告警
线上应用fullgc频繁,收到告警
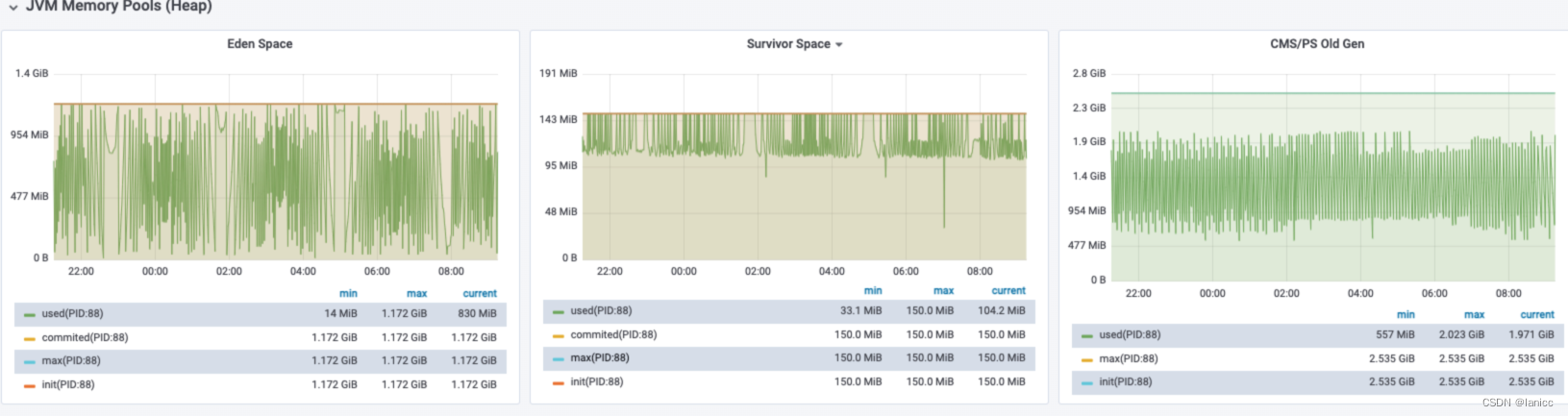
GC监控—堆内存不足
查看近12小时的监控,发现Survivor区一直处于 满状态、fullgc非常频繁、但没有内存溢出的现象,很明显是堆内存不足
GC日志分析—暂停时间并不长
因为fullgc相当频繁,抽取了一次fullgc日志分析,发现一次fullgc过程中,暂停时间并不长
例如下面的fullgc,暂停时长为
- 初始标记CMS-initial-mark:0.05s
- 重新标记CMS Final Remark:0.29s
2022-11-22T09:11:30.438+0800: 344102.892: [GC (Allocation Failure) 2022-11-22T09:11:30.440+0800: 344102.894: [ParNew: 1376182K->153600K(1382400K), 0.2052663 secs] 3454603K->2289
346K(4040704K), 0.2088212 secs] [Times: user=0.56 sys=0.01, real=0.21 secs]
2022-11-22T09:11:30.662+0800: 344103.116: [GC (CMS Initial Mark) [1 CMS-initial-mark: 2135746K(2658304K)] 2310318K(4040704K), 0.0489591 secs] [Times: user=0.13 sys=0.01, real=0.
05 secs]
2022-11-22T09:11:30.716+0800: 344103.170: [CMS-concurrent-mark-start]
2022-11-22T09:11:31.347+0800: 344103.801: [CMS-concurrent-mark: 0.631/0.631 secs] [Times: user=1.29 sys=0.03, real=0.64 secs]
2022-11-22T09:11:31.351+0800: 344103.805: [CMS-concurrent-preclean-start]
2022-11-22T09:11:31.366+0800: 344103.819: [CMS-concurrent-preclean: 0.014/0.015 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
2022-11-22T09:11:31.369+0800: 344103.823: [CMS-concurrent-abortable-preclean-start]
2022-11-22T09:11:31.533+0800: 344103.987: [GC (Allocation Failure) 2022-11-22T09:11:31.535+0800: 344103.989: [ParNew: 1382400K->153600K(1382400K), 0.2068298 secs] 3518146K->2345
666K(4040704K), 0.2097398 secs] [Times: user=0.58 sys=0.01, real=0.21 secs]
2022-11-22T09:11:32.654+0800: 344105.108: [CMS-concurrent-abortable-preclean: 1.058/1.285 secs] [Times: user=2.70 sys=0.04, real=1.28 secs]
2022-11-22T09:11:32.667+0800: 344105.121: [GC (CMS Final Remark) [YG occupancy: 1345792 K (1382400 K)]2022-11-22T09:11:32.668+0800: 344105.122: [Rescan (parallel) , 0.1862920 se
cs]2022-11-22T09:11:32.854+0800: 344105.308: [weak refs processing, 0.0001122 secs]2022-11-22T09:11:32.854+0800: 344105.308: [class unloading, 0.0624232 secs]2022-11-22T09:11:32
.917+0800: 344105.371: [scrub symbol table, 0.0319926 secs]2022-11-22T09:11:32.949+0800: 344105.403: [scrub string table, 0.0032403 secs][1 CMS-remark: 2192066K(2658304K)] 35378
59K(4040704K), 0.2851247 secs] [Times: user=0.65 sys=0.01, real=0.29 secs]
2022-11-22T09:11:32.958+0800: 344105.412: [CMS-concurrent-sweep-start]
2022-11-22T09:11:33.030+0800: 344105.483: [GC (Allocation Failure) 2022-11-22T09:11:33.031+0800: 344105.485: [ParNew: 1382400K->120109K(1382400K), 0.1535558 secs] 3550502K->2343
198K(4040704K), 0.1567270 secs] [Times: user=0.42 sys=0.01, real=0.15 secs]
2022-11-22T09:11:34.931+0800: 344107.384: [CMS-concurrent-sweep: 1.771/1.972 secs] [Times: user=3.94 sys=0.06, real=1.98 secs]
2022-11-22T09:11:34.933+0800: 344107.387: [CMS-concurrent-reset-start]
2022-11-22T09:11:34.942+0800: 344107.396: [CMS-concurrent-reset: 0.009/0.009 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
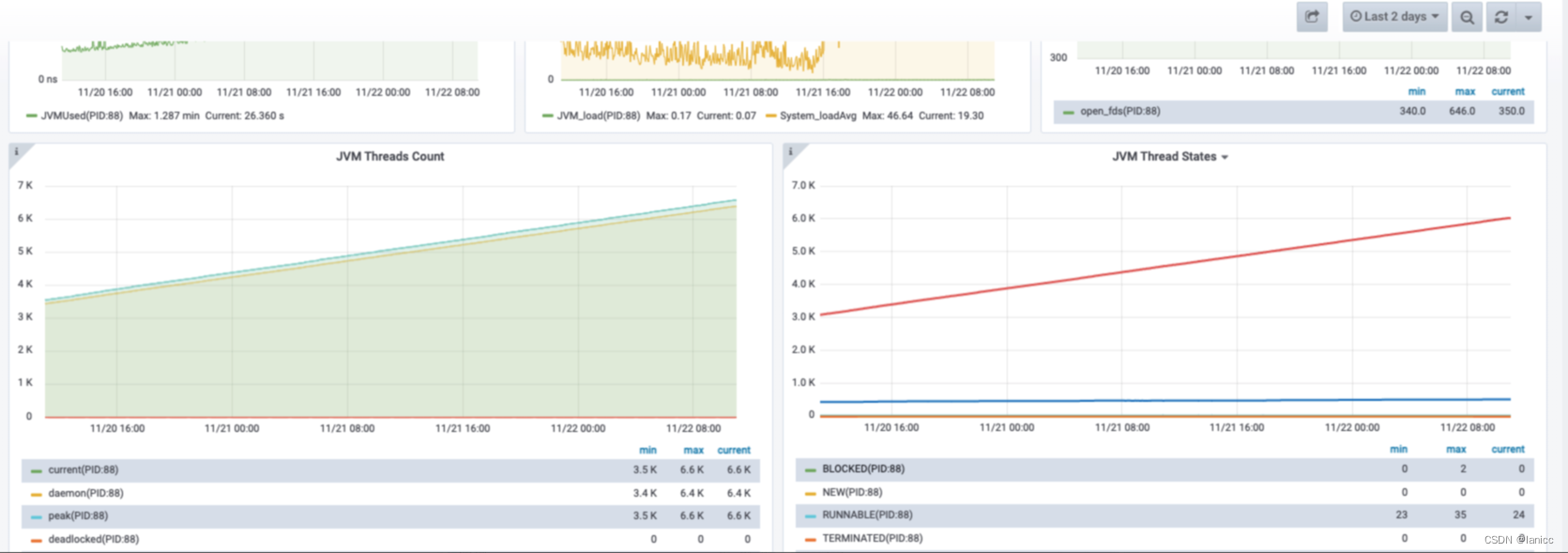
Thread监控—线程数持续增长
另一个同学注意到线程监控异常,发现线程数持续增长,处于TIMED_WATING状态的线程也持续增长,
初步怀疑是线程对象较多,且状态处于长时间的TIMED_WATING,所以younggc无法回收,进入老年代,引起频繁fullgc
执行jstack—分析线程
线上执行jstack
使用工具IBM Thread and Monitor Dump Analyzer for Java (TMDA)对stack日志进行分析
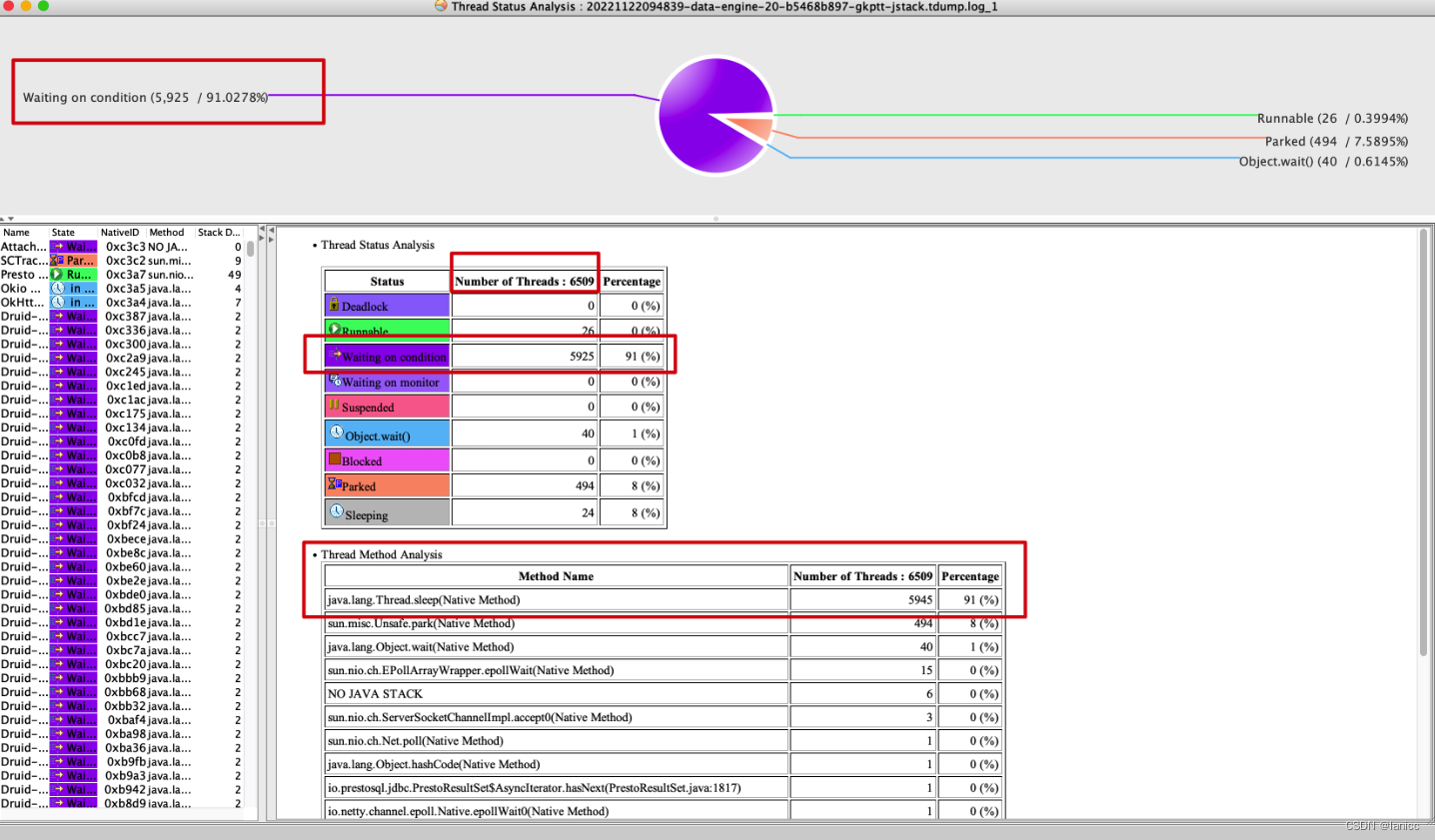
线程状态分析
发现
- 线程总数多,6k+
- 91%的线程在等待,Wating on condition,看堆栈,是调用了Thread.sleep
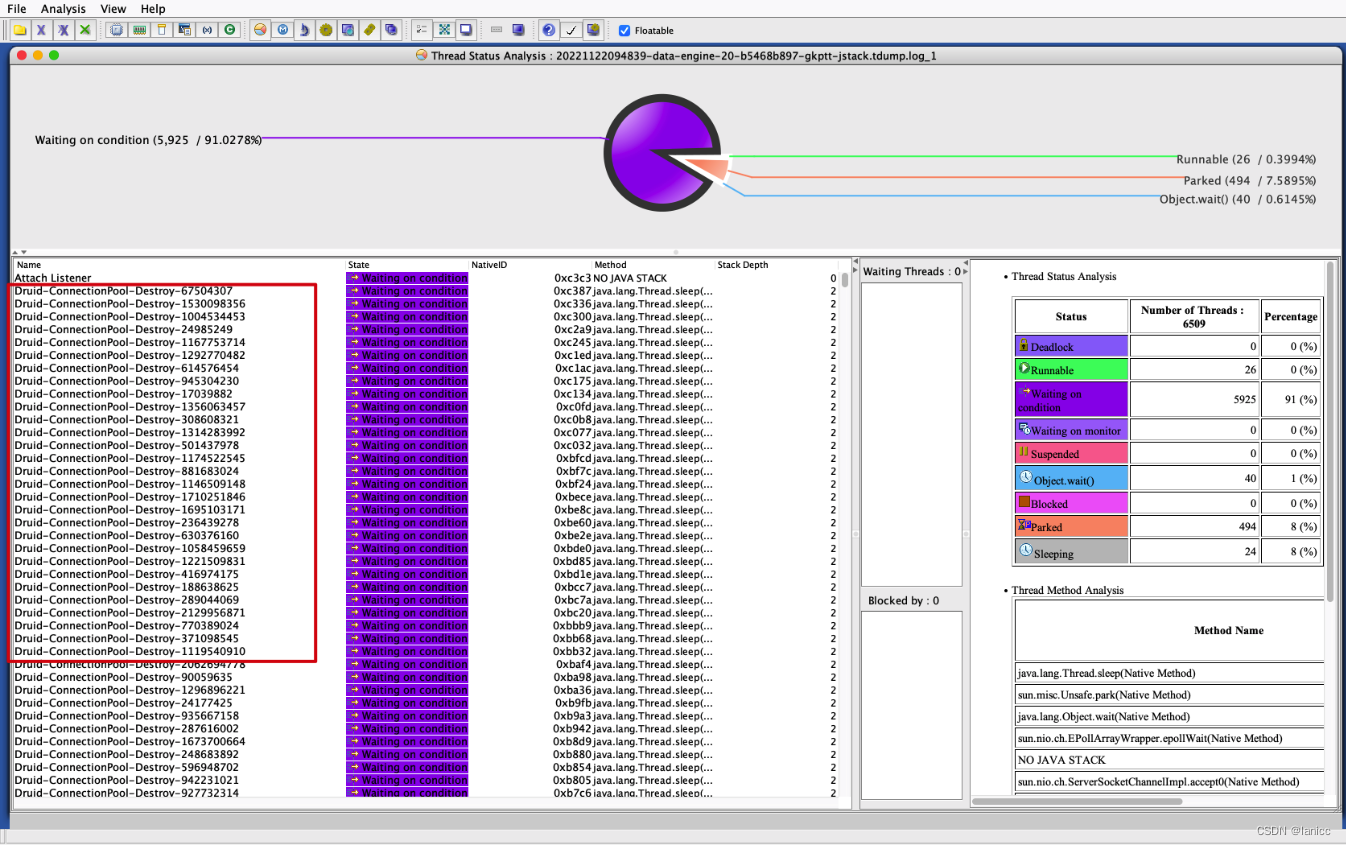
Waiting on condition线程分析
查看状态为Waiting on condition状态的线程,发现几乎都是Druid-ConnectionPool-Destory-xxxx
线程堆栈信息

分析Druid-ConnectionPool-Destory线程
DruidDataSource.init()
->createAndStartDestroyThread()
相关代码如下
String threadName = "Druid-ConnectionPool-Destroy-" + System.identityHashCode(this);
destroyConnectionThread = new DestroyConnectionThread(threadName);
destroyConnectionThread.start();
也就是说,一个DruidDataSource连接池,对应一个Druid-ConnectionPool-Destroy线程
上面的6k左右个Druid-ConnectionPool-Destroy线程,对应了6k左右的DruidDataSource连接池🥶
所以,究竟是哪里创建了这么多连接池?
哪里创建了这么多连接池?
这个应用是bi系统中的数据查询引擎,维护了很多库,约500个,但现在有6k左右的数据库连接池肯定是不对劲的。
后来经过排查,是有个定时检查内存中的连接池与数据库中维护的数据源信息差异的任务,在不断的创建连接池,在某个分支条件下,创建了连接池后,发生异常,但没有及时关闭连接池,导致在后续的定时任务调度中,不断的创建连接池。
结论与方案
关于连接池
对于连接池的维护,部分代码需要优化,尤其是在发生异常时,没有及时关闭连接池。这也是本次告警的主要原因
关于gc
从上面的排查来看gc频繁的问题,应该就是因为数据库连接池频繁创建,没有及时关闭造成的。
但gc日志分析来看gc暂停时间并不长,只是gc整个过程较长
●新生代的s区基本处于满状态,fullgc频繁,但没有内存泄露的现象,很明显是内存不足
●抽取一次fullgc日志分析,发现gc暂停时间不长,是运维告警的问题
若有收获,就点个赞吧







![19.[Python GUI] PyQt5中的模型与视图框架-基本原理](https://img-blog.csdnimg.cn/img_convert/0b43def892892ebae81ce7855ce1a6b9.png)