- 文献题目:Bi-Link: Bridging Inductive Link Predictions from Text via Contrastive Learning of Transformers and Prompts
- 发表期刊:WWW2023
- 代码: https://anonymous.4open.science/r/Bi-Link-2277/.
摘要
- 归纳知识图的完成需要模型来理解关系的底层语义和逻辑模式。 随着预训练语言模型的进步,最近的研究设计了用于链接预测任务的转换器。 然而,实证研究表明,线性化三元组会影响关系模式的学习,例如反转和对称性。 在本文中,我们提出了 Bi-Link,这是一种对比学习框架,具有用于链接预测的概率语法提示。 使用 BERT 的语法知识,我们可以根据学习到的泛化到大型知识图谱的句法模式有效地搜索关系提示。 为了更好地表达对称关系,我们设计了一个对称链接预测模型,在前向预测和反向预测之间建立双向链接。 这种双向链接在测试时适应灵活的自集成策略。 在我们的实验中,Bi-Link 在链接预测数据集(WN18RR、FB15K-237 和 Wikidata5M)上的表现优于最近的基线。 此外,我们将 Zeshel-Ind 构造为连接环境的域内归纳实体以评估 Bi-Link。 实验结果表明,我们的方法产生了鲁棒的表示,可以在域转移下进行泛化。 我们的代码和数据集可在 https://anonymous.4open.science/r/Bi-Link-2277/ 上公开获得。
引言
- 知识图谱是结构化的事实数据库,将实体表示为节点,将关系表示为边。 对于开放式传入数据,自动完成知识图对于知识密集型任务(例如问答 [19] 和对话系统 [25])来说是一个价值数十亿美元的问题。 作为一种特别流行的范式,TransE [2] 最初提出了一种用于知识表示的加性模型。 尽管它很简单,但 TransE 已经对关系模式(例如反转和组合)进行了建模。 ComplEx [30] 表示具有实嵌入空间和虚嵌入空间的对称关系。 通过乘法模型,RotatE [27] 已将表达能力扩展到大多数一般模式,包括反对称性和自反性。
- 然而,现实世界中的链接预测是一个归纳学习过程,如图 1 所示,其中模型不仅需要理解逻辑模式,还需要对看不见的实体进行推理。 为了在归纳环境中表现良好,模型应该掌握知识图谱的关系语义,即关系之间的逻辑规则。 例如,一个智能模型应该具有将实体放入逻辑框架的归纳能力,如下
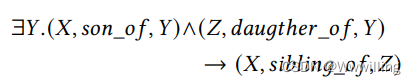
- DKRL [36] 是一种开创性的归纳链接预测方法,它建议从实体描述中建立这些逻辑规则。 KEPLER [34] 结合了三元组的逻辑和实体描述的语义,并通过预训练语言模型 (PLM) 的进步进行了编码。 损失函数是 TransE 损失和掩码语言建模损失的线性组合。 不幸的是,该方法收敛速度出乎意料地慢,并且对实体描述中的噪声表现出敏感性。 借助高效的双编码器,SimKGC [33] 使用归一化对比损失 [3] 有效地比较了知识表示。 由于收敛速度非常快,这种简单的方法在 FB15k-237 上完成链路预测需要 10 分钟,而 KEPLER 需要 20 小时。
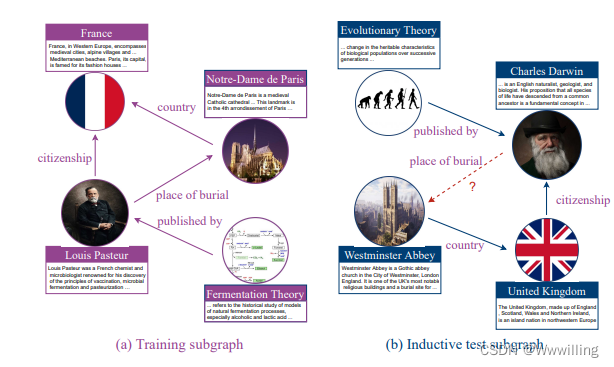
- 图 1:知识图中归纳链接预测的玩具示例。 训练子图和测试子图具有相互关系但不相交的实体。 实体描述可以帮助从训练子图的实体(紫色)到测试子图的不可见实体(蓝色)的结构泛化。
- 然而,实证研究表明,最近的对比链接预测方法严重依赖语义匹配而忽略了底层的图形结构。 我们假设有缺陷的初始化是对比表示学习不佳的罪魁祸首。 换句话说,PLM 很难估计线性化关系表达式和实体之间的相似性,例如,将“X 的反向兄弟”与“Z”进行比较。
- 这种现象至少揭示了两个问题。 首先,不同的语义需要不同的方式来表达反转。 受最近的提示调优研究 [6、13] 的启发,我们生成了基于规则的提示,以提高不同类型语法下关系表达式的流畅性。 以句法为原则查找提示,既提高了可解释性,又降低了提示查找的难度,因为英语没有太多的语法规则。 具体来说,我们在词性标注任务上对 PLM 进行微调,以将语法和文本编码到相同的语义空间中。 使用 PLM 的嵌入,在图 2 中,我们训练了一个多层感知器来预测平滑低维空间中的句法模式。 然后,高斯混合模型为一对可逆提示建立索引,用于前向和后向链接预测。 我们将提示和未完成的边缘组合为关系表达式,以更好地微调双编码器以进行归纳链接预测。 MLP 和双编码器的参数使用期望最大化 (EM) 算法 [14] 进行更新。
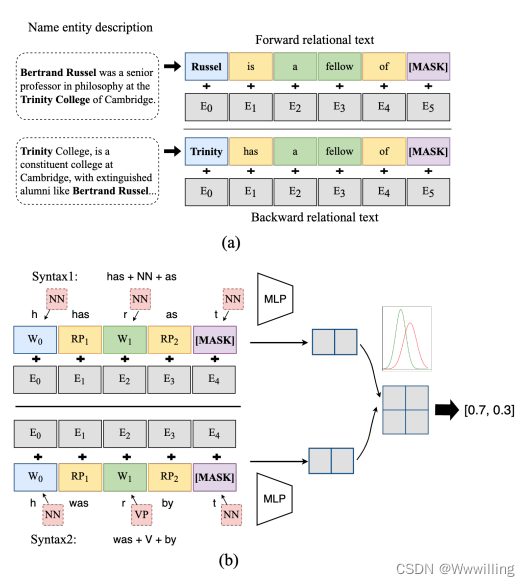
- 图 2:概率句法提示。 (a) 语法为 NN NN NN 的可逆提示。 (b) 预训练中嵌入 POS 的轻量级句法提示生成器。
- 另一个问题是最近的对比表示学习破坏性地影响了对称关系建模。 对称性在神经计算中有着根深蒂固的基础 [38]。 为了提高对称性的表现力,我们引入了关系双编码器之间的双向链接(图 3),简称为 Bi-Link。 给定关系表达式,Bi-Link 从两个方向理解一个三元组,更好地理解像“兄弟”这样的对称关系。 有趣的是,在训练中学到的双向链接适应了测试时间增强的灵活的自集成选项。 Bi-Link 在我们关于转导和归纳链接预测任务的实验中优于最近的基线。
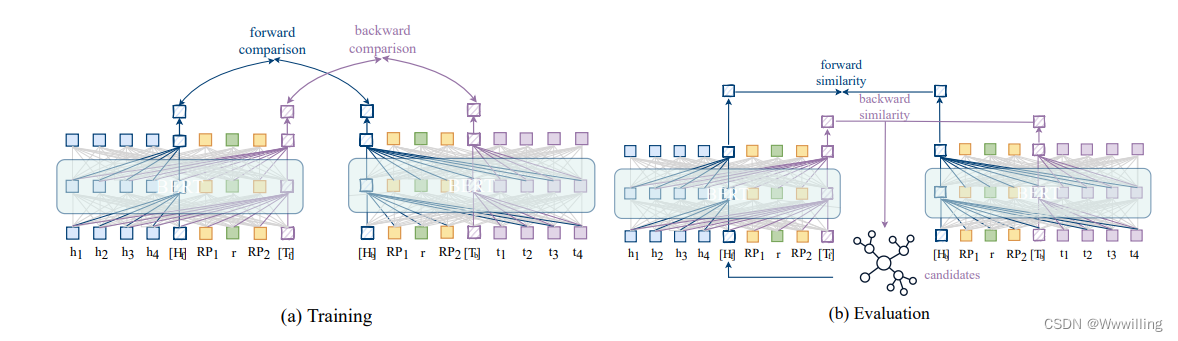
- 图 3:拟议的 Bi-Link 模型概述,一个由一对变压器编码器组成的孪生网络。 (a) 在前向预测中,尾实体用相关头实体的描述(蓝色)、基于规则的提示(黄色)和关系(绿色)表示为 [𝑇𝑓]。 在反向预测中,头部实体用相关尾部实体的描述(紫色)、基于规则的提示(黄色)和关系(绿色)表示为 [𝐻𝑏]。 对比学习将同一三元组的 [𝐻] 和 [𝑇] 拉在一起,同时将负批内对分开。 (b) 在评估过程中,双向链接效应允许预测一个方向以改进另一个方向。 它还通过将 [𝐻𝑓] 与其新邻居 [𝐻𝑏] 平均来启用事后实体嵌入更新。
- Bi-Link 只需最少的修改即可应用于知识密集型任务。 凭借丰富的词汇和句法语义,实体链接任务对所有候选文档进行排序,以预测从上下文中提及的命名实体到其所指实体文档的链接。 最近,Zeshel [16] 极大地支持了 PLM 的零样本评估,其实体链接语料库超出了集中用于预训练的事实知识库。 然而,Zeshel 结合了零样本学习和无监督领域适应的任务。 从技术上讲,这对不同模型和训练方法的错误分析造成了事实上的痛苦。 在这项工作中,我们创建了一个域内零样本实体,将基准 ZeshelInd 与 Fandom 的数据链接起来。 为了使我们的模型适应零样本实体链接,我们对提及跨度使用共享软提示,而不是双方都使用提示。 除了最近在 SimCSE [7] 和 SimKGC [33] 中使用的对比技术外,我们还选择在批次样本中共享 BM25 [24] 检索到的阴性候选者。 我们的方法在 Zeshel-Ind 和 Zeshel 上都取得了有竞争力的结果。 我们的实验还显示了对比学习向领域转移的有趣行为。
- 总之,我们的主要贡献有三方面:1.) 我们提出了一种概率句法提示方法,使用可泛化的轻量级模型将未完成的边缘表达为自然关系表达式。 2.)我们设计了对称关系编码器Bi-Link,用于基于文本的知识图谱链接预测,并将其应用于实体链接任务。 =3.) 我们构建了一个新的开源基准 Zeshel-Ind 作为 Zeshel 的全归纳反映,用于域内零样本性能评估。 我们使用最近在 Zeshel 和 Zeshel-Ind 上的几个基线广泛验证了 Bi-Link。
相关工作
- 对比知识表示。 Contrastive knowledge representation 受 NCE [8] 原理的启发,CPC [22] 和 SimCLR [3] 是特别流行的对比学习范例,它们使用嘈杂的负样本学习鲁棒表示。 对于语义文本相似性任务 (STS),SimCSE [7] 显着简化了以前使用双变换器的对比句子嵌入方法。 PromptBERT [10] 通过模板去噪进一步改善了结果。 然而,实证研究 [32] 表明 SimCSE 对实体链接没有帮助。 使用双变换器来对比文档表示仍然是一个正在进行的研究方向。 找到合适的负样本对于对比学习至关重要 [33]。 GPL [32] 使用管道自动找到高质量负样本,包括 T5 [23]、密集检索器 [24] 和交叉编码器 [9]。 在这项工作中,我们将在子图上学习的轻量级句法提示生成器推广到大型知识图。 提示通过将未完成的边缘转移到近似关系表达式来提高负样本的质量。
- 使用预训练的变压器进行检索。 双编码器独立地将查询和文档映射到共享的语义空间,以有效地计算它们的相似性分数。 相比之下,交叉编码器 [37] 广播一个查询并将其与所有可能的文档连接起来,通过查询和文档之间的交叉注意力来预测相关性分数。 之前的工作 [9] 表明交叉编码器可以产生更健壮的表示并取得更好的结果。 但是繁琐的计算开销严重增加了推理时间。 为了解决这个问题,ColBERT [12] 和 TwinBERT [18] 同时提出了由双编码器和交叉注意层组成的混合网络。 因此,这些工作通过在保持性能的同时显着减少计算负担,促进了现实世界的搜索引擎。 另一方面,后期交互需要额外的训练数据和策略。 我们的工作与之前的工作不同,因为当查询是零散的单词时,我们基于提示的双编码器会很有用。
方法
- 给定一个有向知识图 G = ( 𝑉 , 𝐸 , 𝑅 ) G = (𝑉 , 𝐸, 𝑅) G=(V,E,R) 和 ∣ 𝑉 ∣ |𝑉| ∣V∣ 实体, ∣ 𝐸 ∣ |𝐸| ∣E∣ 观察到的边缘,和 ∣ 𝑅 ∣ |𝑅| ∣R∣ 关系类型,我们的转导链接预测任务是推断缺失边 𝑒 描述为 ( h , 𝑟 , ? ) (ℎ, 𝑟, ?) (h,r,?) 或其逆版本 𝑒𝑖𝑛𝑣 描述为 ( ? , 𝑟 , 𝑡 ) (?, 𝑟, 𝑡) (?,r,t)。 作为逻辑运算符,三元组 ( h , 𝑟 , 𝑡 ) (ℎ, 𝑟, 𝑡) (h,r,t) 由头实体、关系和尾实体组成。 在这项工作中,我们提出了 Bi-Link,这是一个对称框架,它从实体描述和可逆关系文本中学习知识表示。 如图 2 所示的示例,我们使用由基于概率规则的提示表达式表达的反向关系文本信息来丰富 G G G。 然后我们使用孪生网络 Bi-Link 对关系信息进行编码(图 3)。 语法模块和Bi-Link网络用EM算法更新。 我们使用这个通用框架进行转导链接预测、全归纳链接预测 [28]、归纳命名实体链接。
- 图 2 和图 3 概述了提议的框架,下面对每个步骤进行了更详细的解释。
基于概率规则的提示
- 为了减少双编码器之间的语义差距,我们引入了基于概率规则的提示 (RP) 以利用 PLM 中的隐式知识。 为了从上下文嵌入中获取语法信息,我们按照 RoBERTa [15] 的过程在标记数据集 PennTreeBank [21] 的知名部分上微调 BERT [5]。 我们使用这个微调的 BERT 作为知识图链接预测的主干。 给定命名实体描述
𝑥
=
[
𝑤
1
,
𝑤
2
,
.
.
.
𝑤
𝑛
]
𝑥 = [𝑤_1,𝑤_2, ...𝑤_𝑛]
x=[w1,w2,...wn] 和实体的流出边之一
𝑒
𝑖
=
(
h
𝑖
,
𝑟
𝑖
,
[
𝑀
𝐴
𝑆
𝐾
]
)
𝑒_𝑖 = (ℎ^𝑖, 𝑟^𝑖, [𝑀𝐴𝑆𝐾])
ei=(hi,ri,[MASK]),如图2所示,我们迭代地将边缘与语法规则库中所有可能的提示
T
𝑓
𝑜
𝑟
𝑤
𝑎
𝑟
𝑑
T_{𝑓𝑜𝑟𝑤𝑎𝑟𝑑}
Tforward 结合起来。
T
𝑓
𝑜
𝑟
𝑤
𝑎
𝑟
𝑑
T_{𝑓𝑜𝑟𝑤𝑎𝑟𝑑}
Tforward 的大小是
m
m
m。 标记化后,我们将标记和位置输入 BERT 嵌入层并取平均嵌入。 这些关系嵌入然后通过 MLP,投影为低维表示
𝑥
𝑖
𝑥_𝑖
xi。 然后我们计算高斯混合模型的责任并应用标签锐化,允许更新最高预测。 选择具有边缘的模板的概率可以正式地写为
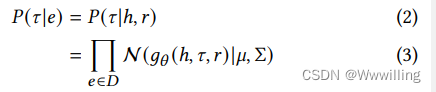
- 其中
τ
\tau
τ表示对应于句法模式的模板。
𝑔
𝑔
g,一个用
θ
\theta
θ参数化的浅层编码器,将不完整边的嵌入和最后一次迭代的提示编码到较低维空间中。
μ
\mu
μ和
Σ
Σ
Σ是高斯混合模型的参数。 簇数
𝑘
𝑘
k 是一个超参数。 这个句法提示生成器和双编码器的参数更新了EM算法,
M
M
M步可以写成如下,
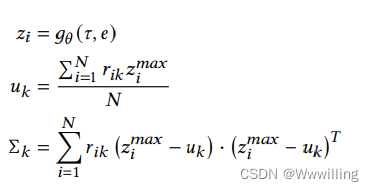
- 其中 𝑢 𝑘 𝑢_𝑘 uk和 Σ 𝑘 Σ_𝑘 Σk是第 k k k个高斯分量的均值和协方差, 𝑟 𝑖 𝑘 𝑟_{𝑖𝑘} rik是责任, 𝑧 𝑖 𝑚 𝑎 𝑥 𝑧^{𝑚𝑎𝑥}_𝑖 zimax是最可能的基于提示的关系表达式。 此外,GMM 的参数使用验证集的手动标记子集的统计数据进行初始化。 注释者根据 [English-Corpora](https://www.english-corpora]。 使用最可能的句法提示,我们将流出边和流入边表达为输入空间中的关系表达式 𝑣 ( 𝑒 h 𝑟 ) 𝑣(𝑒_{ℎ𝑟}) v(ehr) 和 𝑣 ( 𝑒 𝑟 𝑡 ) 𝑣(𝑒_{𝑟𝑡}) v(ert)。
KG链接预测
- 在图 3 中,Bi-Link 使用双变换器对关系表达式和实体之间的相似性进行评分,这是本文中的排序问题。 在前向链接预测中,Bi-Link 对尾部实体的概率进行建模,给定头部实体的关系表达式为
𝑃
(
𝑡
∣
h
,
𝑅
𝑃
1
,
𝑟
,
𝑅
𝑃
2
)
𝑃(𝑡|ℎ, 𝑅𝑃_1, 𝑟, 𝑅𝑃_2)
P(t∣h,RP1,r,RP2)。 同样,后向概率可以表示为
𝑃
(
h
∣
𝑅
𝑃
1
,
𝑟
,
𝑅
𝑃
2
,
𝑡
)
𝑃(ℎ|𝑅𝑃_1, 𝑟, 𝑅𝑃_2, 𝑡)
P(h∣RP1,r,RP2,t)。 该模型可用于转导学习 [2] 和归纳学习 [28] 任务,上下文关系表示可以写成
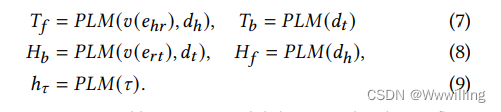
- 其中 PLM 是一种预训练语言模型,它将流出边 𝑣 ( 𝑒 h 𝑟 ) 𝑣(𝑒_{ℎ𝑟}) v(ehr) 和头实体的描述 𝑑 h 𝑑_ℎ dh 编码为前向关系表示 𝑇 𝑓 𝑇_𝑓 Tf。 类似地,在反向链接预测中,PLM 将流入边 𝑣 ( 𝑒 𝑟 𝑡 ) 𝑣(𝑒_{𝑟𝑡}) v(ert) 和尾部实体的描述编码为反向关系表示 𝐻 𝑏 𝐻_𝑏 Hb。使用注意掩码,头部和尾部实体描述被编码为 𝐻 𝑓 𝐻_𝑓 Hf 和 𝑇 𝑏 𝑇_𝑏 Tb。在图 3 中, 这些表示是从关系标记的地方输出的。 h τ ℎ_\tau hτ 是用于模板去噪的基于规则的提示 τ \tau τ 的表示 [10]。
- 我们通过将前向预测和后向预测的文本关系嵌入拉在一起来学习链接预测的嵌入,训练目标写为
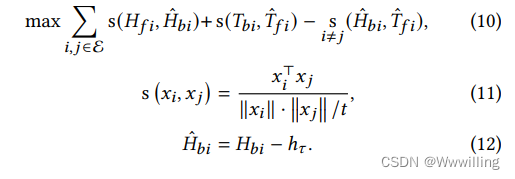
- 其中 E E E 是实体集, s s s 是嵌入之间的缩放余弦相似度。 等式 10 的第三项惩罚基于提示模式的朴素匹配。 𝑡 𝑡 t 是温度参数。 𝑇 ^ 𝑓 𝑖 \hat𝑇_{𝑓 𝑖} T^fi 和 𝐻 ^ 𝑏 𝑖 \hat𝐻_{𝑏𝑖} H^bi 是去噪模板。 最初在 PromptBERT [10] 中提出,模板去噪通过消除提示的句法偏差来改进对比句子嵌入。
- 在实践中,我们使用以下对比损失函数优化等式 10 中所示的训练目标:
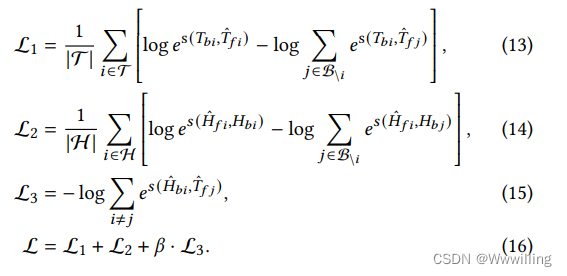
- 其中 H H H 和 T T T 是头部和尾部实体的文本表达集。 B B B 是当前批次的集合,Font metrics not found for font: . 是双向链接系数。
- 在测试阶段,为了预测缺失的流入边
(
?
,
𝑟
,
𝑡
)
(?, 𝑟, 𝑡)
(?,r,t),我们计算了语言化关系表达式
(
𝑣
(
𝑒
𝑟
𝑡
)
,
𝑑
𝑡
)
(𝑣(𝑒_{𝑟𝑡}), 𝑑_𝑡)
(v(ert),dt) 和所有实体描述
𝑑
h
𝑑_ℎ
dh 之间的双向相似度得分。 在图 3 中,Bi-Link 通过自集成增强测试性能,正式写为,
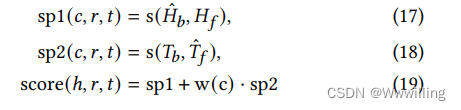
- 其中 s p 1 sp1 sp1 和 s p 2 sp2 sp2 是从两个角度评分的相同文本序列。 𝑐 ∈ C 4 是 4 s p 1 𝑐 ∈ C4 是 4sp1 c∈C4是4sp1 建议的候选集。 w ( c ) w(c) w(c) 是一个灵活的加权函数。 为简单起见,我们遵循 TransE 的过滤设置。 请注意,在建模反转模式和对称模式之间没有冲突,因为尾部实体可以使用第 3.1 节中提到的基于规则的可逆提示代替头部实体。
归纳实体链接
- 当一组新的实体进入数据库时,在当前社会的先前记录中从未真正提及过它们。 对于来自这个时间戳的新帖子,我们希望将新出现的提及链接到新实体,同时消除它们与旧实体的歧义。 例如,在发布了一些新的虚构人物后,管理员希望删除一些令人不安的新提及的敏感话题,这些话题很容易滋生社会仇恨。 因此,我们给出与以下定义相联系的归纳实体的正式定义。
- 定义 给定提及的集合
M
M
M,实体集
E
E
E,候选集
C
C
C和特定的文本域
D
D
D,诱导实体链接满足
∀
𝑐
∈
C
∀𝑐∈C
∀c∈C,
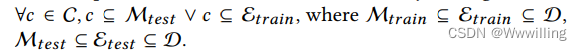
- 由于没有明确的关系结构,归纳实体链接是一项知识密集型信息检索任务,需要语义来消除域内命名实体提及的歧义。 在下面的实验中,我们将 Bi-Link 的零样本性能与定义的归纳设置和另一个跨域设置下的交叉编码器基线进行比较。
实验
- 我们设计了实验,从以下几个方面评估我们提出的方法:
- 转导链接预测。 在转导知识图完成任务中,三元组被分成训练集、验证集和测试集,但实体在不同的集合之间共享。 此设置要求模型从训练数据中理解关系句法框架,并通过将合理的实体放入框架中来预测缺失的关系。
- 归纳关系预测。 在 GraIL [28] 中提出的完全归纳设置中,关系在训练、验证和测试三元组之间共享,但实体是不相交的。 具体来说,归纳知识图数据集由一对图、训练子图和归纳测试子图组成。 这两个图具有相互关系但不相交的实体。 组成新的实体和关系,模型必须学习与实体无关的关系语义来完成知识图谱。
- 归纳实体链接。 这种归纳设置的目标是预测提及与其所指实体之间的联系。 提及项和实体来自混合域,并且不连续地分为训练集、验证集和测试集。 为了消除实体提及的歧义,模型应该在其上下文中学习提及的潜在语义。 另一方面,这些语义应该反映所指实体和相似候选者之间的区别。
- 跨域归纳实体链接。 数据拆分在域级别上,其中一些域被指定为训练域,其余域被指定为评估域。 跨域归纳设置比归纳设置更难,因为在提及上下文和实体描述之间存在域转换。
数据集
-
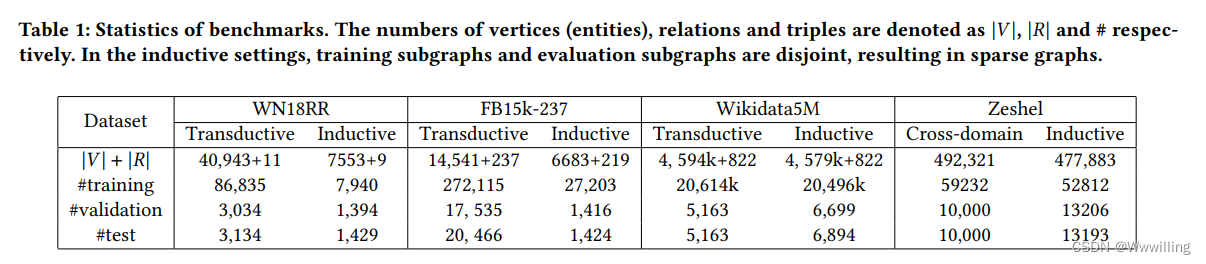
我们实验中使用的数据集的统计数据如表1所示。 WN18RR [2]、FB15k-237 [29] 和 Wikidata5M [34] 是文献中可用的链接预测标准基准。 这些数据集实际上是通过其原始设计为转导链接预测而构建的。 为了评估归纳链接预测,我们采用 GraIL [28] 的数据拆分,其中训练样本和测试样本的实体来自不相交的子图。 对于实体链接,我们将 Zeshel [16] 视为跨域实体链接基准。 该数据集包含专门针对不同主题(例如虚构世界或平行宇宙)的社区编写的百科全书。 实体和提及来自 16 个主题,其中 8 个用于训练,每 4 个用于验证和测试。 不同的主题没有相互提及或实体。 Zeshel 是评估归纳学习方法的绝佳基准。 具体来说,通常作为主体出现的实体可能在 Fandom 中作为客体出现。
-
为了区分归纳实体链接与域适应,我们创建了 Zeshel-Ind,这是一个具有不相交实体提及拆分的域内零样本基准。 详细地说,我们首先在每个域中创建一个实体提及集,并通过统一抽样提及而不进行替换,将这些集合分成训练、验证和测试子集。 因此,子集具有不相交的实体。 在我们的实验中,我们使用 Apache Lucene [26] 检索前 64 个候选者。 我们删除没有任何粗略搜索候选的样本。 这些硬阳性对仅占整个种群的 0.1%,也未用于 [16] 的评估。 对于少于 64 个候选的样本,我们添加随机抽样的域内文档,直到候选列表的长度为 64。这些样本占数据集的 23%。 我们从候选文档中删除实体名称以避免潜在的标签泄漏,并惩罚朴素的文本匹配。 最后,我们相应地将不同域的子集合并为三个数据拆分,即训练集、验证集和测试集。
实施细节
- 知识图链接预测。 在转导链接预测设置中,我们对三个不同大小的 KG 进行实验,节点数量从 ∼15k 到 ∼5M 不等。 至于浅层嵌入模型,我们使用了由 GraphVite [39] 实现的 TransE [2]、ComplEx [30] 和 RotatE [27] 的代码并报告了结果。 我们重新实现 KG-BERT [37],并重用 KEPLER [34] 和 SimKGC [33] 的官方实现作为基线。
- 考虑到关系的多样性,我们根据关系语法的出现频率来选择句法规则集的大小。 在 WN18RR 的实验中,我们将规则集的大小和隐藏维度的数量设置为 8,即 8 对可逆关系提示。 在FB15k-237和Wikidata5M的实验中,规则集的大小为32,即32对细粒度语法。 特别是,我们在前向链接预测中使用前向关系模板,在反向链接预测中使用反向关系模板。 在训练过程中,我们使用 3.1 节介绍的高斯混合模型进行软关系规则选择。 在测试阶段,在评估单个模型时,我们使用当前三元组 $(ℎ, 𝑟, [𝑇]) $或 ( [ 𝐻 ] , 𝑟 , h ) ([𝐻], 𝑟, ℎ) ([H],r,h) 概率最高的关系模板,为该关系表达式建议更频繁的语法。 我们使用图 3 (b) 所示的双向预测的平均值。
- 由于计算限制,我们截断了超过 64 位的实体描述,并用邻居的实体名称填充这些短描述以烘焙邻居信息。 为了与其他基线进行公平比较,我们使用 BERT [5] 作为所有链接预测方法的默认预训练语言模型。 我们使用 Hugging Face 的 bert-base-uncased 的权重初始化双编码器,并分别更新它们以进行公平比较。 使用更好的预训练语言模型作为编码器有望进一步提高性能。 在训练和测试中,从屏蔽实体位置中提取的嵌入在评分之前通过模板归一化以零为中心。 使用 AdamW [17] 作为优化器,我们使用 500 个预热步骤和线性衰减策略从 {1e-5, 2e-5, 5e-5} 网格搜索学习率。 权重衰减参数为1e-4。 所有结果都在 3 个随机种子上运行。
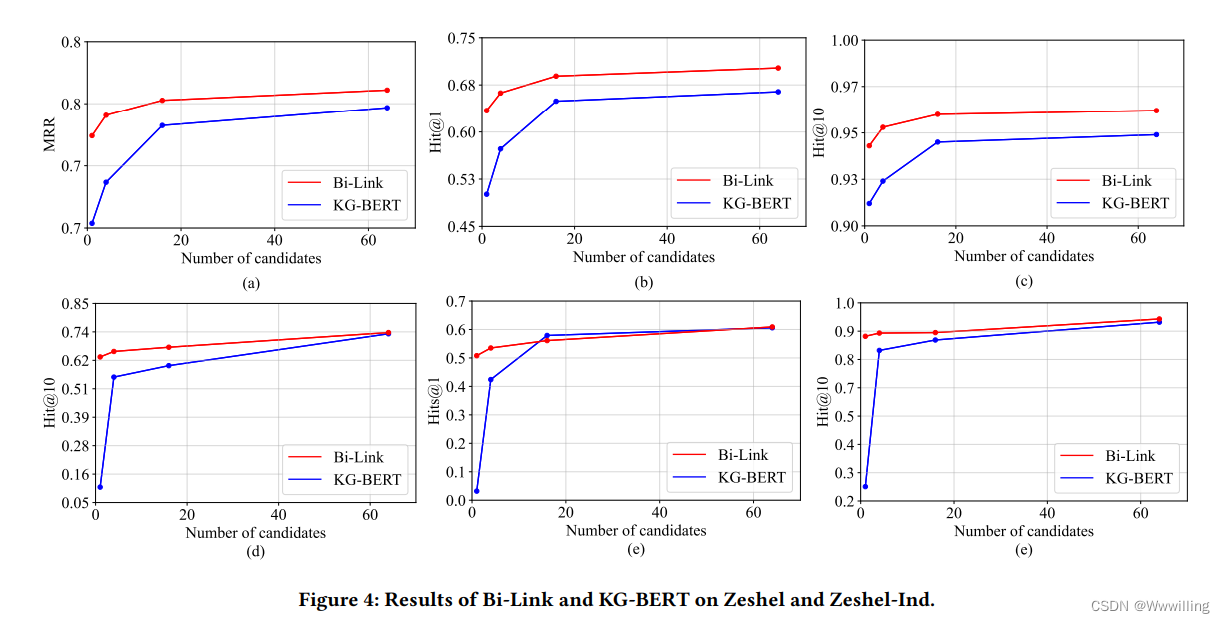
- 实体链接。 实体链接对所有候选文档进行排名,以预测从上下文中提及的命名实体到其所指对象的链接。 与知识图链接预测不同,我们的实体链接任务不提供明确的关系,而是提供固定大小的候选集,如图 4 所示。对于每个提及实体对,指称实体文档标记为 1,否定候选者标记为 0。与语义文本相似性提示类似,关系提示不一定是概率性的。 为了公平比较,我们在所有实验中将最大序列长度固定为 64。
指标
- 遵循 TransE [2] 的基于等级的标准评估协议,我们在封闭世界假设 (CWA) 下评估我们的链接预测方法的性能。 特别是,我们报告了上述四个链接预测任务中 Bi-Link 的平均倒数排名 (MRR) 和 H i t s @ k ( 𝑘 ∈ { 1 , 3 , 10 } ) Hits@k (𝑘 ∈ \{1, 3, 10\}) Hits@k(k∈{1,3,10})。 对于转导 KG 链接预测,KG 中的所有实体在评估期间都被视为候选对象。 MRR 是测试三元组中标记的实体的平均倒数排名。 H i t s @ k Hits@k Hits@k 计算标签实体在 top-k 预测中排名的比例。 对于全归纳链接预测,我们还报告了所有实体之间的排名结果。 请注意,我们的评估与 GraIL 的评估不同,GraIL 使用概率局部世界假设随机抽取节点作为候选集。 对于实体链接,每个提及实体对都有一个候选集,其中包括参考实体的文档、粗略搜索的文档和随机抽样的域内文档。 MRR 和 Hits@k 是在这些候选集中计算的。
结果
-
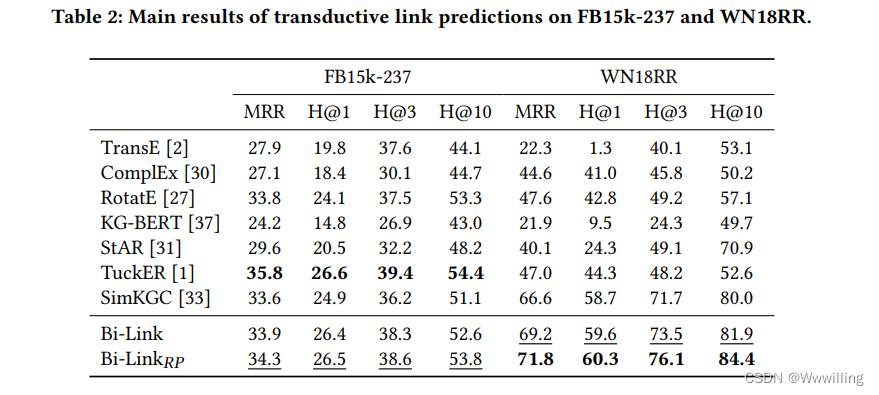
转导链接预测。 我们在表 2 中报告了转导链接预测的结果。 我们的实验表明,对比学习可以有效地从实体和关系的文本描述中提取语义。 通过双尾 t t t检验,BiLink 产生了统计上显着的改进,证明了后向和前向文本链接预测之间双向链接的有效性。 基于概率规则的提示显示 WN18RR 比 FB15k-237 增加更多。 我们假设当关系简单且相应的语言听起来更自然时,概率 RP 模型的参数更容易学习。 因此,该模型不仅可以从反向提示中学习可逆关系嵌入,还可以使用所提出的孪生网络学习对称关系模式。
-
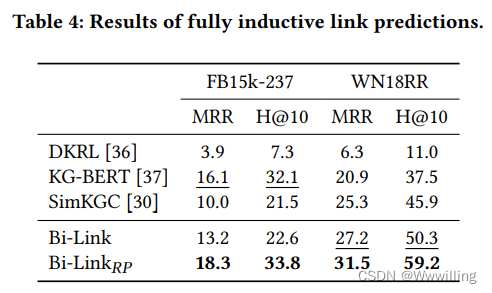
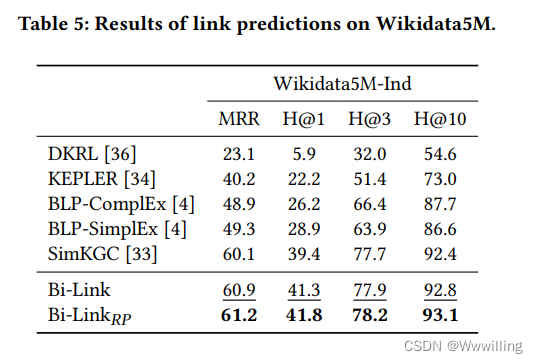
归纳链接预测。 我们在表 4 和表 5 中列出了归纳链接预测结果。在建模实体独立关系方面,由于细粒度提示,我们大大改进了基线。 SimKGC 的性能下降比 Bi-Link 更严重。 这可能是因为原始反演以外的关系是通过 SimKGC 中的数据隐式学习的,而 Bi-Link 具有明确的机制来模拟细粒度反演和对称关系模式。 通过我们的实验,我们确认了 PromptBERT [10] 中设计的模板去噪的有效性,以及自我否定 [33] 在归纳链接预测中的负面影响。
-
实体链接。 我们在表 3 中列出了 Zeshel(跨域)和 Zeshel-Ind 上实体链接的结果。前两行显示了 BERT [5] 和 SpanBERT [11] 的零样本性能,然后是基线方法和我们的方法的性能。 在 Zeshel-Ind 上,Bi-Link 的表现明显优于基线。 相比之下,Bi-Link 优于 KG-BERT 0.3%,表明对比学习容易受到领域转移的影响。 在图4中,我们以accuracy(Hits@1, MRR)和recall(Hits@10)作为分析标准。 我们的实验证明了高质量负样本的重要性。 在其他实验条件相同的情况下,使用所有 64 个候选者给出最好的结果。 在域内实体链接任务中,我们的方法在链接准确性和召回能力方面均优于 KG-BERT。

-
领域适应。 在跨域实体链接任务上,我们在准确性上与 KG-BERT 相当,但域内和跨域零样本性能之间的差距揭示了域转移的影响。 我们的方法在 Hits@10 上的最佳结果和稳健性均优于 KG-BERT,这意味着 Bi-Link 的召回能力优于 KG-BERT。 值得注意的是,由于批内比较和负候选共享技巧,当候选数量减少时,Bi-Link 仍然表现良好。 例如,在没有候选的情况下,域内 KG-BERT 在 Hits@1 上的准确率为 50.1%,MRR 为 0.655,而跨域 Bi-Link 的准确率为 50.8%,MRR 为 0.635,证明了我们方法的显着优势。 我们的实验表明,使用提及作为负样本会损害性能。
-
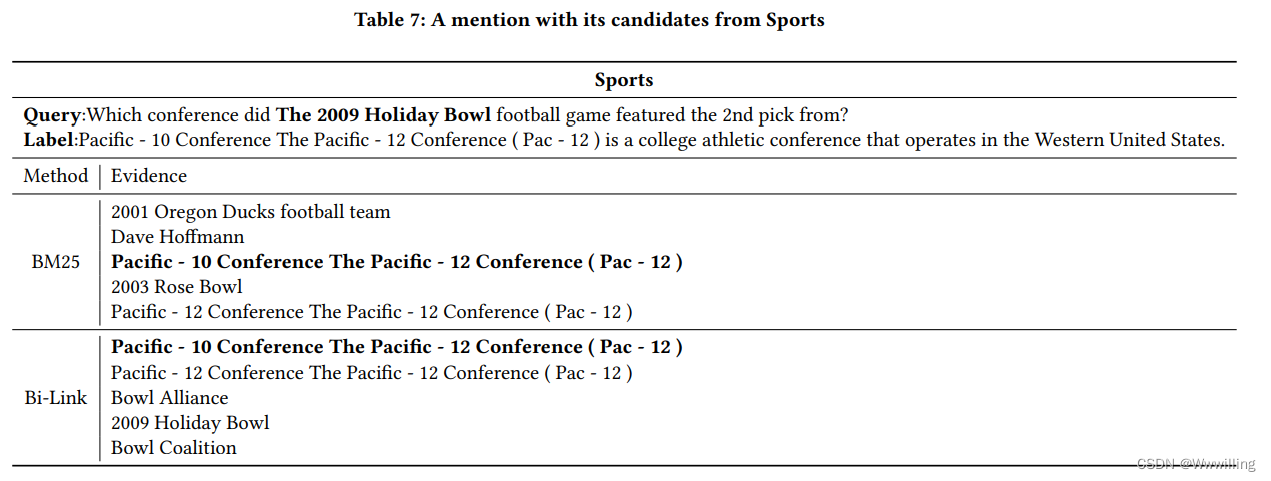
错误分析。 表6和7中的运行实例表明我们的方法是有效的。 我们注意到不同实体的文档可能指向同一个实体,如表 7 所示。 这是可以理解的,因为这个数据集是社区贡献的,并且在数据构建过程中可能存在偏差导致这种多对一的情况。 在这种情况下,在不同实体的文档极其相似的情况下,人们已经很难区分它们,这意味着它们都可以作为实体的链接。 在一定程度上,模型在这方面的判别能力甚至优于人类。

-
限制。 在这项工作中,离散提示由语言专家手动设计,这是非常昂贵的。 当知识库具有多种关系集合时,句法提示可能会给对比表示学习带来太多噪音。
结论
- 在本文中,为了学习基于文本的归纳链接预测模型,我们提出了一种有效的对比学习框架 Bi-Link,它具有基于概率规则的提示。 具体来说,为了创建自然的关系表达式,Bi-Link 框架首先从句法模式生成基于规则的提示。 我们使用 PLM 的语法知识学习高斯混合模型以进行语法预测。 为了更好地表达对称关系,我们设计了一个对称链接预测模型,在前向预测和反向预测之间建立双向链接。 双向链接在测试时适应灵活的自集成策略。 我们发布了用于域内零样本实体链接的 Zeshel-Ind 数据集。 实验结果表明,Bi-Link 框架可以通过文本学习鲁棒表示,用于知识图链接预测和实体链接任务。 未来的工作可以将路径信息合并到这个框架中,以产生更多可解释的知识表示。