如果说当下最火的AI技术和话题是什么,恐怕很难绕开ChatGPT。各大厂商都在表示未来要跟进ChatGPT技术,开发在自然语言处理智能系统,可见其影响力。本篇博客追个热度,来简单的介绍下ChatGPT到底是一项什么技术,究竟如何完成复杂的语言处理任务的。
ChatGPT到底是一项什么技术
如果想要了解ChatGPT是一项什么技术,不如直接问问他:
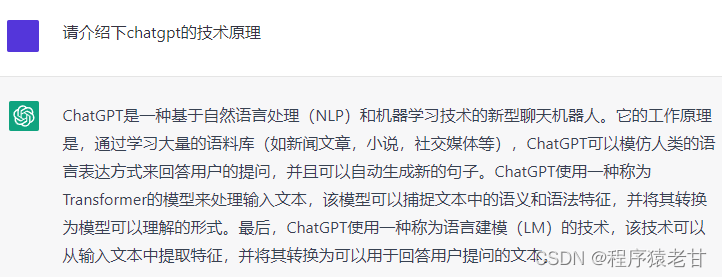
可以看到ChatGPT是一项基于Transformer模型实现的NLP软件。关于Transformer模型,我们已经在之前文章《注意力机制原理概述》介绍过。这里提到的LM技术,其实就是Transformer。
ChatGPT背后的Transformer架构
那么,ChatGPT的Transformer架构是什么样?我让chatgpt打印了他自己的主干网络代码,如下:
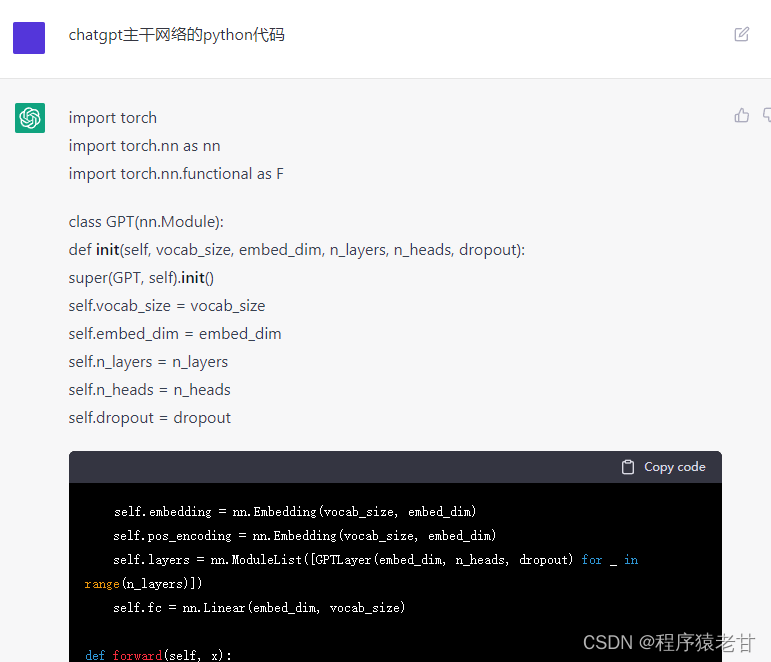
完整的代码分为四个模块:GPT框架,GPT层,多头注意力模块代码和位置编码。
GPT框架:
import torch
import torch.nn as nn
import torch.nn.functional as F
class GPT(nn.Module):
def init(self, vocab_size, embed_dim, n_layers, n_heads, dropout):
super(GPT, self).init()
self.vocab_size = vocab_size
self.embed_dim = embed_dim
self.n_layers = n_layers
self.n_heads = n_heads
self.dropout = dropout
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.pos_encoding = nn.Embedding(vocab_size, embed_dim)
self.layers = nn.ModuleList([GPTLayer(embed_dim, n_heads, dropout) for _ in range(n_layers)])
self.fc = nn.Linear(embed_dim, vocab_size)
def forward(self, x):
# Embedding
x = self.embedding(x)
# Position Encoding
x = self.pos_encoding(x)
# GPT Layers
for layer in self.layers:
x = layer(x)
# Output
x = self.fc(x)
return x
GPT层代码:
class GPTLayer(nn.Module):
def init(self, embed_dim, n_heads, dropout):
super(GPTLayer, self).init()
self.embed_dim = embed_dim
self.n_heads = n_heads
self.dropout = dropout
self.attention = MultiHeadAttention(embed_dim, n_heads, dropout)
self.feed_forward = PositionwiseFeedForward(embed_dim, dropout)
def forward(self, x):
# Attention
x = self.attention(x)
# Feed Forward
x = self.feed_forward(x)
return x
多头注意力模块代码:
class MultiHeadAttention(nn.Module):
def init(self, embed_dim, n_heads, dropout):
super(MultiHeadAttention, self).init()
self.embed_dim = embed_dim
self.n_heads = n_heads
self.dropout = dropout
self.query_linear = nn.Linear(embed_dim, embed_dim)
self.key_linear = nn.Linear(embed_dim, embed_dim)
self.value_linear = nn.Linear(embed_dim, embed_dim)
self.output_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
# Query, Key, Value
query = self.query_linear(x)
key = self.key_linear(x)
value = self.value_linear(x)
# Attention
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(query.size(-1))
scores = F.softmax(scores, dim=-1)
scores = self.dropout(scores)
# Output
output = torch.matmul(scores, value)
output = self.output_linear(output)
return output
位置编码:
class PositionwiseFeedForward(nn.Module):
def init(self, embed_dim, dropout):
super(PositionwiseFeedForward, self).init()
self.embed_dim = embed_dim
self.dropout = dropout
self.fc1 = nn.Linear(embed_dim, embed_dim)
self.fc2 = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
# Feed Forward
x = self.fc1(x)
x = F.relu(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
GPT主体框架主要由GPT层叠加构成。GPT层也比较容易理解,基本就是由多头注意力处理模块构建的。按照注意力机制原理,多头注意力处理首先将输入按照查询、键、值做对应的线性变换,之后输入一个多分枝的注意力结构,建立一个具有关联关系的评分结果。按照评分结果,实现对查询的值预测,实现NLP任务。这个模型基本就是2017年Vaswani工作 [1] 的复现。这让我们真正理解了多头注意力的强大之处。
总结
chatgpt是一个有趣且有用的AI工具,对于泛NLP任务,具有目前最优秀的处理分析能力。我认为其在客户问答,信息查询,文字编辑等任务中,将产生深远的影响。其背后基于多头注意力机制的Transformer模型,已被验证在逻辑关系学习领域,具有惊人的技术优势。相信在该技术路线上,未来还会有更加优秀的工作被不断提出。
Reference
[1] A. Vaswani, N. Shazeer, N. Parmar, et al. Attention is all you need. Advances in neural information processing systems, 2017,5998‒6008.





![[Java 进阶面试题] CAS 和 Synchronized 优化过程](https://img-blog.csdnimg.cn/2e801aa85df74f31ba85ab1273150b1d.png)