文章目录
- 9.1模型调参
- 9.1.1思考与总结
- 9.1.2 基线baseline
- 9.1.3SGD ADAM
- 9.1.4 训练代价
- 9.1.5 AUTOML
- 9.1.6 要多次调参管理
- 9.1.7复现实验的困难
9.1模型调参
9.1.1思考与总结
1了解了baseline和调参基本原则
2了解了adams和sgd的优劣
3了解了训练树和神经网络的基本代价
4了解了autoML
5要多次调参管理
6复现试验的困难
9.1.2 基线baseline
选取一个好的超参数得到一个好的结果是比较花时间的过程
一般会从一个好的基线开始。一般工具包中都会存在极限
-
基线是什么?
-
选一个质量比较高的工具包,其中设了不错的参数,虽然可能对我们的问题不算是最好的,但是是一个不错的开始点;
-
如果要做的东西是跟某些论文相关,可以看看该论文里面的超参数是什么(有些超参数跟特定的数据集有关),这些超参数在一般的情况下都不错
-
有了比较好的起始点之后,调整超参数后再重新训练模型,再去看看验证集上的结果(精度、损失)
-
一次调一个值,多个值同时调可能会不知道谁在起贡献
-
看看模型对超参数的敏感度是什么样子【没调好一个超参数模型可能会比较差,但是调好了也只是到了还不错的范围】
9.1.3SGD ADAM
想对超参数没那么敏感的话,可以使用比较好的模型【在优化算法中使用Adam(对有些超参数没那么敏感,调参会简单很多)而不是SGD(在比较小的区域比较好)
9.1.4 训练代价
-
在小任务上很多时候已经可以用机器来做了(到最后可能都是用机器来调参【人的成本在增加】)
-
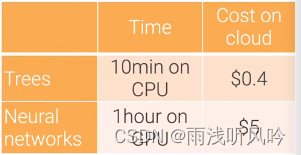
训练树模型在CPU上花10min 大概花$0.4
-
训练神经网络在GPU花1h左右 大概花$5
-
跟人比(人大概花十天左右),算法训练1000次调参数,很有可能会打败人类(90%)

9.1.5 AUTOML
-
AutoML在模型选择这一块做的比较好
-
超参数的优化(HPO)【比较通用】:通过搜索的方法,找到一个集合去调整模型的超参数
-
NAS(Neural architecture search)【专注于神经网络】:可以构造一个比较好的神经网络模型,使得能够拟合我们的任务
-
每个年代都有最大的技术痛点,当前AutoML可能是技术瓶颈。
9.1.6 要多次调参管理
-
每次调参一定要做好笔记【任何调过的东西,最好将这些实验管理好】(训练日志、超参数记录下来,这样可以与之前的实验做比较,也好做分享,与自己重复自己的实验)
-
最简单的做法是将log记录到txt上,把超参数和关键性指标(训练误差)放在excel中【适合实验没有那么多的参数】
-
Tensorboard,tensorflow开发的一个可视化工具
-
weight&kbias:允许在训练的时候用他们的API,然后把实验记录下来后上传到他们的网页上,就可以进行比较
9.1.7复现实验的困难
-
重复一个实验是非常难的
-
开发的环境:用的硬件是什么、新旧GPU可能会有点不一样;用的库的版本(Python本身也要去注意)
-
代码开发要做好版本控制(可以将每个版本的代码放在同一个地方 需求的库也放在这里)
-
要注意随机性(改变了随机种子,模型抖动比较大的话,说明代码的稳定性不是很好)【要避免换了个随机种子后,结果浮动比较大。这样的话,尝试能不能将不稳定的地方修改一下,实在不行就将多个模型做ensemble】






![剑指 Offer 10- I. 斐波那契数列[c语言]](https://img-blog.csdnimg.cn/3c7b7485e07343e3b924653d1109d8ce.png)