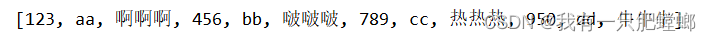文章目录
- 读取 txt 文件
- 读取 csv 文件
- 读取 MySQL 数据库表
- 读取 Json 文件
- 中文输出乱码
前提: 可以参考文章 SpringBoot 接入 Spark
- SpringBoot 已经接入 Spark
- 已配置 JavaSparkContext
- 已配置 SparkSession
@Resource
private SparkSession sparkSession;
@Resource
private JavaSparkContext javaSparkContext;
读取 txt 文件
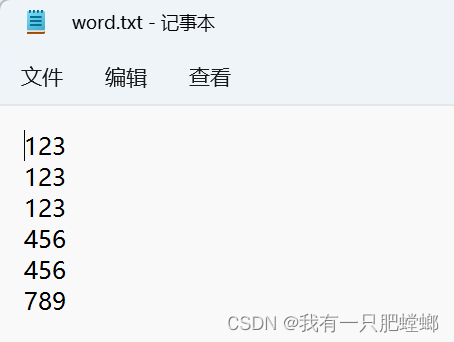
测试文件 word.txt
java 代码
- textFile:获取文件内容,返回 JavaRDD
- flatMap:过滤数据
- mapToPair:把每个元素都转换成一个<K,V>类型的对象,如 <123,1>,<456,1>
- reduceByKey:对相同key的数据集进行预聚合
public void testSparkText() {
String file = "D:\\TEMP\\word.txt";
JavaRDD<String> fileRDD = javaSparkContext.textFile(file);
JavaRDD<String> wordsRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaPairRDD<String, Integer> wordAndOneRDD = wordsRDD.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> wordAndCountRDD = wordAndOneRDD.reduceByKey((a, b) -> a + b);
//输出结果
List<Tuple2<String, Integer>> result = wordAndCountRDD.collect();
result.forEach(System.out::println);
}
结果得出,123 有 3 个,456 有 2 个,789 有 1 个

读取 csv 文件
测试文件 testcsv.csv
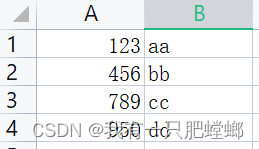
java 代码
public void testSparkCsv() {
String file = "D:\\TEMP\\testcsv.csv";
JavaRDD<String> fileRDD = javaSparkContext.textFile(file);
JavaRDD<String> wordsRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator());
//输出结果
System.out.println(wordsRDD.collect());
}
输出结果
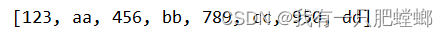
读取 MySQL 数据库表
- format:获取数据库建议是 jdbc
- option.url:添加 MySQL 连接 url
- option.user:MySQL 用户名
- option.password:MySQL 用户密码
- option.dbtable:sql 语句
- option.driver:数据库 driver,MySQL 使用 com.mysql.cj.jdbc.Driver
public void testSparkMysql() throws IOException {
Dataset<Row> jdbcDF = sparkSession.read()
.format("jdbc")
.option("url", "jdbc:mysql://192.168.140.1:3306/user?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai")
.option("dbtable", "(SELECT * FROM xxxtable) tmp")
.option("user", "root")
.option("password", "xxxxxxxxxx*k")
.option("driver", "com.mysql.cj.jdbc.Driver")
.load();
jdbcDF.printSchema();
jdbcDF.show();
//转化为RDD
JavaRDD<Row> rowJavaRDD = jdbcDF.javaRDD();
System.out.println(rowJavaRDD.collect());
}
也可以把表内容输出到文件,添加以下代码
List<Row> list = rowJavaRDD.collect();
BufferedWriter bw;
bw = new BufferedWriter(new FileWriter("d:/test.txt"));
for (int j = 0; j < list.size(); j++) {
bw.write(list.get(j).toString());
bw.newLine();
bw.flush();
}
bw.close();
结果输出
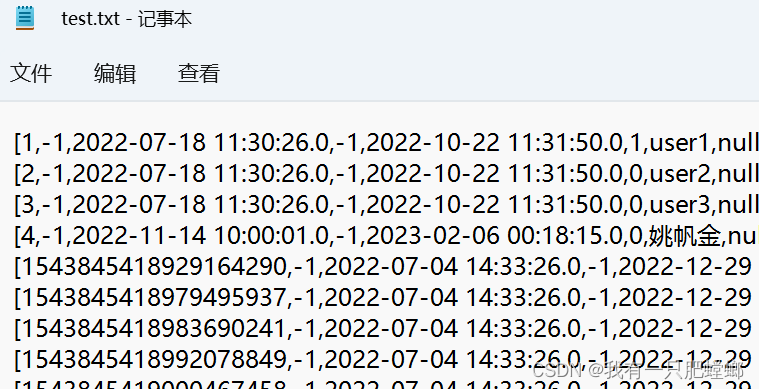
读取 Json 文件
测试文件 testjson.json,内容如下
[{
"name": "name1",
"age": "1"
}, {
"name": "name2",
"age": "2"
}, {
"name": "name3",
"age": "3"
}, {
"name": "name4",
"age": "4"
}]
注意:testjson.json 文件的内容不能带格式,需要进行压缩

java 代码
- createOrReplaceTempView:读取 json 数据后,创建数据表 t
- sparkSession.sql:使用 sql 对 t 进行查询,输出 age 大于 3 的数据
public void testSparkJson() {
Dataset<Row> df = sparkSession.read().json("D:\\TEMP\\testjson.json");
df.printSchema();
df.createOrReplaceTempView("t");
Dataset<Row> row = sparkSession.sql("select age,name from t where age > 3");
JavaRDD<Row> rowJavaRDD = row.javaRDD();
System.out.println(rowJavaRDD.collect());
}
输出结果
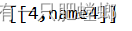
中文输出乱码
测试文件 testcsv.csv
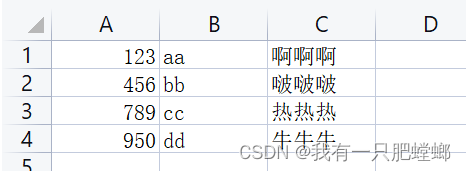
public void testSparkCsv() {
String file = "D:\\TEMP\\testcsv.csv";
JavaRDD<String> fileRDD = javaSparkContext.textFile(file);
JavaRDD<String> wordsRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator());
//输出结果
System.out.println(wordsRDD.collect());
}
输出结果,发现中文乱码,可恶
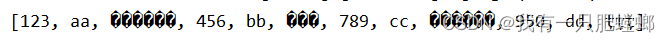
原因:textFile 读取文件没有解决乱码问题,但 sparkSession.read() 却不会乱码
解决办法:获取文件方式由 textFile 改成 hadoopFile,由 hadoopFile 指定具体编码
public void testSparkCsv() {
String file = "D:\\TEMP\\testcsv.csv";
String code = "gbk";
JavaRDD<String> gbkRDD = javaSparkContext.hadoopFile(file, TextInputFormat.class, LongWritable.class, Text.class).map(p -> new String(p._2.getBytes(), 0, p._2.getLength(), code));
JavaRDD<String> gbkWordsRDD = gbkRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator());
//输出结果
System.out.println(gbkWordsRDD.collect());
}
输出结果