目录
第一关:标准化
任务描述:
相关知识:
一、为什么要进行标准化
二、Z-score标准化
三、Min-max标准化
四、MaxAbs标准化
编程要求:
测试说明:
第二关:非线性转换
任务描述:
相关知识:
一、为什么要非线性转换:
二、映射到均匀分布:
三、映射到高斯分布:
编程要求:
测试说明:
第三关:归一化
任务描述:
相关知识:
一、为什么使用归一化:
二、L1范式归一化:
三、L2范式归一化:
编程要求:
测试说明:
第四关:离散值编码
任务描述:
相关知识:
一、LabelEncoder:
二、 OneHotEncoder:
编程要求:
测试说明:
第五关:生成多项式特征
任务描述:
相关知识:
一、为什么需要多项式特征:
二、PolynomialFeatures:
编程要求:
测试说明:
第六关:估算缺失值
任务描述:
相关知识:
1.为什么要估算缺失值:
2.Imputer:
编程要求:
测试说明:
第一关:标准化
任务描述:
本关任务:利用sklearn对数据进行标准化。
相关知识:
为了完成本关任务,你需要掌握:1.为什么要进行标准化,2.Z-score标准化,3.Min-max标准化,4.MaxAbs标准化。
一、为什么要进行标准化
对于大多数数据挖掘算法来说,数据集的标准化是基本要求。这是因为,如果特征不服从或者近似服从标准正态分布(即,零均值、单位标准差的正态分布)的话,算法的表现会大打折扣。实际上,我们经常忽略数据的分布形状,而仅仅做零均值、单位标准差的处理。在一个机器学习算法的目标函数里的很多元素所有特征都近似零均值,方差具有相同的阶。如果某个特征的方差的数量级大于其它的特征,那么,这个特征可能在目标函数中占主导地位,这使得模型不能从其它特征有效地学习。
二、Z-score标准化
这种方法基于原始数据的均值mean和标准差standard deviation进行数据的标准化。将特征A的原始值x使用z-score标准化到x’。z-score标准化方法适用于特征A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。将数据按其特征(按列进行)减去其均值,然后除以其方差。最后得到的结果是,对每个特征/每列来说所有数据都聚集在0附近,方差值为1。数学公式如下:

from sklearn import preprocessingimport numpy as npX_train = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])X_scaled = preprocessing.scale(X_train)>>>X_scaledarray([[ 0. ..., -1.22..., 1.33...],[ 1.22..., 0. ..., -0.26...],[-1.22..., 1.22..., -1.06...]])
经过缩放后的数据具有零均值以及标准方差:
>>> X_scaled.mean(axis=0)array([ 0., 0., 0.])>>> X_scaled.std(axis=0)array([ 1., 1., 1.])
三、Min-max标准化

X_train = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])min_max_scaler = preprocessing.MinMaxScaler()X_train_minmax = min_max_scaler.fit_transform(X_train)>>> X_train_minmaxarray([[ 0.5 , 0. , 1. ],[ 1. , 0.5 , 0.33333333],[ 0. , 1. , 0. ]])
四、MaxAbs标准化

编程要求:
在右侧编辑器Begin-End处补充Python代码,实现数据标准化方法,我们会使用实现好的方法对数据进行处理。
测试说明:
我们会调用你实现的方法对数据进行处理,如使用Z-score方法,则处理后数据均值为0方差为1,如使用minmax方法,则处理后数据最小值为0,最大值为1,如使用maxabs方法,则处理后数据最大值为1。我们会对结果进行检测,完全正确则视为通关。
# -*- coding: utf-8 -*-
from sklearn.preprocessing import scale,MaxAbsScaler,MinMaxScaler
#实现数据预处理方法
def Preprocessing(x,y):
'''
x(ndarray):处理 数据
y(str):y等于'z_score'使用z_score方法
y等于'minmax'使用MinMaxScaler方法
y等于'maxabs'使用MaxAbsScaler方法
'''
#********* Begin *********#
if y == 'z_score':
x = scale(x)
return x
elif y == 'minmax':
min_max_scaler = MinMaxScaler()
x = min_max_scaler.fit_transform(x)
return x
elif y == 'maxabs':
maxabs = MaxAbsScaler()
x = maxabs.fit_transform(x)
return x
#********* End *********#
第二关:非线性转换
任务描述:
本关任务:利用sklearn对数据进行非线性转换。
相关知识:
为了完成本关任务,你需要掌握:1.为什么要非线性转换,2.映射到均匀分布,3.映射到高斯分布。
一、为什么要非线性转换:
在上一关中已经提到,对于大多数数据挖掘算法来说,如果特征不服从或者近似服从标准正态分布(即,零均值、单位标准差的正态分布)的话,算法的表现会大打折扣。非线性转换就是将我们的特征映射到均匀分布或者高斯分布(即正态分布)。
二、映射到均匀分布:
相比线性缩放,该方法不受异常值影响,它将数据映射到了零到一的均匀分布上,将最大的数映射为1,最小的数映射为0。其它的数按从小到大的顺序均匀分布在0到1之间,如有相同的数则取平均值,如数据为np.array([[1],[2],[3],[4],[5]])则经过转换为:np.array([[0],[0.25],[0.5],[0.75],[1]]),数据为np.array([[1],[2],[9],[10],[2]])则经过转换为:np.array([[0],[0.375],[0.75],[1.0],[0.375]])。第二个例子具体过程如下图:
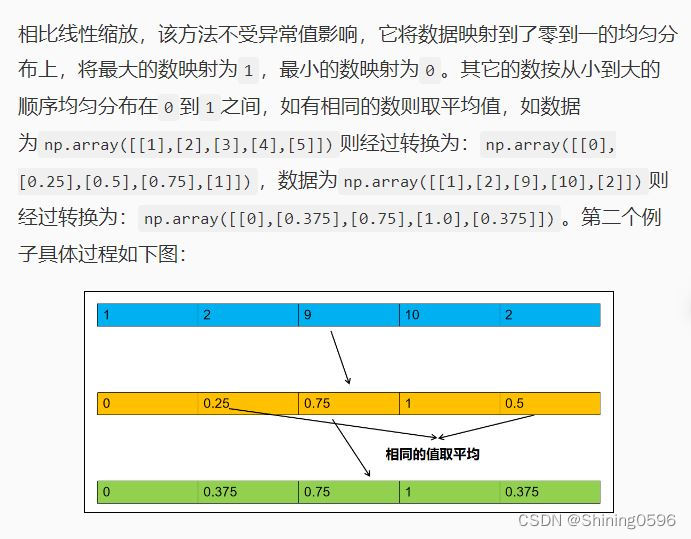
在sklearn中使用QuantileTransformer方法实现,用法如下:
from sklearn.preprocessing import QuantileTransformerimport numpy as npdata = np.array([[1],[2],[3],[4],[5]])quantile_transformer = QuantileTransformer(random_state=666)data = quantile_transformer.fit_transform(data)>>>dataarray([[0. ],[0.25],[0.5 ],[0.75],[1. ]])
三、映射到高斯分布:

from sklearn.preprocessing import PowerTransformer
import numpy as np
data = np.array([[1],[2],[3],[4],[5]])
pt = PowerTransformer(method='box-cox', standardize=False)
data = pt.fit_transform(data)学习平台使用的是sklearn 0.19.x,通过对QuantileTransformer设置参数output_distribution='normal'实现映射高斯分布,用法如下:
from sklearn.preprocessing import QuantileTransformerimport numpy as npdata = np.array([[1],[2],[3],[4],[5]])quantile_transformer = QuantileTransformer(output_distribution='normal',random_state=666)data = quantile_transformer.fit_transform(data)data = np.around(data,decimals=3)>>>dataarray([[-5.199],[-0.674],[ 0. ],[ 0.674],[ 5.199]])
编程要求:
根据提示,在右侧编辑器Begin-End处补充Python代码,实现数据非线性转换方法,我们会使用实现好的方法对数据进行处理。
测试说明:
我们会调用你实现好的方法对数据进行处理,如输入数据为:
np.array([[1],[2],[3],[4],[5]])
映射到均匀分布,则处理后结果为:
np.array([[0. ], [0.25],[0.5 ],[0.75],[1. ]])
映射到高斯分布,则处理后结果为:
np.array([[-5.199],[-0.674],[ 0. ],[ 0.674],[ 5.199]])
# -*- coding: utf-8 -*-
from sklearn.preprocessing import QuantileTransformer
#实现非线性转换方法
def non_linear_transformation(x,y):
'''
x(ndarray):待处理数据
y(int):y等于0映射到均匀分布
y等于1映射到高斯分布
'''
#********* Begin *********#
if y == 0:
transformer = QuantileTransformer(random_state=666)
x = transformer.fit_transform(x)
return x
elif y == 1:
transformer = QuantileTransformer(output_distribution='normal',random_state=666)
x = transformer.fit_transform(x)
return x
#********* End *********#
第三关:归一化
任务描述:
本关任务:利用sklearn对数据进行归一化。
相关知识:
为了完成本关任务,你需要掌握:1.为什么使用归一化,2.L1范式归一化,3.L2范式归一化。
一、为什么使用归一化:
归一化是缩放单个样本以具有单位范数的过程。归一化实质是一种线性变换,线性变换有很多良好的性质,这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现,这些性质是归一化的前提。归一化能够加快模型训练速度,统一特征量纲,避免数值太大。值得注意的是,归一化是对每一个样本做转换,所以是对数据的每一行进行变换。而之前我们讲过的方法是对数据的每一列做变换。
二、L1范式归一化:

三、L2范式归一化:

编程要求:
根据提示,在右侧编辑器Begin-End处补充Python代码,实现数据归一化方法,我们会使用实现好的方法对数据进行处理。
测试说明:
我们会调用你实现的方法对数据进行处理,如数据为:
data = np.array([[-1,0,1],[1,0,1],[1,2,3]])
使用L1归一化则输出为:
array([[-0.5 , 0. , 0.5 ],[ 0.5 , 0. , 0.5 ],[ 0.167, 0.333, 0.5 ]])
使用L2归一化则输出为:
array([[-0.707, 0. , 0.707],[ 0.707, 0. , 0.707],[ 0.267, 0.535, 0.802]])
# -*- coding: utf-8 -*-
from sklearn.preprocessing import normalize
#实现数据归一化方法
def normalization(x,y):
'''
x(ndarray):待处理数据
y(int):y等于1则使用"l1"归一化
y等于2则使用"l2"归一化
'''
#********* Begin *********#
if y == 1:
x = normalize(x,norm='l1')
return x
elif y == 2:
x = normalize(x,norm='l2')
return x
#********* End *********#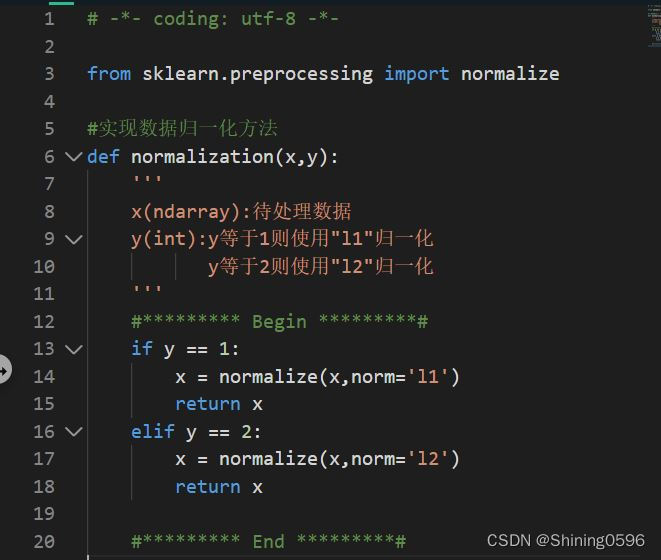
第四关:离散值编码
任务描述:
本关任务:利用sklearn对标签进行OneHot编码。
相关知识:
为了完成本关任务,你需要掌握:1. LabelEncoder;2. OneHotEncoder。
一、LabelEncoder:
在数据挖掘中,特征经常不是数值型的而是分类型的。举个例子,一个人可能有["male", "female"],["from Europe", "from US", "from Asia"],["uses Firefox", "uses Chrome", "uses Safari", "uses Internet Explorer"]等分类的特征。这些特征能够被有效地编码成整数,比如["male", "from US", "uses Internet Explorer"]可以被表示为[0, 1, 3],["female", "from Asia", "uses Chrome"]表示为[1, 2, 1]。
在sklearn中,通过LabelEncoder来实现:
from sklearn.preprocessing import LabelEncoderlabel = ['male','female']int_label = LabelEncoder()label = int_label.fit_transform(label)>>>labelarray([1, 0])

二、 OneHotEncoder:
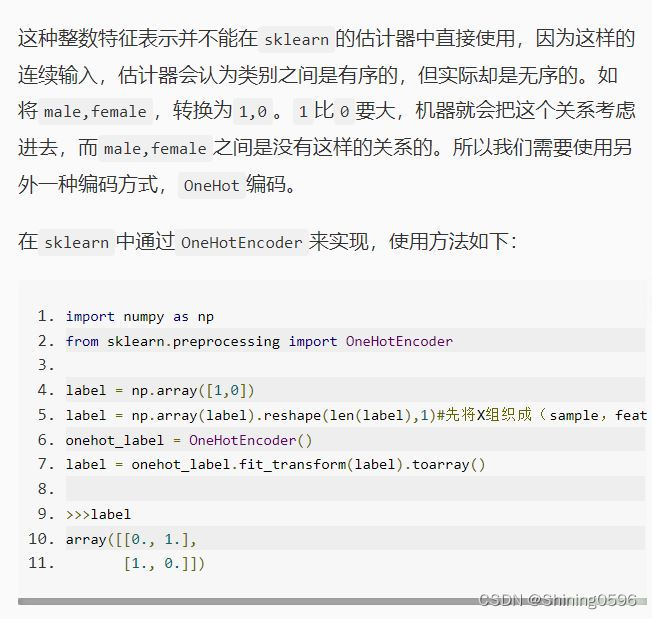
import numpy as np
from sklearn.preprocessing import OneHotEncoder
label = np.array([1,0])
label = np.array(label).reshape(len(label),1)#先将X组织成(sample,feature)的格式
onehot_label = OneHotEncoder()
label = onehot_label.fit_transform(label).toarray()
>>>label
array([[0., 1.],
[1., 0.]])编程要求:
根据提示,在右侧编辑器Begin-End处补充代码,实现OneHot编码方法。
测试说明:
我们会调用你实现的方法对标签进行处理,如标签为:
label = ['male','female']
则经过OneHot编码后的数据为:
array([[0., 1.],[1., 0.]])
# -*- coding: utf-8 -*-
import numpy as np
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
def onehot_label(label):
'''
input:label(list):待处理标签
output:lable(ndarray):onehot处理后的标签
'''
#********* Begin *********#
int_label = LabelEncoder()
label = int_label.fit_transform(label)
label = np.array(label).reshape(len(label),1)
onehot_label = OneHotEncoder()
label = onehot_label.fit_transform(label).toarray()
return label
#********* End *********#第五关:生成多项式特征
任务描述:
本关任务:利用sklearn生成多项式特征。
相关知识:
为了完成本关任务,你需要掌握:1.为什么需要多项式特征;2.PolynomialFeatures。
一、为什么需要多项式特征:
在数据挖掘中,获取数据的代价经常是非常高昂的。所以有时就需要人为的制造一些特征,并且有的特征之间是有关联的。生成多项式特征可以轻松的为我们获取更多的数据,并获得特征的更高维度和互相间关系的项且引入了特征之间的非线性关系,可以有效的增加模型的复杂度。
二、PolynomialFeatures:
在sklearn中通过PolynomialFeatures方法来生成多项式特征,使用方法如下:
import numpy as npfrom sklearn.preprocessing import PolynomialFeaturesdata = np.arange(6).reshape(3, 2)poly = PolynomialFeatures(2)#生成二项式特征data = poly.fit_transform(data)>>>dataarray([[ 1., 0., 1., 0., 0., 1.],[ 1., 2., 3., 4., 6., 9.],[ 1., 4., 5., 16., 20., 25.]])
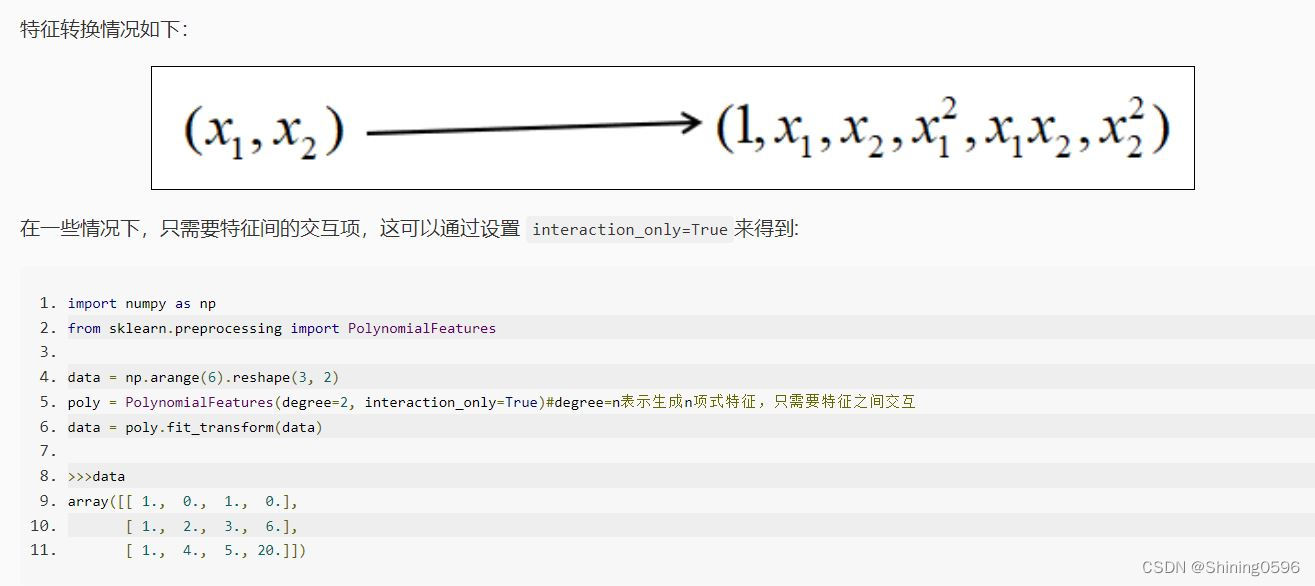
import numpy as npfrom sklearn.preprocessing import PolynomialFeaturesdata = np.arange(6).reshape(3, 2)poly = PolynomialFeatures(degree=2, interaction_only=True)#degree=n表示生成n项式特征,只需要特征之间交互data = poly.fit_transform(data)>>>dataarray([[ 1., 0., 1., 0.],[ 1., 2., 3., 6.],[ 1., 4., 5., 20.]])

编程要求:
根据提示,在右侧编辑器Begin-End处补充代码,实现生成多项式特征方法。
测试说明:
我们会调用你实现的方法,将数据生成多项式特征,如数据为:
data = np.arange(6).reshape(3, 2)
则生成二项式特征为:
array([[ 1., 0., 1., 0., 0., 1.],[ 1., 2., 3., 4., 6., 9.],[ 1., 4., 5., 16., 20., 25.]])
生成二项式只交互特征为:
array([[ 1., 0., 1., 0.],[ 1., 2., 3., 6.],[ 1., 4., 5., 20.]])
# -*- coding: utf-8 -*-
from sklearn.preprocessing import PolynomialFeatures
def polyfeaturs(x,y):
'''
x(ndarray):待处理特征
y(int):y等于0生成二项式特征
y等于1生成二项式特征,只需要特征之间交互
'''
#********* Begin *********#
if y==0:
poly = PolynomialFeatures(2)#生成二项式特征
x = poly.fit_transform(x)
return x
elif y==1:
poly = PolynomialFeatures(degree=2, interaction_only=True)#生成二项式特征,只需要特征之间交互
x = poly.fit_transform(x)
return x
#********* End *********#
第六关:估算缺失值
任务描述:
本关任务:利用sklearn对数据估算缺失值。
相关知识:
为了完成本关任务,你需要掌握:1.为什么要估算缺失值,2.Imputer。
1.为什么要估算缺失值:
由于各种原因,真实世界中的许多数据集都包含缺失数据,这类数据经常被编码成空格、NaNs,或者是其他的占位符。但是这样的数据集并不能被sklearn学习算法兼容,因为大多的学习算法都默认假设数组中的元素都是数值,因而所有的元素都有自己的意义。 使用不完整的数据集的一个基本策略就是舍弃掉整行或整列包含缺失值的数据。但是这样就付出了舍弃可能有价值数据(即使是不完整的 )的代价。 处理缺失数值的一个更好的策略就是从已有的数据推断出缺失的数值。
2.Imputer:
sklearn中使用Imputer方法估算缺失值,使用方法如下:
from sklearn.preprocessing import Imputerdata = [[np.nan, 2], [6, np.nan], [7, 4],[np.nan,4]]imp = Imputer(missing_values='NaN', strategy='mean', axis=0)#缺失值为nan,沿着每一列,使用平均值来代替缺失值data = imp.fit_transform(data)>>>dataarray([[6.5 , 2. ],[6. , 3.33333333],[7. , 4. ],[6.5 , 4. ]])
其中strategy参数用来选择代替缺失值方法:
`mean`表示使用平均值代替缺失值`median`表示使用中位数代替缺失值`most_frequent`表示使用出现频率最多的值代替缺失值
missing_values参数表示何为缺失值:
`NaN`表示`np.nan`为缺失值`0`表示`0`为缺失值
编程要求:
根据提示,在右侧编辑器Begin-End处补充代码,实现估算缺失值方法。
测试说明:
我们会调用你实现的估算缺失值方法对数据进行处理,如输入数据为:
data = [[np.nan, 2], [6, np.nan], [7, 4],[np.nan,4]]
则用取平均值方法处理后数据为:
array([[6.5 , 2. ],[6. , 3.33333333],[7. , 4. ],[6.5 , 4. ]])
用取中位数方法处理后数据为:
array([[6.5, 2. ],[6. , 4. ],[7. , 4. ],[6.5, 4. ]])
用出现频率最多的值代替缺失值方法处理后数据为:
array([[6., 2.],[6., 4.],[7., 4.],[6., 4.]])
# -*- coding: utf-8 -*-
from sklearn.preprocessing import Imputer
def imp(x,y):
'''
x(ndarray):待处理数据
y(str):y为'mean'则用取平均方式补充缺失值
y为'meian'则用取中位数方式补充缺失值
y为'most_frequent'则用出现频率最多的值代替缺失值
'''
#********* Begin *********#
if y == 'mean':
im = Imputer(missing_values='NaN', strategy='mean', axis=0)
x = im.fit_transform(x)
return x
elif y == 'median':
im = Imputer(missing_values='NaN', strategy='median', axis=0)
x = im.fit_transform(x)
return x
elif y == 'most_frequent':
im = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
x = im.fit_transform(x)
return x
#********* End *********#
![[附源码]计算机毕业设计JAVA教师档案管理系统](https://img-blog.csdnimg.cn/881f7fe23c1146089c069d94a18e7fdb.png)