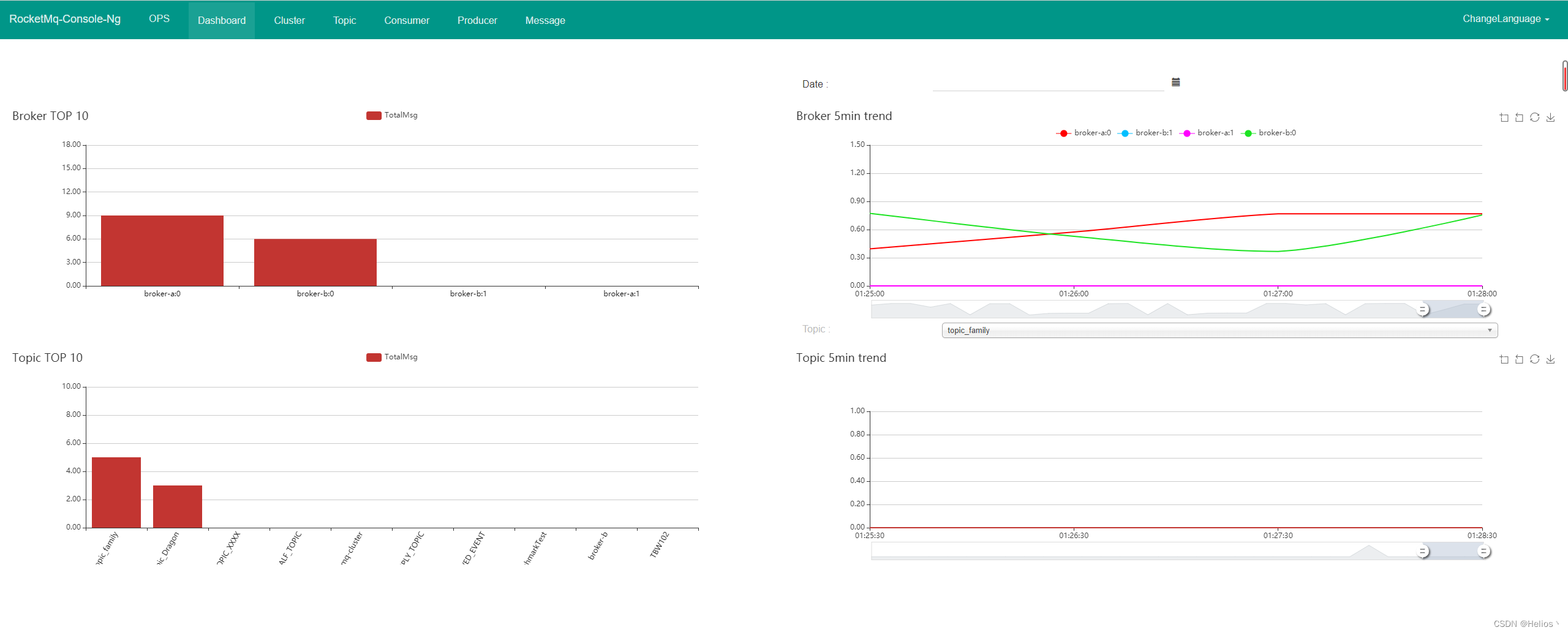
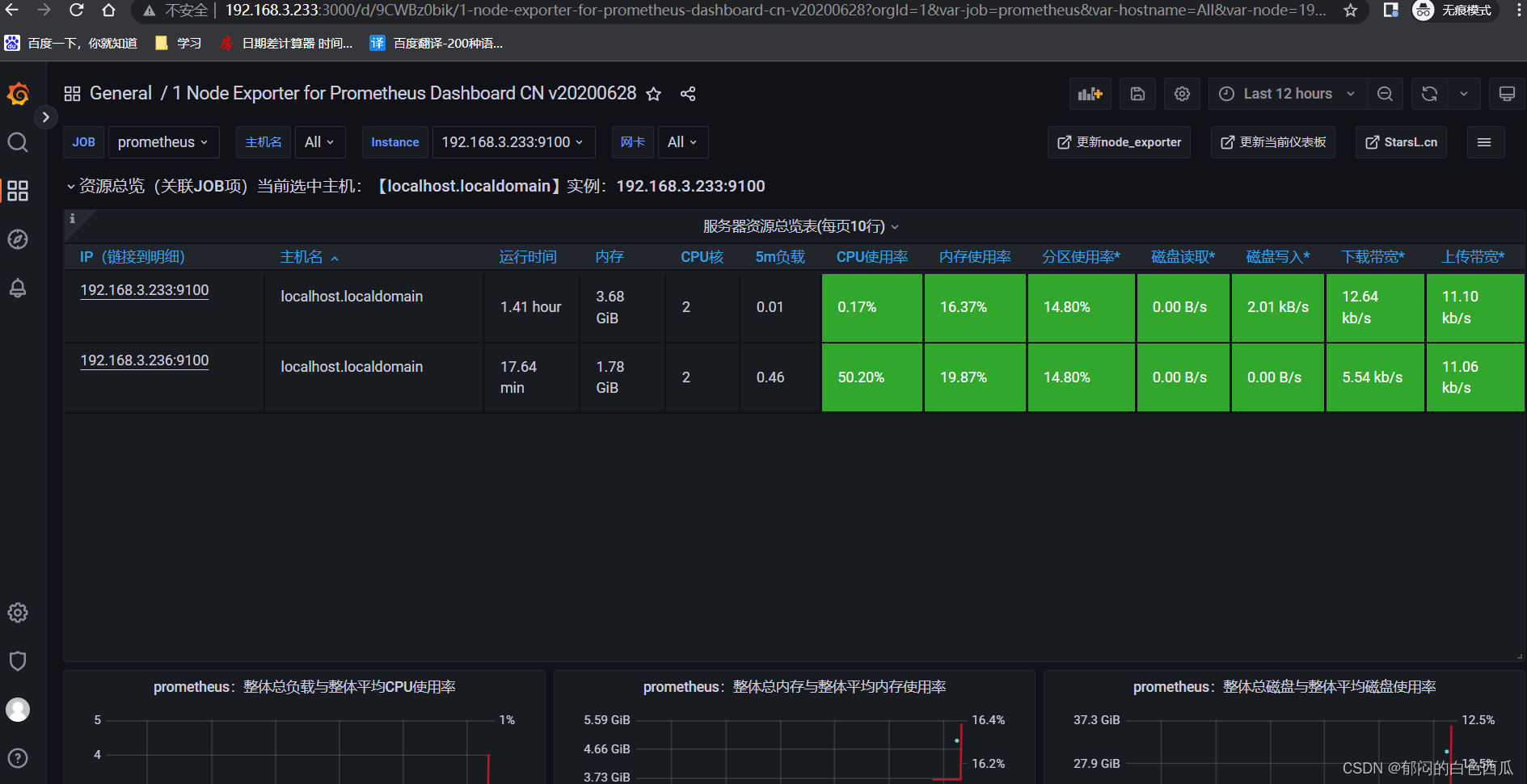
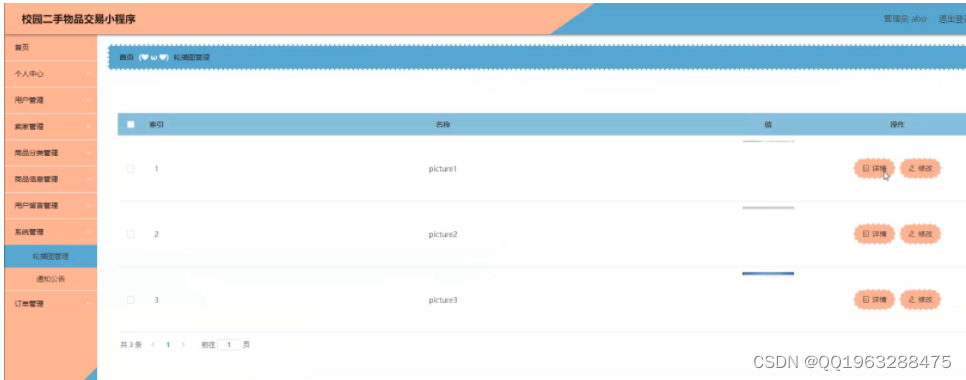
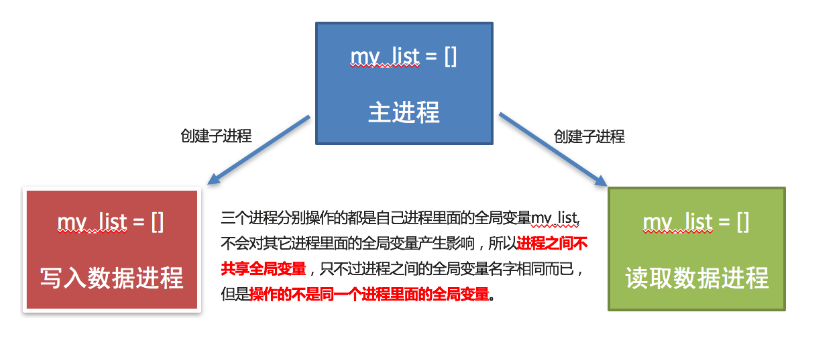
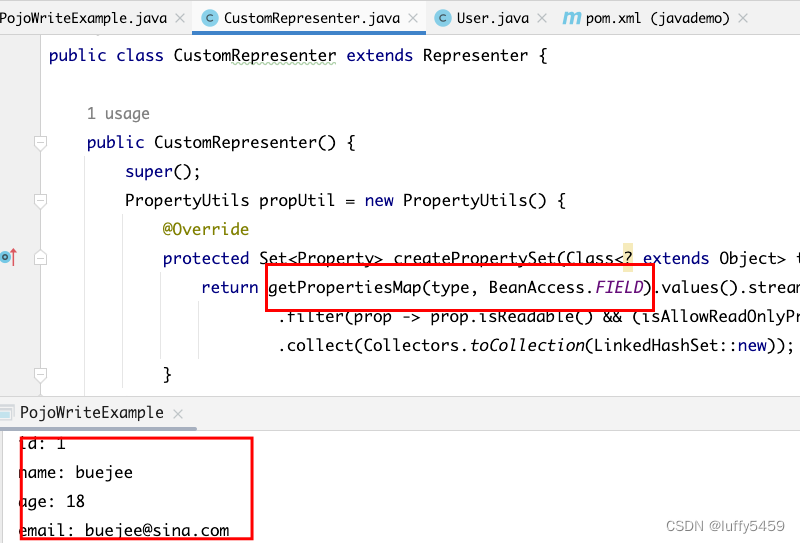
目标层:评价光污染
准则层为四个大类:道路、商业、住宅、绿化
方案层为25个小类指标
但每个大类只和自己下面的几个小类指标相关,不是图示的下面两层全有关联
或许考虑把25个小指标提取公共部分,比如路灯亮度、高度、和外墙的距离、光色、频闪这些是每个大类都有的,不区分主体后也可以形成图示的全连接
实际用的代码是熵权法+TOPSIS(清风)
层次分析的矩阵从何而来还有部分没考虑清楚,不过不影响结果的权重得出
熵权法的原理和实现流程交给喵姐喽,下面的代码结果应该也能看懂,8个地区的污染程度排名好像还可以,下午再仔细检查一下排名,排名暂时也不需要在论文中用到
原始数据及初步处理(sheet1)

结果的权重见sheet3

最后两个地区的数据竟然完全相同,而且地区没有商业化属性,所以只用前8个
绿化大类的属性很多地区也没有,所以选前3个大类,对应17个小类指标
绿化部分的权重是从天津的层次分析结果直接稍微改动得出的
总体权重符合常识
共有8个评价对象, 17个评价指标
这17个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: 0
标准化矩阵 Z =
列 1 至 6
0.4846 0.4846 0.4823 0.4503 0.5320 0.4600
0.3061 0.3061 0.2597 0.3416 0.3546 0.3748
0.3316 0.3316 0.3710 0.3105 0.4532 0.3919
0.3316 0.3316 0.3710 0.3571 0.2561 0.3919
0.3316 0.3316 0.2412 0.2640 0.1970 0.2896
0.2551 0.2551 0.1855 0.3105 0.1182 0.2385
0.4081 0.4081 0.4823 0.4037 0.3941 0.3407
0.3316 0.3316 0.3154 0.3571 0.3349 0.2896
列 7 至 12
0.5418 0.4600 0.4223 0.3964 0.3933 0.3913
0.3612 0.3748 0.3112 0.3867 0.3837 0.2709
0.4616 0.3919 0.4446 0.3867 0.3837 0.4515
0.2609 0.3919 0.2890 0.3191 0.3165 0.3913
0.2007 0.2896 0.1556 0.2514 0.2494 0.4064
0.1204 0.2385 0.1778 0.3481 0.3069 0.2709
0.4014 0.3407 0.3556 0.3867 0.3837 0.2408
0.2810 0.2896 0.5112 0.3287 0.3837 0.3462
列 13 至 17
0.4022 0.3662 0.4018 0.4164 0.4581
0.3713 0.1060 0.2296 0.2082 0.2036
0.3094 0.3855 0.2487 0.3470 0.3393
0.3558 0.3855 0.2487 0.2863 0.2799
0.4177 0.3855 0.5166 0.4685 0.4581
0.3403 0.1928 0.1913 0.3470 0.3393
0.2475 0.5783 0.5357 0.3470 0.3393
0.3558 0.1928 0.2678 0.3470 0.3393
请输入是否需要增加权重向量,需要输入1,不需要输入0
请输入是否需要增加权重: 1
使用熵权法确定权重请输入1,否则输入0: 1
熵权法确定的权重为:
列 1 至 5
0.0266 0.0266 0.0729 0.0190 0.1260
列 6 至 10
0.0299 0.1313 0.0299 0.1045 0.0147
列 11 至 15
0.0166 0.0348 0.0169 0.1598 0.1113
列 16 至 17
0.0365 0.0427
最后的得分为:
stand_S =
0.1922
0.0895
0.1612
0.1106
0.1117
0.0376
0.1875
0.1098
sorted_S =
0.1922
0.1875
0.1612
0.1117
0.1106
0.1098
0.0895
0.0376
index =
1
7
3
5
4
8
2
6