摘要
强化学习中的一个重要问题是如何以有原则的方式整合专家知识,尤其是当我们扩展到现实世界的任务时。在本文中,我们提出了一种在不改变最优策略的情况下将任意建议纳入强化学习agent的奖励结构的方法。 该方法将 Ng 等人 (1999) 提出的基于势能的塑形方法扩展到基于状态和动作的塑形函数的情况。 这允许使用更具体的信息来指导agent——选择哪个动作——而不需要agent仅从状态的奖励中发现这一点。 我们开发了两种定性不同的方法来将势能函数转换为对agent的建议。我们还提供了根据势能函数的属性在这些建议算法之间进行选择的理论和实验依据。
1. Introduction
------人类很少在不假设哪种行为可能有效的情况下处理新任务。这种偏见是我们如何快速学习跨各个领域的有效行为的必要组成部分。如果没有这样的假设,就需要很长时间才能偶然发现有效的解决方案。
在其最一般的定义中,人们可以将建议(advice)视为一种对解决问题的各种行为的有用性提供期望的手段。在早期学习过程中,建议是至关重要的,以便首先尝试有前途的行为。这在大域中是必要的,其中强化信号可能很少而且相距很远。这种问题的一个很好的例子是国际象棋。
------国际象棋的目标是赢得比赛,适当的强化信号将以此为基础。如果一个agent要在没有先验知识的情况下学习国际象棋,它就必须花费大量时间才能找到获胜策略。我们可以通过建议agent来加快这个过程,让它意识到拿走棋子是有奖励的,而丢失棋子是遗憾的。这个建议创造了一个更丰富的学习环境,但也冒着分散agent注意力的风险,使其偏离真正的目标——赢得比赛。
------建议极为重要的另一个领域是机器人技术和其他现实世界的应用程序。**在现实世界中,学习时间非常昂贵。**为了减轻“颠簸”——反复尝试无效的行动——应尽可能频繁地提供奖励(Mataric,1994)。如果问题本质上是由稀疏奖励来描述的,那么在不破坏目标的情况下很难改变环境的奖励结构。
------在高度随机的环境中,建议也是必要的。在这样的环境中,行动的预期效果不会立即显现。为了公平地评估一个动作的价值,必须多次尝试该动作。如果建议可以将这种探索集中在可能是最优的行动上,那么可以节省大量的探索时间。
2. Previous Approaches
------将偏见或建议(bias or advice)纳入强化学习有多种形式。偏见学习最基本的方法是根据问题的先验知识选择一些初始化。可以在 Hailu 和 Sommer (1999) 中找到关于不同 Q 值初始化对一个域的影响的简要研究。这种方法的相关性在很大程度上取决于agent使用的内部表示。如果agent简单地维护一个表,初始化很容易,但如果agent使用更复杂的表示,则可能很难或不可能将agent的 Q 值初始化为特定值。
------一种更微妙的指导agent学习的方法是直接操纵agent的策略。这种方法的主要动机是,从相当好的策略的结果中学习比从随机探索中学习更有益。在 Malak 和 Kholsa (2001) 中可以找到一种将任意数量的外部策略合并到agent策略中的方法。他们的系统使用精心设计的策略加权方案来确定何时遵循外部策略不再有益。这个想法的另一个转折点是直接从其他agent的经验中学习(Price & Boutilier,1999)。这些方法的优点是它们不依赖于agent使用的内部表示。另一方面,他们只允许建议以策略的形式出现。此外,由于agent正在学习的策略可能与agent试图评估的策略非常不同,因此agent可以使用的学习算法类型受到限制。
------如果已知有关哪些操作安全有效的可靠建议,则可以将agent的可用操作限制为这些建议。 派生此类专家知识已在控制文献中进行了大量研究,并已被 Perkins 和 Barto (2001) 应用于强化学习。 此方法需要广泛的领域知识,并且可能会排除最佳操作。
------我们在本文中开发的方法与塑形非常相似。通过塑形,来自环境的奖励会随着额外的奖励而增加。这些奖励用于鼓励最终会导致目标的行为,或阻止后来会后悔的行为。如果随意进行,塑形可能会改变环境,使得先前次优的策略现在随着新奖励的加入而变得最优。现在最优的新行为可能与预期的策略有很大不同,即使添加了相对较小的塑形奖励也是如此。Randløv 和 Alsrøm (1998) 中有一个典型的例子。在训练agent控制自行车模拟时,他们会在agent向目标目的地移动时奖励agent。作为对这种奖励的回应,agent学会了绕一个小圈子,只要它朝目标方向移动就会得到奖励。基于势能的塑形,我们将在后面详细描述,是为了防止学习这样的策略而开发的(Ng et al., 1999)。
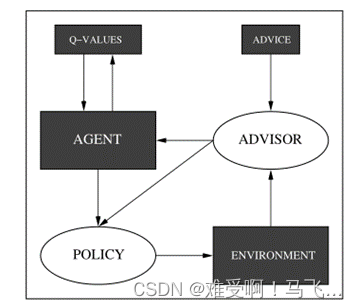
图 1. 我们为我们的建议系统假设的模型。 环境、建议函数和 Q 值估计器都是“黑盒子”。 我们展示了改变策略的方法,以及环境反馈,以便它们纳入建议。
3. Preliminaries
------我们遵循标准的强化学习框架,尽可能少地假设访问环境动态或agent的内部表示。我们的方法通过添加一个advisor来改变学习,该advisor能够改变agent收到的强化,以及改变agent的策略。下面我们列出了对agent使用的环境和学习机制所做的常见假设。
3.1 Terminology
------大多数强化学习技术将学习环境建模为马尔可夫决策过程(MDP)(见Sutton&Barto,1998)。MDP定义为 ( S , S 0 , A , T , R , γ ) (S,S0,A,T,R,γ) (S,S0,A,T,R,γ),其中S是状态集(可能无限), S 0 ( s ) S_0(s) S0(s)是agent在状态S中开始的概率,A是动作集, T ( s ’ ∣ s , a ) T(s’|s,a) T(s’∣s,a)是在状态s执行动作a时转换到状态s’的概率, R ( s , a , s ’ ) R(s,a,s’) R(s,a,s’)是一个随机函数,定义了当在状态 s s s中执行动作 a a a导致向状态 s ’ s’ s’过渡时所收到的强化, γ γ γ是衡量短期和长期奖励重要性的折现率。
------通常的强化学习任务是找到策略
π
:
S
→
A
π:S→ A
π:S→A最大化预期总折扣奖励:
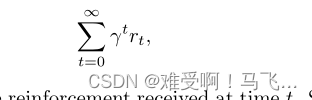
------其中
r
t
r_t
rt是在时间t接收到的增援(reinforcement)。一些MDP包含特殊的终端状态,以表示完成任务的目标或进入不可恢复的情况。当agent转换到这些状态中的一个时,所有进一步的动作都转换到空状态,并且所有进一步的增强都为零。
------我们专注于使用
Q
Q
Q值估计来确定agent策略的强化学习算法。
Q
Q
Q值表示在状态
s
s
s中采取行动
a
a
a后的预期未来折扣回报。当特定策略
π
π
π的
Q
Q
Q值准确时,它们满足以下递归关系:

------贪婪策略
π
g
(
s
)
=
a
r
g
m
a
x
a
Q
(
s
,
a
)
π^g(s)=argmax_{a}Q(s,a)
πg(s)=argmaxaQ(s,a),如果
Q
Q
Q值对于该策略是准确的,则是最优的。
-----为了学习贪婪策略的正确Q值,我们可以使用Q学习或Sarsa。这两种方法都根据MDP的经验更新Q值。一个经验是一个四元祖的<
s
,
a
,
r
,
s
’
s,a,r,s’
s,a,r,s’>,其中动作
a
a
a在状态
s
s
s中执行,获得奖励
r
r
r并转换到下一个状态
s
’
s’
s’。对于每次体验,这些方法都会根据规则更新Q值
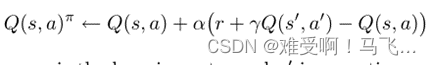
------其中 α α α 是学习率, a ′ a' a′ 是特定学习方法指定的动作。 对于 Sarsa 学习, a ′ a' a′ 是agent将执行的下一个动作。 Q-learning 将 a ′ a' a′ 设置为状态 s ′ s' s′ 的贪婪动作。 有关这些和其他强化学习算法的更多详细信息,请参见 Sutton 和 Barto (1998)。
3.2 Potential-based Shaping
------Ng 等人提出了一种以保证最优策略保持最优性的方式向 MDP 添加塑形奖励的方法。 他们在状态上定义了一个势函数
Φ
(
)
Φ()
Φ()。 从状态
s
s
s 转换到
s
′
s'
s′ 的塑形奖励根据
Φ
(
)
Φ()
Φ() 定义为:
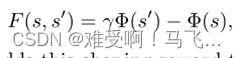
------advisor将这种塑形奖励添加到agent经历的每个状态转换的环境奖励中。
------advisor势能函数可以被视为定义状态空间上的地形。 因此,从一种状态过渡到另一种状态的塑形奖励是这种势能函数的折扣变化。因为在相同状态下开始和结束的任何路径上的总折扣势能变化为零,所以此方法保证没有循环会因塑形而产生净收益。这就是前面提到的自行车模拟所面临的问题。事实上,Ng 等人证明,任何对带有基于势能的塑形奖励增强的 MDP 最优的策略对于未增强的 MDP 也是最优的。
4. Potential-based Advice
------尽管基于势能的塑形是一种为强化agent提供指导的优雅工具,但它还不足以代表任何类型的建议。基于势能的塑形可以给agent一个关于特定状态是好是坏的提示,但它不能提供关于各种动作
a
t
a_t
at同样的建议。
PS:这段话的第二句不好翻译。我把原文贴出来,大家自己琢磨.
Potential-based shaping can give the agent a hint on whether a particular state is good or bad, but it cannot provide the same sort of advice about various actions.
------我们将基于势能的塑形扩展到定义在状态和动作上的势函数的情况。我们将基于势能的建议定义为由agent访问的状态和agent选择的动作决定的辅助奖励。
------这种扩展的一个后果是,对MDP的修改不能被描述为添加了塑形函数。塑形函数的参数是当前状态、所选动作和结果状态。这是决定奖励函数的相同信息。建议(advice)函数需要与agent当前正在评估的策略相关的附加参数。注意,如果正在评估的策略是静态的,则该参数实际上是常量,因此建议可以表示为塑形函数。
------我们提出了两种方法来实施基于势能的建议(advice)。第一种方法,我们称之为先行建议,是基于势能的塑形的直接扩展。还描述了第二种方法,称为回顾建议。当不能直接操纵agent的策略或当 Q 值泛化可能使前瞻性建议没有吸引力时,此方法提供了一种替代方法。
4.1 Look-Ahead Advice–前瞻性建议
在前瞻性建议中,在
s
s
s状态下采取动作导致向
s
′
s'
s′状态过渡所获得的增加奖励定义为
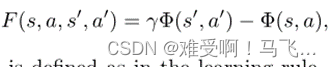
------其中
a
′
a'
a′ 在学习规则中定义。我们将在时间
t
t
t 给agent的奖励的建议部分称为
f
t
f_t
ft。
------我们分析了前瞻性建议如何改变原始 MDP 中最优策略的
Q
Q
Q-values。在原始 MDP
Q
∗
(
s
,
a
)
Q^∗(s, a)
Q∗(s,a) 中为某些状态和动作调用最优
Q
Q
Q -values。我们知道这个值等于遵循最优策略
π
∗
(
)
π^∗()
π∗() 的预期回报:
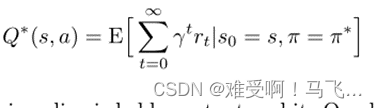
------当此策略保持不变并且其
Q
Q
Q -values在 MDP 中通过添加建议奖励进行评估时,
Q
Q
Q -values与势能函数的真实值不同:
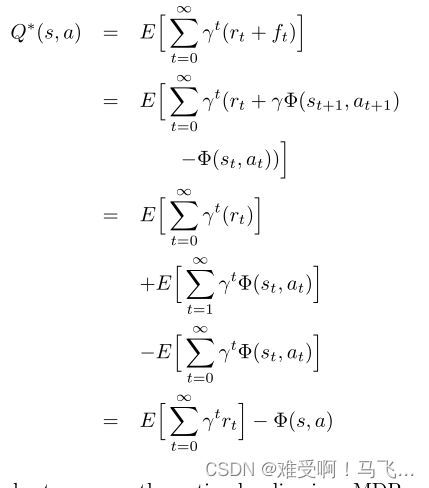
------为了在增加了前瞻性建议奖励的 MDP 中恢复最优策略,必须选择具有最高
Q
Q
Q-values加上势能
Φ
(
s
)
Φ(s)
Φ(s)的动作。我们称这种策略偏向贪婪。它被正式定义为
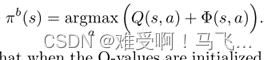
------请注意,当
Q
Q
Q-values初始化为零时,有偏见的贪婪策略会选择势能函数中具有最高值的动作,从而鼓励首先探索高度建议的动作。任何策略都可以通过将势能函数添加到当前
Q
Q
Q-values估计来选择动作来产生偏差。
4.1.1 Learnability of the Optimal Policy–最优策略的可学习性
------虽然我们可以使用有偏贪心策略恢复最优策略,但我们仍然需要确定最优策略是否可学习。 虽然我们不能在任何学习方案下对最优策略的可学习性提出要求,但当状态和动作空间有限时,我们可以对其可学习性提出要求。 在这种情况下,使用前瞻性建议和有偏策略的agent的学习动态(learning dynamics)本质上与 Q Q Q 值被初始化为势能函数的无偏agent相同。
------我们定义了两个强化学习agent
L
L
L 和
L
′
L'
L′,它们将在整个学习过程中经历相同的
Q
Q
Q-values变化。令
L
L
L 的
Q
Q
Q 表的初始值为
Q
(
s
,
a
)
=
Q
′
(
s
,
a
)
Q(s, a) = Q'(s, a)
Q(s,a)=Q′(s,a)。在学习期间将应用基于势能函数
Φ
(
)
Φ()
Φ() 的前瞻性建议
F
(
)
F()
F()。 另一个agent
L
′
L'
L′ 将有一个
Q
Q
Q 表初始化为
Q
0
′
(
s
,
a
)
=
Q
0
(
s
,
a
)
+
Φ
(
s
,
a
)
Q'_0(s, a) = Q_0(s, a) +Φ(s, a)
Q0′(s,a)=Q0(s,a)+Φ(s,a)。该agent将不会收到建议奖励。
该部分内容可以参考我的这个博客。
------两个agent的
Q
Q
Q 值都根据使用先前描述的标准强化学习更新规则的经验进行更新:

------可以将上述等式视为使用按学习率
α
α
α 缩放的误差项更新
Q
Q
Q 值。我们将误差项称为
δ
Q
(
s
,
a
)
δQ(s, a)
δQ(s,a) 和
δ
Q
′
(
s
,
a
)
δQ'(s, a)
δQ′(s,a)。 我们还跟踪学习过程中
Q
(
⋅
)
Q(·)
Q(⋅) 和
Q
′
(
⋅
)
Q'(·)
Q′(⋅) 的总变化。
Q
(
⋅
)
Q(·)
Q(⋅) 和
Q
′
(
⋅
)
Q'(·)
Q′(⋅) 中原始值和当前值之间的差异分别称为
Δ
Q
(
⋅
)
ΔQ(·)
ΔQ(⋅) 和
Δ
Q
′
(
⋅
)
ΔQ'(·)
ΔQ′(⋅)。 agent的
Q
Q
Q 值可以表示为它们的初始值加上更新导致的这些值的变化:
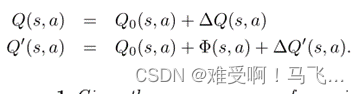
定理 1. 在学习过程中给定相同的经验序列,
Δ
Q
(
⋅
)
ΔQ(·)
ΔQ(⋅) 总是等于
Δ
Q
′
(
⋅
)
ΔQ'(·)
ΔQ′(⋅)。
证明:归纳法证明。 基本情况是当 s s s 和 s ′ s' s′ 的 Q Q Q 表条目仍然是它们的初始值时。 该定理适用于这种情况,因为 Δ Q ( ⋅ ) ΔQ(·) ΔQ(⋅) 和 Δ Q ′ ( ⋅ ) ΔQ'(·) ΔQ′(⋅) 中的项均一致为零。
对于归纳情况,假设所有
s
s
s 和
a
a
a 的条目
Δ
Q
(
s
,
a
)
=
Δ
Q
′
(
s
,
a
)
ΔQ(s, a) =ΔQ'(s, a)
ΔQ(s,a)=ΔQ′(s,a)。
我们表明,作为对经验 <
s
,
a
,
r
,
s
′
s, a, r, s'
s,a,r,s′> 的响应,误差项
δ
Q
(
s
,
a
)
δQ(s, a)
δQ(s,a) 和
δ
Q
′
(
s
,
a
)
δQ'(s, a)
δQ′(s,a) 是相等的。
首先,我们检查在存在建议的情况下对
Q
(
s
,
a
)
Q(s, a)
Q(s,a) 执行的更新:

------两个
Q
Q
Q 表都更新了相同的值,因此
Δ
Q
(
⋅
)
ΔQ(·)
ΔQ(⋅) 和
Δ
Q
0
(
⋅
)
ΔQ_0(·)
ΔQ0(⋅) 仍然相等。
------由于这两个agent的 Q 值在给定相同经验的情况下会发生相同的变化,因此它们总是会因初始化时的差异量而有所不同。 这个量就是势能函数。
------推论 1. 在使用标准强化学习更新规则学习相同经验后,接收前瞻建议的agent的有偏策略与 Q Q Q-values 初始化为势能函数的agent的无偏策略相同。
------这直接从证明中得出。 这意味着agent的贪婪策略收敛到最优策略的任何理论结果都适用于接收前瞻建议的agent的有偏见的贪婪策略。
------如果势能函数在状态空间中的区别比agent的 Q Q Q-values逼近器小,则agent可能会将势能函数视为随机的。因为最优动作和次优动作之间的 Q Q Q-values差异可以任意接近,势能函数中任何数量的感知随机性都可能导致有偏见的贪婪策略选择次优动作。 经过任何数量的学习后,这仍然是正确的。
5. Look-Back Advice–回顾建议
------到目前为止,我们假设势能函数在agent的整个生命周期内是确定的和稳定的,并且我们可以操纵agent的策略。 如果违反了这些条件中的任何一个,则可能不需要先行建议。
------基于势能的偏差的另一种方法检查agent经历的当前和以前情况的势能函数的差异。在处于状态
s
t
−
1
s_{t-1}
st−1 并在前一个时间步选择
a
t
−
1
a_{t-1}
at−1 之后,在状态
s
t
s_t
st 中选择动作
a
t
a_t
at 收到的建议是
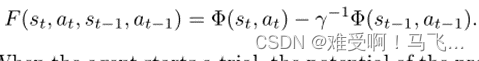
------当agent开始试验时,先前状态和动作的势能被设置为 0。
------让我们检查一下在评估固定策略
π
π
π 和接收回溯建议时期望
Q
Q
Q 值收敛到什么:
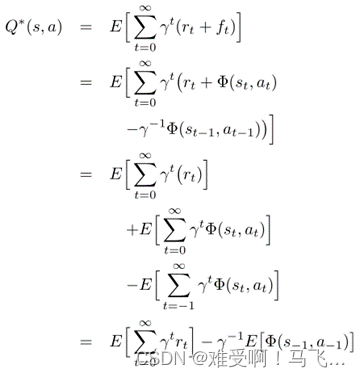
------这里
E
[
Φ
(
s
−
1
,
a
−
1
)
]
E[Φ(s_{−1}, a_{−1})]
E[Φ(s−1,a−1)] 是前一状态的势能函数的期望值,给定
π
π
π。由于agent的探索历史因素会影响建议,因此此方法只能使用 Sarsa 等在线策略学习规则。
------保证被建议的agent在没有建议的情况下在双方都充分学习后会表现得相似的策略。 这适用的策略共享一个属性,即它们对于给定状态中所有 Q Q Q 值的恒定加法是不变的。 此类策略的一些示例是贪婪的、e-贪婪的和(可能令人惊讶的)softmax。 因为我们不必操纵agent的策略来保持最优性,所以这种建议方法也可以与 actor-critic 学习架构结合使用。
------该分析还表明,回顾建议对势能函数中的感知随机性不太敏感。使用这种形式的建议学习已经面临随机性,即逼近当前选择之前的状态和动作的势能函数值。势能函数中的额外随机性将无法与agent经验中的其他随机性来源区分开来。然而,这种对噪声的鲁棒性可能会以学习时间为代价。
------在这一点上,我们没有证据表明agent的 Q 值会收敛到上面导出的预期值。 然而,表格环境中的所有实验都支持这一说法。



![[附源码]计算机毕业设计JAVA教师档案管理系统](https://img-blog.csdnimg.cn/881f7fe23c1146089c069d94a18e7fdb.png)