TDANet: 一种具有自上而下注意力的用于语音分离的高效自编码器架构
文章目录
- TDANet: 一种具有自上而下注意力的用于语音分离的高效自编码器架构
- 速览
- 摘要
- 方法
- Pipeline
- TDANet
- 实验
- 总结
速览
| 下载 | 收录 | 源码 | 机构 | 演示 |
|---|---|---|---|---|
| arxiv | ICLR 2023 | PyTorch | 清华大学 | Demo |
@inproceedings{tdanet2023iclr,
title={An efficient encoder-decoder architecture with top-down attention for speech separation},
author={Li, Kai and Yang, Runxuan and Hu, Xiaolin},
booktitle={ICLR},
year={2023}
}
摘要
-
问题描述:现有语音分离模型无法兼顾效率和性能。
-
解决方案:本文基于脑启发,提出了一个能够模拟大脑自上而下注意力的高效自编码器架构用于语音分离任务。具体地,它利用全局注意力(GA)模块和级联的局部注意力(LA)模块来获得一个自上而下的注意力表示。
-
实验结果:在三个基准数据集上进行了实验,与之前的 SOTA 模型 Sepformer 相比,TDANet 实现了一致性的具有竞争力的性能,并且效率极高。具体地,TDANet 的 MACs 只有 Sepformer 的 5%,CPU 推理时间仅为 Sepformer 的 10%。
方法
Pipeline
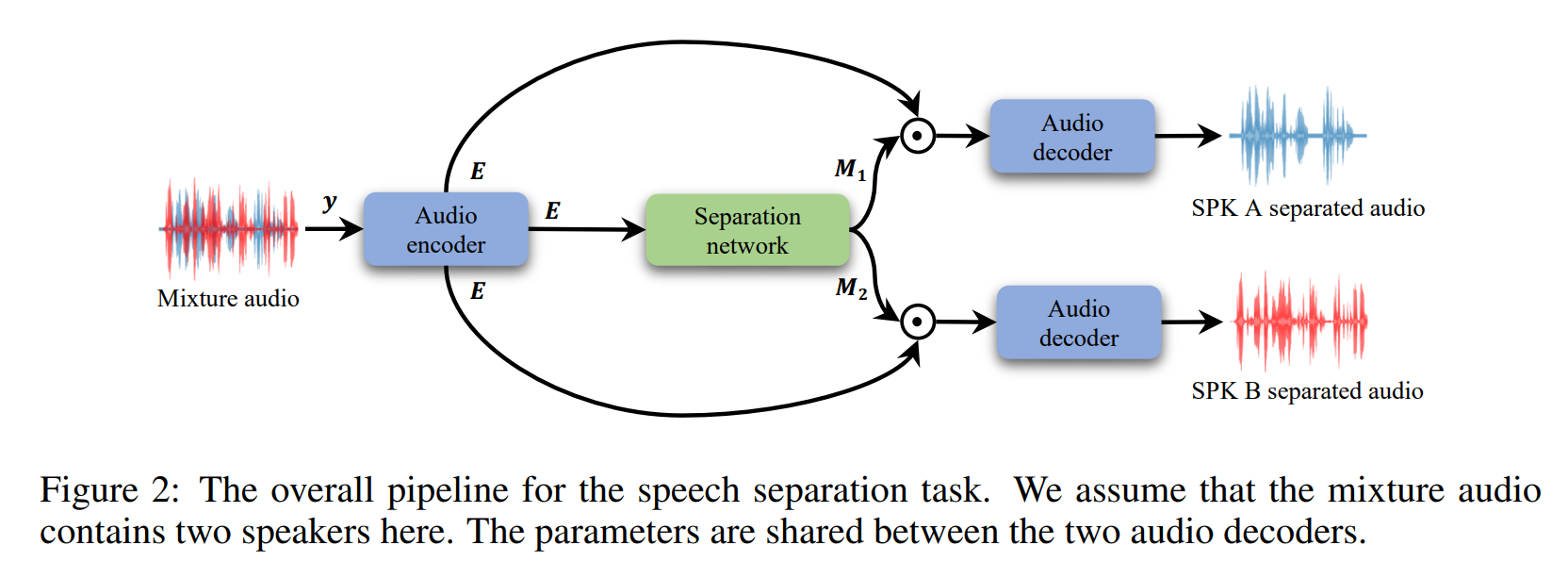
TDANet
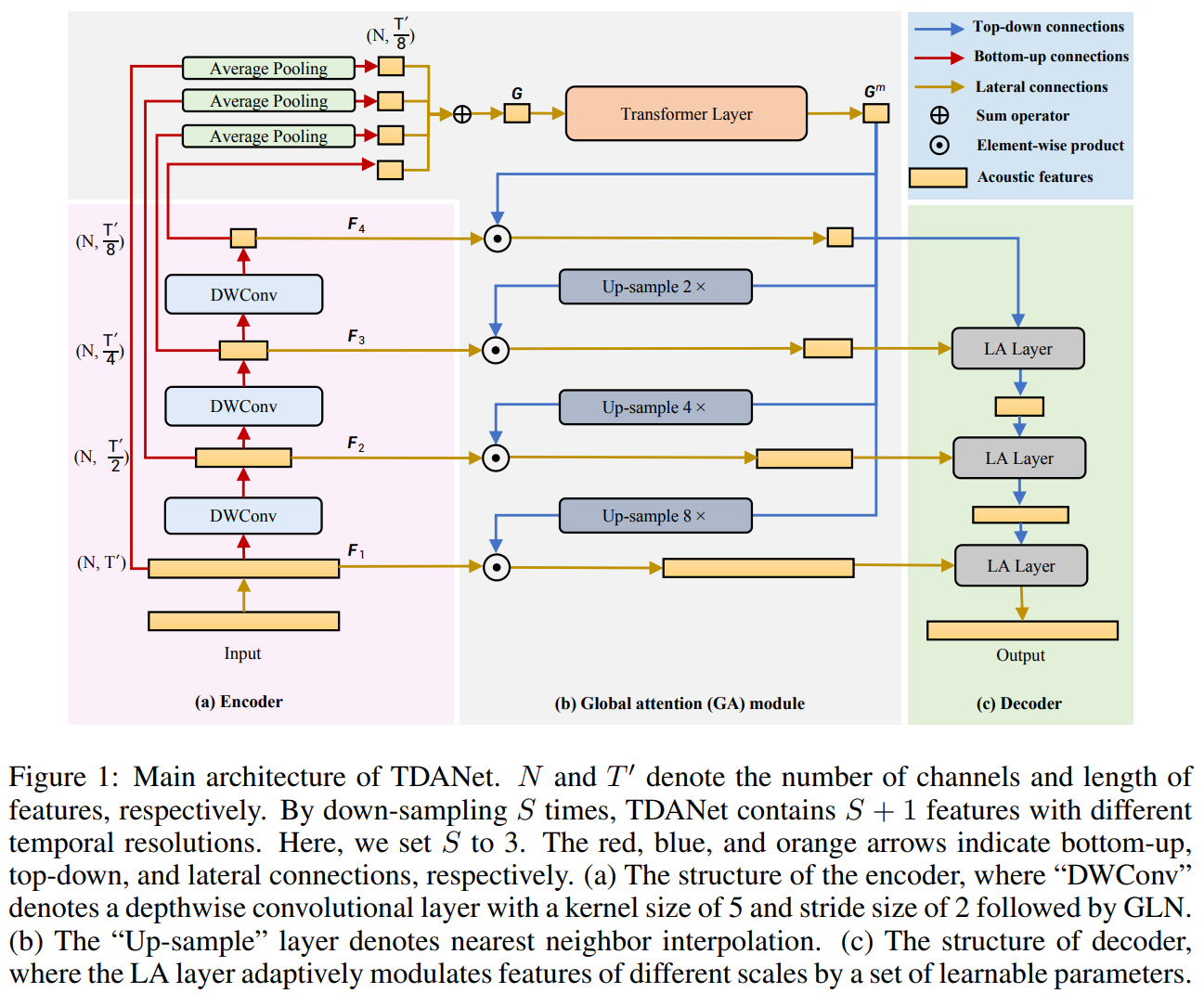
TDANet 的主要结构如上图所示。它由三部分构成:
1)编码器:采用多个卷积对输入的音频信号进行下采样。出于轻量的考虑,使用卷积核大小为 5,步长为 2 的深度可分离卷积来替换普通卷积;
2)全局注意力模块:GA 模块由一个转换层和自上而下的注意力组成。Transformer Layer 的输入是使用 dense connections 处理的融合的多尺度特征。dense connections 只使用 pooling layers,没有任何参数。当我们删除dense connections 时,TDANet 的编码器变成了典型的 U-Net 编码器。
我们使用 dense connections 有以下两个原因:
(1)dense connections 与 DenseNet 类似,提升了梯度的反向传播,使网络更容易训练;
(2)在自下而上的过程中,特征可能会失去一些细节。使用 dense connections 投射到顶层可以更有效地使用多尺度特征。
使用 Transformer Layer 的原因是,这个网络是明确为与语音分离任务(sequence task)兼容的序列建模而设计的,也是一个标准的注意力模型。 使用自上而下的注意力来调制不同规模的特征,在实现上是非常简单的(我们只需要通过 element-wise production 的一个步骤)。我们使用自上而下的注意力来调节局部特征,减少信息冗余,使网络更专注于任务相关的特征,更好地指导不同尺度的序列的建模过程。
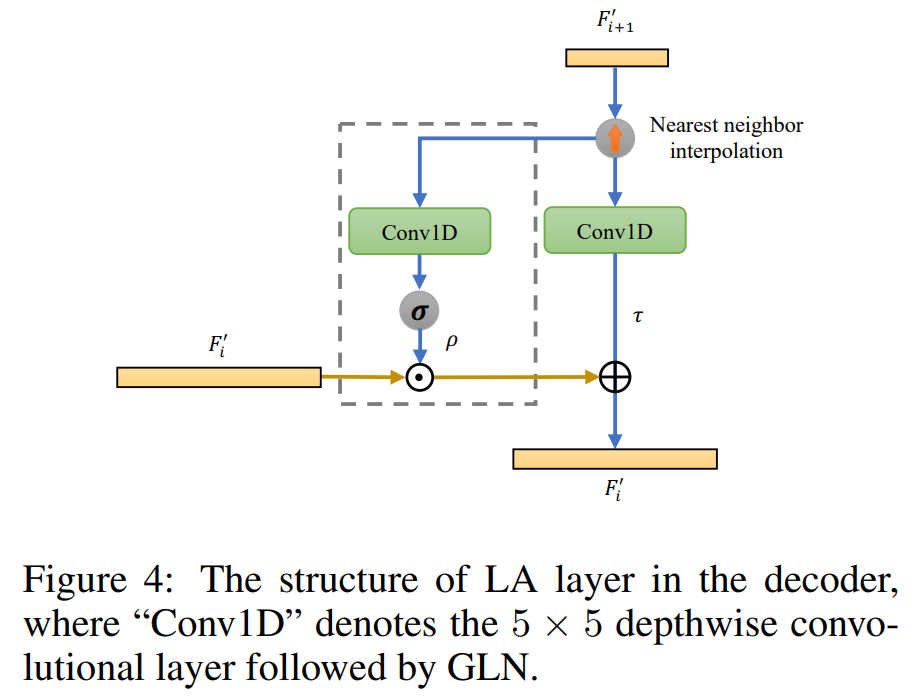
3)解码器:解码器由若干个级联的局部注意力层组成,主要负责音频信号的重建过程,其结构如下图所示。去掉图中的灰色方框后,它就成了一个典型的UNet中的解码器。LA层只是两个 1D 深度卷积层和一个 Sigmoid 函数,只有 ~0.01M 的参数。解码器中的LA层提高了分离性能(1.8dB 的增益),一个可能的原因是,LA 层使用邻近层的特征来学习一组参数,以适应性地调制当前层的融合特征,从而重建细粒度的特征。这一操作在以前基于 U-Net的模型(SuDoRM-RF)中是不可用的。因此,我们通过在 SuDoRM-RF 的解码器中加入 LA 层,再次验证 LA 层对于 SuDoRM-RF 模型的重要性。
实验
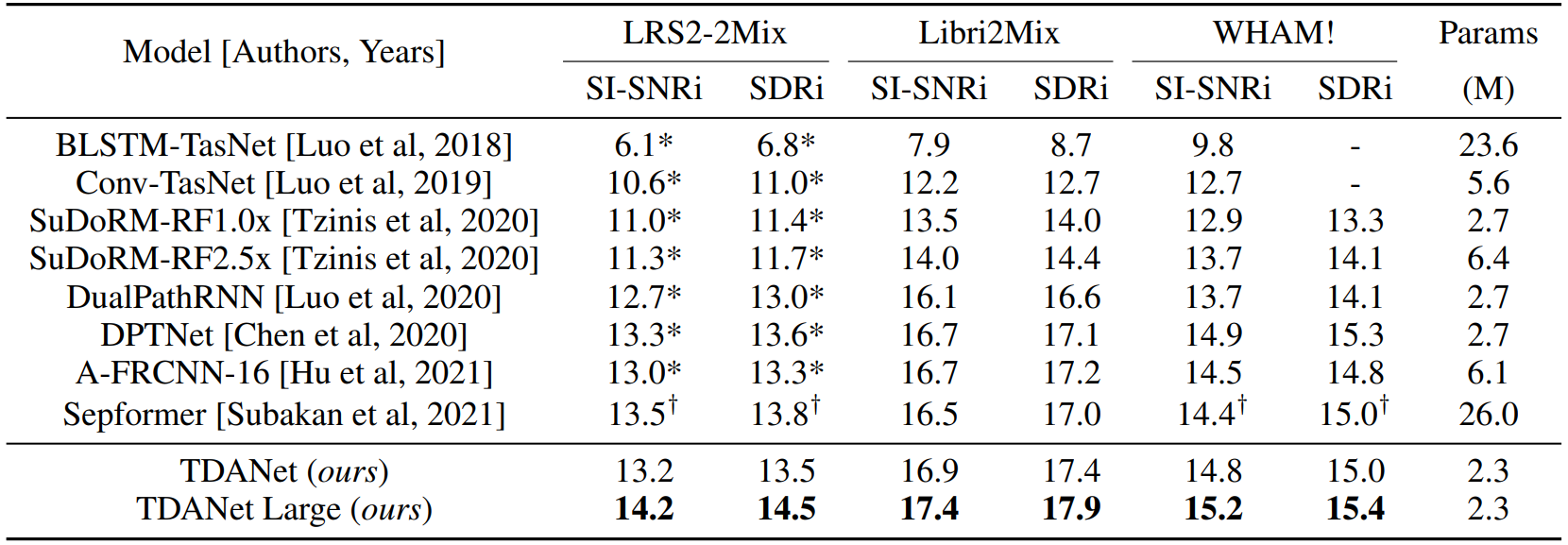
本文在三个基准数据集(Libri2Mix,WHAM! 和 LRS2-2Mix)上进行了实验,以验证其提出方法的性能和效率。
-
TDANet 具有最低的参数量,与之前的 SOTA 模型 Sepformer 相比,实现了具有竞争力的性能。此外,TADNet Large 在三个数据集上都实现了 SOTA 性能。
-
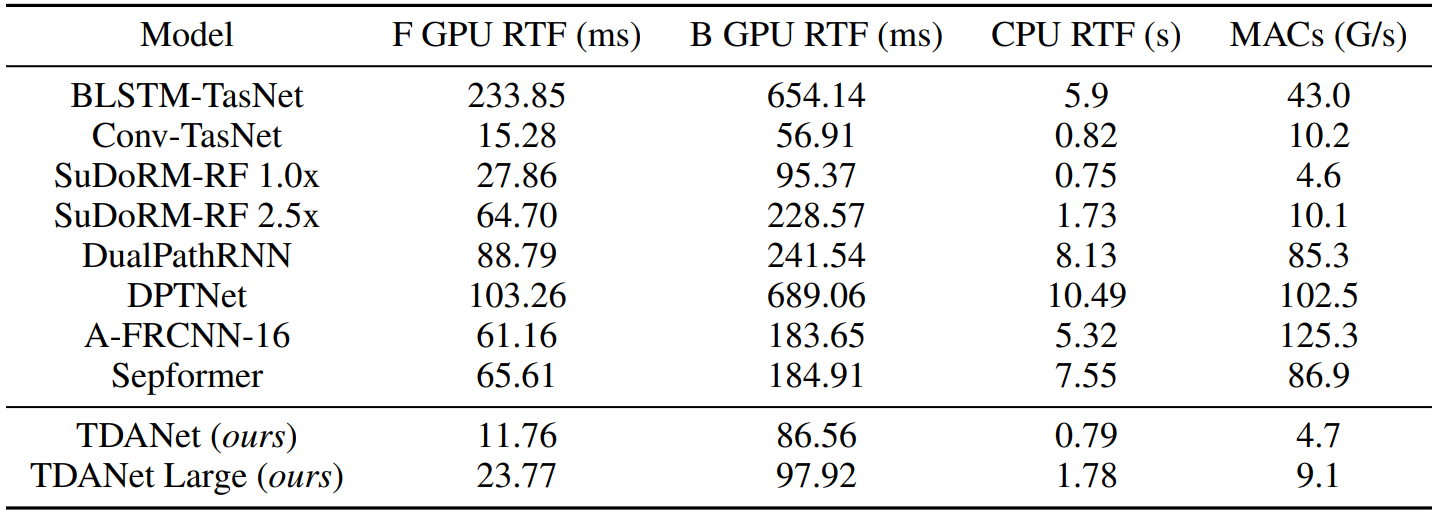
TDANet 的计算复杂度和推理时间远胜于之前的 SOTA 模型。
总结
对于语音分离任务,TDANet 可以兼顾性能和效率,相比于前一个 SOTA 模型,实现了极大的效率超越,对于语音分离模型的实际应用部署具有重要意义。TDANet 的成功也反映了基于脑启发仿真研究深度神经网络的正确性,我们可以从大脑的思考或感知过程中获得构建神经网络的灵感。此外,TDANet 提出的轻量级自编码器架构也可以轻松移植到计算机视觉等应用。







![Python之FileNotFoundError: [Errno 2] No such file or directory问题处理](https://img-blog.csdnimg.cn/img_convert/5e96d62a80771794b2a1621eadbabb2a.png)