📣📣📣📣📣📣📣
🎍大家好,我是慕枫
🎍前阿里巴巴高级工程师,InfoQ签约作者、阿里云专家博主,一直致力于用大白话讲解技术知识
🎍在这里和大家分享一线互联网大厂面试经验、技术人成长路线以及Java技术、分布式、高并发、架构设计方面的经验总结
🎍感恩遇见,希望我们都能成为更好的自己
📣📣📣📣📣📣📣
人工智能研究实验室OpenAI在2022年11月30日发布了自然语言生成模型ChatGPT,上线两个月就已经超过一亿用户,成为了人工智能界当之无愧的超级大网红。ChatGPT凭借着自身强大的拟人化及时应答能力迅速破圈,引起了各行各业的热烈讨论。简单来说ChatGPT就是可以基于用户文本输入自动生成回答的人工智能聊天机器人。那肯定会有人说这不就是Siri嘛,虽然都是交互机器人但是两者的差别可老大了。那么ChatGPT在人机交互时为什么会有这么出色的表现?它到底会不会取代搜索引擎?90%的人真的会因为ChatGPT的出现而面临失业的危险吗?带着这些疑问我们一起来看看ChatGPT到底有哪些过人之处以及未来会给行业带来怎样的变革。
ChatGPT到底是个啥
谁搞出来的ChatGPT
OpenAI的创始人Sam Altman是一个8岁就会编程的天才,在2015年他联合特斯拉老板马斯克、天使投资人彼得·泰尔等一众硅谷大佬创办了OpenAI,这是一家人工智能研究实验室,主要由盈利组织 OpenAI LP 与母公司非盈利组织 OpenAI Inc 所组成,目的是促进和发展友好的人工智能,避免人工智能脱离人类控制。OpenAI重点研究开发尖端的人工智能技术,其中包括机器学习算法、强化学习以及自然语言处理等。OpenAI在2022年11月30日发布了ChatGPT,正式向外提供实时的在线问答对话服务。

ChatGPT是什么

《知识的边界》一书中有这样一段话:
当知识变得网络化之后,房间里最聪明的那个,已经不是站在屋子前头给我们上课的那个,也不是房间里所有人的群体智慧。房间里最聪明的人,是房间本身:是容纳了其中所有的人与思想,并把他们与外界相连的这个网。
我对这句话的理解就是,互联网上拥有全人类的知识以及经验,为人工智能提供了海量的学习数据,当这些知识和经验被有序的进行组织之后,也同时为训练一个“懂王”人工智能应用提供了丰沛的数据土壤。而ChatGPT就是被互联网海量的文本数据以及语言资料库数据喂养训练之后,它就可以根据你输入文字的内容来生成对应的回答,就好像两个人在一问一答的聊天。它除了可以和你无障碍的进行沟通,甚至让你感觉你对话的不是一个聊天机器人而是一个学识渊博又有点风趣的真实的人,回答出来的答案甚至带有人类的某种语气,这在以往的聊天机器人中是不敢想象的。
这里稍微说明下ChatGPT的字面含义,它是一款通用自然语言生成模型,Chat是对话的意思,而所谓GPT就是Genarative Pre-trained Transformer,意思就是生成型预训练转换模型,听上去是不是有点不明觉厉的感觉。
除此之外,你还可以让他帮你完成一些实际的工作,比如写文案、写剧本甚至可以帮你直接写代码出来还可以帮你找到代码的bug,这是程序员要把自己饭碗给砸碎而且是稀碎的节奏啊,在文字以及代码层面可以说是无所不能。这种输入问题立马给答案的交互方式,远胜于传统搜索引擎在海量数据中查找自己需要内容的使用感受,因此可以预见在不久的将来ChatGPT将会颠覆传统的搜索引擎,彻底改变信息检索的使用方式。

另外ChatGPT还可以在上下文语境下回答问题、同时能够主动承认自己的不足以及挑战问题的合理性。以下就是ChatGPT在否定我提出来的问题。

PS:帮大家问了ChatGPT如何成为世界首富,秘诀在下面。
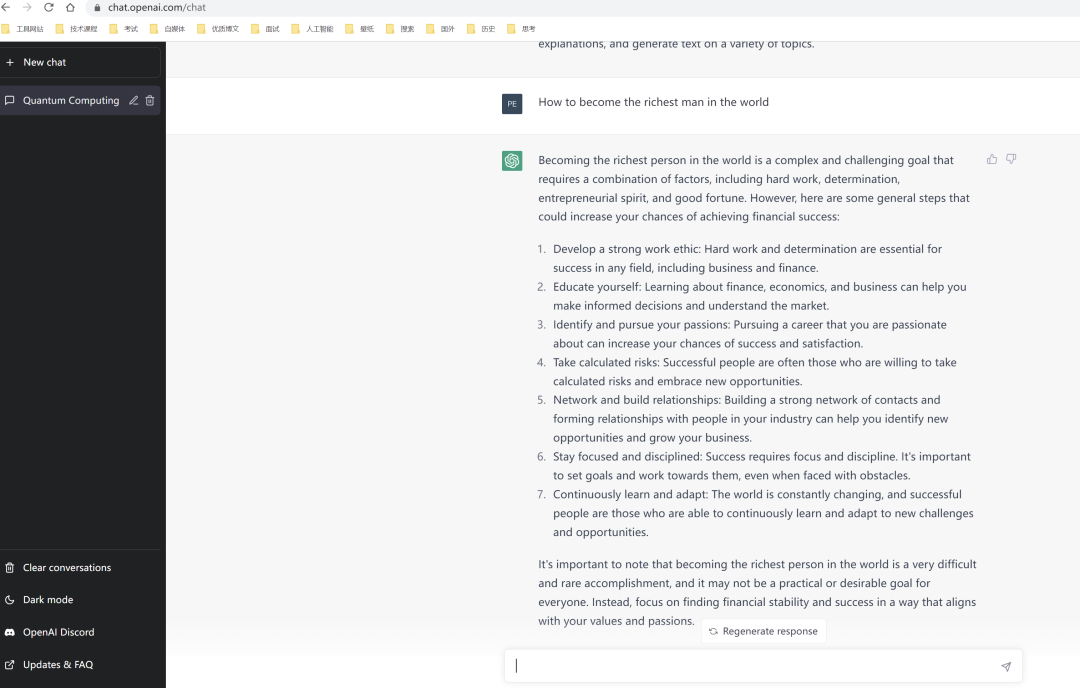
正因为ChartGPT具备这样强大的理解能力、学习能力以及创作能力,促使它成为AI人工智能诞生以来,面向C端用户增长最快的智能应用产品。在以前,人工智能C端产品总是被认为不够智能甚至被嘲笑是“人工智障”,即便在B端也只是某些场景下使用,普通人根本感受不到AI人工智能的威力,但是ChatGPT的出现可能预示着未来人工智能将融入到普通人的生活当中。
PS:我真怕他回答有。
ChatGPT为什么这么强?
虽然ChatGPT是一夜爆红,但是其背后的技术发展却并不是一蹴而就的。因此如果我们要想搞清楚ChatGPT为什么如此强悍,我们就得弄明白其背后实现的技术原理到底是怎样的。
语言模型迭代
我们都知道自然语言是人类进行交流沟通的最重要的工具,因此如何让机器可以和人通过自然语言进行无障碍的沟通交流一直是人工智能领域孜孜不倦追求的目标。而NLP(Natural Language Processing,自然语言处理)就是计算机科学领域和人工智能领域专门研究让机器可以理解自然语言同时在此基础上进行响应的重要研究方向。那么要想让计算机可以识别自然语言,那么需要对应的语言模型来对文本进行分析处理。而语言模型的大致原理就是对语言文本进行概率建模,通过模型来预测下一段输出内容的概率。大致的过程如下所示,通过语言模型将一段话后面的出现概率最高的语句进行输出。
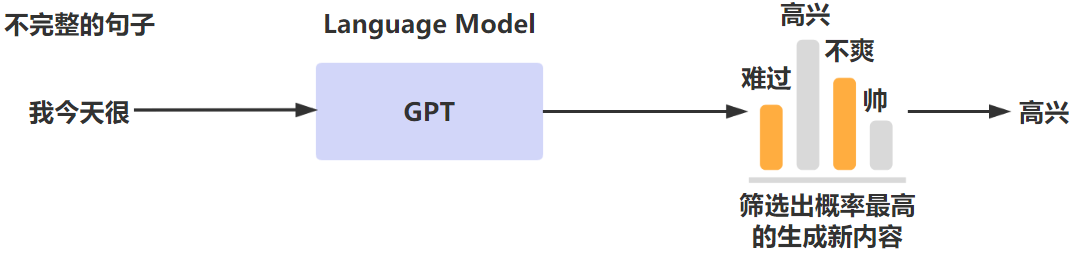
语言模型可以分为统计语言模型以及神经网络语言模型。而ChatGPT就属于神经网络语言模型,它在经过多个版本的迭代优化后才有了今天震惊四座的优秀表现。我们可以简单梳理下LM(Language Model,语言模型)的发展脉络,看看语言模型是怎么一步步进行进化的,这对我们理解ChatGPT背后的技术原理非常有帮助。
RNN
RNN(Recurrent Neural Network,循环神经网络)在NPL领域有着广泛的应用。上文我们提到的NLP要解决的是让机器理解自然语言的问题,因此如果让机器理解一句话的含义,肯定不能只理解这句话中每个单词是什么意思,而应该处理这句话连起来之后的序列所表达的的含义是什么,而RNN解决的是就是样本数据为序列的建模问题。
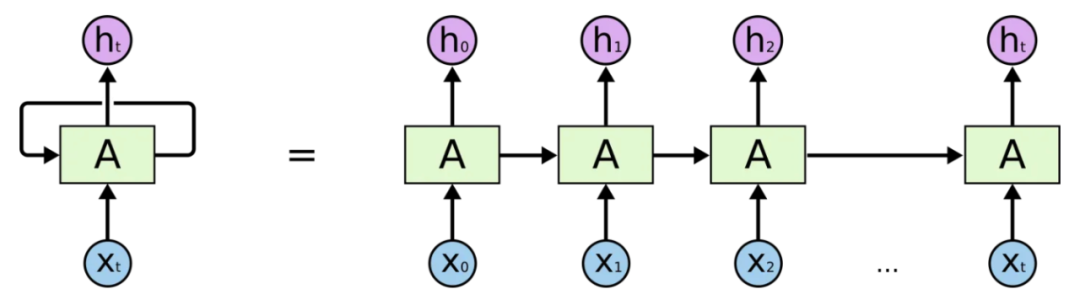
但是RNN存在效率问题,在处理语言序列的时候是通过串行化的方式来进行的,也就是说后一个单词的的处理需要等到前一个单词的状态输出后才能进行,另外还有梯度爆炸和遗忘等问题。因此人工智能专家们不断在此基础上进行模型优化。
Transformer
Google Brain 2017年在《Attention Is All You Need》论文提出了Transformer模型,这是一个基于自注意力机制的深度学习模型,主要针对RNN的问题进行了优化设计。特别是串行化出列文本序列的问题,Transformer模型可以同时处理文本序列中所有的单词,同时序列中任意单词的距离都为1,避免了RNN模型中因为序列过长到导致的距离过长问题。Transformer模型的提出可以说是NLP领域跨越式发展的重要标志,因为后续著名的BERT模型以及GPT模型都是基于Transformer模型演化而来的。下图为Transformer模型结构。
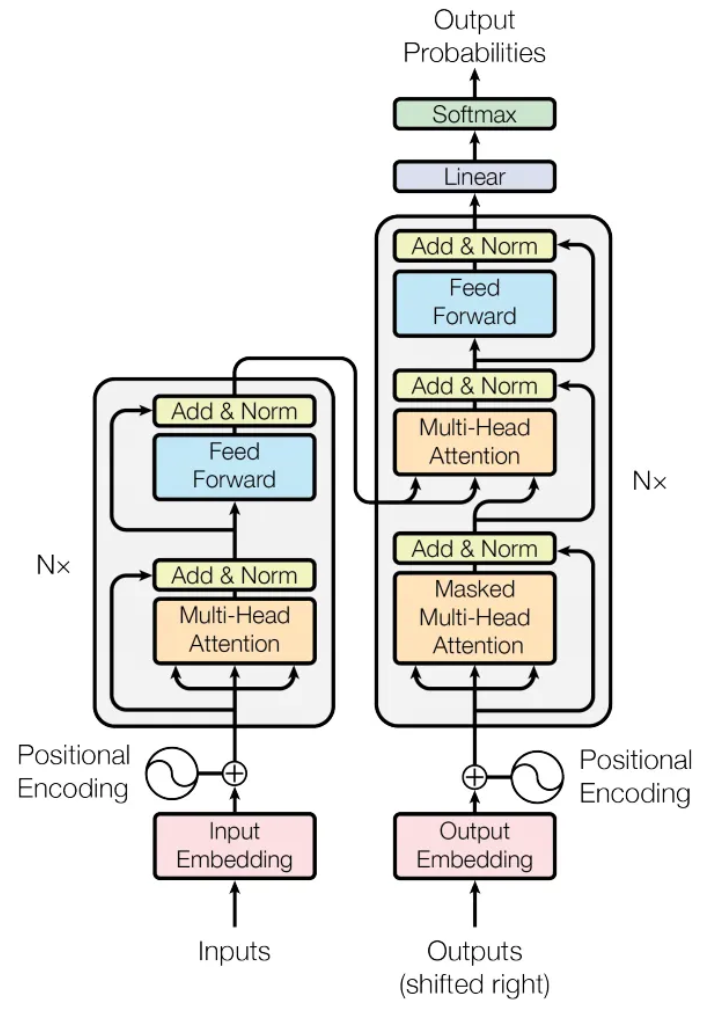
GPT、GPT-2
无论是原始的GPT模型还是最新的ChatGPT模型其实都是以Transformer模型为核心结构的语言模型。GPT使用的是Transformer模型的Decoder组件,比较适合根据上文回答下文的场景。
为了提高训练的精准度,很多机器学习的训练任务都是采用标记的dataset来完成,但是实际上标注数据是一个工作量很大的事情会耗费大量的人力和时间。因此随着算力的不断增强,实际上我们需要对更多的未进行人工标记的数据进行训练。因此GPT提出了新的自然语言训练范式就是通过海量的文本数据来进行无监督学习从而能实现模型训练。这也是GPT采用了Pre-training + Fine-tuning的训练模式的原因。GPT的模型结构如下,它的训练目标就是根据上文来预测下文。
而GPT-2实际在模型结构上并没有大的改变,只是进行了简单的调整,主要是GPT-2使用了更多的模型参数以及更多的训练数据。它的目标就是训练出一个泛化能力更强的语言模型,所谓泛化就是应对没有遇到过的问题的能力。
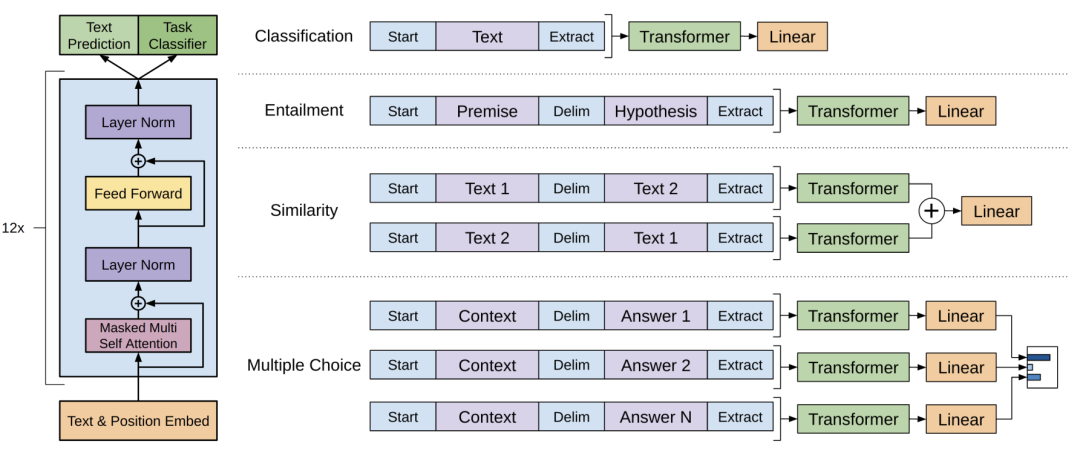
GPT-3
2020年OpenAI在论文《Language Models are Few-Shot Learners》中提出了GPT-3模型,它使用的模型参数两以及训练数据量都非常大。它主要提出了LLM的上下文学习的能力。
GPT-3探讨了模型在Zero-shot、One-shot、Few-shot三种不同输入形式下的效果。它主要考虑如何让通过已有问题预测可能的回答,这里稍微解释下Zero-shot、One-shot、Few-shot,Zero-shot意味着只给提示,One-shot会给一个范例,Few-shot意味着给多个范例。但是它是没有考虑回答的内容是不是符合人类的预期的,这也是后期InstructGTP最主要的优化方向。

通过下表可以看的出来GPT训练的参数量级以及数据量级爆发性增长,当模型迭代到GPT-3的时候,参数量已经过千亿,预训练数据量达到45TB,可以说是一个实打实的超级LLM模型了。巨大的模型参数量以及预训练数据量也带来了训练成本的不断攀升,GPT-3的训练成本高达1200美元。

ChatGPT关键能力
目前OpenAI还尚未就ChatGPT公开对应的论文,但是实际上的它的核心思想和OpenAI在2022年发表的论文《Training language models to follow instructions with human feedback》基本是一致的,InstructGPT最重要的优化就是引入了RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习 )技术。通过让模型学习人类对话的过程以及让人类标注评价排序模型回答的结果来微调原始模型,使得收敛后的模型在回答问题的时候能够更加符合人类的意图。
另外这篇论文中提出来的InstructGPT训练方法实际和ChatGPT也基本是一样的,只是在获取数据的方式上稍有差别,因此InstructGPT可以说和ChatGPT是一对兄弟模型。我们具体来看下ChatGPT是怎么被训练出来的,以及ChatGPT如何解决让模型回答的答案更加符合人类的意图或者说偏好。
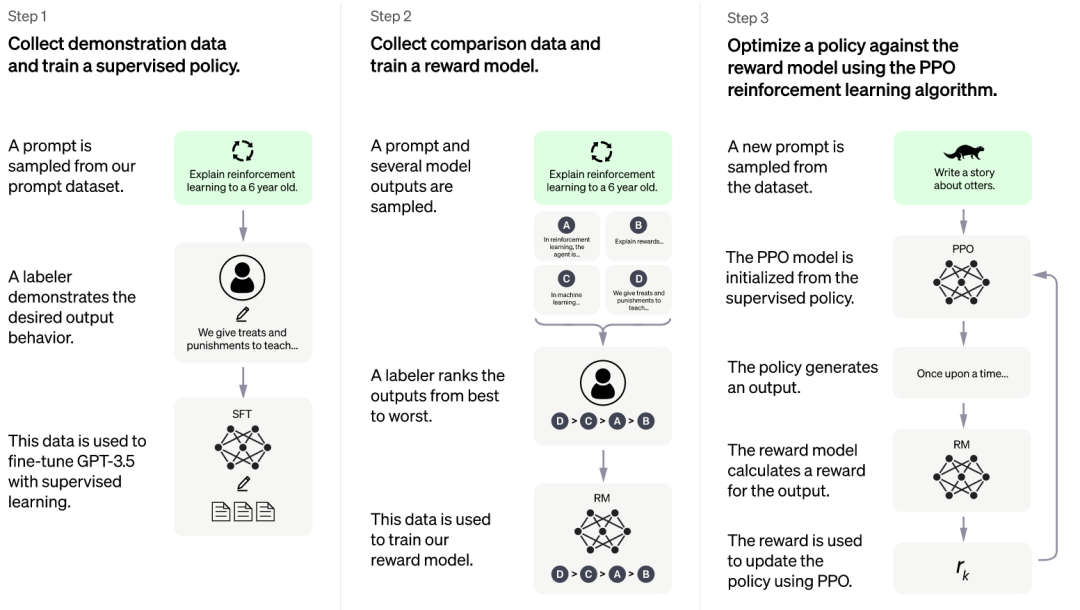
上面的训练过程可能看起来有点复杂,经过简化之后如下图所示,这样应该更加便于同学理解ChatGPT模型是怎么被训练出来的。根据官网给出的步骤,它的核心训练思想就是收集反馈数据-》训练奖励模型-》PPO强化学习。
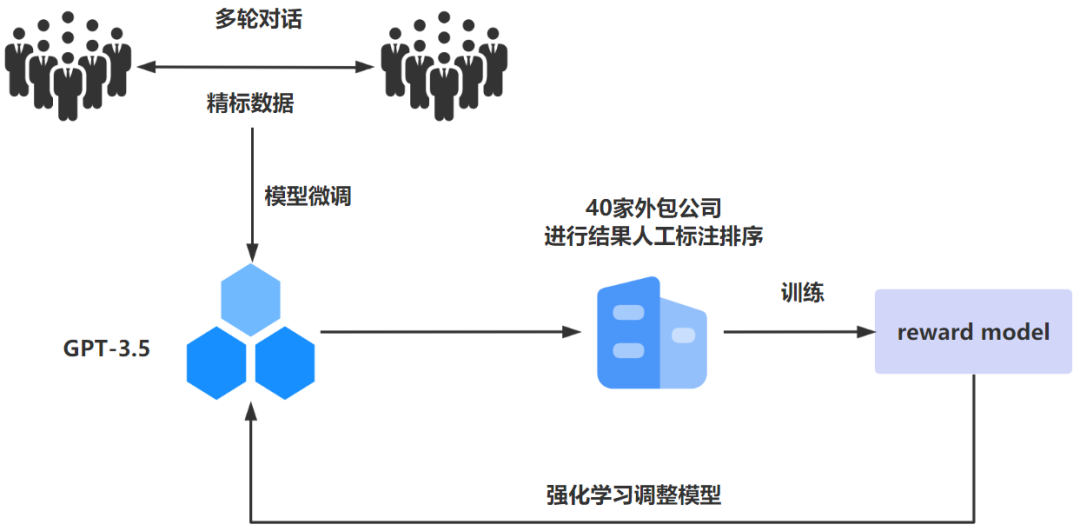
ChatGPT训练过程主要分为三个阶段:
阶段一:通过监督学习,微调GPT-3.5初始模型
其实对于LLM(Large Language Model,大语言模型)来说,并不是说训练的样本数据越多越好,为什么这么说呢?因为像ChatGPT这种大语言预训练模型都是在超大参数以及海量数据中被训练出来的,这些海量样本数据实际上对于人工智能专家来说时透明的,也是无法控制的。因此如果样本数据中带有一些种族歧视、暴力等不良的数据的时候,可能预训练出来的模型就会带有这些不好的内容属性。但是对于人工智能专家来说,必须要保证人工智能的客观公正不带有任何的偏见,而ChatGPT也正是朝着这个方面来进行训练。
因此ChatGPT通过监督学习的方式来进行模型训练,所谓监督学习就是要在“有答案”的dataset上进行学习。为此,OpenAI雇佣了40家承包商来进行数据标记工作,首先让这些标记人员模拟人机交互进行多轮的语言交互,在这个过程中会产生对应的人工精标数据,这些精标数据用来对GPT-3.5模型来进行微调以便于获得SFT(Supervised Fine-Tuning)模型。
阶段二:构建Reward Model
随机抽取一批prompt数据后,使用第一阶段微调后的模型进行不同问题的自动回复,然后让标记人员对回答出来的结果进行从好到坏排序,排序出来的结果数据用来训练Reward Model,在此过程中,对排序的结果继续进行两两组合形成排序训练数据对,Reward Model接受数据对输入来给出回答质量的分数。这个Reward Model从本质上来讲就是抽象出来的人类真实意图。因为有了这关键的一步,Reward Model可以不断引导模型朝着符合人类意图的方向去产生对应的回答结果。

阶段三:PPO(Proximal Policy Optimization,近端策略优化)强化学习微调模型
PPO 是一种信赖域优化算法,它使用梯度约束来确保更新步骤不会破坏学习过程的稳定性。在这个阶段继续抽取一批prompt数据之后,使用阶段二构造出来的Reward Model来对微调后的训练模型的回答进行打分来更新预训练的参数。通过Reward Model对产生高分回答进行奖励,由此产生的策略梯度可以更新PPO模型参数。不断循环迭代直至最终收敛模型。

可以看的出来实际上ChatGPT训练的过程实际就监督学习结合RLHF技术应用落地的过程,ChatGPT实际上就是靠RLHF技术来实现生成一个比较符合人类预期的回答。
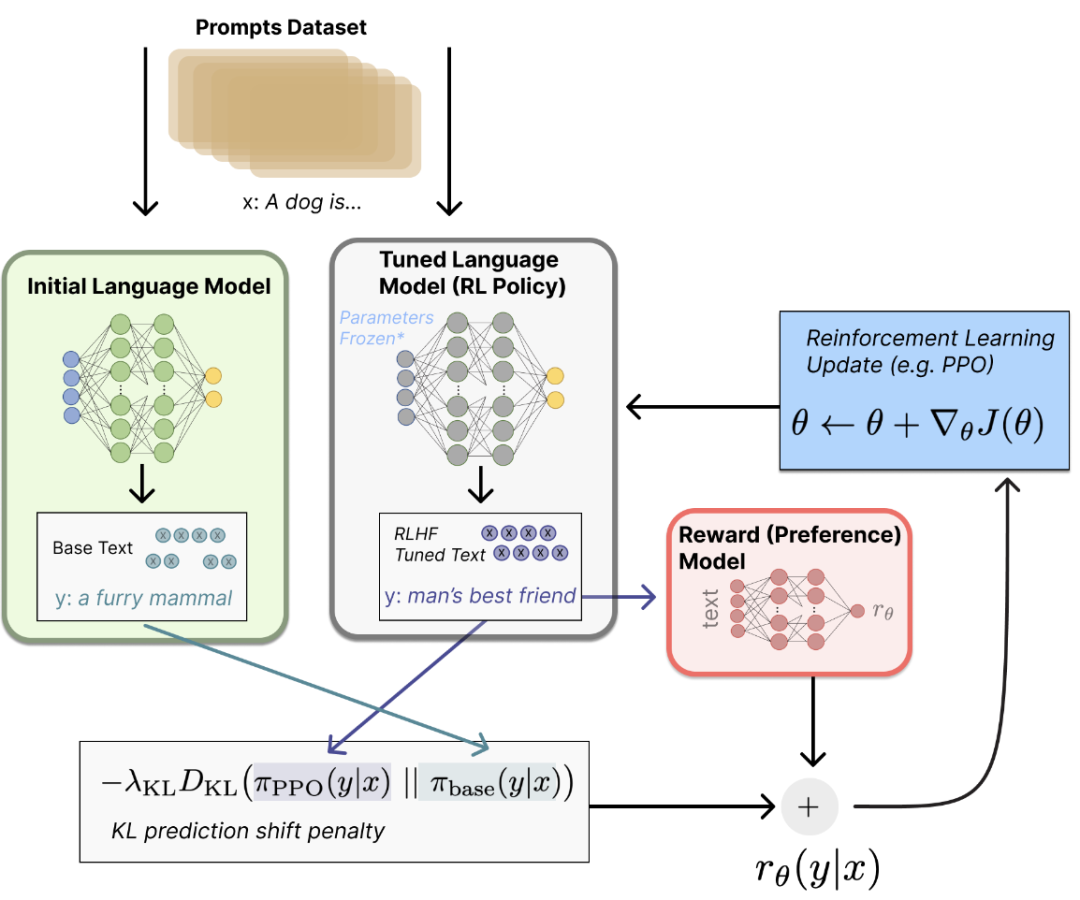
通过上面的模型训练过程,我们总结下来ChatGPT之所以具备强大的上下文理解能力,主要得益于三个方面的关键能力,分别是强大的基础模型、高质量的样本数据以及基于人类反馈的强化学习。
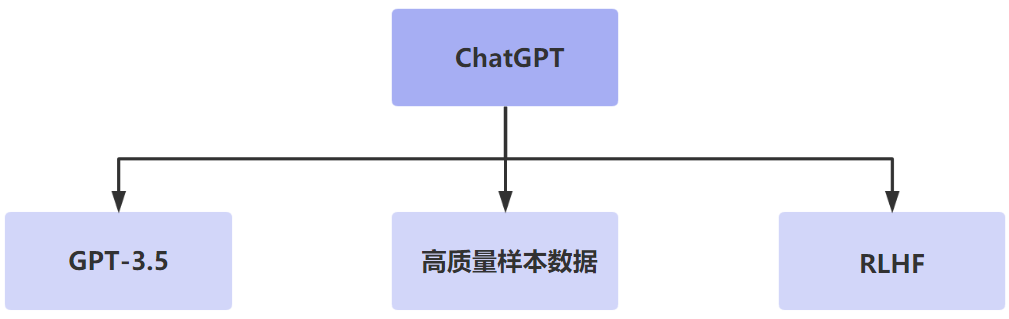
最核心的还是RLHF技术,通过训练来找到最能解释人类判断的reward函数,然后不断训练进行强化认知。
ChatGPT带来哪些变革
取代搜索引擎
当前的搜索引擎只能根据我们搜索的关键字,在搜索引擎的数据库中匹配索引对应的网页进行结果反馈,像百度这样的搜索引擎还动不动给你塞点广告。用户仍然需要在返回的信息中找到自己最想要的。但是ChatGPT则不同,所答就是所问,省去了用户大量自己过滤无效搜索结果的时间和精力。ChatGPT能够非常准确的把握用户实际意图的理解,而传统的搜索引擎还是关键字匹配的搜索方式,实际上并不理解用户输入搜索语句的真实含义,但是ChatGPT做到可以理解用户输入的真实意图。另外他还会创造性地回答,帮助用户从繁杂的工作中解脱出来。
PS:微软的Bing搜索引擎开始接入ChatGPT。
取代人工客服
现在所谓的智能客服不过是预设了一些常见的问题进行自动回答,远远称不上所谓的智能的程度,但是在一定程度上可以降低公司在客服人员方面的投入成本。但是如果有了ChatGPT之后,由于它可以理解用户的真实意图,而不是机械地回答预设问题,因此更能够帮助用户解决实际客服问题,最大程度将客服人工成本降到最低。
取代内容创作
ChatGPT不仅可以回答问题,它还可以进行内容创作,比如写一首歌,作一首诗以及写一篇活动策划等等。所以很多关于文字内容创作的从业同学都感觉到了深深的危机,以前一直觉得机器人最先取代的应该是体力劳动工作者,但是谁能想到ChatGPT的出现直接把很多脑力工作者的工作干没了。

ChatGPT局限性
训练数据偏差
ChatGPT的训练数据是基于互联网世界海量文本数据的,如果这些文本数据本身不准确或者带有某种偏见,目前的ChatGPT是无法进行分辨的,因此在回答问题的时候会不可避免的将这种不准确以及偏见传递出来。
适用场景有限
目前ChatGPT主要可以处理自然语言方面的问答以及任务,在其他领域比如图像识别、语音识别等还不局必然相应的处理能力,但是相信在不远的将来可能会有VoiceGPT、ViewGPT,大家拭目以待。
高昂训练成本
ChatGPT属于NPL领域中的非常大的深度学习模型,其训练参数以及训练数据都非常巨大,因此如果想训练ChatGPT就需要使用大型数据中心以及云计算资源,以及大量的算力和存储空间来处理海量的训练数据,简单来说训练和使用ChatGPT的成本还是非常高的。
总结
AI人工智能已经说了很多年了,一直处于发展阶段,在一些特定领域已经取得应用成果。但是面对C端用户,基本没有可以拿得出手的真真意义上的人工智能应用产品。但是这次ChatGPT的发布却是一个里程碑式的节点事件,因为对于普通人来说AI人工智能不再是遥不可及的技术名词,而是触手可及实实在在的智能应用工具,可以让普通人真切地感受到AI人工智能的威力。另外我想说的是也许ChatGPT只是个开始,目前它只是按照人类的指令去完成对应的任务,但是在未来随着人工智能自我学习的不断迭代,可能会有意识,可能会自主的去做事情,到那个时候人类面对的到底是一个无所不能的好帮手还是无法控制的恶龙就不得而知了。


![[Java 进阶面试题] CAS 和 Synchronized 优化过程](https://img-blog.csdnimg.cn/2e801aa85df74f31ba85ab1273150b1d.png)