目录
一、机械硬盘
二、SSD硬盘
(一)SSD硬盘的读写原理
1、SLC、MLC、TLC 和 QLC
2、P/E 擦写问题
(二)SSD 读写的生命周期
(三)磨损均衡、TRIM 和写入放大效应
1、FTL 和磨损均衡
2、TRIM 指令的支持
3、写入放大
(四)AeroSpike:如何最大化 SSD 的使用效率?
一、机械硬盘
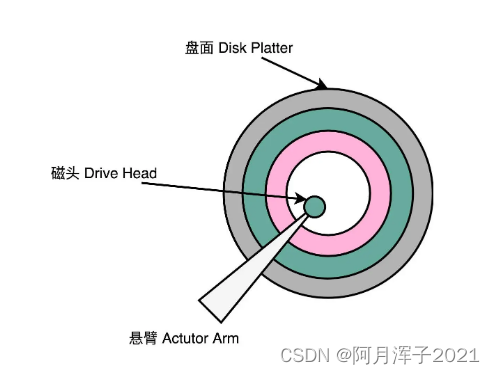
一块机械硬盘是由盘面、磁头和悬臂三个部件组成的。
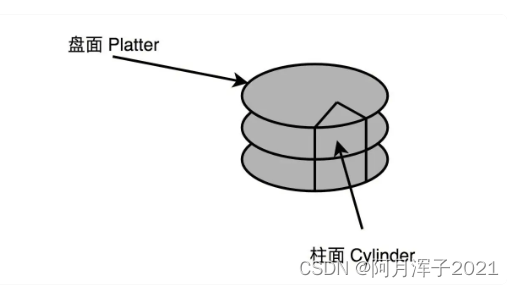
- 盘面(Disk Platter):其实就是实际存储数据的盘片。盘面本身通常是用的铝、玻璃或者陶瓷这样的材质做成的光滑盘片,盘面上有一层磁性的涂层,数据就存储在这个磁性的涂层上。盘面中间有一个受电机控制的转轴。这个转轴会控制盘面旋转。硬盘的转速指的就是盘面中间电机控制的转轴的旋转速度,英文单位叫 RPM,也就是每分钟的旋转圈数(Rotations Per Minute)。
- 磁头(Drive Head):数据是通过磁头,从盘面上读取到,再通过电路信号传输给控制电路、接口,再到总线上的。通常,一个盘面上会有两个磁头,分别在盘面的正反面。盘面在正反两面都有对应的磁性涂层来存储数据,而且一块硬盘也不是只有一个盘面,而是上下堆叠了很多个盘面,各个盘面之间是平行的。每个盘面的正反两面都有对应的磁头。
- 悬臂(Actutor Arm):悬臂链接在磁头上,并且在一定范围内会去把磁头定位到盘面的某个特定的磁道(Track)上。
磁道,会分成一个一个扇区(Sector)。上下平行的一个一个盘面的相同扇区叫作一个柱面(Cylinder)。
读取数据时,首先,把盘面旋转到某一个位置。在这个位置上,悬臂可以定位到整个盘面的某一个子区间。这个子区间叫作几何扇区(Geometrical Sector),在“几何”位置上,所有这些扇区都可以被悬臂访问到。其次,把悬臂移动到特定磁道的特定扇区,在这个“几何扇区”里面,找到实际的扇区。找到之后,落下磁头,就可以读取到正对着扇区的数据。
进行一次硬盘上的随机访问,需要的时间由两个部分组成:
平均延时(Average Latency):盘面选转后,悬臂定位到扇区的的时间。和机械硬盘的转速相关。随机情况下,平均找到一个几何扇区,需要旋转半圈盘面,
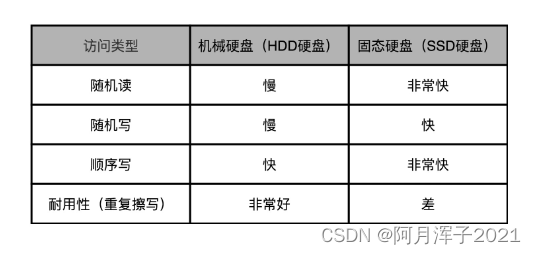
平均寻道时间(Average Seek Time):盘面选转后,悬臂定位到扇区的的时间。硬盘是机械结构的,只有一个电机转轴,也只有一个悬臂,所以没有办法并行地去定位或者读取数据。那一块 7200 转的硬盘,一秒钟随机的 IO 访问次数,也就是1s / 8 ms = 125 IOPS 或者 1s / 14ms = 70 IOPS。
如果进行顺序的数据读写,应该怎么最大化读取效率呢?可以选择把顺序存放的数据,尽可能地存放在同一个柱面上。这样,只需要旋转一次盘面,进行一次寻道,就可以去写入或者读取,同一个垂直空间上的多个盘面的数据。如果一个柱面上的数据不够,也不要去动悬臂,而是通过电机转动盘面,这样就可以顺序读完一个磁道上的所有数据。所以,其实对于 HDD 硬盘的顺序数据读写,吞吐率还是很不错的,可以达到 200MB/s 左右。
二、SSD硬盘
SSD 没有像机械硬盘那样的寻道过程,所以它的随机读写都更快。
(一)SSD硬盘的读写原理
对于 SSD 硬盘,可以先简单地认为,它是由一个电容加上一个电压计组合在一起,记录了一个或者多个比特。
1、SLC、MLC、TLC 和 QLC
能够记录一个比特很容易理解。给电容里面充上电有电压的时候就是 1,给电容放电里面没有电就是 0。采用这样方式存储数据的 SSD 硬盘,我们一般称之为使用了 SLC 的颗粒,全称是 Single-Level Cell,也就是一个存储单元中只有一位数据。
同样的面积下,能够存放下的元器件是有限的。如果只用 SLC,就会遇到存储容量上不去、价格下不来的问题。于是,硬件工程师们就陆续发明了 MLC(Multi-Level Cell)、TLC(Triple-Level Cell)以及 QLC(Quad-Level Cell),也就是能在一个电容里面存下 2 个、3 个乃至 4 个比特。
4 个比特一共可以从 0000-1111 表示 16 个不同的数。那么,如果能往电容里面充电的时候,充上 15 个不同的电压,并且电压计能够区分出这 15 个不同的电压。加上电容被放空代表的 0,就能够代表从 0000-1111 这样 4 个比特了。
不过,表示 15 个不同的电压,充电和读取的时候,对于精度的要求就会更高,会导致充电和读取的时候都更慢,所以 QLC 的 SSD 的读写速度,要比 SLC 的慢上好几倍。
2、P/E 擦写问题
SSD 硬盘的硬件构造自顶向下是这样的:
首先,和其他的 I/O 设备一样,它有对应的接口和控制电路。现在的 SSD 硬盘用的是 SATA 或者 PCI Express 接口。在控制电路里,有一个很重要的模块,叫作 FTL(Flash-Translation Layer),也就是闪存转换层,可以说是 SSD 硬盘的一个核心模块,SSD 硬盘性能的好坏,很大程度上也取决于 FTL 的算法好不好。
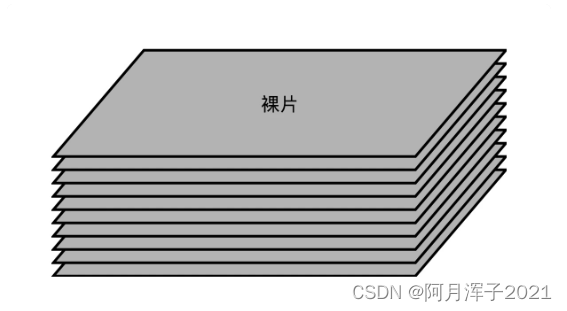
接下来是实际的 I/O 设备,它其实和机械硬盘很像。现在新的大容量 SSD 硬盘都是 3D 封装的了,也就是说,是由很多个裸片(Die)叠在一起的,就好像机械硬盘把很多个盘面(Platter)叠放再一起一样,这样可以在同样的空间下放下更多的容量。
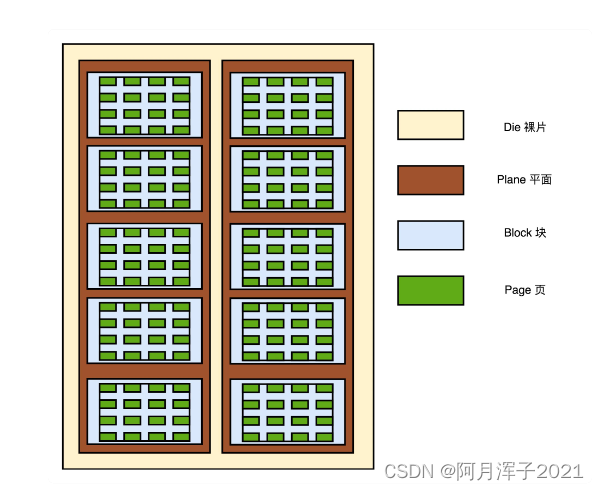
一张裸片上可以放多个平面(Plane),一般一个平面上的存储容量大概在 GB 级别。一个平面上面,会划分成很多个块(Block),一般一个块(Block)的存储大小, 通常几百 KB 到几 MB 大小。一个块里面,还会区分很多个页(Page),就和内存里面的页一样,一个页的大小通常是 4KB。
对于 SSD 硬盘来说,数据的写入叫作 Program。写入不能像机械硬盘一样,通过覆写(Overwrite)来进行的,而是要先擦除(Erase),再写入。SSD 的读取和写入的基本单位是页(Page),SSD 的擦除单位是块。
SSD 的使用寿命,其实是每一个块(Block)擦除的次数。 SLC 的芯片,可以擦除的次数大概在 10 万次,MLC 就在 1 万次左右,而 TLC 和 QLC 就只在几千次了。
(二)SSD 读写的生命周期
用三种颜色分别来表示 SSD 硬盘里面的页的不同状态,白色代表这个页从来没有写入过数据,绿色代表里面写入的是有效的数据,红色代表里面的数据,在操作系统看来已经是删除的了。

一开始,所有块的每一个页都是白色的。随着我们开始往里面写数据,里面的有些页就变成了绿色。然后,因为我们删除了硬盘上的一些文件,所以有些页变成了红色。但是这些红色的页,并不能再次写入数据。因为 SSD 硬盘不能单独擦除一个页,必须一次性擦除整个块,所以新的数据,我们只能往后面的白色的页里面写。这些散落在各个绿色空间里面的红色空洞,就好像硬盘碎片。
如果有哪一个块的数据一次性全部被标红了,就可以把整个块进行擦除。它就又会变成白色,可以重新一页一页往里面写数据。这种情况其实也会经常发生。毕竟一个块不大,也就在几百 KB 到几 MB。你删除一个几 MB 的文件,数据又是连续存储的,整个块就可以被擦除。
随着硬盘里面的数据越来越多,红色空洞占的地方也会越来越多。于是,我们就要没有白色的空页去写入数据了。这个时候,可以做一次类似于 Windows 里面“磁盘碎片整理”或者 Java 里面的“内存垃圾回收”工作。找一个红色空洞最多的块,把里面的绿色数据,挪到另一个块里面去,然后把整个块擦除,变成白色,可以重新写入数据。
不过,“磁盘碎片整理”或者“内存垃圾回收”的工作,不能太主动、太频繁地去做。因为 SSD 的擦除次数是有限的。如果动不动就搞个磁盘碎片整理,那么我们的 SSD 硬盘很快就会报废了。
一块 SSD 的硬盘容量,是没办法完全用满的。生产 SSD 硬盘的厂商,其实是预留了一部分空间,专门用来做“磁盘碎片整理”工作的。一块标成 240G 的 SSD 硬盘,往往实际有 256G 的硬盘空间。SSD 硬盘通过控制芯片电路,把多出来的硬盘空间,用来进行各种数据的闪转腾挪,让你能够写满那 240G 的空间。多出来的 16G 空间,叫作预留空间(Over Provisioning),一般 SSD 的硬盘的预留空间都在 7%-15% 左右。
仔细想想,SSD 硬盘特别适合读多写少的应用。在日常应用里面,系统盘适合用 SSD。但是,如果我们用 SSD 做专门的下载盘,一直下载各种影音数据,然后刻盘备份就不太好了,特别是现在 QLC 颗粒的 SSD,只有几千次可擦写的寿命。
在数据中心里面,SSD 的应用场景也是适合读多写少的场景。拿 SSD 硬盘用来做数据库,存放电商网站的商品信息很合适。但是,用来作为 Hadoop 这样的 Map-Reduce 应用的数据盘就不行了。因为 Map-Reduce 任务会大量在任务中间向硬盘写入中间数据再删除掉,这样用不了多久,SSD 硬盘的寿命就会到了。
(三)磨损均衡、TRIM 和写入放大效应
1、FTL 和磨损均衡
磨损均衡(Wear-Leveling)是让 SSD 硬盘各个块的擦除次数,均匀分摊到各个块上。实现这个技术的核心办法,就是添加一个间接层—— FTL 闪存转换层。
在 FTL 里面,存放逻辑块地址(Logical Block Address,简称 LBA)到物理块地址(Physical Block Address,简称 PBA)的映射。
操作系统访问的硬盘地址,其实都是逻辑地址。只有通过 FTL 转换之后,才会变成实际的物理地址,找到对应的块进行访问。操作系统本身,不需要去考虑块的磨损程度,只要和操作机械硬盘一样来读写数据就好了。
操作系统所有对于 SSD 硬盘的读写请求,都要经过 FTL。FTL 里面又有逻辑块对应的物理块,所以 FTL 能够记录下来,每个物理块被擦写的次数。如果一个物理块被擦写的次数多了,FTL 就可以将这个物理块,挪到一个擦写次数少的物理块上。但是,逻辑块不用变,操作系统也不需要知道这个变化。
这也是设计大型系统中的一个典型思路——各层之间是隔离的,操作系统不需要考虑底层的硬件是什么,完全交由硬件的控制电路里面的 FTL,来管理对于实际物理硬件的写入。
2、TRIM 指令的支持
操作系统不去关心实际底层的硬件是什么,在 SSD 硬盘的使用上,也会带来一个问题——操作系统的逻辑层和 SSD 的逻辑层里的块状态,是不匹配的。
在操作系统里面去删除一个文件,其实并没有真的在物理层面去删除这个文件,只是在文件系统里面,把对应的 inode 里面的元信息清理掉,这代表这个 inode 还可以继续使用,可以写入新的数据。这个时候,实际物理层面的对应的存储空间,在操作系统里面被标记成可以写入了。
所以,我们日常的文件删除,都只是一个操作系统层面的逻辑删除。这也是为什么,很多时候我们不小心删除了对应的文件,我们可以通过各种恢复软件,把数据找回来。同样的,这也是为什么,如果我们想要删除干净数据,需要用各种“文件粉碎”的功能才行。
删除的逻辑在机械硬盘层面没有问题,因为文件被标记成可以写入,后续的写入可以直接覆写这个位置。但是,在 SSD 硬盘上就不一样了。
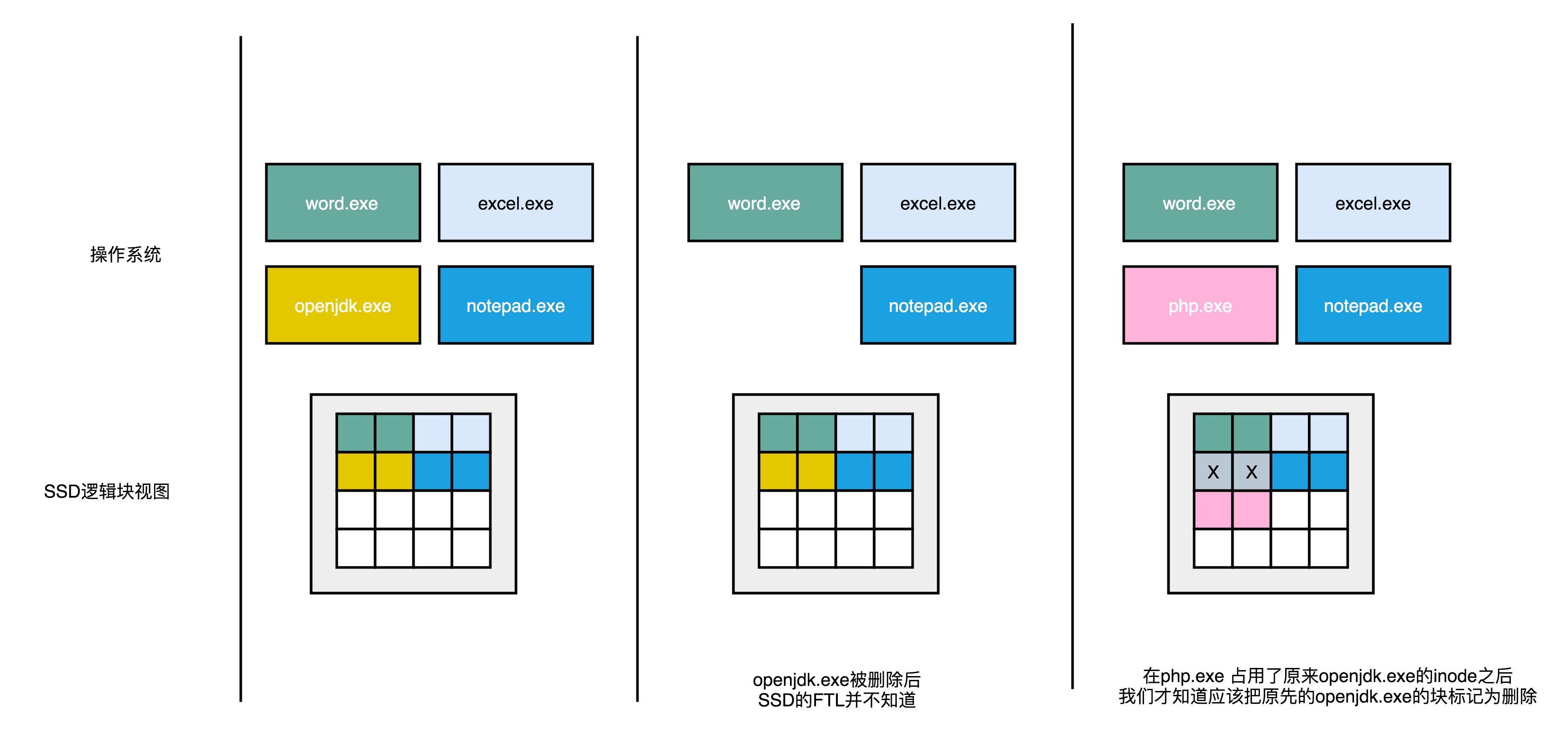
当我们在操作系统里面,删除掉一个刚刚下载的文件,比如标记成黄色 openjdk.exe 这样一个 jdk 的安装文件,在操作系统里面,对应的 inode 里面,就没有文件的元信息。但是,这个时候,我们的 SSD 的逻辑块层面,其实并不知道这个事情。所以在,逻辑块层面,openjdk.exe 仍然是占用了对应的空间。对应的物理页,也仍然被认为是被占用了的。
如果此时需要对 SSD 进行垃圾回收操作,openjdk.exe 对应的物理页仍然会被搬运到其他的 Block 里面去。只有当操作系统再在刚才的 inode 里面写入数据的时候,我们才会知道原来的些黄色的页,其实都已经没有用了,才会把它标记成废弃掉。
所以,在使用 SSD 的硬盘情况下,SSD 硬盘其实并不知道操作系统对于文件的删除。这就导致,磨损均衡,很多时候在都在搬运已经删除了的数据。以致于产生很多不必要的数据读写和擦除,既消耗了 SSD 的性能,也缩短了 SSD 的使用寿命。
为了解决这个问题,现在的操作系统和 SSD 的主控芯片,都支持 TRIM 命令。这个命令可以在文件被删除的时候,让操作系统去通知 SSD 硬盘,对应的逻辑块已经标记成已删除了。现在的 SSD 硬盘都已经支持了 TRIM 命令。无论是 Linux、Windows 还是 MacOS,这些操作系统也都已经支持了 TRIM 命令了。
3、写入放大
TRIM 命令的发明,也反应了一个使用 SSD 硬盘的问题——SSD 硬盘容易越用越慢。
当 SSD 硬盘的存储空间被占用的越来越多,每一次写入新数据,都可能没有足够的空白。不得不去进行垃圾回收,合并一些块里面的页,然后再擦除掉一些页,才能匀出一些空间来。从应用层或者操作系统层面来看,可能只是写入了一个 4KB 或者 4MB 的数据。但是,实际通过 FTL 之后,可能要去搬运 8MB、16MB 甚至更多的数据。
写入放大倍数 = 实际的闪存写入的数据量 / 系统通过 FTL 写入的数据量
写入放大的倍数越大,实际的 SSD 性能也就越差,会远远比不上实际 SSD 硬盘标称的指标。而解决写入放大,需要在后台定时进行垃圾回收,在硬盘比较空闲的时候,就把搬运数据、擦除数据、留出空白的块的工作做完,而不是等实际数据写入的时候,再进行这样的操作。
(四)AeroSpike:如何最大化 SSD 的使用效率?
想要把 SSD 硬盘用好,其实没有那么简单。
既然清楚了 SSD 硬盘的各种特性,就可以依据这些特性来设计应用。接下来,就看一下AeroSpike 这个专门针对 SSD 硬盘特性设计的 Key-Value 数据库(键值对数据库),是怎么利用这些物理特性的。
- AeroSpike 直接操作 SSD 硬盘里的块和页,并没有通过操作系统的文件系统。操作系统里面的文件系统,对于 KV 数据库来说,只会降低性能,没有什么实际的作用。
- AeroSpike 在读写数据的时候,做了两个优化:在写入数据的时候,AeroSpike 尽可能去写一个较大的数据块,而不是频繁地去写很多小的数据块。这样,硬盘就不太容易频繁出现磁盘碎片。并且,一次性写入一个大的数据块,也更容易利用好顺序写入的性能优势。AeroSpike 写入的一个数据块,是 128KB,远比一个页的 4KB 要大得多。
- 在读取数据的时候,AeroSpike 可以读取 512 字节(Bytes)这样的小数据。因为 SSD 的随机读取性能很好,也不像写入数据那样有擦除寿命问题。而且,很多时候读取的数据是键值对里面的值,这些数据要在网络上传输。如果一次性必须读出比较大的数据,就会导致网络带宽不够用。
AeroSpike 是一个对于响应时间要求很高的实时 KV 数据库,如果出现了严重的写放大效应,会导致写入数据的响应时间大幅度变长。所以 AeroSpike 做了这样几个动作:
- 持续地进行磁盘碎片整理。AeroSpike 用了所谓的高水位(High Watermark)算法。其实这个算法很简单,就是一旦一个物理块里面的数据碎片超过 50%,就把这个物理块搬运压缩,然后进行数据擦除,确保磁盘始终有足够的空间可以写入。
- 在 AeroSpike 给出的最佳实践中,为了保障数据库的性能,建议只用到 SSD 硬盘标定容量的一半。也就是说,人为地给 SSD 硬盘预留了 50% 的预留空间,以确保 SSD 硬盘的写放大效应尽可能小,不会影响数据库的访问性能。
正是因为做了这种种的优化,在 NoSQL 数据库刚刚兴起的时候,AeroSpike 的性能把 Cassandra、MongoDB 这些数据库远远甩在身后,和这些数据库之间的性能差距,有时候会到达一个数量级。这也让 AeroSpike 成为了当时高性能 KV 数据库的标杆。你可以看一看 InfoQ 出的这个Benchmark,里面有 2013 年的时候,这几个 NoSQL 数据库巨大的性能差异。
课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间




![C/C++工业数据分析与文件信息管理系统[2023-02-12]](https://img-blog.csdnimg.cn/img_convert/086357f99012573e1a28840d77f5e1d7.png)
![[golang gin框架] 2.Gin HTML模板渲染以及模板语法,自定义模板函数,静态文件服务](https://img-blog.csdnimg.cn/img_convert/26e0c230782b5595d30ae31609607a05.png)