ByteScout PDF Extractor SDK – 用于 PDF 到 JSON、PDF 到 Excel、CSV、XML、从 .NET 和 ASP.NET 从 PDF 中提取文本的 PDF 提取器库


| PDF Extractor SDK 是一套面向开发人员的高级 PDF 提取器和图像提取工具。 在您的应用程序中轻松设置强大的 PDF 提取器并自动提取表格、文本和其他数据。 |
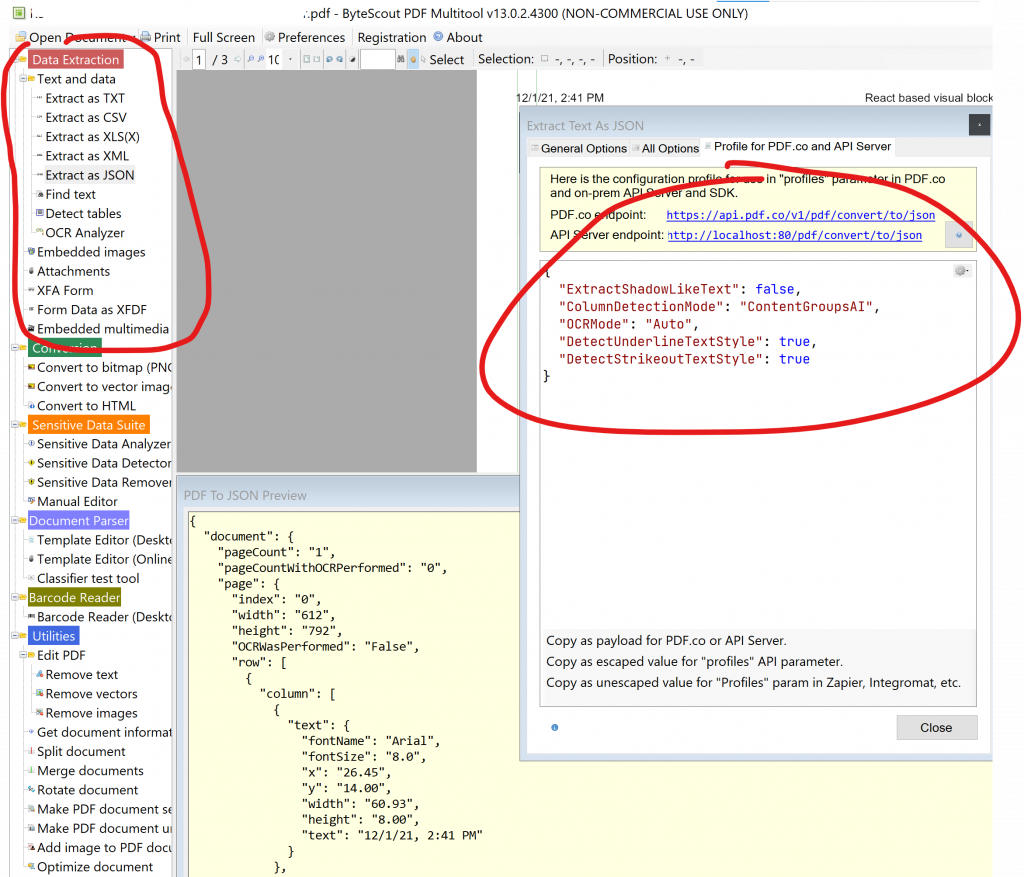
PDF 提取器支持的演示应用程序
主要优势
- 处理数百万个 PDF 文档: PDF Extractor 的高性能引擎在压力下完美运行,使其成为处理大量 PDF 报告、索引大型 PDF 库等的理想解决方案
- 易于使用和实施:无论您的 PDF 文档结构多么复杂,您都会发现 PDF Extractor 易于使用并可无缝集成到您现有的系统中
- 没有更多的提取错误: PDF Extractor 可以处理具有复杂结构的损坏文件,可以修复格式错误的文本,否则需要手动处理
- 多语言支持: PDF Extractor 支持混合语言和 Unicode 语言的文档。
- 离线工作,无需互联网;
- 10 多年的 PDF 提取器技术和专业知识;
- 提供比大多数类似的开源工具更快的上市时间;
在生产中的大型商业项目上经过实战测试;
包括对专家的支持。 - 支持扫描的、损坏的、格式错误的、混合的PDF、扫描的PDF、扫描的图像;
- 支持非拉丁语言、Unicode 支持、混合语言支持的高级 OCR ;
- 适用于.NET和ASP.NET支持(.NET 2.0、4.5 及更高版本,Windows 上的 .Net Core Framework);
- 可以从脚本和遗留编程语言中使用,如 ASP、VBScript、VB6(通过类似 ActiveX 的界面);
- 全套高级工具:将扫描件转换为可搜索的 PDF、拆分和合并 PDF、删除文本、分析、查找、检测和删除 PDF 和扫描文档中的敏感数据和个人身份信息 (PII);
- PDF提取专家的技术支持;
- 包括数百个源代码示例。
技术特点
- PDF Extractor SDK 将从PDF文件中提取文本,
- 将 PDF 转换为 JSON,将 PDF 转换为文本,从 PDF 中提取图像,将 PDF 转换为 CSV 或 Excel,将 PDF 转换为 XML。
- 使用自动和 AI 驱动的 OCR(图像文本识别)将PDF 转换为文本,将 PDF 转换为 JSON/XML/XLSX 其他 PDF 提取器转换为文本;
- OCR(图像到文本)支持英语、德语、西班牙语、日语、韩语和许多其他语言。支持混合语言 OCR(例如同一页面上的英语 + 西班牙语)
- 使用正则表达式的高级文本搜索;
- 内置图像到文本 OCR 过滤器以处理嘈杂的图像(例如扫描不当的文档);
- 修复损坏的文本对象(当 PDF 显示正确的文本但如果您选择并复制它已损坏);
- 与所有字符编码(包括 Unicode)无缝协作;
- 提取 PDF 文档信息(页数、书签)和元数据(文件作者、标题、描述等);
- 提取表格并将其转换为CSV或XML;
- 使用 .XLS 和 .XLSX 作为输出将表格和文本对象从 PDF 提取到 Excel;
- 提取嵌入的图像和附件;
- 将 PDF转换为 Excel,将 PDF 转换为 CSV,将 PDF 转换为 XML;
- 提取表格并将其转换为 CSV,可以轻松将其转换为 MS Excel 格式。
- 转换为 Excel、CSV或XML;
- 包括一组额外的工具,例如保护您的 PDF 不被复制或搜索的工具、 合并或拆分PDF 文档的工具、删除文本、删除和重新排列页面的工具;