- 一站式元数据治理平台——Datahub
- 万字保姆级长文——Linkedin元数据管理平台Datahub离线安装指南 - 独孤风 - 博客园 (cnblogs.com)
- 企业级数据治理工作怎么开展?Datahub这样做 - 独孤风 - 博客园 (cnblogs.com)
- 【DataHub】 现代数据栈的元数据平台–如何与spark集成,自动产生spark作业的数据血缘关系?_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台–如何删除元数据?_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台–如何处理同一平台类型的多个实例?_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台–如何配置DataHub作为Airflow的数据血缘后端存储,自动将工作流DAG写入DataHub作为数据血缘?_九层之台起于累土的博客-CSDN博客_datahub 血缘
- 【DataHub】 现代数据栈的元数据平台–如何从DataHub容器中提取日志?_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台–组件日志时间早8个小时,怎么办?_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台–如何使用数据领域Domain?_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台–如何针对DataHub UI 前端展示进行汉化_九层之台起于累土的博客-CSDN博客_前端汉化
- 【DataHub】 现代数据栈的元数据平台–如何快速验证所有组件容器都在正确的运行?_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台–如何监控DataHub_九层之台起于累土的博客-CSDN博客_datahub 使用
- 【DataHub】 现代数据栈的元数据平台–如何搭建本地开发环境_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台–如何添加自定义数据平台_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台–如何将数据血缘关系写入DataHub_九层之台起于累土的博客-CSDN博客_datahub 血缘
- 【DataHub】 现代数据栈的元数据平台–如何将自定义的元数据事件发送到DataHub_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台–如何针对元数据建模?_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台的Serving Architecture【服务体系架构】讲解_九层之台起于累土的博客-CSDN博客
- 【DataHub】 现代数据栈的元数据平台的入门体验及填坑记录_九层之台起于累土的博客-CSDN博客_datahub
随着数字化转型的工作推进,数据治理的工作已经被越来越多的公司提上了日程。作为新一代的元数据管理平台,Datahub在近一年的时间里发展迅猛,大有取代老牌元数据管理工具Atlas之势。国内Datahub的资料非常少,大部分公司想使用Datahub作为自己的元数据管理平台,但可参考的资料太少。
所以整理了这份文档供大家学习使用。 本文档基于Datahub最新的0.8.20版本,整理自部分官网内容,各种博客及实践过程。文章较长,建议收藏。
通过本文档,可以快速的入门Datahub,成功的搭建Datahub并且获取到数据库的元数据信息。是从0到1的入门文档,更多Datahub的高级功能,可以关注后续的文章更新。
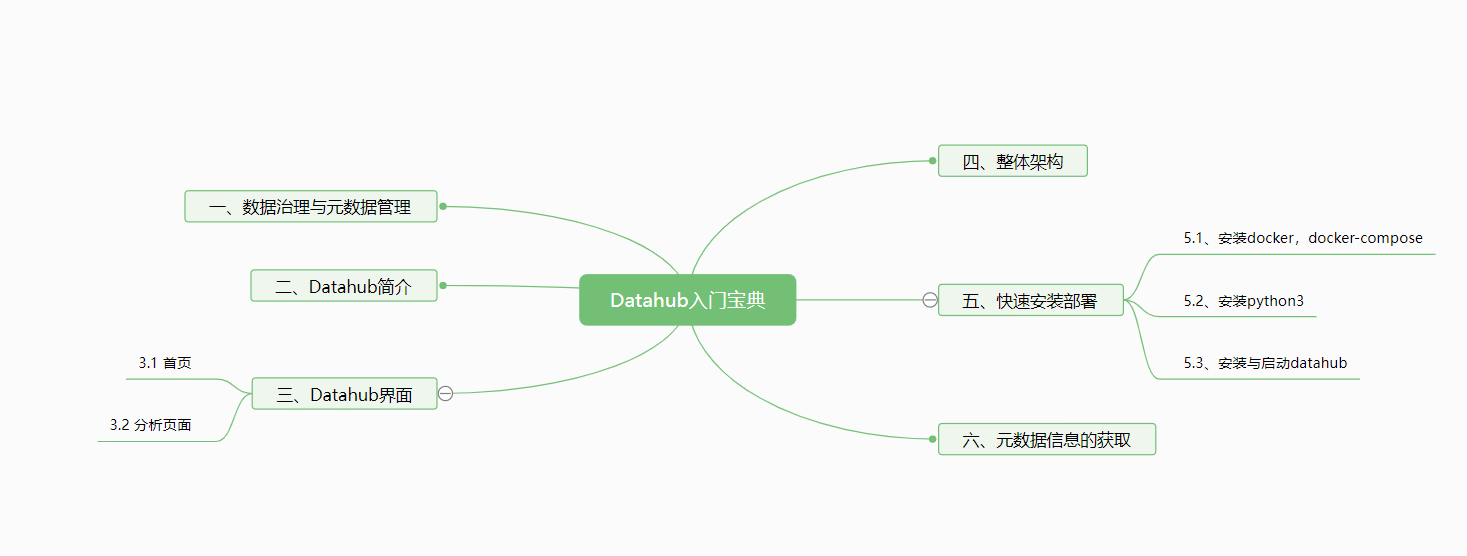
文档共分为6个部分,层级结构如下图所示。
一、数据治理与元数据管理
背景
为什么要做数据治理? 业务繁多,数据繁多,业务数据不断迭代。人员流动,文档不全,逻辑不清楚,对于数据很难直观理解,后期很难维护。
在大数据研发中,原始数据就有着非常多的数据库,数据表。
而经过数据的聚合以后,又会有很多的维度表。
近几年来数据的量级在疯狂的增长,由此带来了系列的问题。作为对人工智能团队的数据支撑,我们听到的最多的质疑是 “正确的数据集”,他们需要正确的数据用于他们的分析。我们开始意识到,虽然我们构建了高度可扩展的数据存储,实时计算等等能力,但是我们的团队仍然在浪费时间寻找合适的数据集来进行分析。
也就是我们缺乏对数据资产的管理。事实上,有很多公司都提供了开源的解决方案来解决上述问题,这也就是数据发现与元数据管理工具。
元数据管理
简单地说,元数据管理是为了对数据资产进行有效的组织。它使用元数据来帮助管理他们的数据。它还可以帮助数据专业人员收集、组织、访问和丰富元数据,以支持数据治理。
三十年前,数据资产可能是 Oracle 数据库中的一张表。然而,在现代企业中,我们拥有一系列令人眼花缭乱的不同类型的数据资产。可能是关系数据库或 NoSQL 存储中的表、实时流数据、 AI 系统中的功能、指标平台中的指标,数据可视化工具中的仪表板。
现代元数据管理应包含所有这些类型的数据资产,并使数据工作者能够更高效地使用这些资产完成工作。
所以,元数据管理应具备的功能如下:
- **搜索和发现:**数据表、字段、标签、使用信息
- **访问控制:**访问控制组、用户、策略
- **数据血缘:**管道执行、查询
- **合规性:**数据隐私/合规性注释类型的分类
- **数据管理:**数据源配置、摄取配置、保留配置、数据清除策略
- **AI 可解释性、再现性:**特征定义、模型定义、训练运行执行、问题陈述
- **数据操作:**管道执行、处理的数据分区、数据统计
- **数据质量:**数据质量规则定义、规则执行结果、数据统计
架构与开源方案
下面介绍元数据管理的架构实现,不同的架构都对应了不同的开源实现。
下图描述了第一代元数据架构。它通常是一个经典的单体前端(可能是一个 Flask 应用程序),连接到主要存储进行查询(通常是 MySQL/Postgres),一个用于提供搜索查询的搜索索引(通常是 Elasticsearch),并且对于这种架构的第 1.5 代,也许一旦达到关系数据库的“递归查询”限制,就使用了处理谱系(通常是 Neo4j)图形查询的图形索引。
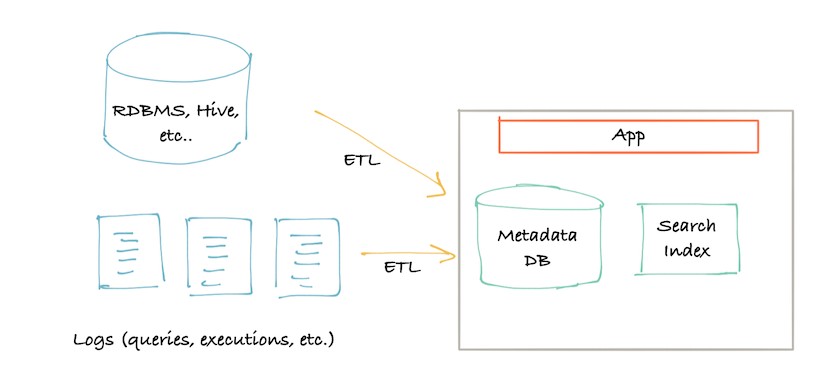
很快,第二代的架构出现了。单体应用程序已拆分为位于元数据存储数据库前面的服务。该服务提供了一个 API,允许使用推送机制将元数据写入系统。
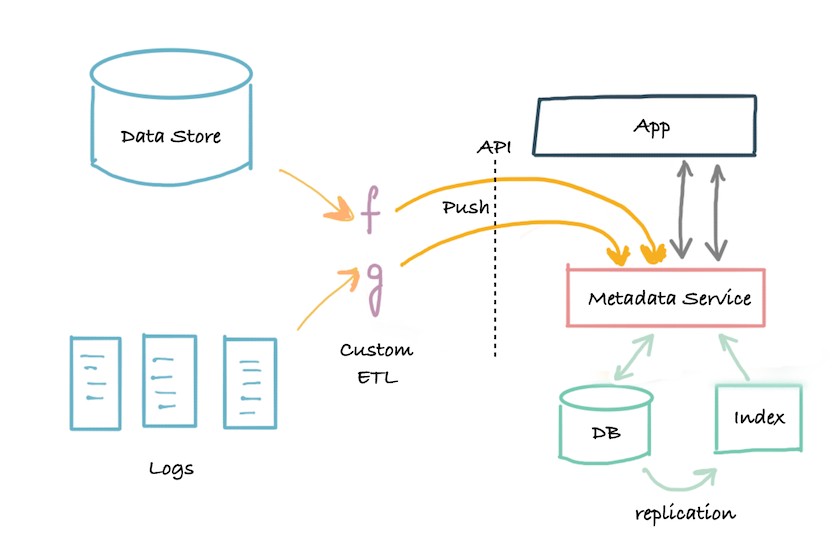
第三代架构是基于事件的元数据管理架构,客户可以根据他们的需要以不同的方式与元数据数据库交互。
元数据的低延迟查找、对元数据属性进行全文和排名搜索的能力、对元数据关系的图形查询以及全扫描和分析能力。
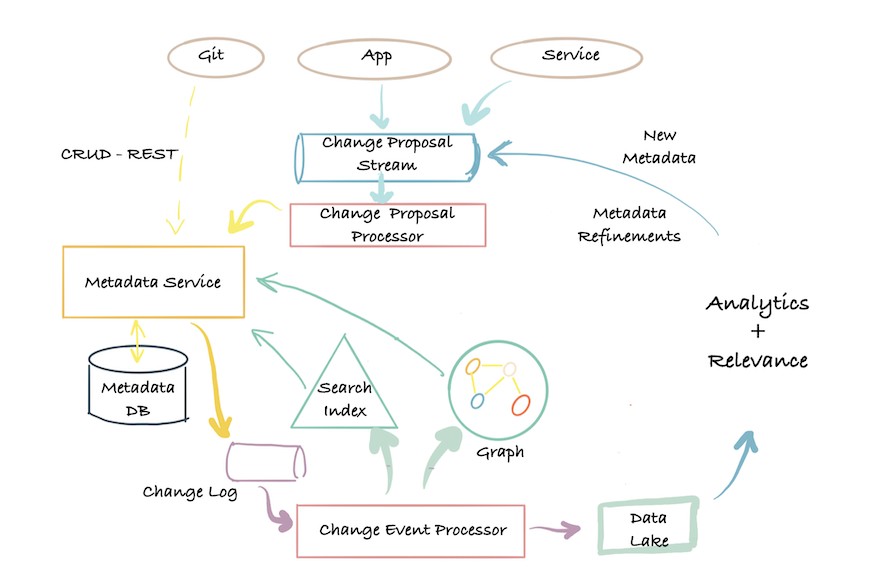
Datahub 就是采用的这种架构。
下图是当今元数据格局的简单直观表示:
(包含部分非开源方案)
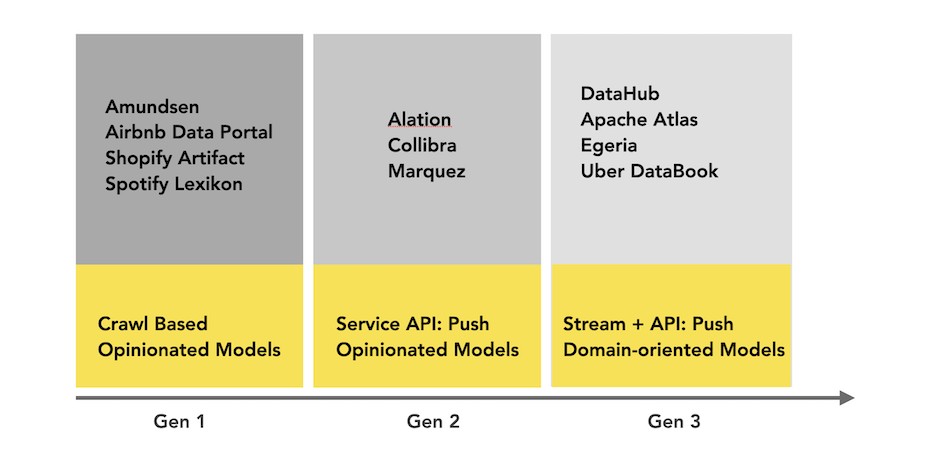
其他方案可作为调研的主要方向,但不是本文讨论的重点。
二、Datahub简介
首先,阿里云也有一款名为DataHub的产品,是一个流式处理平台,本文所述DataHub与其无关。
数据治理是大佬们最近谈的一个火热的话题。不管国家层面,还是企业层面现在对这个问题是越来越重视。数据治理要解决数据质量,数据管理,数据资产,数据安全等等。而数据治理的关键就在于元数据管理,我们要知道数据的来龙去脉,才能对数据进行全方位的管理,监控,洞察。
DataHub是由LinkedIn的数据团队开源的一款提供元数据搜索与发现的工具。
提到LinkedIn,不得不想到大名鼎鼎的Kafka,Kafka就是LinkedIn开源的。LinkedIn开源的Kafka直接影响了整个实时计算领域的发展,而LinkedIn的数据团队也一直在探索数据治理的问题,不断努力扩展其基础架构,以满足不断增长的大数据生态系统的需求。随着数据的数量和丰富性的增长,数据科学家和工程师要发现可用的数据资产,了解其出处并根据见解采取适当的行动变得越来越具有挑战性。为了帮助增长的同时继续扩大生产力和数据创新,创建了通用的元数据搜索和发现工具DataHub。
市面上常见的元数据管理系统有如下几个:
a) linkedin datahub:
https://github.com/linkedin/datahub
b) apache atlas:
https://github.com/apache/atlas
c) lyft amundsen
https://github.com/lyft/amundsen
atlas之前我们也介绍过,对hive有非常好的支持,但是部署起来非常的吃力。amundsen还是一个新兴的框架,还没有release版本,未来可能会发展起来还需要慢慢观察。
综上,datahub是目前的一颗新星,只是目前datahub的资料还较少,未来我们将持续关注与更新datahub的更多资讯。
目前datahub的github星数已经达到4.3k。
Datahub官网
Datahub官网对于其描述为Data ecosystems are diverse — too diverse. DataHub’s extensible metadata platform enables data discovery, data observability and federated governance that helps you tame this complexity.
数据生态是多样的,而 DataHub提供了可扩展的元数据管理平台,可以满足数据发现,数据可观察与治理。这也极大的解决了数据复杂性的问题。
Datahub提供了丰富的数据源支持与血缘展示。
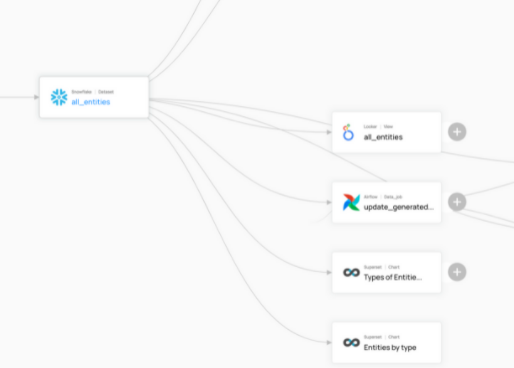
在获取数据源的时候,只需要编写简单的yml文件就可以完成元数据的获取。
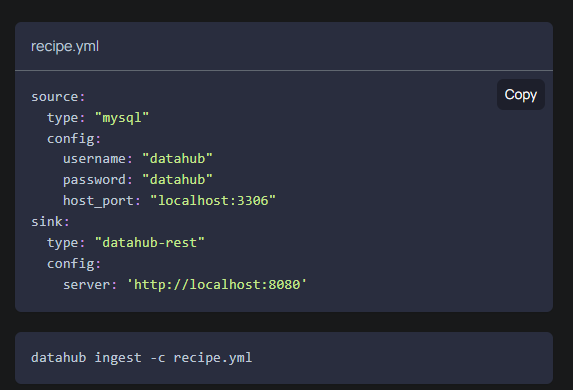
在数据源的支持方面,Datahub支持druid,hive,kafka,mysql,oracle,postgres,redash,metabase,superset等数据源,并支持通过airflow的数据血缘获取。可以说实现了从数据源到BI工具的全链路的数据血缘打通。
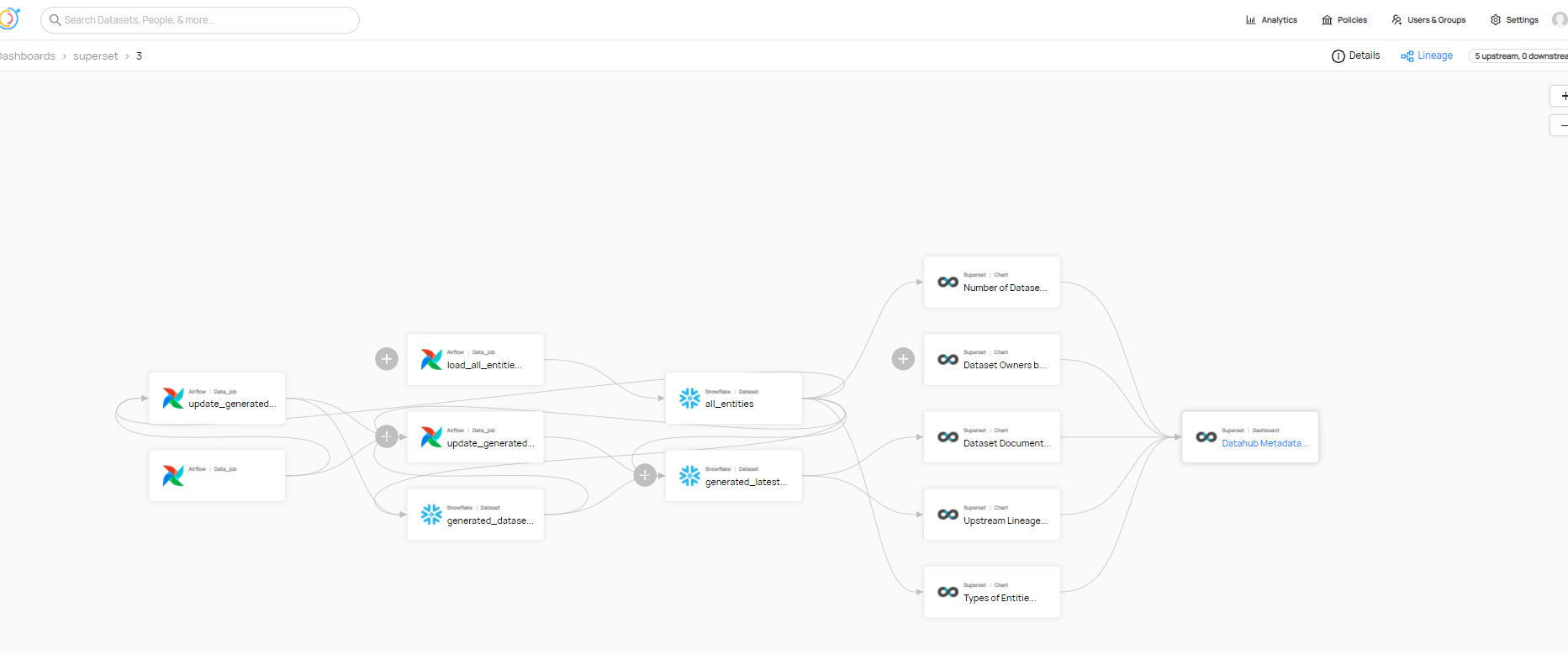
三、Datahub界面
通过Datahub的页面我们来简单了解下Datahub所能满足的功能。
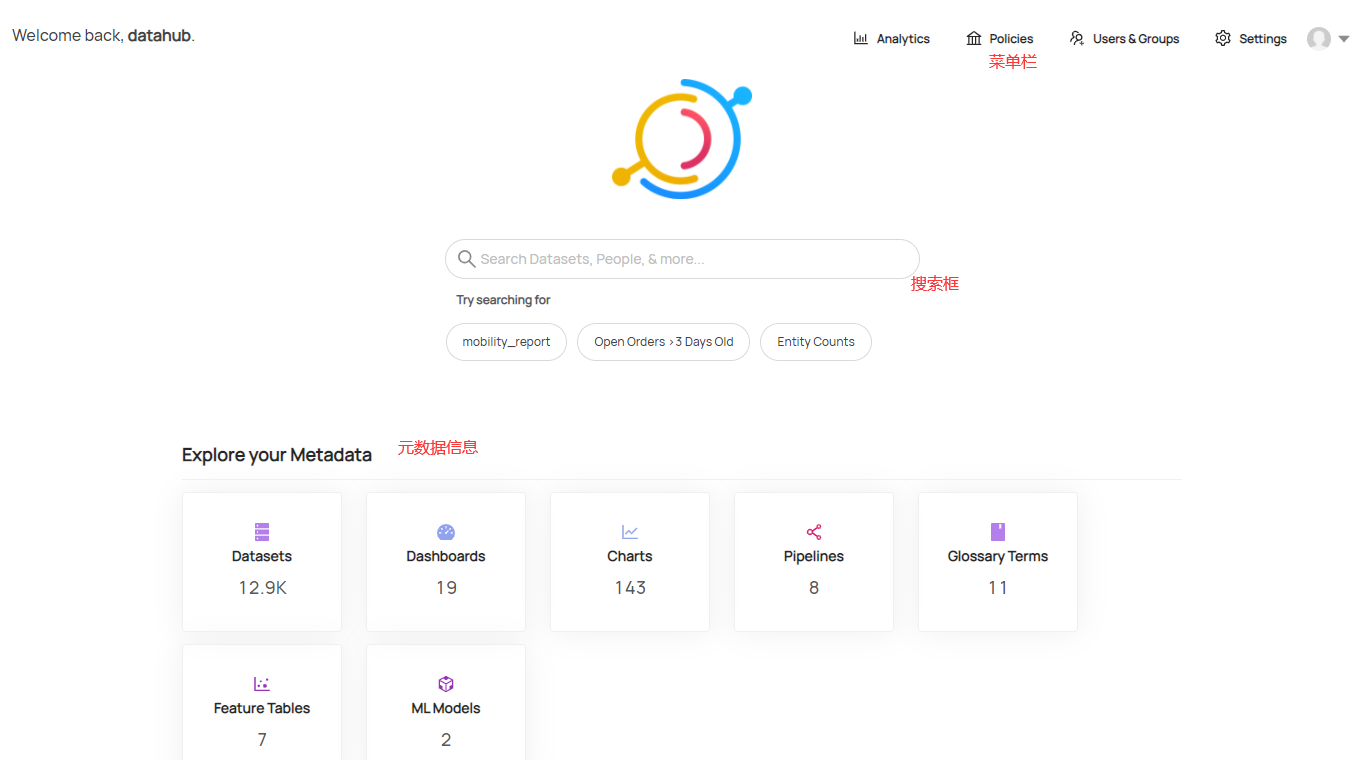
3.1 首页
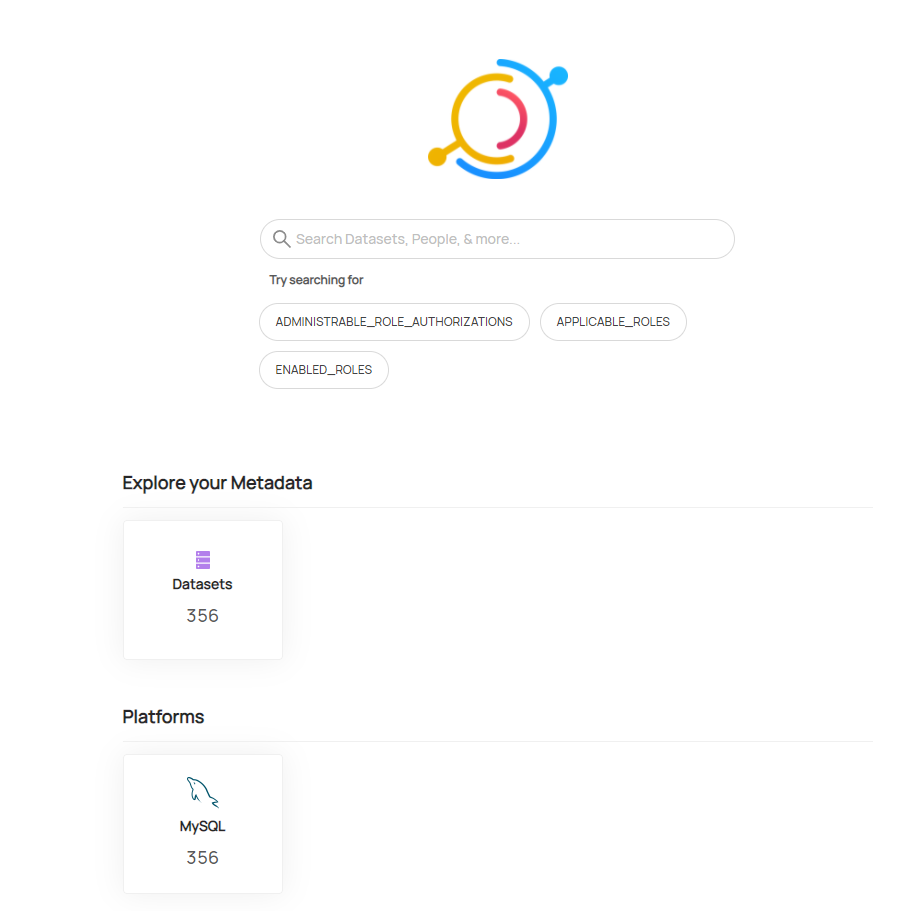
首先,在登录到Datahub以后就进入了Datahub首页,首页中提供了Datahub的菜单栏,搜索框和元数据信息列表。这是为了让大家可以快速的对元数据进行管理。
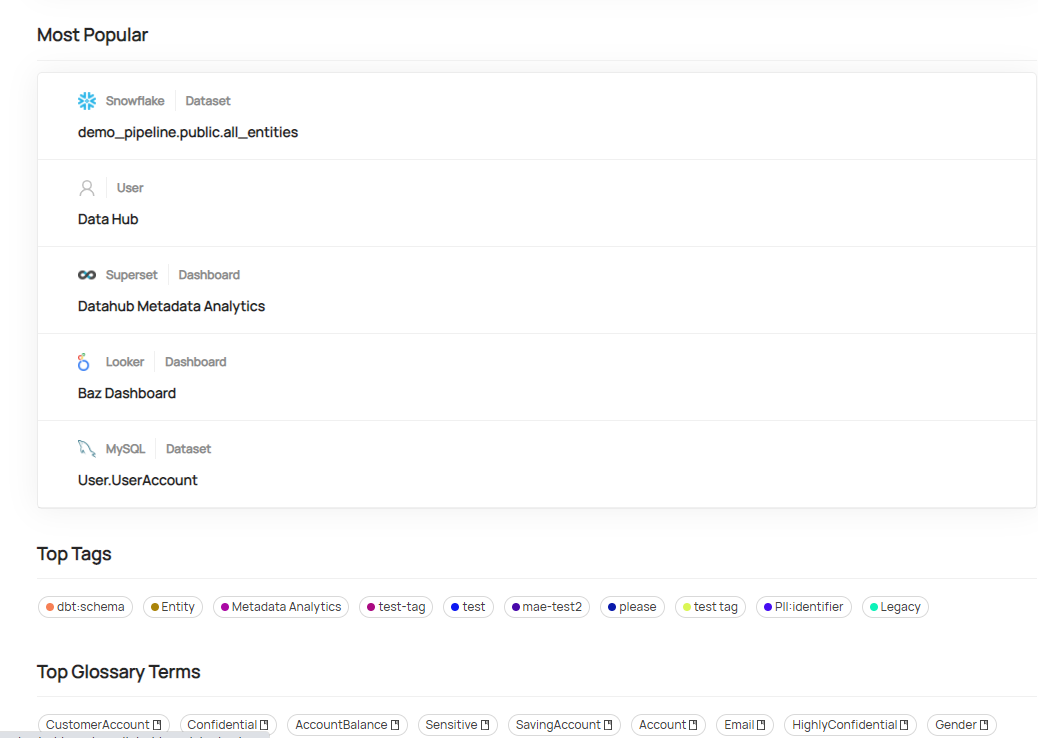
元数据信息中按照数据集,仪表板,图表等类型进行了分类。
再往下看是平台信息,在这当中包括了Hive,Kafka,Airflow等平台信息的收集。

下面其实是一些搜索的统计信息。用于统计最近以及最流行的搜索结果。
包括一些标签和术语表信息。
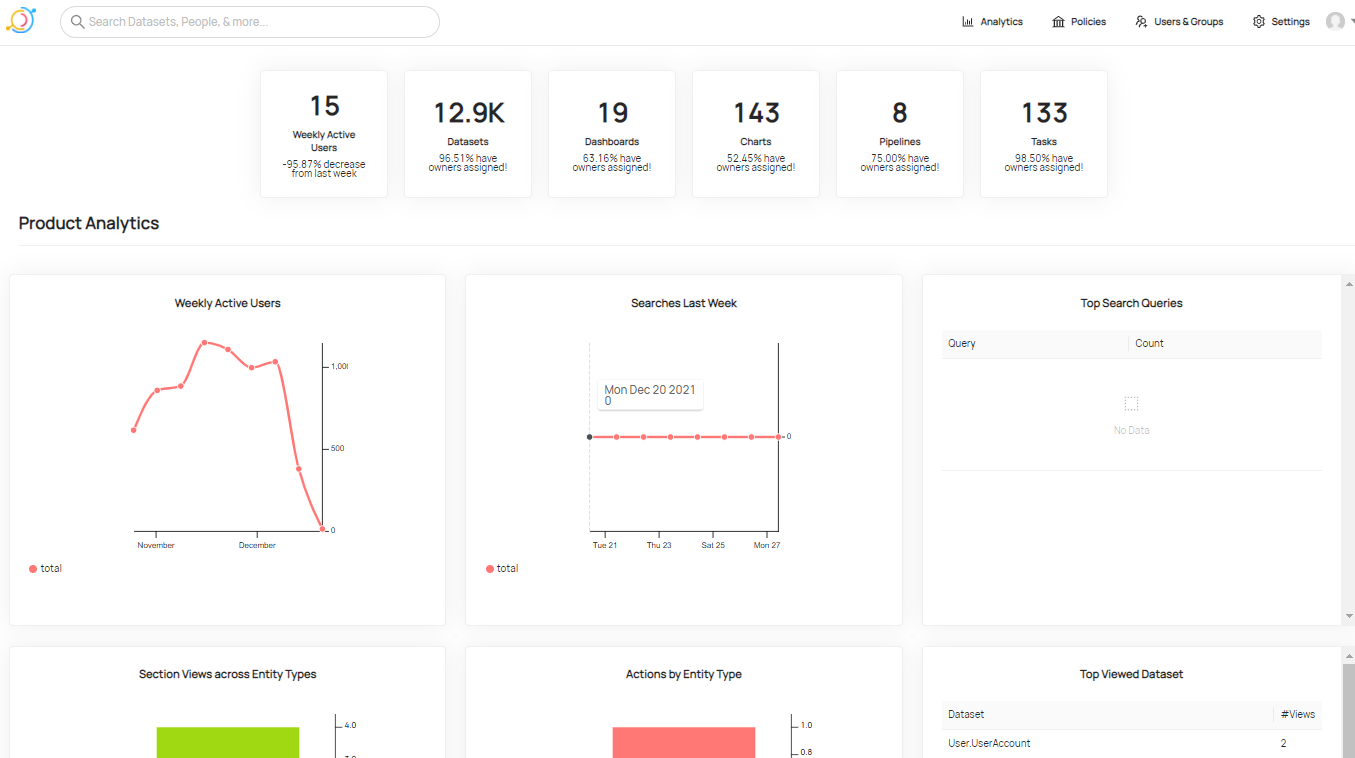
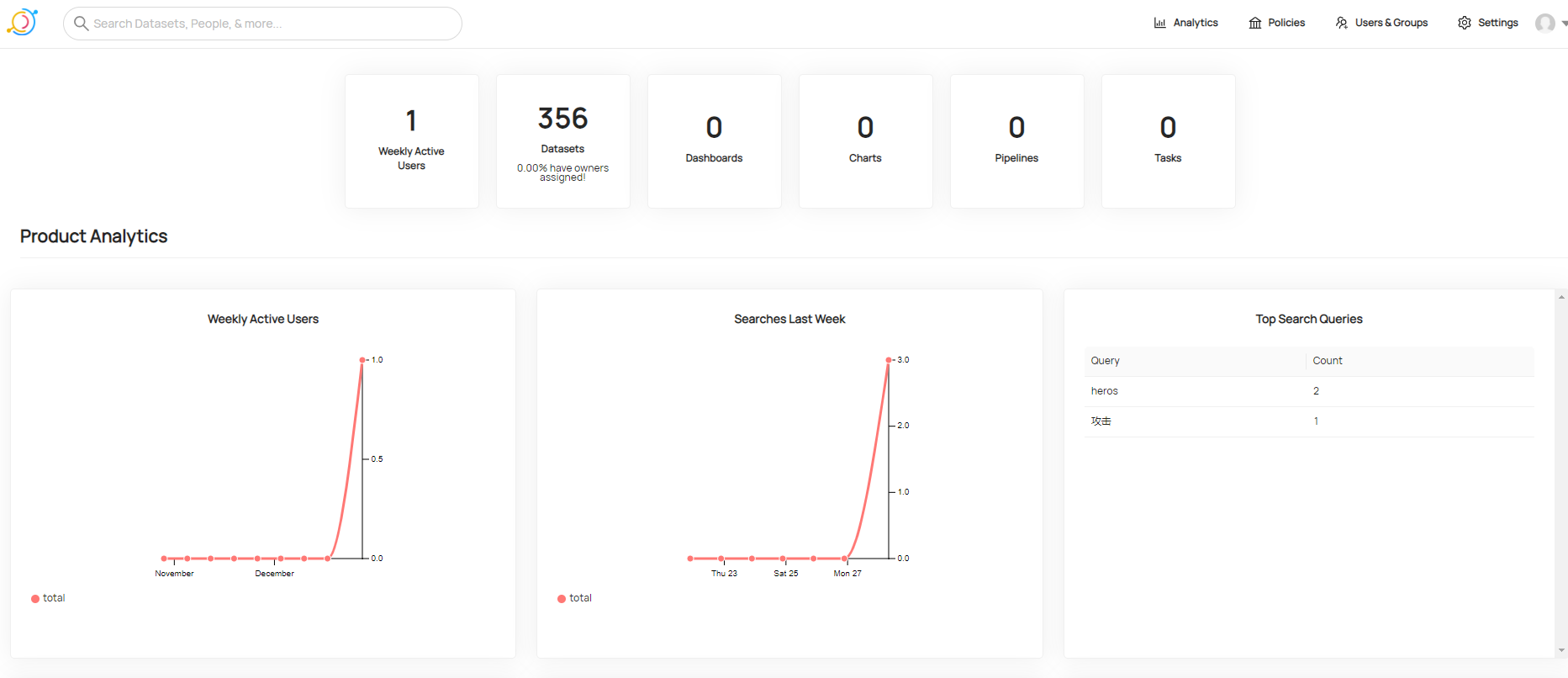
3.2 分析页面
分析页面是对元数据信息的统计,也是对使用datahub的用户信息的统计。
可以理解为一个展示页面,这对于总体情况的了解还是非常的有必要的。
其他的功能基本是对于用户和权限的控制。
四、整体架构
要想学习好Datahub,就必须了解Datahub的整体架构。
通过Datahub的架构图可以清晰的了解Datahub的架构组成。

DataHub 的架构有三个主要部分。
前端为 Datahub frontend作为前端的页面展示。
丰富的前端展示让Datahub 拥有了支撑大多数功能的能力。其前端基于React框架研发,对于有二次研发打算的公司,要注意此技术栈的匹配性。
后端 Datahub serving来提供后端的存储服务。
Datahub 的后端开发语言为Python,存储基于ES或者Neo4J。
而Datahub ingestion则用于抽取元数据信息。
Datahub 提供了基于API元数据主动拉取方式,和基于Kafka的实时元数据获取方式。这对于元数据的获取非常的灵活。
这三部分也是我们部署过程中主要关注的点,下面我们就从零开始部署Datahub,并获取一个数据库的元数据信息。
五、快速安装部署
部署datahub对于系统有一定的要求。本文基于CentOS7进行安装。
要先安装好 docker,jq,docker-compose。同时保证系统的python版本为 Python 3.6+。
5.1、安装docker,docker-compose,jq
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux或Windows操作系统的机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。
可以通过yum的方式快速的安装docker
yum -y install docker
完成后通过docker -v来查看版本情况。
# docker -v
Docker version 1.13.1, build 7d71120/1.13.1
通过下面的命令可以启停docker
systemctl start docker // 启动docker
systemctl stop docker // 关闭docker
随后安装Docker Compose
Docker Compose是 docker 提供的一个命令行工具,用来定义和运行由多个容器组成的应用。使用 compose,我们可以通过 YAML 文件声明式的定义应用程序的各个服务,并由单个命令完成应用的创建和启动。
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
修改执行权限
sudo chmod +x /usr/local/bin/docker-compose
建立软连接
ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
查看版本,验证安装成功。
docker-compose --version
docker-compose version 1.29.2, build 5becea4c
安装jq
首先安装EPEL源,企业版 Linux 附加软件包(以下简称 EPEL)是一个 Fedora 特别兴趣小组,用以创建、维护以及管理针对企业版 Linux 的一个高质量附加软件包集,面向的对象包括但不限于 红帽企业版 Linux (RHEL)、 CentOS、Scientific Linux (SL)、Oracle Linux (OL) 。
EPEL 的软件包通常不会与企业版 Linux 官方源中的软件包发生冲突,或者互相替换文件。EPEL 项目与 Fedora 基本一致,包含完整的构建系统、升级管理器、镜像管理器等等。
安装EPEL源
yum install epel-release
安装完EPEL源后,可以查看下jq包是否存在:
yum list jq
安装jq:
yum install jq
5.2、安装python3
安装依赖
yum -y groupinstall "Development tools"
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libffi-devel
下载安装包
wget https://www.python.org/ftp/python/3.8.3/Python-3.8.3.tgz
tar -zxvf Python-3.8.3.tgz
编译安装
mkdir /usr/local/python3
cd Python-3.8.3
./configure --prefix=/usr/local/python3
make && make install
修改系统默认python指向
rm -rf /usr/bin/python
ln -s /usr/local/python3/bin/python3 /usr/bin/python
修改系统默认pip指向
rm -rf /usr/bin/pip
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip
验证
python -V
修复yum
python3会导致yum不能正常使用
vi /usr/bin/yum
把 #! /usr/bin/python 修改为 #! /usr/bin/python2
vi /usr/libexec/urlgrabber-ext-down
把 #! /usr/bin/python 修改为 #! /usr/bin/python2
vi /usr/bin/yum-config-manager
#!/usr/bin/python 改为 #!/usr/bin/python2
没有的不用修改
5.3、安装与启动datahub
首先升级pip
python3 -m pip install --upgrade pip wheel setuptools
需要看到下面成功的返回。
Attempting uninstall: setuptools
Found existing installation: setuptools 57.4.0
Uninstalling setuptools-57.4.0:
Successfully uninstalled setuptools-57.4.0
Attempting uninstall: pip
Found existing installation: pip 21.2.3
Uninstalling pip-21.2.3:
Successfully uninstalled pip-21.2.3
检查环境
python3 -m pip uninstall datahub acryl-datahub || true # sanity check - ok if it fails
收到这样的提示说明没有问题。
WARNING: Skipping datahub as it is not installed.
WARNING: Skipping acryl-datahub as it is not installed.
安装datahub,此步骤时间较长,耐心等待。
python3 -m pip install --upgrade acryl-datahub
收到这样的提示说明安装成功。
Successfully installed PyYAML-6.0 acryl-datahub-0.8.20.0 avro-1.11.0 avro-gen3-0.7.1 backports.zoneinfo-0.2.1 certifi-2021.10.8 charset-normalizer-2.0.9 click-8.0.3 click-default-group-1.2.2 docker-5.0.3 entrypoints-0.3 expandvars-0.7.0 idna-3.3 mypy-extensions-0.4.3 progressbar2-3.55.0 pydantic-1.8.2 python-dateutil-2.8.2 python-utils-2.6.3 pytz-2021.3 pytz-deprecation-shim-0.1.0.post0 requests-2.26.0 stackprinter-0.2.5 tabulate-0.8.9 toml-0.10.2 typing-extensions-3.10.0.2 typing-inspect-0.7.1 tzdata-2021.5 tzlocal-4.1 urllib3-1.26.7 websocket-client-1.2.3
最后我们看到datahub的版本情况。
[root@node01 bin]# python3 -m datahub version
DataHub CLI version: 0.8.20.0
Python version: 3.8.3 (default, Aug 10 2021, 14:25:56)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)]
随后启动datahub
python3 -m datahub docker quickstart
会经过漫长的下载过程,耐心等待。
开始启动,注意观察报错情况。如果网速不好,需要多执行几次。
如果可以看到如下显示,证明安装成功了。

访问ip:9002 输入 datahub datahub 登录
六、元数据信息的获取
登录到Datahub以后,会有一个友好的welcome页面。来提示如何进行元数据的抓取。
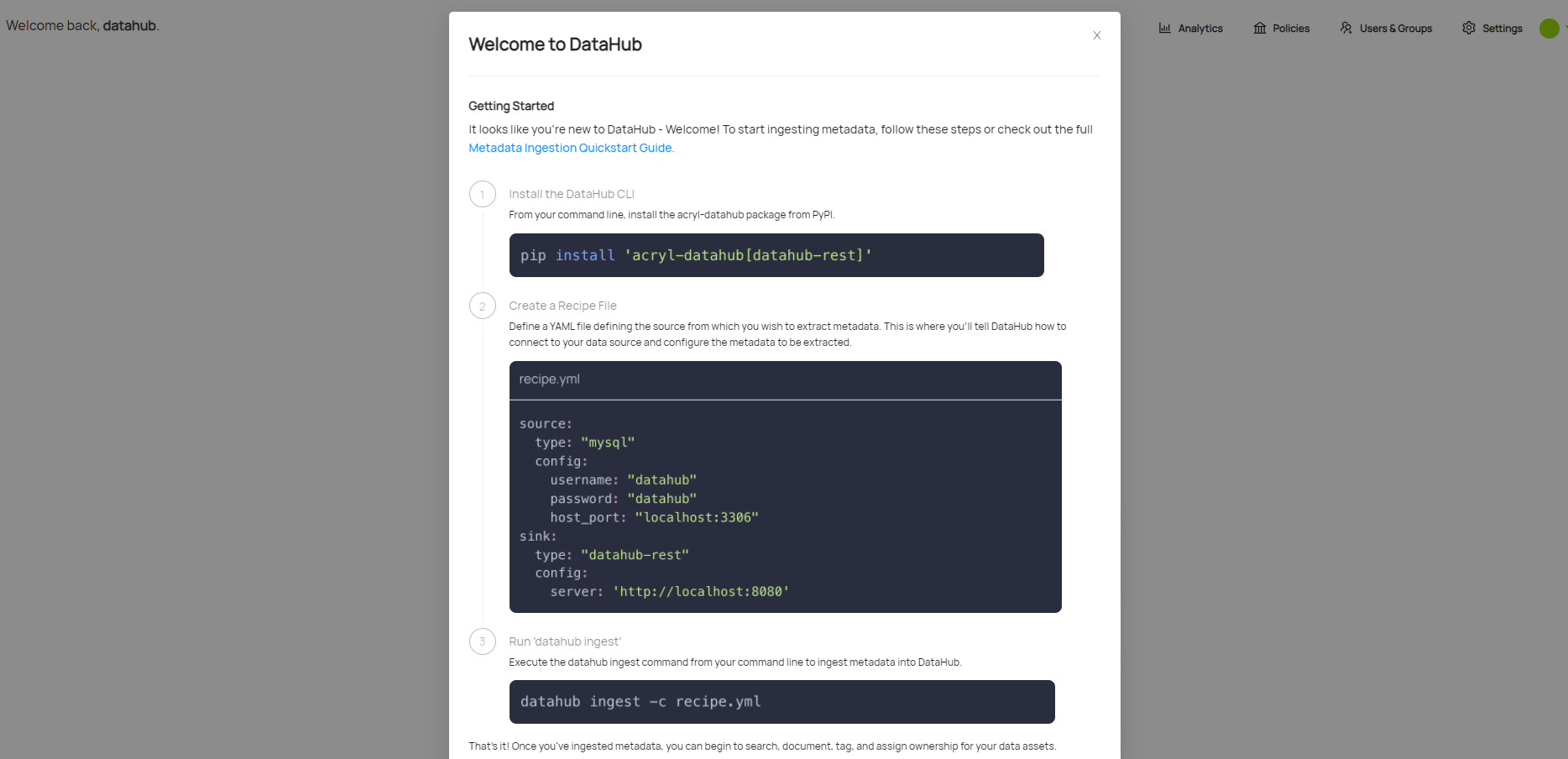
元数据摄入使用的是插件架构,你仅需要安装所需的插件。
摄入源有很多
插件名称 安装命令 提供功能
mysql pip install 'acryl-datahub[mysql]' MySQL source
这里安装两个插件:
源:mysql
汇:datahub-rest
pip install 'acryl-datahub[mysql]'
安装的包较多,得到如下提示证明安装成功。
Installing collected packages: zipp, traitlets, pyrsistent, importlib-resources, attrs, wcwidth, tornado, pyzmq, pyparsing, pycparser, ptyprocess, parso, nest-asyncio, jupyter-core, jsonschema, ipython-genutils, webencodings, pygments, prompt-toolkit, pickleshare, pexpect, packaging, nbformat, matplotlib-inline, MarkupSafe, jupyter-client, jedi, decorator, cffi, backcall, testpath, pandocfilters, nbclient, mistune, jupyterlab-pygments, jinja2, ipython, defusedxml, debugpy, bleach, argon2-cffi-bindings, terminado, Send2Trash, prometheus-client, nbconvert, ipykernel, argon2-cffi, numpy, notebook, widgetsnbextension, toolz, ruamel.yaml.clib, pandas, jupyterlab-widgets, jsonpointer, tqdm, termcolor, scipy, ruamel.yaml, jsonpatch, ipywidgets, importlib-metadata, altair, sqlalchemy, pymysql, greenlet, great-expectations
Successfully installed MarkupSafe-2.0.1 Send2Trash-1.8.0 altair-4.1.0 argon2-cffi-21.3.0 argon2-cffi-bindings-21.2.0 attrs-21.3.0 backcall-0.2.0 bleach-4.1.0 cffi-1.15.0 debugpy-1.5.1 decorator-5.1.0 defusedxml-0.7.1 great-expectations-0.13.49 greenlet-1.1.2 importlib-metadata-4.10.0 importlib-resources-5.4.0 ipykernel-6.6.0 ipython-7.30.1 ipython-genutils-0.2.0 ipywidgets-7.6.5 jedi-0.18.1 jinja2-3.0.3 jsonpatch-1.32 jsonpointer-2.2 jsonschema-4.3.2 jupyter-client-7.1.0 jupyter-core-4.9.1 jupyterlab-pygments-0.1.2 jupyterlab-widgets-1.0.2 matplotlib-inline-0.1.3 mistune-0.8.4 nbclient-0.5.9 nbconvert-6.3.0 nbformat-5.1.3 nest-asyncio-1.5.4 notebook-6.4.6 numpy-1.21.5 packaging-21.3 pandas-1.3.5 pandocfilters-1.5.0 parso-0.8.3 pexpect-4.8.0 pickleshare-0.7.5 prometheus-client-0.12.0 prompt-toolkit-3.0.24 ptyprocess-0.7.0 pycparser-2.21 pygments-2.10.0 pymysql-1.0.2 pyparsing-2.4.7 pyrsistent-0.18.0 pyzmq-22.3.0 ruamel.yaml-0.17.19 ruamel.yaml.clib-0.2.6 scipy-1.7.3 sqlalchemy-1.3.24 termcolor-1.1.0 terminado-0.12.1 testpath-0.5.0 toolz-0.11.2 tornado-6.1 tqdm-4.62.3 traitlets-5.1.1 wcwidth-0.2.5 webencodings-0.5.1 widgetsnbextension-3.5.2 zipp-3.6.0
随后检查安装的插件情况,Datahub是插件式的安装方式。可以检查数据源获取插件Source,转换插件transformer,获取插件Sink。
python3 -m datahub check plugins
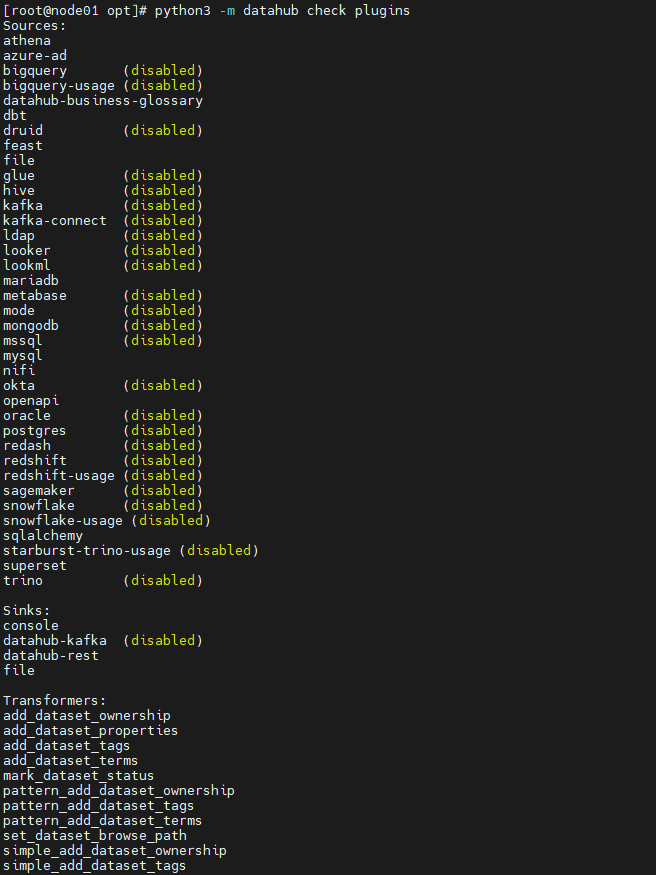
可见Mysql插件和Rest接口插件已经安装,下面配置从 MySQL 获取元数据使用 Rest 接口将数据存储 DataHub。
vim mysql_to_datahub_rest.yml
# A sample recipe that pulls metadata from MySQL and puts it into DataHub
# using the Rest API.
source:
type: mysql
config:
username: root
password: 123456
database: cnarea20200630
transformers:
- type: "fully-qualified-class-name-of-transformer"
config:
some_property: "some.value"
sink:
type: "datahub-rest"
config:
server: "http://ip:8080"
# datahub ingest -c mysql_to_datahub_rest.yml
随后是漫长的数据获取过程。
得到如下提示后,证明获取成功。
{datahub.cli.ingest_cli:83} - Finished metadata ingestion
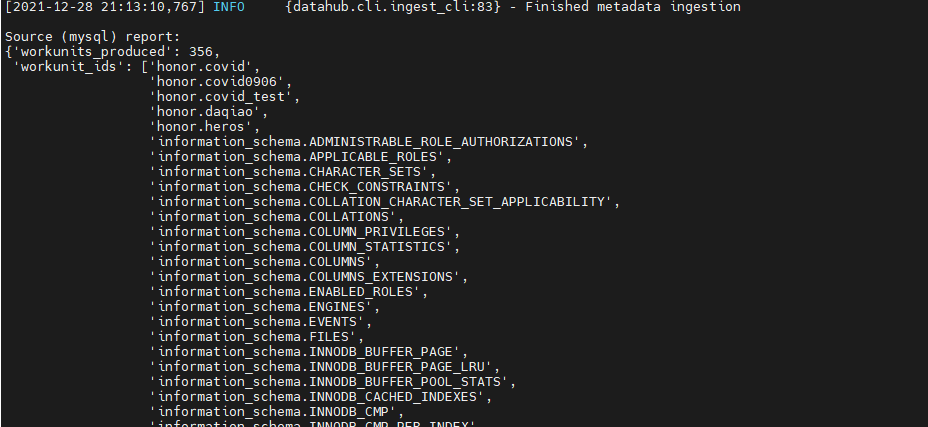
Sink (datahub-rest) report:
{'records_written': 356,
'warnings': [],
'failures': [],
'downstream_start_time': datetime.datetime(2021, 12, 28, 21, 8, 37, 402989),
'downstream_end_time': datetime.datetime(2021, 12, 28, 21, 13, 10, 757687),
'downstream_total_latency_in_seconds': 273.354698}
Pipeline finished with warnings
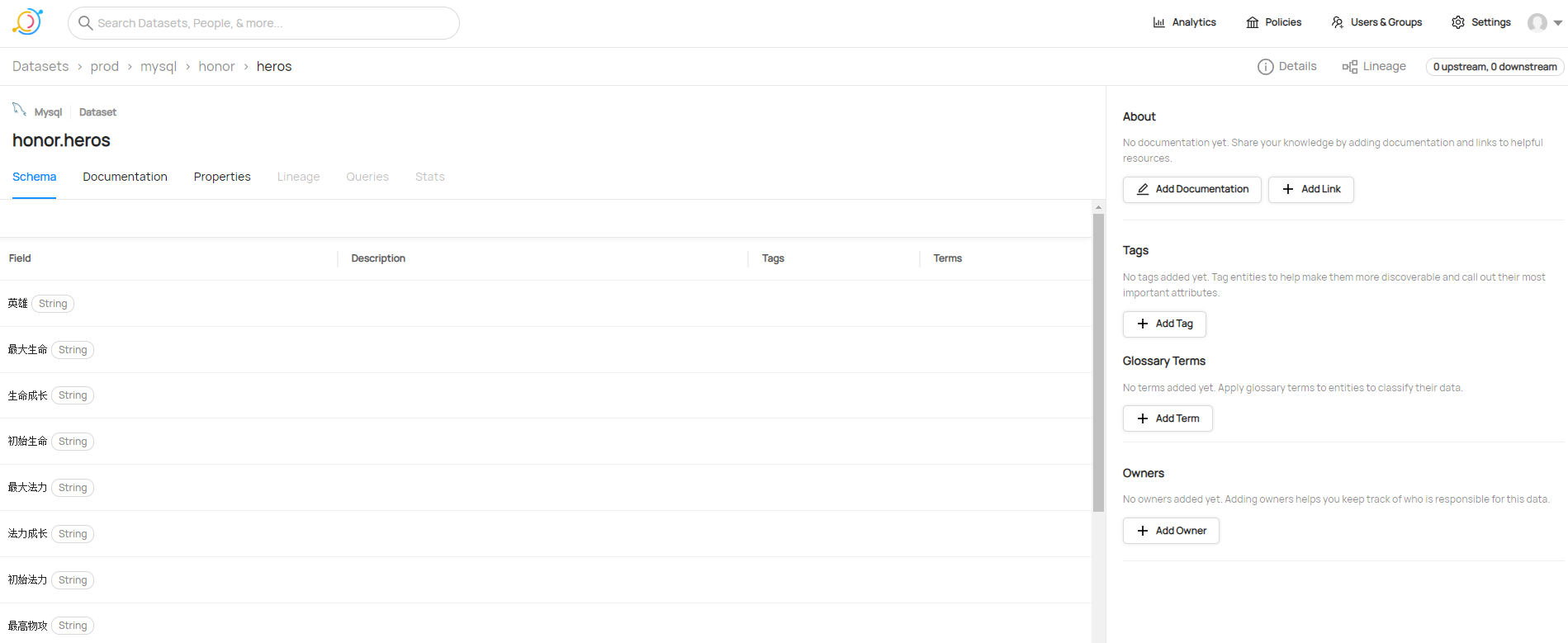
在此刷新datahub页面,mysql的元数据信息已经成功获取。
进入表中查看元数据的情况,表字段信息。
在之前展示元数据分析页也已经有了详细的展示。
至此我们完成了Datahub从0到1的搭建,在整个过程中除了简单的安装配置以外,基本没有进行任何代码研发工作。但是datahub还有更多的功能,比如对数据血缘的获取,在元数据获取的过程中进行转换操作等等。在未来的文章中也会进行更新这些功能的教程。






![19.[Python GUI] PyQt5中的模型与视图框架-基本原理](https://img-blog.csdnimg.cn/img_convert/0b43def892892ebae81ce7855ce1a6b9.png)