阅读了Modular Routing Design for Chiplet-based Systems这篇论文,是关于多chiplet通信的,个人感觉核心贡献在于实现了 deadlock-freedom in multi-chiplet system,而不仅仅是考虑单个intra-chiplet的局部NoC可以通信,具体的一些记录如下:
目录
一、Article:文献出处(方便再次搜索)
(1)作者
(2)文献题目
(3)文献时间
(4)引用
二、Data:文献数据(总结归纳,方便理解)
(1)背景介绍
(2)目的
(3)结论
(4)主要实现手段
(5)实验结果
三、Comments对文献的想法 (强迫自己思考,结合自己的学科)
四、Why:为什么看这篇文献 (方便再次搜索)
五、Summary:文献方向归纳 (方便分类管理)
一、Article:文献出处(方便再次搜索)
(1)作者
- Jieming Yin, Onur Kayiran, Matthew Poremba, Muhammad Shoaib Bin Altaf, Gabriel H. Loh (Advanced Micro Devices, Inc. AMD超微半导体)
- Zhifeng Lin(南加州大学)
- Natalie Enright Jerger(多伦多大学)
(2)文献题目
- Modular Routing Design for Chiplet-based Systems
(3)文献时间
- 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture
- 计算机体系结构年度国际研讨会 ISCA
(4)引用
- J. Yin et al., "Modular Routing Design for Chiplet-Based Systems," 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 2018, pp. 726-738, doi: 10.1109/ISCA.2018.00066.
二、Data:文献数据(总结归纳,方便理解)
(1)背景介绍
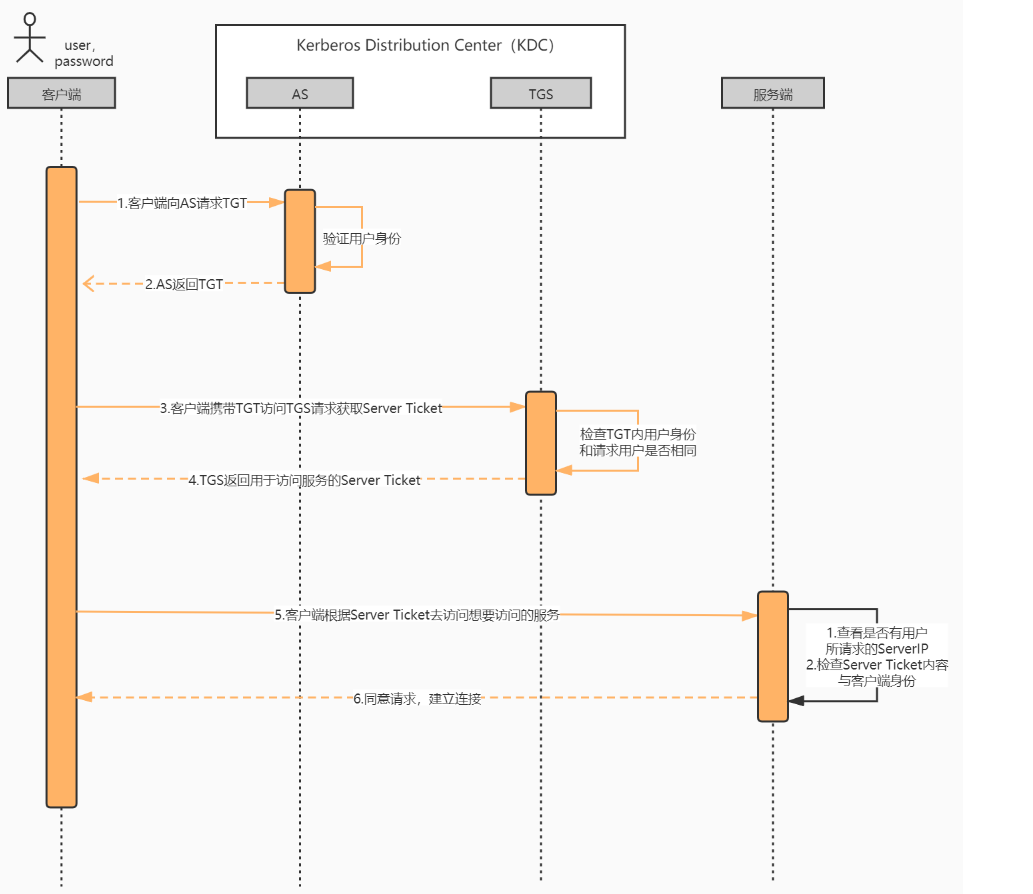
- 大背景:日益复杂的工艺技术导致成本的骤升,这是基于chiplet的SoC出现的动机。单个chiplet应该在不了解整个系统的情况下进行设计验证,但即使单个的chiplet都得到了验证,fully integrated system仍然存在正确性问题。
- 作者具体聚焦到互连网络,组装多个disparate chips(e.g., CPU, GPU, memory, FPGA)成为一个SoC,其correctness validation成为了一个挑战。具体来说,individual chiplets是独立设计的,有自己的NoC,无死锁且内部可以正常通信, 但将几个NoC连接在一起可能会引入新的resource cycle,从而导致跨芯片之间的循环依赖关系,很容易导致死锁。
(2)目的
- 通过引入一种简单的,模块化的,优雅的方法来确保multi-chiplet system的deadlock-free
- 以期通过independently-optimized chiplet-local NoCs来实现真正模块化和可重用的的chiplets
(3)结论
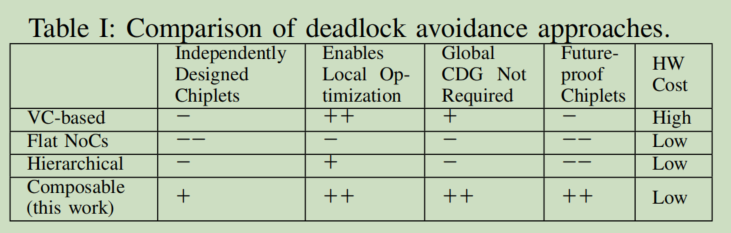
- 可在无需其它chiplets或者interposer's NoC细节的情况下独立设计,而prior-art(需要complete system-level information,比如CDG)不支持这个属性,故可以在高性能的情况下消除死锁,开发了一种composable, highly-modular, chiplet-based的方法来实现各种拓扑的routing
- 提出了一个关键抽象点:从单个chiplet的角度来看,系统的其余部分可以被抽象到单个虚拟节点中,基于此设置了boundary router 和 turn restriction的方法
(4)主要实现手段
总的来说,作者提出的chiplet-based的路由方法是composable, topologynostic, deadlock-free的,目标是:尽可能地隔离chiplets和interposer的设计,允许对chiplets和interposer进行独立的负载均衡优化,同时保持整个系统的routing是deadlock-free的。大致过程如下:
- 在每个chiplet的boundary router上设置unidirectional turn restrictions(决定了边界路由器的inbound和outbound reachability并且每个chiplet中不存在cyclic channel dependency),其余部分抽象成一个连接到boundary router的节点;
- 将这些reachability信息传播到interposer,这个interposer又负责将信息从一个边界路由器发送到另一个边界路由器;
- 通过了解边界路由器reachability,信息被发送到destination chiplet,最后local NoC会将其转发到final destination。
具体的核心实现技术如下:
-
Boundary Router Placement and Turn Restriction Algorithm

关键参数:
Number of Boundary Routers:边界路由器的数量决定了一个芯片为发送/接收intra-chiplet traffic所能维持的吞吐量;边界路由器越多,intra-chiplet traffic带宽就越高。虽然边界路由器可能的最大数量是芯片的面积函数,但最大有用带宽是其周长的函数。
Turn Restrictions at Boundary Routers:在选择prohibited turn时,我们的目标是最小化下式:Average_distance/ Average_reachability,较低的Average_distance和较高的Average_reachability的组合。
- 首先,避免将边界路由器聚类在一起,以减少创建网络热点的机会;
- 其次,边界路由器的放置应该平衡所有边界路由器的inbound和outbound reachability;
- 第三,首选采用半径较低的路由器。
-
Interposer NoC Confifiguration
- 如果一个目标只能通过一个边界路由器到达,则Interposer 必须将该消息路由到该特定的边界路由器。
- 否则,我们选择边界路由器来平衡跨边界路由器的网络负载(同样地利用芯片Interposer 带宽),同时最小化路径长度(避免仅仅为了负载平衡而以高度迂回的方式发送消息)
如何将片上节点分配给边界路由器的步骤:
- 首先,根据所有边界路由器,选择具有最少项目数量的路由器Ai (仅能通过i可达的节点集)。
- 然后,将Ci中的节点一个一个分配给Ai,直到Ai中的项目数量不再是最小的。当分配给Ai时,从Ci中删除一个项目。如果Ai仍然具有最少的项目数量,则从E{i,j}中一个一个分配节点给Ai。分配给Ai后,从Ei,j和Ej,i中删除项目。如果不能进行进一步的分配,则边界路由器i的节点分配完成。(Ci是在拓扑上离i比其它边界路由器近的节点列表,且这些节点不仅只通过1一个边界路由器可达;E{i,j}是与边界路由器i和j等距的节点列表,且这些节点至少与两个边界路由器等距)
- 重复步骤1-3,直到对于所有的边界路由器i和j,Ci = ∅和Ei,j = ∅为止。
(5)实验结果
- 实验配置
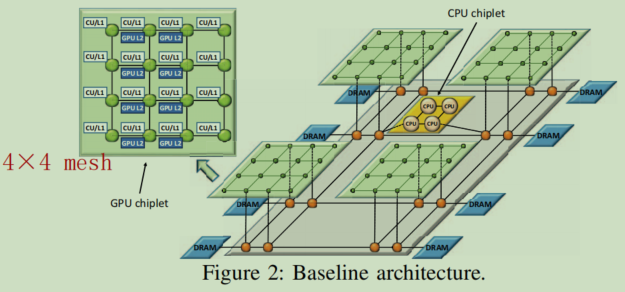
有4个GPU chiplet,每个芯片提供16个GPU SIMD计算单元(CUs),和一个中央CPU chiplet来支持GPGPU工作负载的CPU阶段。这5个chiplet被堆叠在一个active interposer上,该interposer实现了它自己的NoC来互连这些芯片和其他常见的系统功能,单个chiplet的网络是 4X4 mesh,interposer的网络也是 4X4 mesh,如下图2:
- benchmarks
- VC-based routing:需要很多VCs才能进行,且VC的分配需要提高一些全局CDG信息
- updown routing(flat network):不支持系统的模块化和可组合性,流量不均,根节点往往更拥挤
- segment-base routing(flat network)
- Nue routing(flat network):需要complete channel dependency graph (CDG)来构建生成树从而保证死锁自由
- shortest path :an idealized system,是一种理想化,不实际
- ours(composable)
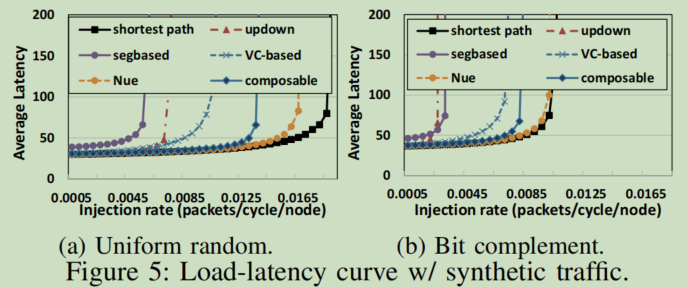
- 对比试验1:Basic Throughput Evaluations with Synthetic Traffific
- 在uniform random和bit complement下测试load-latency,结果表明:ours优于segbased/updown/VC-based,主要原因是:segbased 是基于2D mesh-like的网络,而本实验的全局拓扑仍然不规则,路由无法很好处理;updown 过早饱和,根节点比叶节点更拥挤,负载不太平衡;VC-based 需要的额外VCs减少了head-of-line blocking。而Nue优于我们,是因为它利用了完整的CDG知识来优化路由,可以更好的提供负载平衡,因而产生与shortest相似的性能;shortest虽然性能好但不切实际。总的来看,prior-art都不适用于模块化的SoC设计,ours能较为全面的进行全局负载均衡优化,无需先验complete CDG知识,也能保证在较高的正确性和性能下进行模块化设计。
-
对比试验2:Application-level Impact
-
测试平均网络延迟。没有对比segbased方法,是因为它需要大量的不切实际的VCs来避免路由和协议级的死锁。如下图a,ours实现的网络延迟几乎与shortest相同,在bfs/nw/srad的情况下,ours优于shortest(考虑是由于偶尔情况下的负载/拥塞不平衡,往往出现在GPU比在CPU更频繁);updown方法是由于根节点的平均网络延迟增加超过了50%,在heavy traffic情况下成为瓶颈,从而限制了系统的有效带宽。
-
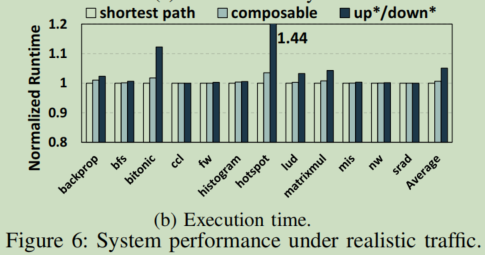
测试application performance。总体来看,对app的执行时间的影响是温和的,因为大多数的GPU app本身就对延迟不那么敏感。虽然updown方法偶尔有5-10%的波动,但ours的性能与shortest大致相同。
-
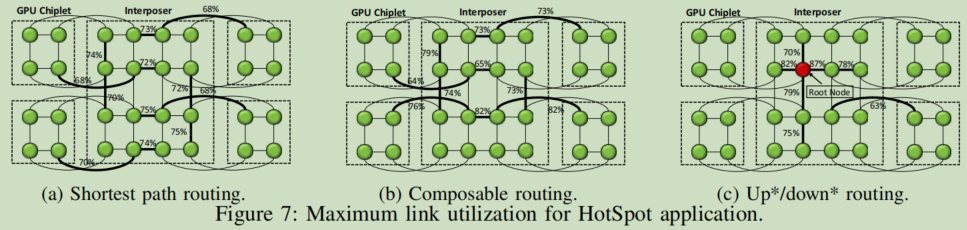
Case Study – HotSpot:在执行HotSpot时,测试利用率最高的链路的最大链路利用率。如图7,只显示GPU chiplet上的边界路由器和interposer,其余的CU 芯片利用率较低,每10000个周期,我们就对每条链路的利用率进行采样。图中标注的是最大链路利用率(整个过程中的最大采样结果),通过观察该值可以定位NoC的流量瓶颈,其中updown中的红点是根节点。
-

- 消融实验:broader applicability
- 验证实验设置guideline的有效性。
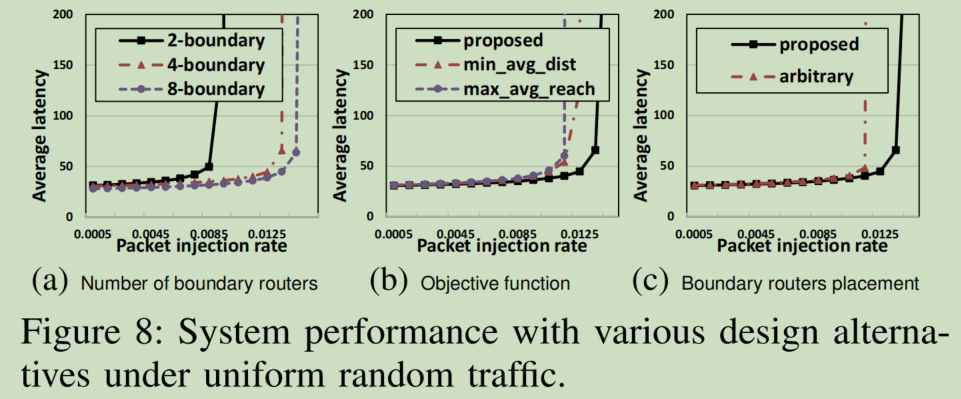
- 边界路由器数量设设置。下图8.a显示了边界路由器数量从2增加到8时,平均网络延迟的变化。可知,2->4的提升显著高于4->8的显著。虽然增加边界路由器会增加off-chiplet bandwidth,减少intra-chiplet communication,但是会增加router的复杂性面积,从而影响边界路由器的性能,提高了硬件成本,故4个边界路由器是合理设计。
- 选取turn restriction的objective function。下图8.b显示了不同objective function下的平均网络延迟,包括:最小化Average_distance和最大化 Average_reachability,但这往往会产生不平衡的on-chiplet traffic。实验能证明proposed function对turn restriction select的有效性。
- 边界路由器的位置。下图8.c考虑了一种与ours不同的placement methods—随机放置。但这会导致负载不均,使得某些链路的使用率高于其它链路,影响系统吞吐量。
- 敏感性研究:Sensitivity Studies
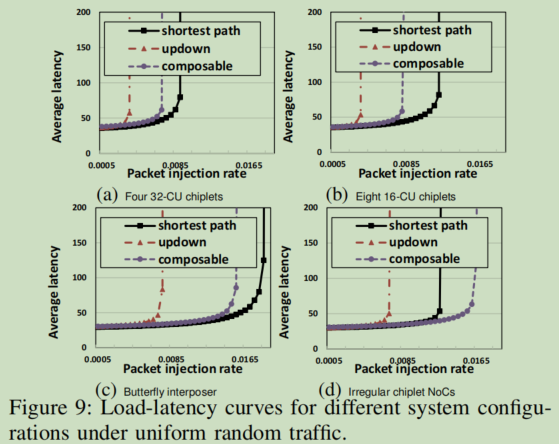
- System Size:将baseline中的64-CU替换成128-CU,使用两种方案:1) 4 chiplets with 32 CUs each;2) 8 chiplets with 16CUs each。如下图9.a和9.b,两者的区别是inter-chiplet和intra-chiplet的比率,其中ours显著优于updown,比起shortest,ours对流量分布的敏感性较低(图9中ours位置变化不明显)。
-
Interposer NoC Topology:将baseline中interposer's mesh NoC替换成“Double Butterflfly” topology,如下图9.c,与baseline的性能相近,表明ours是独立于 interposer’s NoC topology的。
-
Irregular Chiplet Topologies:将每个GPU chiplet替换成不同的local NoC topology,如下图9.d所示,ours甚至超过“ideal” shortest routing,推测是因为shortest倾向于靠近中心的interposer(见上图7.c的红点),ours可以更好的实现interposer traffic distribution。
- 验证实验设置guideline的有效性。
- 其它实验:Other Chiplet Packaging Options
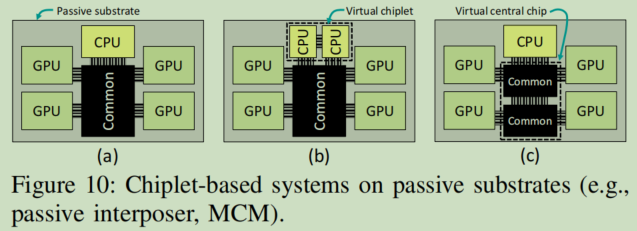
-
考虑取消“central chip”:如下图10.c,没有单个的“central chip”,而是将两个连接在一起的chip看作一个virtual chip。
-
考虑使用non-star topology in chiplets:如下图10.b,两个CPU chiplets拥有点对点链路(可以看作一个virtual chiplets),仍可以正常执行我们的算法,不会造成死锁。
- 考虑使用passive interposer:如下图10.a,the compute chiplets fan out from the central chip in a star-like topology。
-
三、Comments对文献的想法 (强迫自己思考,结合自己的学科)
第一次看互连网络的死锁路由,我没看出来啥,囫囵吞枣,和我的毕设没太大关系,先搁这儿,以后有用再回头细细琢磨。
- 虽然这篇是顶会,但是其实我觉得对读者来说并不友好,你没办法只通过introduction就明确它的贡献在哪里,必须要深入仔细的阅读,才能发现它是穿插在prior-art的结尾,作为对比来凸显contribution/difference。我还是倾向于总分总的结构,在introduction中明确问题/挑战,现有的work解决了什么问题,还存在哪些漏洞,针对这些问题如何获得motivation,进而迅速明确文章的亮点。
- 作者考虑的很全面,有非常完整的实验设计过程,但我有点疑问是,在最后一个实验(fig.10)说明方法的普适性时,缺乏数据的支撑?只是图示实验设计,并说明是可行的,就感觉说服力没那么强。当然我是个菜鸡,我不是很懂,知道的uu可以留言告诉我。
四、Why:为什么看这篇文献 (方便再次搜索)
了解课题背景:
- 师兄师姐推荐的文章,用于了解chiplet通信的一些背景
- 了解多chiplet通信的死锁问题
五、Summary:文献方向归纳 (方便分类管理)
deadlock-freedom in multi-chiplet system:
- active silicon interposer
- turn restrictions and boundary router
- highly-modular, simple, elegant, topologynostic routing

![C/C++工业数据分析与文件信息管理系统[2023-02-12]](https://img-blog.csdnimg.cn/img_convert/086357f99012573e1a28840d77f5e1d7.png)
![[golang gin框架] 2.Gin HTML模板渲染以及模板语法,自定义模板函数,静态文件服务](https://img-blog.csdnimg.cn/img_convert/26e0c230782b5595d30ae31609607a05.png)