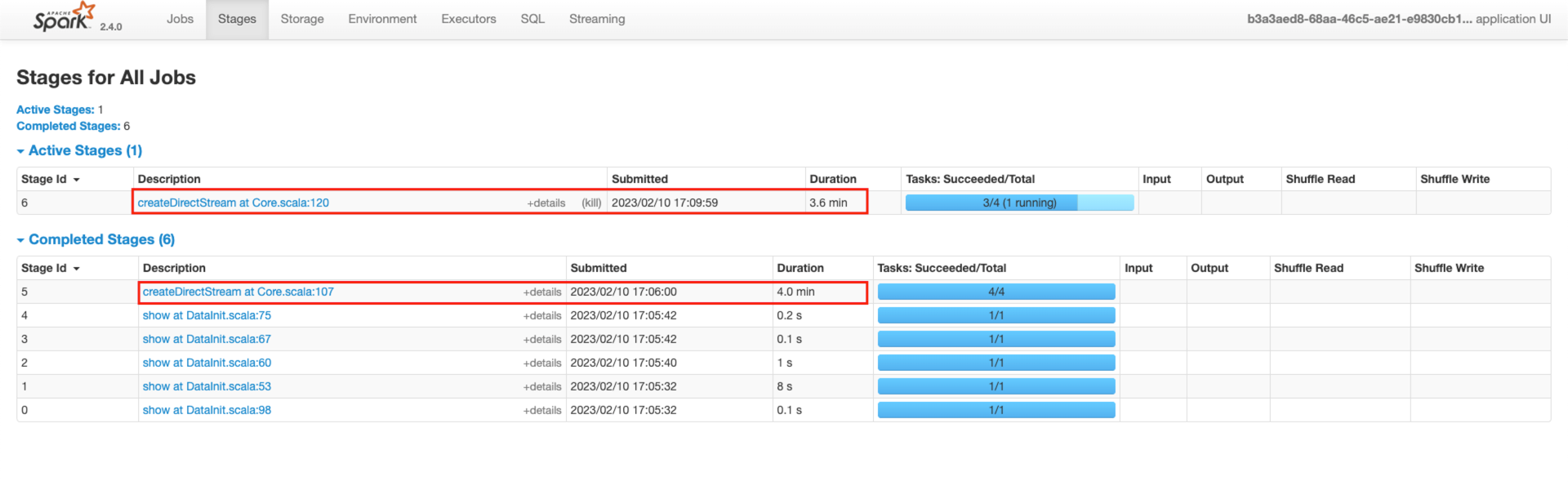
该项目中需要读取 kafka 中三个主题的数据,所以每批次数据处理生成的任务中,都会执行一次 createDirectStream 代码。
从上图中可以看到,连接 kafka 的代码处,执行了非常长的时间,甚至有时候会超时失败,然后任务会一直被卡主,不处理数据。
3. 排查步骤
刚开始,我以为是默认的连接 kafka 之类的超时时间太小了,然后就不断的调大各种超时时间,包括会话超时时间、请求超时时间、拉取数据超时时间、心跳时间等,但是最后还是不管用。即使是调整到了 10 分钟这个级别,任务依然会卡主,而且也不会因为发生了什么报错而停止,很让人摸不着头脑。
3.1. 查看spark日志
一直排查不到问题,而且任务改造花费了很长很长的时间,领导也来帮忙了(不是大数据方向的,但是一直在做后端,经验很足)。领导让我仔细的看看日志,一行一行的看,不忽略任何错误和警告日志,甚至是 info 级别的日志也仔细的一行一行看,最后发现了这行日志:
WARN consumer.ConsumerConfig: The configuration
'What to do when there is no initial offset in Kafka or if the current offset does not exist any more on the server
(e.g. because that data has been deleted):
<ul><li>earliest: automatically reset the offset to the earliest offset<li>
latest: automatically reset the offset to the latest offset</li><li>n
one: throw exception to the consumer if no previous offset is found for the consumer's group</li><li>
anything else: throw exception to the consumer.</li></ul>' was supplied but isn't a known config.
注意日志中的这个信息:What to do when there is no initial offset in Kafka or if the current offset does not exist any more on the server (e.g. because that data has been deleted),意思是说:如果在 kafka 中不存在指定的初始化偏移量,或者是当前偏移量不存在(比如数据被删除),该怎么做。
后面的意思就是读取 kafka 中数据时,我们设置的初始偏移量,有 earliest、latest、none,大家一般都知道前两种是啥意思,可能很少注意最后这个 none,初始偏移量被设置为 none 时,消费者组如果找不到之前的偏移量,则会抛出异常,这个抛异常很关键。如果由于设置为 none,并且找不到之前的偏移量了,就会由于抛出的异常,而卡住咱们的消费程序。
之后在 idea 中调试运行程序,又发现了这些警告信息:

注意第二行警告信息:**KafkaUtils: overriding auto.offset.reset to none for executor**,这是在说,spark 提供的连接 kafka 的工具类 KafkaUtils ,会覆盖一些咱们手动配置的信息。
即使我代码中手动设置了连接 kafka 的参数 auto.offset.reset,不管设置为什么,他都会覆盖为 none。而通过上面的日志信息可以知道,如果初始偏移量设置为 none,可能是会发生错误的。但还有另外一个问题,kafka 中的数据,是很少会丢失的,怎么会发生这个错误呢。
3.2. 排查kafka自身
通过 offset explorer(前身是 kafka tool,可以直接在软件界面读取到 kafka 中的主题数据)查看程序消费的 kafka 中的数据,发现数据是没啥问题的,一直在进来新数据。然后点开主题,直接查看主题一个分区内的数据,结果发现了问题,如下图:
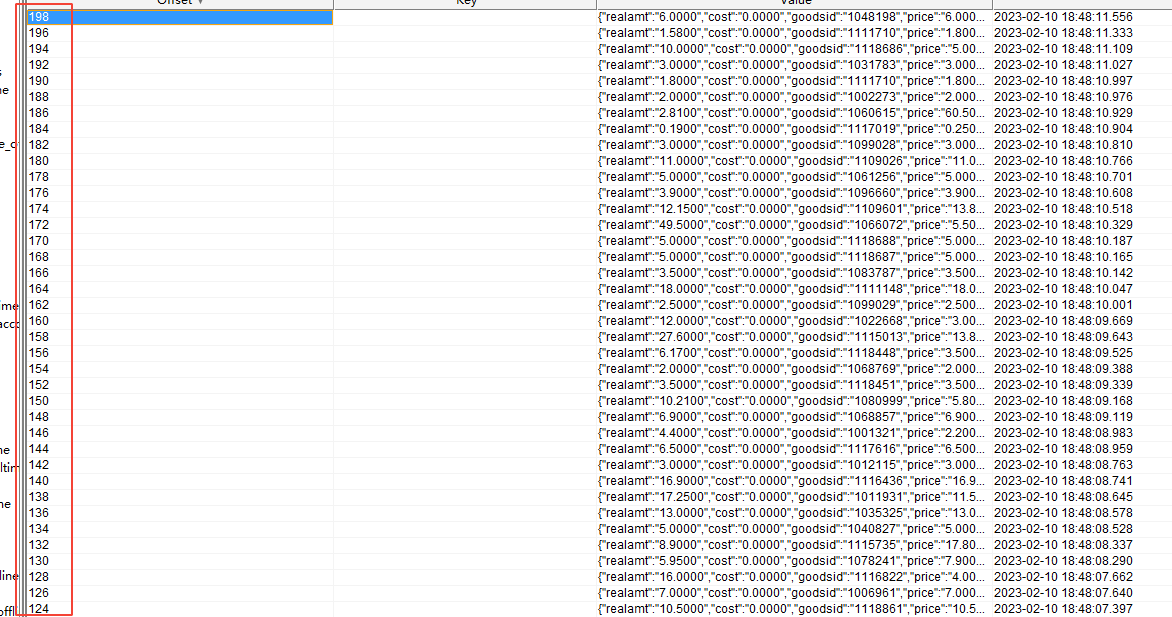
kafka 主题单个分区内的 offset 值是不连续的,而且都是双数。通过网络查询得知,造成这种 offset 值不连续的一个原因,就是上游生产者开启了事务,然后每条数据对应的事务都是占用一个 offset 值,所以真正的数据的 offset 值都会隔一个进行占用。
然后再次查看线上运行时的 executor 日志,然后发现了类似 set offset 1000 to 1002 日志,然后我们去 offset explorer 中查看具体 offset 值附近的数据,发现这个数据到达 kafka 中的时间,并不是打印日志的时间,而是延后了 2 分钟。我们经过思考,觉得有可能是事务造成的影响。spark 去 kafka 中查找到了最新的 offset 值,然后将最新 offset 值作为本批次读取数据的结束 offset 值,之后就开始读取数据,但是从 kafka 中却找不到 offset 值为 1002 的数据,然后就根据设置的 aotu.offset.reset 来重新初始化 offset 值。而由于 spark 将该配置强制设置为了 none ,这是消费者就抛出了异常,此时整个任务就卡住了。
知道了该现象是由于生产者开启事务造成的,我们就让后端同事重新上线了去掉了事务的生产者代码,之后就再没报错了。
4. 解决方案
4.1. 取消生产者事务
由于生产者开启了事务,所有数据真正写入 kafka,并且能让消费者看到的时间,必定会有一定的延迟。消费者直接获取最新 offset 值,获取到的是主题分区的 LEO(日志末端位移)值,但是这个 offset 对应的数据,默认是不能被消费者马上看到的,必须在生产者提交了事务之后才能看到。如果上游生产者由于某些原因,最后回滚了事务,那这个 offset 值对应的数据,就永远看不到了。所以最简单的方法就是取消生产者事务。
4.2. 设置消费者隔离级别
另外,我们还在官网看到了另外一个参数:isolation.level,这个参数含义如下:
控制如何读取以事务方式写入的消息。如果设置为
read_committed,consumer.poll()将只返回已提交的事务消息。如果设置为read_uncommitted(默认值),consumer.poll()将返回所有消息,甚至包括已经中止的事务性消息。在任何一种模式下,非事务性消息都将无条件返回。
消息总是按偏移量顺序返回。因此,在read_committed模式下,consumer.poll()将只返回最后一个稳定偏移量(LSO)之前的消息,LSO小于第一个打开事务的偏移量。特别是,在属于正在进行的交易的消息之后出现的任何消息将被扣留,直到相关交易完成。因此,read_committed消费者在事务运行中无法读取到高水位。
此外,在read_committed中,seekToEnd方法将返回LSO
默认为读未提交,如果事务中断,或者是事务还未提交,但是消费者开始读取最新的数据了,此时这个数据是还不能被消费者看到的,消费者此时拿不到数据,就会根据设置的 auto.offset.reset 值重新初始化偏移量。
所以,保险起见,如果生产者开启了事务,或者是不确定生产者是否开启了事务,都将消费者的 isolation.level 值设置为 read-committed,以防消费者去读取还未提交事务的消息,但又读不到而发生错误。