文章目录
- 提升group by的效率
- 分页查询优化
- 覆盖索引+子查询
- 起始位置重定义
- 检查 where,order by,group by后面的列
- 尽量使用 varchar 代替 char。(SQL 性能优化)
- 如果修改 / 更新数据过多,考虑批量进行
提升group by的效率
select user_id,user_name from order
group by user_id
having user_id <= 200;
分组是一个相对耗时的操作,为什么我们不先缩小数据的范围之后,再分组呢?
select user_id,user_name from order
where user_id <= 200
group by user_id
分页查询优化
覆盖索引+子查询
[SQL]
SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id >= (select id from emp order by id limit 100,1)
order by a.id limit 25;
受影响的行: 0
时间: 0.106s
[SQL]
SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id >= (select id from emp order by id limit 4800000,1)
order by a.id limit 25;
受影响的行: 0
时间: 1.541s
起始位置重定义
[SQL]
SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id > 100 order by a.id limit 25;
受影响的行: 0
时间: 0.001s
[SQL]
SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
from emp a left join dep b on a.depno = b.depno
where a.id > 4800000 # 从4800000 开始
order by a.id limit 25;
受影响的行: 0
时间: 0.000s
检查 where,order by,group by后面的列
多表关联的列
是否已加索引,优先考虑组合索引
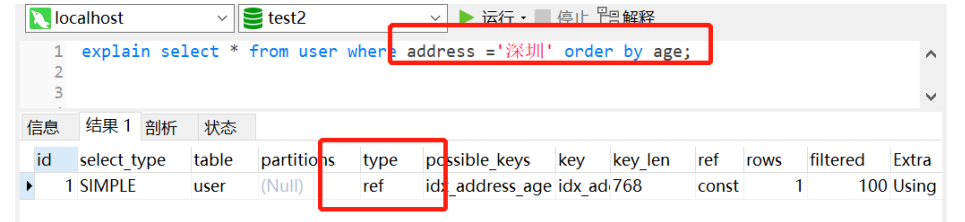
# 添加索引
alter table user add index idx_address_age (address,age);
尽量使用 varchar 代替 char。(SQL 性能优化)
「反例:」
`deptName` char(100) DEFAULT NULL COMMENT '部门名称'
「正例:」
`deptName` varchar(100) DEFAULT NULL COMMENT '部门名称'
理由:
- 因为首先
变长字段存储空间小,可以节省存储空间 - 其次对于查询来说,在一个
相对较小的字段内搜索,效率更高
如果修改 / 更新数据过多,考虑批量进行
反例:
delete from account limit 100000;
正例:
for each(200 次)
{
delete from account limit 500;
}
理由:
- 大批量操作会会造成
主从延迟。 - 大批量操作会产生
大事务,阻塞。 - 大批量操作,数据量过大,会把
cpu 打满






![19.[Python GUI] PyQt5中的模型与视图框架-基本原理](https://img-blog.csdnimg.cn/img_convert/0b43def892892ebae81ce7855ce1a6b9.png)





![[附源码]计算机毕业设计JAVA教师档案管理系统](https://img-blog.csdnimg.cn/881f7fe23c1146089c069d94a18e7fdb.png)