前言
哈喽!上午好嘞,各位小可爱们!有没有等着急了呀~
由于最近一直在学习新的内容,所以耽搁了一下下,抱歉.jpg 双手合十。
所有文章完整的素材+源码都在👇👇
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。

今天稍微赶了一下下,嘿嘿,想着还是给大家更新一下蛮,爬虫的内容基本上都过不了审核,
可能是我写的方式不对,思考.jpg,这么久了还是没找到好办法,大概率知道不能出现某些网
站的名字网址等,所以最近给大家更新的爬虫系列,就简简单单给大家写一点儿叭~
部分爬虫的代码是有录制完整的视频滴 讲解的更加仔细哈,需要的还是可以滴一下我哦!
好啦,开始今天的正题吧——Python采集某网站m3u8 格式视频哦 ~

正文
一、课前准备
运行环境:Python3(解释器版本我用的3.7,识别代码)Pycharm(编辑器 编辑代码滴 )
模块安装如下——
requests——pip install +模块名 或镜像源安装:
pip install -i https://pypi.douban.com/simple/+模块名内置模块:import re import json 安装好Python环境即可。
二、爬虫的基本流程
明确自己的需求---> 视频内容以及视频标题 - 通过开发者工具<>抓包分析,
分析视频是从哪里来的 - F12 fn+f12 右击页面点击检查 - a站 m3u8视频格式 ---> media 是
没有数据 mp4文件 ---> 整个视频内容 m3u8视频格式 ---> 把 整个视频内容 分割非常多小片
段 - 代码的实现步骤 1. 发起请求 2. 获取数据 3. 解析数据 4. 保存数据 三、抓取目标
1)目标网址
https://www.acfun.cn/v/ac13524296
分析视频是从哪里来的 - F12。
找到User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36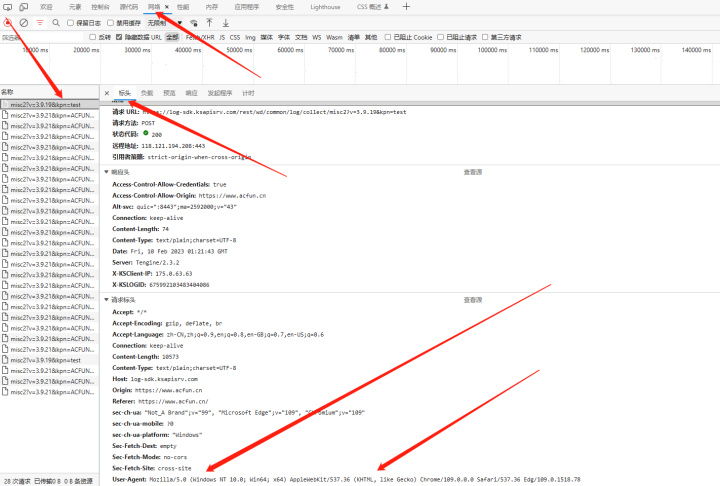
2)代码实现
"""
# 导入模块
import requests
# 导入正则模块
import re
# 导入数据格式化模块
from pprint import pprint
import json
url = 'https://www.acfun.cn/v/ac13524296'
# 模拟浏览器 请求头
# User-Agent 用户代理
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# 1. 发起请求
response = requests.get(url, headers=headers)
# 2. 获取数据 获取响应
# print(response.text)
# 3.数据解析
"""
.*? 元字符
. 匹配任意字符除了换行符之外
*匹配前一个字符0或者无限个
? 非贪婪匹配
"""
# 提取标题p
title = re.findall('"title":"(.*?)",',response.text)[1]
# print(title)
# 通过re提取视频内容信息
html_data = re.findall('window.pageInfo = window.videoInfo =(.*?);',response.text)[0]
# 数据转化json
json_data = json.loads(html_data)
# pprint(json_data)
# 字典取值 dict = {键值:value值} dict[键值]
m3u8_url = json.loads(json_data['currentVideoInfo']['ksPlayJson'])['adaptationSet'][0]['representation'][0]['backupUrl'][0]
pprint(m3u8_url)
m3u8_data = requests.get(m3u8_url, headers=headers).text
# print(m3u8_data)
m3u8_data=re.sub('#E.*','',m3u8_data).split()
# print(m3u8_data)
for ts in m3u8_data:
# print(ts)
ts_url = 'https://ali-safety-video.acfun.cn/mediacloud/acfun/acfun_video/hls/'+ts
ts_name = ts.split('.')[1]
# print(ts_url,ts_name)
ts_content = requests.get(url=ts_url,headers=headers).content
# 保存 图片 音频 视频 都是字节流 二进制
with open('video\\'+ts_name+'.mp4' , mode='wb') as f:
f.write(ts_content) 四、效果展示
四、效果展示
A站是m3u8的数据格式,很多人就会问了,你怎么知道,你为什么知道,你凭什么知道。
这些咱们都是可以通过开发者工具对于网页内容的分析,可以看到链接的后缀都是ts结尾的,
这样的文件内容都是你m3u8格式,是把整个视频分成多段的ts文件。
我们可以看到一段视频仅仅只有5秒钟的时间。对于ts文件有一个特性,它就是会存在一个
m3u8文件里面,所有的ts文件都在那,所以只需要找到m3u8的文件就可以了。
视频文件:

如何合成ts文件变成mp4呢?
添加到压缩文件——更改压缩文件后缀名以及压缩方式——后缀名改为:.mp4,压缩方式改
为:存储,然后点击确定即可。
播放视频:

特别说明:这样合并的前提是你的ts文件都是0000,然后0001 这样按照顺序排列的,不然你
合并出来之后播放顺序是乱的。
总结
XX忍者这部漫画连载了将近二十年,正好是一代人从小成长起来的时间。可以说不少人的童年
是伴随着XX忍者而成长起来的。让人记忆深刻的不仅有强大的忍者,眼花缭乱的忍术,还有一
些“童年阴影”的画面。让那个时候的我们记忆犹新。今天带大家爬完这些视频之后,有没有勾
起了你童年时期的回忆呢?
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
🔨推荐往期文章——
1.0 Python爬虫入门推荐案例:学会爬虫_表情包手到擒来~
1.1 【Tkinter界面化小程序】用Python做一款免费音乐下载器、无广告无弹窗、清爽超流畅哦
1.2 【Python爬虫实战】 不生产小说,只做网站的搬运工,太牛逼了~(附源码)
1.3 【Python抢票神器】火车票枪票软件到底靠谱吗?实测—终极攻略。
1.4 【Python实战】WIFI密码小工具,甩万能钥匙十条街,WIFI任意连哦~(附源码)
1.5 【Python实战】再分享一款商品秒杀小工具,我已经把压箱底的宝贝拿出来啦~
1.6 【Python实战】年底找工作,年后不用愁,多个工作岗位随你挑哦~
1.7 【Python实战】听书就用它了:海量资源随便听,内含几w书源,绝对精品哦~
1.8 【Python实战】海量表情包炫酷来袭,快来pick斗图新姿势吧~(超好玩儿)
🎁文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)









![[CCS 2022] 皇帝没有衣服:用于网络安全的AI/ML](https://img-blog.csdnimg.cn/img_convert/8c527794a3a202e9169432129ca7542c.png)