Hadoop 3.x 新特性剖析系列1
- 1. 概述
- 2. 内容
- 2.1 JDK
- 2.2 EC技术
- 2.3 YARN的时间线V.2服务
- 2.3.1 伸缩性
- 2.3.2 可用性
- 2.3.3 架构体系
- 2.4 优化Hadoop Shell脚本
- 2.5 重构Hadoop Client Jar包
- 2.6 支持等待容器和分布式调度
- 2.7 支持多个NameNode节点
- 2.8 默认的服务端口被修改
- 2.9 支持文件系统连接器
- 2.10 DataNode内部负载均衡
1. 概述
从功能上来说,Hadoop3比Hadoop2有些功能得到了增强,具体增加了哪些,后面再讲。首先,我们来看看Hadoop3主要带来了哪些变化:
- JDK:在Hadoop2时,可以使用JDK7,但是在Hadoop3中,最低版本要求是JDK8,所以低于JDK8的版本需要对JDK进行升级,方可安装使用Hadoop3
- EC技术:Erasure Encoding 简称EC,是Hadoop3给HDFS拓展的一种新特性,用来解决存储空间文件。EC技术既可以防止数据丢失,又能解决HDFS存储空间翻倍的问题
- YARN:提供YARN的时间轴服务V.2,以便用户和开发人员可以对其进行测试,并提供反馈意见,使其成为YARN Timeline Service v.1的替代品。
- 优化Hadoop Shell脚本
- 重构Hadoop Client Jar包
- 支持随机Container
- 支持多个NameNode
- 部分默认服务端口被改变
- 支持文件系统连接器
- DataNode内部添加了负载均衡
2. 内容
2.1 JDK
在Hadoop 3中,所有的Hadoop JAR包编译的环境都是基于Java8来完成的,所有如果仍然使用的是Java 7或者更低的版本,你可能需要升级到Java 8才能正常的运行Hadoop3。如下图所示:

2.2 EC技术
首先,我们先来了解一下什么是Erasure Encoding。如下图所示:

一般来说,在存储系统中,EC技术主要用于廉价磁盘冗余阵列,即RAID。如上图,RAID通过Stripping实现EC技术,其中逻辑顺序数据(比如:文件)被划分成更小的单元(比如:位、字节或者是块),并将连续单元存储在不同的磁盘上。
然后,对原始数据单元的每个Stripe,计算并存储一定数量的奇偶校验单位。这个过程称之为编码,通过基于有效数据单元和奇偶校验单元的解码计算,可以恢复任意Stripe单元的错误。当我们想到了擦除编码的时候,我们可以先来了解一下在Hadoop2中复制的早期场景。如下图所示:

HDFS默认情况下,它的备份系数是3,一个原始数据块和其他2个副本。其中2个副本所需要的存储开销各站100%,这样使得200%的存储开销,会消耗其他资源,比如网络带宽。然而,在正常操作中很少访问具有低IO活动的冷数据集的副本,但是仍然消耗与原始数据集相同的资源量。
对于EC技术,即擦除编码存储数据和提供容错空间较小的开销相比,HDFS复制,EC技术可以代替复制,这将提供相同的容错机制,同时还减少了存储开销。如下图所示:

EC和HDFS的整合可以保持与提供存储效率相同的容错。例如,一个副本系数为3,要复制文件的6个块,需要消耗6*3=18个块的磁盘空间。但是,使用EC技术(6个数据块,3个奇偶校验块)来部署,它只需要消耗磁盘空间的9个块(6个数据块+3个奇偶校验块)。这些与原先的存储空间相比较,节省了50%的存储开销。
由于擦除编码需要在执行远程读取时,对数据重建带来额外的开销,因此他通常用于存储不太频繁访问的数据。在部署EC之前,用户应该考虑EC的所有开销,比如存储、网络、CPU等。
2.3 YARN的时间线V.2服务
Hadoop引入YARN Timeline Service v.2是为了解决两个主要问题:
- 提高时间线服务的可伸缩性和可靠性;
- 通过引入流和聚合来增强可用性
下面首先,我们来剖析一下它伸缩性。
2.3.1 伸缩性
YARN V1仅限于读写单个实例,不能很好的扩展到小集群之外。YARN V2使用了更具有伸缩性的分布式体系架构和可扩展的后端存储,它将数据的写入与数据的读取进行了分离。并使用分布式收集器,本质上是每个YARN应用的收集器。读则是独立的实例,专门通过REST API服务来查询
2.3.2 可用性
对于可用性的改进,在很多情况下,用户对流或者YARN应用的逻辑组的信息比较感兴趣。启动一组或者一系列的YARN应用程序来完成逻辑应用是很常见的。如下图所示:

2.3.3 架构体系
YARN时间线服务V2采用了一组收集器写数据到后端进行存储。收集器被分配并与它们专用的应用程序主机进行协作,如下图所示,属于该应用程序的所有数据都被发送到应用程序时间轴的收集器中,但是资源管理器时间轴收集器除外。

对于给定的应用程序,应用程序可以将数据写入同一时间轴收集器中。此外,为应用程序运行容器的其他节点的节点管理器,还会向运行应用程序主节点的时间轴收集器写入数据。资源管理器还维护自己的时间手机线收集器,它只发布YARN的通用生命周期事件,以保持其写入量合理。时间的读取器是单独的守护进程从收集器中分离出来的,它旨在服务于REST API查询操作。
2.4 优化Hadoop Shell脚本
Hadoop Shell脚本已经被重写,用来修复已知的BUG,解决兼容性问题和一些现有安装的更改。它还包含了一些新的特性,内容如下所示:
所有Hadoop Shell脚本子系统现在都会执行hadoop-env.sh这个脚本,它允许所有环节变量位于一个位置;
守护进程已通过*-daemon.sh选项从*-daemon.sh移动到了bin命令中,在Hadoop3中,我们可以简单的使用守护进程来启动、停止对应的Hadoop系统进程;
触发SSH连接操作现在可以在安装时使用PDSH;
${HADOOP_CONF_DIR}现在可以任意配置到任何地方;
脚本现在测试并报告守护进程启动时日志和进程ID的各种状态;
2.5 重构Hadoop Client Jar包
Hadoop2 中可用的Hadoop客户端将Hadoop的传递依赖性拉到Hadoop应用程序的类路径上。如果这些传递依赖项的版本与应用程序使用的版本发送冲突,这可能会产生问题。
因此,在Hadoop3中有新的Hadoop客户端API和Hadoop客户端运行时工件,它们将Hadoop的依赖性遮蔽到单个JAR中,Hadoop客户端API是编译范围,Hadoop客户端运行时是运行时范围,它包含从Hadoop客户端重新定位的第三方依赖关系。因此,你可以将依赖项绑定到JAR中,并测试整个JAR以解决版本冲突。这样避免了将Hadoop的依赖性泄露到应用程序的类路径上。例如,HBase可以用来与Hadoop集群进行数据交互,而不需要看到任何实现依赖。
2.6 支持等待容器和分布式调度
在Hadoop3 中引入了一种新型执行类型,即等待容器,即使在调度时集群没有可用的资源,它也可以在NodeManager中被调度执行。在这种情况下,这些容器将在NM中排队等待资源启动,等待荣容器比默认容器优先级低,因此,如果需要,可以抢占默认容器的空间,这样可以提供机器的利用率。如下图所示:

默认容器对于现有的YARN容器,它们由容量调度分配,一旦被调度到节点,就保证有可用的资源使它们执行立即开始。此外,只要没有故障发生,这些容器就可以允许完毕。
等待容器默认由中心RM分配,但还增加了支持以允许等待容器被分布式调度,该调度群被实现于AM和RM协议的拦截器。
2.7 支持多个NameNode节点
在Hadoop2中,HDFS NameNode高可用体系结构有一个Active和Standby NameNode,通过JournalNodes,该体系结构能够容忍任何一个NameNode失败。
然而,业务关键部署需要更高程度的容错性。因此,在Hadoop3中允许用户运行多个备用的NameNode。例如,通过配置三个NameNode(1个Active NameNode和2个Standby NameNode)和5个JournalNodes节点,集群可以容忍2个NameNode节点故障。如下图所示:

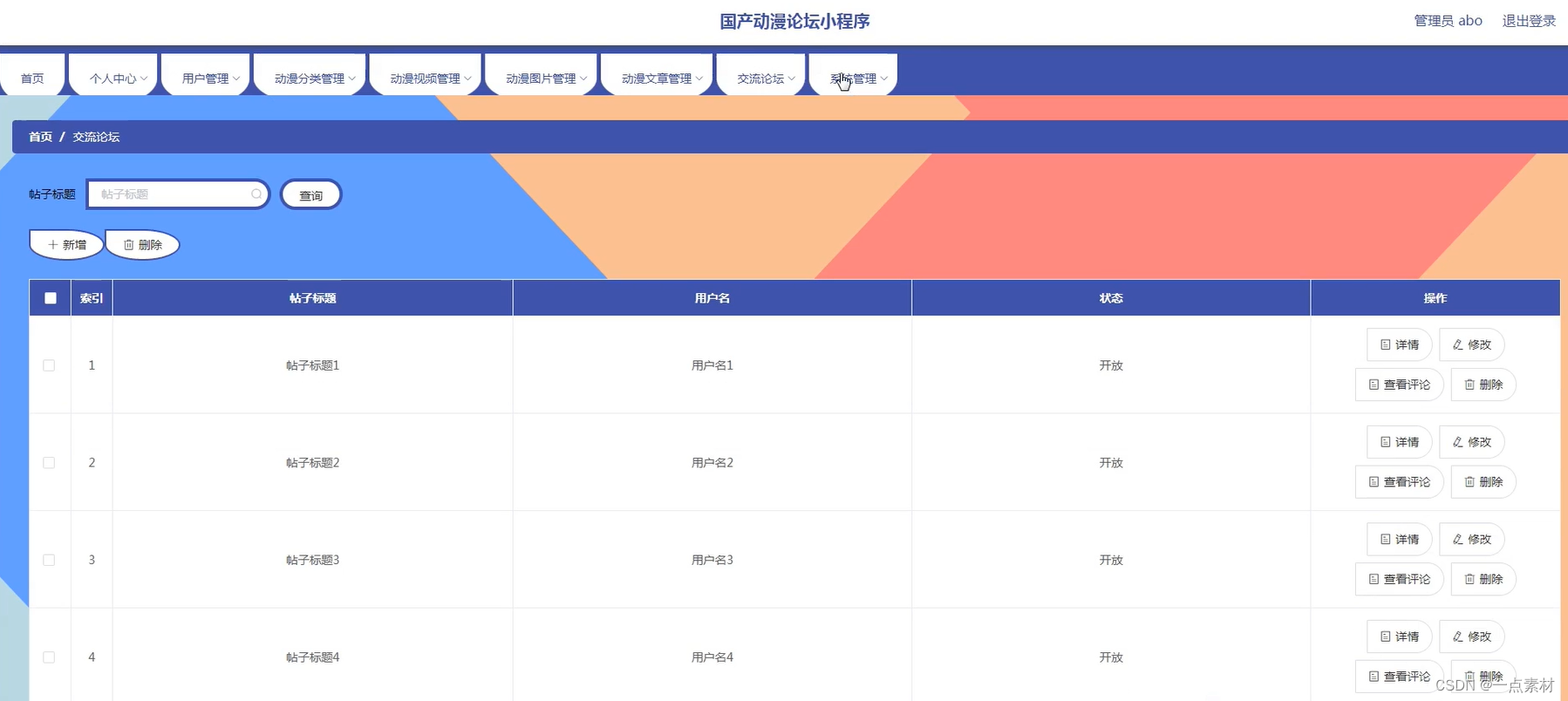
2.8 默认的服务端口被修改
早些时候,多个Hadoop服务的默认端口位于Linux端口范围以内。除非客户端程序明确的请求特定的端口号,否则使用的端口号是临时的,因此,在启动时,服务有时会因为与其他另一个应用程序冲突而无法绑定到端口。
因此,具有临时范围冲突端口已经被移除该范围,影响多个服务的端口号,即NameNode、Secondary NameNode、DataNode等如下所示:
2.9 支持文件系统连接器
Hadoop现在支持与微软 Azure数据和阿里云对象存储系统的集成。它可以作为一种替代Hadoop兼容的文件系统,首先添加微软Azure数据,然后添加阿里云对象存储系统。
2.10 DataNode内部负载均衡
单个数据节点配置多个数据磁盘,在正常写入操作期间,数据被均匀的划分,因此,磁盘被均匀填充。但是,在维护磁盘时,添加或者替换磁盘会导致DataNode节点存储出现偏移,这种情况在早期的HDFS文件系统中,是没有被处理的。如图下图所示,维护前和维护后不均衡的情况:

现在Hadoop3通过新的内部DataNode平衡功能来处理这种情况,这是通过hdfs diskbalancer CLI来进行调用的。执行之后,DataNode会进行均衡处理,如下图所示: