note
- 和CS224W课程对应,将图的基本表示写在task1笔记中了;传统图特征工程:将节点、边、图转为d维emb,将emb送入ML模型训练
- Traditional ML Pipeline
- Hand-crafted feature + ML model
- Hand-crafted features for graph data
- Node-level的特征工程:
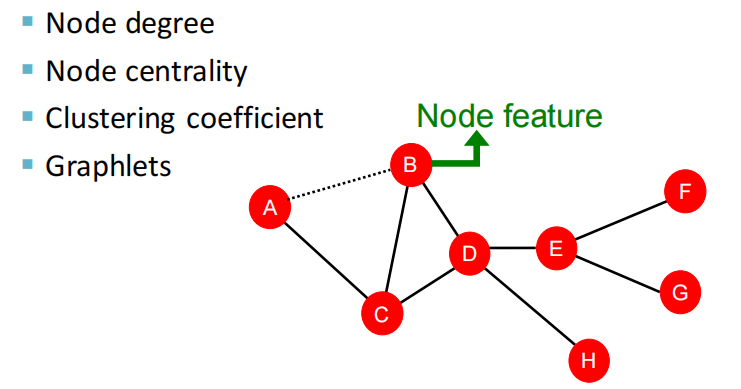
- Node degree, centrality, clustering coefficient, graphlets
- Link-level的特征工程:
- Distance-based feature
- local/global neighborhood overlap
- Graph-level的特征工程:
- Graphlet kernel, WL kernel
- Node-level的特征工程:
-
- 为了研究图神经网络的表达力问题,产生一个重要模型——图同构模型,
Weisfeiler-Lehman测试就是检测两个图是否在拓扑结构上图同构的近似方法;该测试最大的特点是:对每个节点的子树的聚合函数采用的是单射(Injective)的散列函数。
——由该特点我们可以通过设计一个单射聚合聚合函数来设计与WL一样强大的图卷积网络(同时,图同构网络有强大的图区分能力,适合图分类任务)。
- 为了研究图神经网络的表达力问题,产生一个重要模型——图同构模型,
文章目录
- note
- 一、前言
- 二、Traditional Feature-based Methods: Node
- 2.1 节点的特征
- 2.2 node centrality 节点重要度
- 2.3 clustering coefficient 聚集系数
- 2.4 graphlets 有根连通异构子图
- 2.5 思考题
- (1)扩展阅读
- (2)思考题
- (3)小结
- 三、Traditional Feature-based Methods: Link
- 3.1 链接预测任务
- 3.2 捕获节点的共同邻居数
- 3.3 Global neighborhood overlap
- (1)扩展阅读
- (2)思考题
- (3)小结
- 四、Traditional Feature-based Methods: Graph
- 4.1 图级别分类
- 4.2 Kernel Methods
- 方法一:Graphlet Kernel
- 方法二:Weisfeiler-Lehman Kernel
- (1)图同构性测试算法WL Test
- 背景介绍
- WL举例说明(以一维为栗子)
- 第一步:聚合
- 第二步:标签散列(哈希)
- 注:怎样的聚合函数是一个单射函数?
- 第三步:给节点重新打上标签。
- 第四步:数标签
- 第五步:判断同构性
- (2)WL Subtree Kernel图相似性评估(定量化)
- 4.3 小结
- (1)扩展阅读
- (2)思考题
- (3)小结
- 五、其他
- 附:时间安排
- Reference
一、前言
除了想获得训练数据中节点or边or图特征数据,还有反应节点在网络中位置、局部网络local network structure等特征。
本讲不讲属性特征,只讲连接特征。
二、Traditional Feature-based Methods: Node
2.1 节点的特征
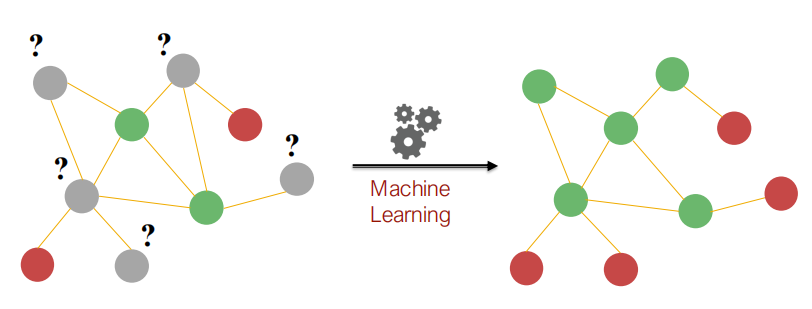
- 半监督学习:如上图的节点分类,预测灰色点时属于红色点还是绿色点。
- 特征抽取目标:找到能够描述节点在网络中结构与位置的特征
- 节点的度数:缺点是节点的所有邻居节点的重要程度都相同
2.2 node centrality 节点重要度
- node centrality:考虑了节点的重要性

(1)eigenvector centrality:如果当前节点周围有很多重要的邻居节点,则可以认为当前节点也是重要的,即节点v的centrality是邻居centrality的加和: c v = 1 λ ∑ u ∈ N ( v ) c u c_{\mathrm{v}}=\frac{1}{\lambda} \sum_{\mathrm{u} \in \mathrm{N}(\mathrm{v})} \mathrm{c}_{\mathrm{u}} cv=λ1∑u∈N(v)cu,其中 λ \lambda λ是某个正常数。- 该递归式的解法是转为矩阵形式: λ c = A c \lambda \mathbf{c}=\mathbf{A} \mathbf{c} λc=Ac,其中 A A A是邻接矩阵,c是centralty向量,即特征向量。根据Perron-Frobenius Theorem知最大的特征值总为正且唯一,对应的c为centrality向量
(2)betweenness centrality:若该节点在很多节点对的最短路径上,则认为该节点重要
(3)closeness centrality:若该节点和其他节点的距离最短,则认为该节点重要 ,如下图所示
2.3 clustering coefficient 聚集系数
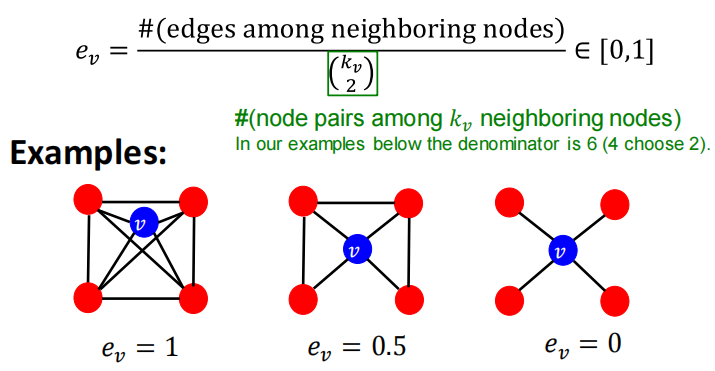
衡量节点邻居的连接程度,描述节点的局部结构信息。
(
k
v
2
)
\left(\begin{array}{c}\mathrm{k}_{\mathrm{v}} \\ 2\end{array}\right)
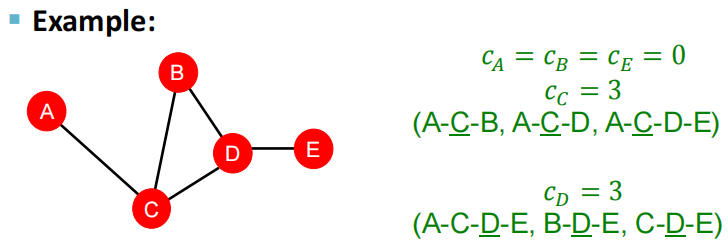
(kv2)是组合数的写法,表示v邻居所构成的节点对,即潜在的连接数,衡量节点邻居的连接有多紧密,如上图中ev=6/6。
2.4 graphlets 有根连通异构子图
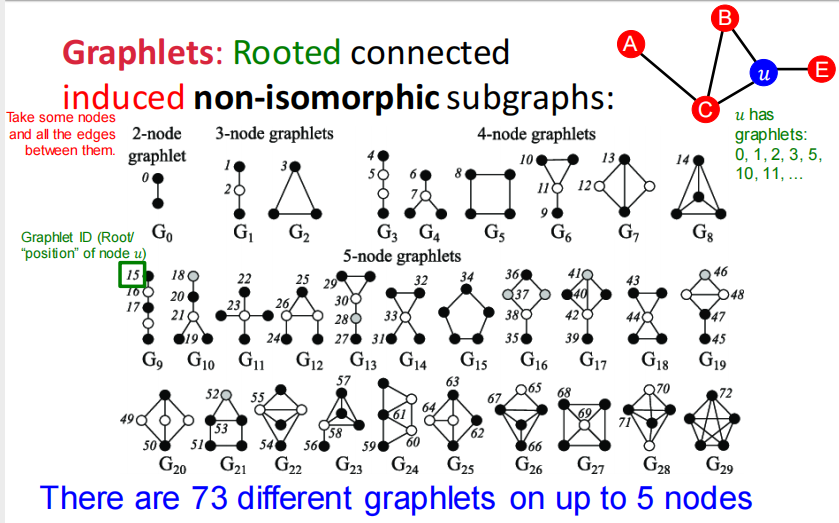
- Graphlet Degree Vector (GDV): Graphlet-base features for nodes
- GDV与其他两种描述节点结构的特征的区别:
- Degree counts #(edges) that a node touches
- Clustering coefficient counts #(triangles) that a node touches.
- GDV counts #(graphlets) that a node touches
- Graphlet Degree Vector (GDV): A count vector of graphslets rooted at a given node.
2.5 思考题
(1)扩展阅读
https://www.geeksforgeeks.org/eigenvector-centrality-centrality-measure
https://www.jsums.edu/nmeghanathan/files/2015/08/CSC641-Fall2015-Module-2-Centrality-Measures.pdf?x61976
https://aksakalli.github.io/2017/07/17/network-centrality-measures-and-their-visualization.html
上海地铁线路图:http://www.shmetro.com
上海地铁时刻表:http://service.shmetro.com/hcskb/index.htm
北京地铁线路图:https://map.bjsubway.com
北京地铁时刻表:https://www.bjsubway.com/station/smcsj
https://hal.archives-ouvertes.fr/hal-01764253v2/document
NetworkX-常用图数据挖掘算法:https://networkx.org/documentation/stable/reference/algorithms/index.html
NetworkX-节点重要度算法:https://networkx.org/documentation/stable/reference/algorithms/centrality.html
NetworkX-Clustering算法:https://networkx.org/documentation/stable/reference/algorithms/clustering.html
NetworkX-最短路径算法:https://networkx.org/documentation/stable/reference/algorithms/shortest_paths.html
(2)思考题
节点层面,存在哪些数据挖掘任务,有何应用场景?
“传统图机器学习方法”传统在何处?
特征工程在数据挖掘中有什么作用?
在传统图机器学习中,为什么要对节点、连接、全图做特征工程?
传统图机器学习方法相比图神经网络(深度学习),有什么优点和缺点?
节点层面可以构造哪些特征?这些特征可以归为哪两类?
简述不同的Node Centrality计算方法
只用Node Degree作为节点重要度,会有什么缺点?
Eigenvector centrality和PageRank有什么异同?
Betweenness Centrality和Closeness Centrality有什么区别?分别揭示了节点是什么特征?
你认为所有海峡中,哪个海峡的Betweenness Centrality最高?
你认为中国所有城市中,哪个城市的Closeness Centrality最高?
湖北到中国任何一个省级行政区,最多跨两个省,说明哪个特征高?
你认为你所在城市的地铁站中,哪个地铁站的Closeness Centrality最高?哪个地铁站的Clutering Coefficient最高?
地铁线路连接关系,应该如何表示?(邻接矩阵、连接列表、邻接列表)
你认为你的人脉圈中,谁的Clutering Coefficient最高?为什么?
什么是Ego-Network(自我中心网络)?
Graphlet和Wavelet(小波分析)有什么异同?
由四个节点组成的图,存在多少种Graphlet?
五个节点构造的所有Graphlet中,存在多少种不同角色的节点?
节点的哪些特征,可以衡量该节点是否为中心枢纽节点?桥接节点?边缘孤立节点?
除了课程中讲的Centrality之外,还有哪些Centrality指标?(PageRank、Katz Centrality、HITS Hubs and Authorities)
(3)小结
节点级别的特征:
- importance-based features:捕获节点在图中的重要性
- 节点度数
- 不同的节点centrality衡量方法

- struture-based features:捕获节点附近的拓扑属性

三、Traditional Feature-based Methods: Link
3.1 链接预测任务
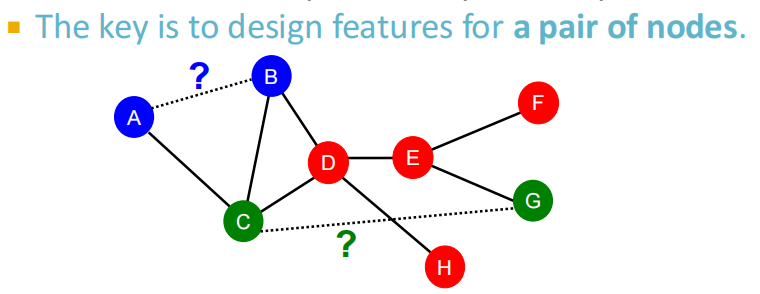
任务:基于已知边,预测新边的类别。测试模型时:将每一对没有连接的节点对进行排序,取存在连接概率最高的topK个节点对,作为预测的结果。
- 两种类型:随机缺失边、随时间演化边
- 第一种:比如研究发现蛋白质之间的交互作用
- 第二种:社交网络,随时间迁移,认识更多人

3.2 捕获节点的共同邻居数
Local neighborhood overlap:
- common neighbors(共同好友个数)的问题在于度数高的点对就会有更高的结果;
- Jaccard’s coefficient(交并比)是其归一化后的结果。
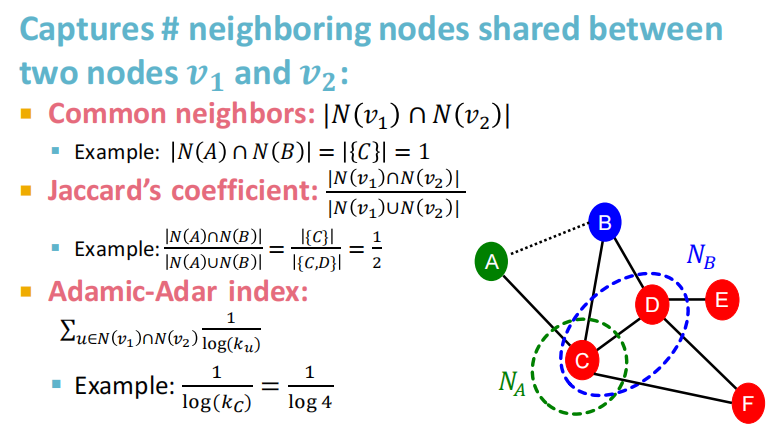
3.3 Global neighborhood overlap
local neighborhood overlap的局限:如果两个节点都没有公共的邻居节点,则对应的local neighborhood overlap始终为0。
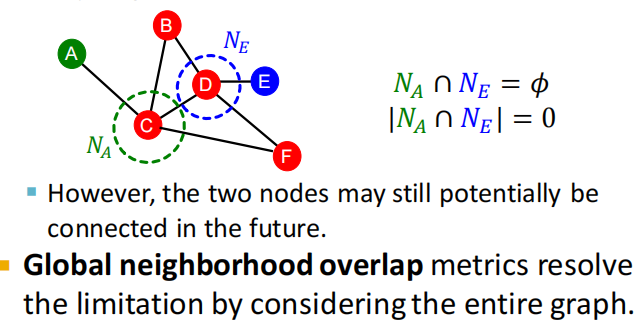
(1)扩展阅读
NetworkX相关文档
https://networkx.org/documentation/stable/reference/generated/networkx.classes.function.common_neighbors.html
https://networkx.org/documentation/stable/reference/algorithms/generated/networkx.algorithms.link_prediction.jaccard_coefficient.html
https://networkx.org/documentation/stable/reference/algorithms/generated/networkx.algorithms.link_prediction.adamic_adar_index.html
https://stackoverflow.com/questions/62069781/how-to-find-the-similarity-between-pair-of-vertices-using-katz-index-in-python
(2)思考题
连接层面,存在哪些数据挖掘任务,有何应用场景?
连接层面可以构造哪些特征?这些特征可以归为哪三类?
简述Link Prediction的基本流程
A和B都知道梅西,C和D都知道同济子豪兄,请问哪对人物更容易产生社交连接。可以用哪个特征解释?
两个节点没有共同好友时,可以用什么特征,将连接编码为D维向量?
简述Katz Index的算法原理
如何计算节点U和节点V之间,长度为K的路径个数
为什么不直接把link两端节点的向量特征concat到一起,作为link的向量特征
(3)小结

四、Traditional Feature-based Methods: Graph
4.1 图级别分类
- 构建目标:找到能描述全图结构的特征
4.2 Kernel Methods

方法一:Graphlet Kernel
【代码例子】找出所有的子图Graphlet。
import networkx as nx
import matplotlib.pyplot as plt
import scipy
import pandas as pd
import matplotlib.colors as mcolors
import itertools
# 10. 子图Graphlet
G = nx.karate_club_graph()
# plt.figure(figsize=(10,8))
pos = nx.spring_layout(G, seed=123)
# nx.draw(G, pos, with_labels=True)
# 指定Graphlet
target = nx.complete_graph(3)
# nx.draw(target)
# 匹配Graphlet, 统计个数
num = 0
for sub_nodes in itertools.combinations(G.nodes(), len(target.nodes())): # 遍历全图中,符合graphlet节点个数的所有节点组合
# 从全图中抽取出子图
subg = G.subgraph(sub_nodes)
# 如果子图是完整连通域,并且符合graphlet特征,输出原图节点编号
if nx.is_connected(subg) and nx.is_isomorphic(subg, target):
num += 1
print(subg.edges())
print("=====test=======")
方法二:Weisfeiler-Lehman Kernel
(1)图同构性测试算法WL Test
背景介绍
两个图是同构的,意思是两个图拥有一样的拓扑结构,也就是说,我们可以通过重新标记节点从一个图转换到另外一个图。Weisfeiler-Lehman 图的同构性测试算法,简称WL Test,是一种用于测试两个图是否同构的算法。
WL Test 的一维形式,类似于图神经网络中的邻接节点聚合。WL Test
1)迭代地聚合节点及其邻接节点的标签,然后 2)将聚合的标签散列(hash)成新标签,该过程形式化为下方的公式,
L
u
h
←
hash
(
L
u
h
−
1
+
∑
v
∈
N
(
U
)
L
v
h
−
1
)
L^{h}_{u} \leftarrow \operatorname{hash}\left(L^{h-1}_{u} + \sum_{v \in \mathcal{N}(U)} L^{h-1}_{v}\right)
Luh←hash
Luh−1+v∈N(U)∑Lvh−1
符号:
L
u
h
L^{h}_{u}
Luh表示节点
u
u
u的第
h
h
h次迭代的标签,第
0
0
0次迭代的标签为节点原始标签。
在迭代过程中,发现两个图之间的节点的标签不同时,就可以确定这两个图是非同构的。需要注意的是节点标签可能的取值只能是有限个数。

WL举例说明(以一维为栗子)
给定两个图 G G G和 G ′ G^{\prime} G′,每个节点拥有标签(实际中,一些图没有节点标签,我们可以以节点的度作为标签)。
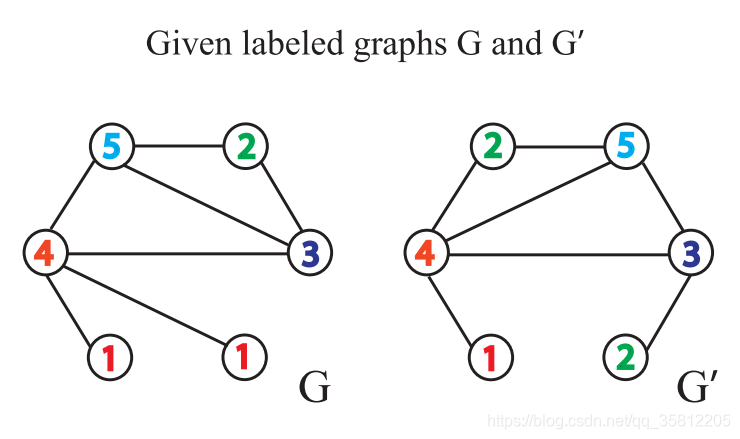
Weisfeiler-Leman Test 算法通过重复执行以下给节点打标签的过程来实现图是否同构的判断:
第一步:聚合
聚合自身与邻接节点的标签得到一串字符串,自身标签与邻接节点的标签中间用,分隔,邻接节点的标签按升序排序。排序的原因在于要保证单射性,即保证输出的结果不因邻接节点的顺序改变而改变。
如下图就是,每个节点有个一个label(此处表示节点的度)。

如下图,做标签的扩展:做一阶BFS,即只遍历自己的邻居,比如在下图中G中原5号节点变成(5,234),这是因为原(5)节点的一阶邻居有2、3、4。
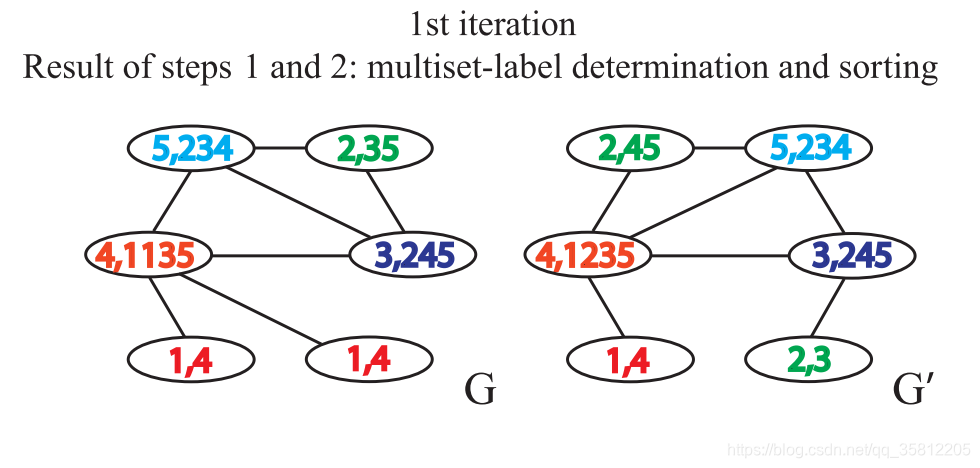
第二步:标签散列(哈希)
即标签压缩,将较长的字符串映射到一个简短的标签。
如下图,仅仅是把扩展标签映射成一个新标签,如5,234映射为13

注:怎样的聚合函数是一个单射函数?
什么是单射函数?
单射指不同的输入值一定会对应到不同的函数值。如果对于每一个y存在最多一个定义域内的x,有f(x)=y,则函数f被称为单射函数。
看一个栗子:
两个节点v1和v2,其中v1的邻接点是1个黄球和1个蓝球,v2的邻接点是2个邻接点是2个黄球和2个蓝球。最常用的聚合函数包含图卷积网络中所使用的均值聚合,以及GraphSAGE中常用的均值聚合或最大值聚合。
(1)如果使用均值聚合或者最大值聚合,聚合后v1的状态是(黄,蓝),而v2的状态也是(黄,蓝),显然它们把本应不同的2个节点映射到了同一个状态,这不满足单射的定义。
(2)如果使用求和函数,v1的状态是(黄,蓝),而v2的状态是(2×黄,2×蓝),也就分开了。

可以看出WL测试最大的特点是:对每个节点的子树的聚合函数采用的是单射(Injective)的散列函数。
第三步:给节点重新打上标签。
继续一开始的栗子,
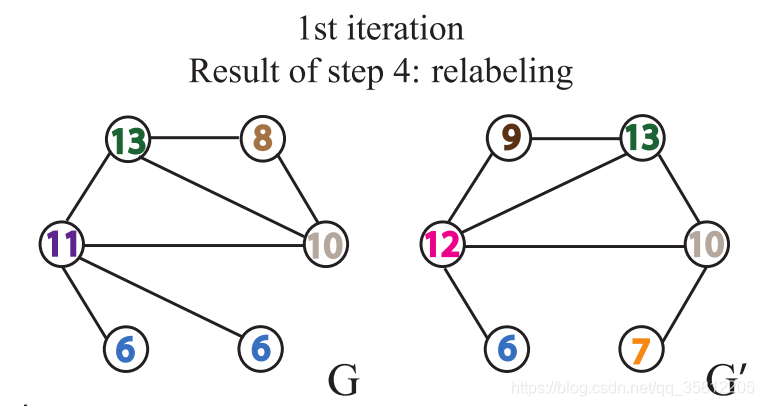
第四步:数标签
如下图,在G网络中,含有1号标签2个,那么第一个数字就是1。这些标签的个数作为整个网络的新特征。

每重复一次以上的过程,就完成一次节点自身标签与邻接节点标签的聚合。
第五步:判断同构性
当出现两个图相同节点标签的出现次数不一致时,即可判断两个图不相似。如果上述的步骤重复一定的次数后,没有发现有相同节点标签的出现次数不一致的情况,那么我们无法判断两个图是否同构。
当两个节点的 h h h层的标签一样时,表示分别以这两个节点为根节点的WL子树是一致的。WL子树与普通子树不同,WL子树包含重复的节点。下图展示了一棵以1节点为根节点高为2的WL子树。
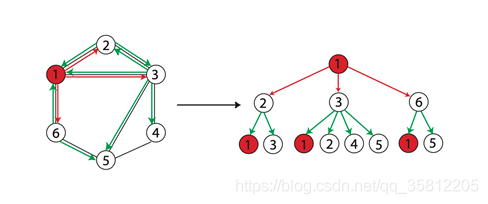
(2)WL Subtree Kernel图相似性评估(定量化)
此方法来自于Weisfeiler-Lehman Graph Kernels。
- WL测试不能保证对所有图都有效,特别是对于具有高度对称性的图,如链式图、完全图、环图和星图,它会判断错误。
- WL测试只能判断两个图的相似性,无法衡量图之间的相似性。要衡量两个图的相似性,我们用WL Subtree Kernel方法。
Weisfeiler-Lehman Graph Kernels 方法提出用WL子树核衡量图之间相似性。该方法使用WL Test不同迭代中的节点标签计数作为图的表征向量,它具有与WL Test相同的判别能力。在WL Test的第 k k k次迭代中,一个节点的标签代表了以该节点为根的高度为 k k k的子树结构。
该方法的思想是用WL Test算法得到节点的多层的标签,然后我们可以分别统计图中各类标签出现的次数,存于一个向量,这个向量可以作为图的表征。两个图的表征向量的内积,即可作为这两个图的相似性估计,内积越大表示相似性越高。
4.3 小结
(1)扩展阅读
https://networkx.org/documentation/stable/reference/algorithms/generated/networkx.algorithms.graph_hashing.weisfeiler_lehman_graph_hash.html
(2)思考题
全图层面,存在哪些数据挖掘任务,有何应用场景?
全图层面可以构造哪些特征?
全图层面的Graphlet,和节点层面的Graphlet,有什么区别?
子图匹配,算法复杂度如何计算?
简述Weisfeiler-Lehman Kernel的算法原理
Weisfeiler-Lehman Kernel的词汇表(颜色表)是如何构建的?
Weisfeiler-Lehman Kernel,算法复杂度是多少?
Weisfeiler-Lehman Kernel和图神经网络(GNN)有什么关系?
简述Kernel Methods基本原理
为什么在Graph-level任务中,使用Kernel Methods
除了Graphlet Kernel和Weisfeiler-Lehman Kernel之外,还有哪些Kernel
传统图机器学习和特征工程中,哪些特征用到了邻接矩阵Adjacency Matrix?
如何把无向图节点、连接、全图的特征,推广到有向图?
如何用代码实现Weisfeiler-Lehman Kernel?
(3)小结

五、其他
同济子豪兄中文精讲视频:
节点特征工程:https://www.bilibili.com/video/BV1HK411175s
连接特征工程:https://www.bilibili.com/video/BV1r3411m7sD
全图特征工程:https://www.bilibili.com/video/BV14W4y1V7gg
斯坦福原版视频:
https://www.youtube.com/watch?v=3IS7UhNMQ3U&list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn&index=4
https://www.youtube.com/watch?v=4dVwlE9jYxY&list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn&index=5
https://www.youtube.com/watch?v=buzsHTa4Hgs&list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn&index=6
附:时间安排
| 任务 | 任务内容 | 截止时间 | 注意事项 |
|---|---|---|---|
| 2月11日开始 | |||
| 第一周 | |||
| task1 | 图机器学习导论 | 2月14日周二 | 完成 |
| task2 | 图的表示和特征工程 | 2月15、16日周四 | |
| task3 | NetworkX工具包实践 | 2月17、18日周六 | 代码实战 |
| 第二周 | |||
| task4 | 图嵌入表示 | 2月19、20日周一 | |
| task5 | deepwalk、Node2vec论文精读 | 2月21、22日周三 | |
| task6 | PageRank | 2月23、24日周五 | |
| task7 | 标签传播与节点分类 | 2月25、26日周日 | |
| 第二周 | |||
| task8 | 图神经网络基础 | 2月27、28日周二 | |
| task9 | 图神经网络的表示能力 | 3月1日周三 | |
| task10 | 图卷积神经网络GCN | 3月2日周四 | |
| task11 | 图神经网络GraphSAGE | 3月3日周五 | |
| task12 | 图神经网络GAT | 3月4日周六 |
Reference
[1] 传统图机器学习的特征工程-节点【斯坦福CS224W】
[2] cs224w(图机器学习)2021冬季课程学习笔记2: Traditional Methods for ML on Graphs
[3] NetworkX入门教程
[4] https://github.com/TommyZihao/zihao_course/tree/main/CS224W
[5] 斯坦福官方课程:https://web.stanford.edu/class/cs224w/
[6] 子豪兄github:https://github.com/TommyZihao/zihao_course
[7] 图表示学习系列2——传统机器学习方法