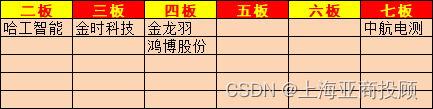
前言
传统的行为预测方法是规则的,基于道路结构的约束生成多个行为假设。最近,很多基于学习的预测方法被提出。他们提出了对于不同行为假设的进行概率解释的好处,但是需要重构一个新的表示来编码地图和轨迹信息。有趣的是,虽然高精度地图是高度结构化的,但是目前大多数预测方法选择将高精度地图渲染成颜色编码的属性,并且采用感受野有限的卷积神经网络对场景信息进行编码。这带来一个疑问:能否直接从结构化的高精度地图中学习到有意义的场景信息表示?

文章提出直接从它们的矢量形式中学习一个动态交通参与者和结构化场景的统一的表示(如图1的右图所示)。道路特征的地理延伸可以是一个点,多边形或是曲线。例如,车道边界包含可以构成样条曲线的多个控制点;人行横道是由几个点定义的多边形;停止标识通过一个点来表示。所有的地理实体都可以被近似为多个控制点定义的折线。同时,动态交通参与者也可以通过他们的运动轨迹被近似为折线。所有的这些折线都可以表示为矢量的集合。

使用图神经网络来合并这些向量的集合。 将每个向量视为图中的一个节点,并且定义节点的特征包含每个向量的起始位置和结束位置,以及其它属性,包括折线ID和语义标签。通过图神经网络,高精度地图的环境信息和其他交通参与者的运动轨迹被整合到目标交通参与者节点上。然后 可以解码目标交通参与者输出的节点特征来预测它未来的运动轨迹。
特别地,为了学习图神经网络的竞争性表示, 发现基于节点的空间和语义邻近性来约束图的连通性是很重要的。因此, 提出了一个分层的图网络结构,首先把具有相同折线ID,并且具有相同语义标签的向量整合成折线特征,然后所有不同的折线特征互相连通交换信息。 通过多层感知器实现局部图,通过自注意力机制实现全局图的方法如图2所示。

图2. 提出的VectorNet框架。观察到的交通参与者运动轨迹和地图特征被表示为矢量序列,然后传入局部图网络中获得折线级的特征。这些特征然后被传入一个全连接图网络中来建模高阶的交互。 计算两类损失:从目标交通参与者对应的节点特征中预测其未来轨迹,以及预测图网络中被掩盖的节点特征。
最后,受到来自连续语音和视觉数据中采用自监督学习方法的有效性的启发,在行为预测目标之外 提出一个辅助的图像补全目标。具体来说就是, 随机掩盖属于静态场景或是动态轨迹的节点特征,然后让模型重构被掩盖的特征。 直觉上认为这样可以鼓励图网络结构更好地捕捉动态交通参与者和静态环境之间的交互。总而言之, 的贡献主要是:
(1)最先证明如何直接整合矢量化的场景信息和动态交通参与者信息来实现行为预测。
(2)提出了双层图网络结构VectorNet和节点补全辅助任务。
(3)在内部的行为预测数据集和Argoverse数据集上评估了提出的方法,结果表明 的方法在减少了超过70%的模型参数以及一个数量级的运算量的情况下达到了与采用渲染鸟瞰图实现预测的方法相当甚至更好的性能。同时, 的方法在Argoverse数据集上达到了目前最优的水平。
直接从结构化的HD MAP数据学习一个信息丰富的上下文(带动态ObjList),找到一种表示方法将HD Map结构化数据跟感知给出的动态的ObjList做到统一表达;然后,基于这个统一的表达做轨迹预测,道路结构(静态的环境信息)和动态的车辆都被表达成了vector,再次表达的基础上做了GNN网络来表达各个元素间交互关系,基于Conv的Encoder会丢失精度,这里采用MAE做法去做表达训练增强。
注:如何将HD Map等结构化信息做vector化呢?
基于spline就等间距采样,基于轨迹就等时间采样(对HD MAP元素1对1采样)。

dsi/dei起始点的坐标;ai特征信息,比如限速/车道等;j是在多边形P中的下标。
HD Map:随着自动驾驶等级的提高,对地图信息要求越来越高,于是HD Map就出现了,他几乎可以提供所有道路的信息,例如车道线位置,种类,颜色;交通信号灯位置及朝向,道路维修等信息。
方法
这个部分介绍了VectorNet方法。首先介绍如何矢量化动态交通参与者的轨迹和高精度地图。接下来提出了层级网络,它先分别聚合来自不同折线的局部特征,然后在全局上整合所有轨迹和地图特征。这个图最后将用于行为预测。
表示轨迹和地图
大多数高精度地图的标注是以样条曲线(如车道线)、封闭形状(如交叉路口)和点(如红绿灯)的形式呈现,并且附带属性信息,如语义标签和当前状态(如交通灯的颜色,道路的速度限制)。对于动态交通参与者,他们的轨迹是关于时间的有向样条曲线的形式。所有这些元素元素都可以近似为矢量序列:对于地图特征, 选择一个起点和方向,均匀地以相同的空间距离在样条曲线上采样关键点,然后把相邻的关键点串联成向量;对于轨迹, 可以通过固定的时间间隔(0.1秒)采样关键点,并将它们连接成向量。如果给定的时空间隔足够小,得到的这些折线就与原始地图和轨迹十分接近。
向量化的过程是一个在连续轨迹,地图标注和矢量集合之间的一对一的映射,虽然后者是无序的。这使 可以在矢量集合上构建一个可以被图神经网络编码的图表示结构。更具体地说, 将属于折线Pj的每一个向量vi看出图中的一个节点,节点特征如下:

其中dis和die是向量的起点和终点坐标,其可以表示为2D坐标(x,y)或是3D坐标(x,y,z);ai对应属性特征,比如动态交通参与者的类型,轨迹的时间戳,或是道路特征的类型,或是车道线的速度限制。j是Pj的ID,表示vi属于Pj。
为了使输入的节点特征与对应的交通参与者的位置无关, 将所有矢量的坐标原点确定在对应的交通参与者最后被观察到的位置。一个将来的工作是为所有交互的交通参与者设定一个坐标原点,这样他们的轨迹可以被平行地预测出来。

构建折线子图
为了利用节点的局部空间和语义信息, 采用了层级的方法,首先在向量层级上构建子图,其中属于同一折线的所有向量节点互相连接。假设一个折线P包含节点{v1,v2,…,vp}, 定义一层子图的前向操作如下:
其中vi(l)是子图网络第l层的节点特征。函数genc(.)编码独立的节点特征,ψagg(.)聚合所有相邻节点的特征,ψrel(.)是节点vi与其相邻节点之间的关系运算。
实际上,genc(.)是一个在所有节点中共享权重的多层感知器(MLP)。具体来说,多层感知器包含一个的全连接层,然后是层归一化[3],最后是ReLU激活函数。ψagg(.)是一个最大池化操作,ψrel(.)是一个简单的拼接。如图3所示。 堆叠多层子图网络,其中每层genc(.)的权重是不一样的。最后,为了获取折线的特征, 计算:

其中ψagg(.)仍是最大池化。

的子图可以被认为是PointNet[22]的一般化:当 令ds=de,并且使a为空, 的网络和PointNet就有相同的输入和计算流程。但是,通过将排序信息嵌入到向量中,基于不同的折线ID可以限制子图的连通性,同时将属性编码到节点特征中, 的方法尤其适合编码结构化的地图标注和交通参与者的运动轨迹。
用于高阶交互的全局图
现在考虑通过一个全局交互图来建模折线节点特征{p1,p2,….,pp}上的高阶交互:

其中,{pi(l)}是折线节点特征的集合,GNN(.)为一层图神经网络,A为折线节点集合的邻接矩阵
领接矩阵A可以是启发式的,例如使用节点之间的空间距离[2]。为简单起见, 假设A是一个全连接图。 的图网络通过自注意力机制实现
:
其中P是节点的特征矩阵,PQ,PK和PV是它的线性映射。
然后 从动态交通参与者对应的节点解码预测的未来轨迹:

其中Lt是图神经网络的层数,ψtraj(.)是轨迹解码器。为了简单起见, 使用一个多层感知器作为轨迹解码器。更多高级的解码器,比如MultiPath[6]提出的基于候选轨迹的方法,或是变分循环神经网络[8,26]都可以用来生成多样化的轨迹。
在实现中使用一层图神经网络,这样在测试期间,只需要计算目标交通参与者所对应的节点特征。但是如果需要, 也可以堆叠多层图神经网络来建模高阶交互。
为了鼓励 的全局交互图更好地捕捉不同轨迹和地图之间的交互, 提出了一个辅助的图像补全任务。在训练过程中, 随机掩盖一些节点的特征,然后尝试去还原被掩盖的节点特征:

其中ψnode(.)是通过多层感知器实现的节点特征解码器。这些节点特征解码器在测试阶段是不会使用的。
回顾一下,pi是一个完全连接的,无序的图中的一个节点。为了能够识别出对应的节点当它对应的节点特征被掩盖时, 计算出所有属于对应节点pi的向量中的起始点坐标的最小值。然后定义输入节点的特征为:

图像补全任务和自然语言处理中获得巨大成功的BERT[11]方法息息相关,它从文本数据的上下文线索中预测缺失的文本输入。 将这个训练目标推广到处理无向图中。不像最近一些方法(如[25]),将泛化为预训练的特征图的无序图像补丁, 的节点特征是在端到端的框架中同时优化的。
整体框架
建立层级图神经网络后, 对多任务训练目标进行优化:

其中Ltraj是对未来真值轨迹的负高斯对数似然,Lnode是预测的节点特征和被掩盖的真值节点特征之间的Huber损失,a=1.0是一个标量用来平衡两个损失项。
预测的轨迹为每个时间步的坐标偏移,并从最后一个观测位置开始。同时, 基于预测目标车辆最后一个观察时刻的朝向旋转坐标系。
实验
在这部分,首先描述实验设置,包括数据集,指标和基于栅格化+卷积网络的基准。其次,对分别全面地对栅格化基准方法和VectorNet做消融研究。然后, 比较和讨论了计算代价,包括计算量和参数量。最后, 与最先进的方法的性能进行比较。
实验设置
1. 数据集
在两个车辆行为预测的数据集上进行实验,分别是Argoverse数据集[7]和 内部的行为预测数据集。
Argoverse行为预测[7]是一个用于在提供历史轨迹的情况下进行车辆行为预测的数据集。其中有33.3万个5秒时长的轨迹序列被分成21.1万个训练样本,4.1万个验证样本和8万个测试样本。这个数据集被创造是为了挖掘有趣的和多样化的场景,比如并道,穿过路口等。轨迹的采样频率为10Hz,前2秒用于观测,后3秒用于轨迹预测。每个序列中都包含一个“interesting”交通参与者作为被预测主体。除了车辆轨迹,每个序列还与地图信息相关联。数据集中测试集的未来轨迹被隐藏了。所以除非另外说明, 消融实验报告的是验证集上的性能。
内部数据集是一个大规模的用于行为预测的数据集。它包含高精度地图数据,感知体系统获取的检测框和跟踪信息,以及手工标注的车辆轨迹。车辆轨迹的总数包括220万个训练样本进而55万个测试样本。每个轨迹的长度为4秒,其中前1秒作为观测的历史轨迹,后3秒作为预测的未来轨迹。轨迹是从车辆在真实世界中的行为采样得到的,包括静止,直行,转弯,变道和倒车等等,并且大致保留了驾驶场景的自然分布。在高精度地图中, 包括了车道边界,停止标志,人行横道和减速带。
数据集
两个车辆行为预测bench-marks。
- Argoverse dataset:简介每条轨迹5s,前2s作为观测,后3s作为标签。
- in-house behavior prediction dataset: 每条轨迹4s,前1s作为观测,后3s作为标签。
- Argoverse运动预测是一个精心挑选的324,557个场景集合,每个场景5秒,用于训练和验证。每个场景都包含以10 Hz采样的每个跟踪对象的2D鸟瞰质心(3D点云可与2D鸟瞰图相互转换)。
两个数据集的历史轨迹都是从感知模型来的,所以存在噪声。Argoverse dataset的标签轨迹也是从感知来的,in-house behavior prediction dataset的标签轨迹是经过手工标记的。
2. 评价指标
对于评价指标,采用被广泛使用的计算整个轨迹的平均位移误差和t时刻的位移误差,其中t分别为1秒,2秒,3秒。位移用米来作为度量。
- ADE-Average Displacement Error-平均偏移误差,在时间t=1.0,2.0,3.0s预测轨迹处的偏移量,单位是m
3. 栅格图基准
渲染N张连续帧的历史图像,其中对于内部数据集N为10,对于Argoverse数据集N为20。每张图片尺寸为400×400×3,其中包括地图信息和目标检测的矩形框。400像素分别对应内部数据集中的100米和Argoverse数据集中的130米。基于自动驾驶车辆在最后观察帧中的位置进行渲染。自动驾驶汽车在内部数据集中被放置的坐标位置为(200,320),在Argoverse数据集中为(200,200)。所有N帧图片被堆叠在一起构成400×400×3N的图像作为模型输入。
栅格图基准使用卷积网络来编码栅格图片,其结构与IntentNet[5]大体一致。 使用ResNet-18[14]作为卷积网络的主干网。与IntentNet不同的是, 不使用LiDAR输入。
为了获得以车辆为中心的特征, 从卷积特征图中裁剪目标车辆周围的特征部分,并且将裁剪后的特征图的所有空间位置进行平均池化,得到一个车辆特征向量。根据经验观察到,使用更深层的ResNet模型或者根据车辆的朝向旋转特征并不能得到更好的效果。车辆的特征向量然后被传入全连接层来预测未来的轨迹坐标。模型用过8块GPU同步训练优化。 使用Adam[17]作为优化器并且以0.3系数衰减每隔5次训练周期衰减学习率。 训练了25个周期的模型并且设置初始学习率为0.001。
为了测试卷积感受野和特征裁剪策略对性能的影响, 对网络感受野,特征裁剪策略和输入图像分辨率进行消融研究。
卷积网络基准的消融研究
- baseline-ConvNet
- 从最后一次观测到的Vehicle的帧开始,往前render N个连续的帧。对于Argoverse 数据集来说400像素代表130米,对于in-house数据集来说400像素代表100米。将N帧堆叠在一起,形成一个400乘400的图像输入数据。
分别对卷积网络的感受野,特征裁剪策略和栅格图的分辨率的影响进行消融研究。
感受野的影响。由于行为预测经常需要捕捉大范围的道路信息,所以卷积的感受野可能会对预测质量有很大的影响。 分别评估不同的变体来观察感受野的两个关键因素(卷积核的大小和特征裁剪策略)是如何影响预测性能的。结果如表1所示。通过比较在400*400分辨率下的大小为3,5和7的卷积核尺寸, 可以发现更大的卷积核尺寸会轻微地改善性能。但是,它也会大量增加计算成本。 也比较了不同的裁剪方法,通过增加裁剪尺寸或是沿着车辆轨迹裁剪。从表1的第3行到第6行 可以看出,较大的裁剪尺寸可以显著地提高性能,同时沿着轨迹裁剪也能得到更好的性能。这一观察结果证实了当把栅格化图像作为输入时,感受野的重要性。同时,也体现了它的局限性,一个精心设计的裁剪策略通常伴随着计算成本的增加。
- 从最后一次观测到的Vehicle的帧开始,往前render N个连续的帧。对于Argoverse 数据集来说400像素代表130米,对于in-house数据集来说400像素代表100米。将N帧堆叠在一起,形成一个400乘400的图像输入数据。
栅格图分辨率的影响。 进一步修改栅格图的分辨率来分析它如何影响预测性能和计算成本,如表1的前三行所示。 测试三个不同的分辨率,包括400×400(每个像素0.25米),200×200(每个像素0.5米)和100×100(每个像素1米)。可以看出随着分辨率的提高,性能也普遍得到了提高。但是,对于Argoverse数据集 可以看出将分辨率从200×200增加到400×400会导致性能的略微下降,这可以解释为对于固定的3×3卷积核尺寸,有效感受野的减小造成的。 在4.4部分讨论了这些设计选择对计算成本的影响。
表1.感受野(受到卷积核的尺寸和裁剪策略控制)和渲染分辨率对卷积网络基准的影响。 分别在内部数据集和Argoverse数据集上汇报了位置偏移误差(DE)和平均位置偏移误差(ADE)。

VectorNet消融研究
- VectorNet
- 原则-尽量保证于ConvNet具有相同的输入信息。折线子图采用3层结构,全局图为一层结构,MLP是64个结点。对context information,子图和全局图的层数做了消融实验。
输入节点类型的影响。 研究对于VectorNet,合并地图特征和动态交通参与者的运动轨迹是否有意义。表2中的前三行对应只使用目标车辆的历史轨迹,只添加地图特征以及同时添加轨迹特征。 可以清楚地看到增加地图特征明显地改善了轨迹预测性能。
节点补全损失的影响。表2的后四行比较了添加辅助的节点补全任务的影响。 可以看出添加这一任务有助于改善性能,尤其在长期预测。
图结构的影响。在表3中 研究了图的深度和广度对轨迹预测性能的影响。 观察到,对于折线子图,三层具有最好的性能,而对于全局图,只需要一层。让多层感知器变宽并不会带来更好的性能,反而会对Argoverse数据集造成不好的影响,可能是因为其训练集更小。图4显示了显示了一些预测的轨迹的可视化示例。
与卷积网络比较。最后, 在表4中比较 的VectorNet和最好的卷积网络模型。对于内部数据集,在大量减少模型参数和计算量的前提下, 的模型达到了与最好的残差网络模型相当的性能。对于Argoverse数据集, 的方法明显优于最好的卷积网络,在预测3秒时位置误差减少了12%。 发现内部数据集包含很多静止的车辆,因为它是自然分布的驾驶场景。这些场景可以很容易地被卷积网络解决,因为它擅长捕捉局部模式。但是Argoverse数据集中只提供“interesting”场景。VectorNet性能好过最优的卷积网络基线,大概是因为它能够通过层级图网络捕捉更大范围的环境信息。
表2.对VectorNet不同的节点输入类型和训练策略的消融研究。这里“map”指的是来自高精度地图的输入向量,“agent”指的是非目标车辆运动轨迹的输入向量。当“Node Compl”启用,模型训练任务除了轨迹预测还包括图节点特征补全。

表3.对于折线子图和全局图的深度和宽度的消融研究。折线子图对第3秒位置偏移误差影响最大。

模型尺寸和计算量的比较
现在比较卷积网络和VectorNet的计算量和模型尺寸,以及它们对性能的影响。结果如表4所示。预测的解码器没有添加到计算量和参数量的计算中。 可以看到随着卷积核尺寸和输入图片尺寸的增加,卷积网络的计算量呈二次方增加,并且模型的参数量也随着卷积核呈二次方增加。对于VectorNet,计算量取决于场景中的向量节点和折线的数量。对于内部数据集,地图中折线的平均数量为17,包含205个向量。平均动态交通参与者折线数为59,包含590个向量。 基于这些平均数来计算计算量。注意,因为 需要重新标准化向量坐标系和重新计算每个目标的VectorNet特征,所以计算量随着预测目标的数量呈线性增加。
比较R18-k3-t-r400(卷积网络中最优模型)和VectorNet,VectorNet明显优于卷积网络。在计算方面,对于一个交通参与者,卷积网络比VectorNet增加了200+倍的计算量。考虑到场景中车辆的平均数量约为30辆,VectorNet的实际计算量仍然比卷积网络小得多。同时,VectorNet的参数量为卷积网络参数量的29%。基于比较可以发现VectorNet可以在大幅度减少计算成本的同时显著提高性能。
表4.ResNet和VectorNet的模型参数量和计算量比较。R18-Km-cN-rS表示ResNet-18模型的卷积核尺寸为M×M,裁剪尺寸为N×N,输入分辨率为S×S。

表5.在Argoverse测试集上当采样的轨迹数K设为1时,轨迹预测的性能。结果取自2020/03/18的Argoverse排行榜。

仿真与结果分析
提出矢量化地表示高精度地图和动态交通参与者。 设计一个层级图神经网络,其中第一级聚合折线中不同矢量的信息,第二级建模折线之间的高阶交互关系。 分别在大规模的内部数据集和公开的Argoverse数据集上进行实验,结果表明 提出的VectorNet方法在大量减少计算量的同时,其性能也要优于卷积网络方法。并且,VectorNet在Argoverse数据集上达到了目前最优水平。下一步工作是整合VectorNet编码器和多模态轨迹解码器以生成多样化的未来轨迹。


图4.(左)预测结果可视化:车道线为灰色,非目标交通参与者为绿色,目标交通参与者的真值轨迹为粉红色,预测轨迹为蓝色。(右)对于道路环境和其他交通参与者注意程度的可视化:明亮的红色对应较高的注意分数。可以看到,当交通参与者面临多种选择时,注意力机制能够将注意力集中在正确的选择上。
延申构思过程
代码链接
从几何意义看,车道线包含多个控制点,交叉路口是个多边形(带多个顶点),交通标志是一个点,所有这些都可被近似–多个顶点多边形。同样,动态Obj的轨迹也可被多边形近似。这种多边形都可以通过vector来表达。这里是整个vector表达的底层逻辑。

有了vector表达,现在要构造上下文;而上下文的表达比较自然的方式也就是Graph了。一组vector就是graph中的一个node(这个Node如何进行构建呢?)。如何采用Graph的方式,在Obj动态驶入/驶出的场景下,可以在已有graph上动态的增删节点然后进行推理?
graph如何构造,作者发现地理位置相近并且语义相近的多变性作为Node去构造Graph比较重要。属于同一多边形并且语义相近的vector做全连接,把属性编入多边形的特征中,多边形间做全连接,类似MAE做法,随机摸出一些Node让这个NN做估计;训练出来的NN能够更好的做表达:Node间的交互和上下文的刻画。
怎么能让multipath跟vectornet结合?关键是pre-define的anchor怎么在vectornet上表达?其本质也是point,既然是Point就能通过vector来表达。
构造多折线子图
最下层的子图,处理统一多边形的所有vector,并且vector间全连接。

vi(l)是第i层的特征;genc单节点的特征提取函数,agg所有邻接点特征聚合函数,rel节点跟其邻接点的关系函数。
从实现角度,genc是一个MLP,agg是一个maxpooling,rel简单的全连接;MLP的权重在一个多边形里面是一个。

agg仍然是一个maxpooling。

经过MLP-Pooling-Concat得到多边形的特征P。
高阶相互作用全局图
全局交互图公式如下:

A是多边形节点的邻接矩阵,通过GNN去处理第I层的节点Pil,得到其交互后的特征。
A的设计比较考究,可以按照距离来也可按照其他来(网络学习一个出来),这里简单用全连接来处理。

GNN即使简单的self-attention来实现(这样的话节点个数可以动态);P是所有节点的合起来的特征阵,PQ/PK/PV分别是Query/Key/Value的特征分量。

将节点的特征值decode成对应的vector,简单用MLP实现。并且使用单层的attention来实现;当然也可以做很复杂的。

类似MAE的做法,随机抹除一部分节点,通过node来轨迹本层的特征;node是一个简单的MLP。当适合的特征被屏蔽掉时,使用点坐标最小的那个作为vector下标。
总体框架

这里两个目标函数形式要注意,一个是高斯近似,一个时HuberLoss;另,在进入GNN前对多边形的特征做了L2正则。

观察到的智能体轨迹和地图特征被表示为向量序列,并传递给局部图网络以获得折线级特征。然后这些特征被传递给一个全连接图来建模高阶交互。计算了两种类型的损失:从移动代理对应的节点特征预测未来轨迹,以及在其特征被掩盖时预测节点特征。
方法
- 向量化表示地图和移动agent(轨迹,车道线采样,每个点用特征向量表示)
- 利用local graph net 聚合每条折线的特征(全联接网络,一条折线最后凝练出一个特征向量【一个点】)
- 利用全局graph聚合各个折线特性点的相互作用(全局图就是各个结点全联接构成的图,经过一层状态更新后通过解码网络得到目标对象的预测轨迹-轨迹的坐标位移)
1. Ployline Graph
- 向量化
地图特征(车道线,交叉路口)-选定起点和方向,在spline(样条)上等空间间隔采样,连接相邻点构成向量,运动轨迹-等时间间隔采样关键点构成向量。
一条轨迹Pj就是一个向量集合(v1,v2,v3,…,vp)。
曲线Pj向量vi的参数:dsi,dei表示起始和终止点坐标;ai对象类型、时间戳、道路类型、限速;j是轨迹编号:

- 折线子图-polyline subgraphs
同一条折线上的节点构成一张子图,节点特征更新规则:


3. 折线表征-同一条折线上所有结点特征经过一个最大池化操作,聚合特征:

注意点:
-
- 起始和终止点的坐标-二维/三维
-
- 目标agent最后一次被观察到time step/位置,作为时间或者空间的原点。
-
- 折线子图可以看作是PointNet的一般化-在PointNet中,ds = de,a和l为空。
2. Global Graph
- 全局图
折线结点{p1,p2,…,pP}构造全局图,A-邻接矩阵-为了简单起见,文章采用全联接图。

图具体计算采用self-attention操作:

P为结点特征矩阵,PQ,PK,PV是P的线形投影。
Q,K,V:来源于Transformer里的self-attention。展开说,如链接所示
- 预测moving agents的未来轨迹

- 附加图补全任务-auxiliary graph completion task
为了使图捕获轨迹和车道线强交互,在训练时,隐藏一部分折线结点特征向量,用模型去预测特征:


3. 消融实验
- ConvNet网络消融实验-卷积核、Crop尺寸、图像分辨率。
- VectorNet网络消融实验-Context、Node Compl、子图和全局图的层数。







![Python之FileNotFoundError: [Errno 2] No such file or directory问题处理](https://img-blog.csdnimg.cn/img_convert/5e96d62a80771794b2a1621eadbabb2a.png)