目录
一、一条查询的sql他是怎么样去执行的呢?
二、建立链接
同步
异步
三、连接方式
长链接
短链接
四、通信协议
Unix socket
TCP/IP
共享内存
五、通信方式
单工
半双工
全双工
六、缓存
七、解析
八、预处理器
九、优化器
十、查询执行引擎
十一、Mysql系统架构总结
十二、一条sql是如何更新的
一、一条查询的sql他是怎么样去执行的呢?
首先我们来思考一下:一条查询的sql他是怎么样去执行的呢?
如图所示,他经历如下过程。
一条查询的sql他是怎么样去执行的呢?

首先我们的程序或者工具要去操作数据的话,第一件事情是什么呢?
mysql他默认是一个服务,这个跟我们去访问第三方服务是一样的,首先我们要去定义一个通信协议。
那么我们来看看,客户端连接mysql服务器他的通信协议有哪些呢?
二、建立链接
通信类型
-
同步
-
异步
同步的话:我们知道同步的特点是,客户端的调用他是依赖被调用方的,受限于被调用方,也就是说他的性能,在我们通过的情况去操作数据库,线程会阻塞一直等待数据的返回,而且同步他只能做到一对一,很难做到一对多的特性。
异步的话:他可以避免我们的应用程序的等待,但是即使你是异步的,你的这个时间不仅仅是链接的时间,大部分的时间消耗是服务端处理的消耗,所以即使你使用异步也不能节省他执行消耗的时间。
如果你使用异步的话,它存在并发,那么你肯定不能用同一个链接,我们每一个sql语句都要单独和服务端建立链接。不然就会出现数据干扰混乱。另外我们用异步的话,大量的sql请求都会建立一个链接,所以会给服务器造成巨大的压力。
一般来说我们都是使用同步的方式。如果你要使用异步的话,你要使用连接池,去复用连接。
三、连接方式
-
长链接
-
短链接
mysql即支持长链接又支持短链接。
短链接:就要sql执行完毕,这个链接就会关闭。
长链接:他可以保持打开,这个链接不需要重复创建,这个链接可以被其他客户端复用。一般我们会在链接池中去使用长链接。
但是保持长链接的话,他对服务端也是问题,就是他会消耗内存。所以对于长时间不活动的链接,我们应该去把他关闭。
所以它是有参数可以设置的。
然后还有很多命令:查询连接数,已有链接等等
在mysql中默认的最大的连接数:151,并不是说连接数越大越好。
四、通信协议
-
Unix socket
-
TCP/IP
-
共享内存
- ....
在不组任何指定,他早期是socket , 一般我们去连接的时候会去指定:-h 一般我们用的都是TCP/IP协议
五、通信方式
-
单工
-
半双工
-
全双工

单工:意味着我们两台计算机在通信的时候,数据的传输的单向。比如:我们的遥控器
半双工:在两台服务器之间他们通信是双向的,我可以给你发送,你也可以给我发送。但是在这个建立的通信连接里面,同一时刻,他只有一台服务器来发送数据。我给你发的时候,你不能给我发,你给我发的时候 ,你也得等我给你发完之后,你才能给我发。
全双工:就是他的数据是双向的,并且我们可以同时传输。
那么mysql里面他用了什么样的通信方式呢?
他实际用的是半双工。
客户端可以给服务端发送,服务端也可以给客户端相应数据。但是同一时刻只能有一端去发送数据。
所以我们在执行sql的时候,不管你有多长,都要一次发送完。
但是我们sql不能太长,太长他会报错。所以这里有一个参数可以设置:这个sql大小。
他默认是4兆。你超过4兆他就会报错,不会再往服务端发送。这是对客户端来说。
那么对于服务端来说:如果我已经执行了sql语句,进行回传数据了,那么我也只能一次性把所有数据都发送给客户端。所以这个大数据的传输,存在内存和网络的消耗。
所以我们在服务端查询操作,一定要避免没有limit的操作。
那么这是我们的第一步;建立了链接,那么下一步该干什么呢?
我们去猜想一下,可能想不到,下一步他会有一个缓存的操作。
六、缓存
在mysql中,他默认查询缓存是关闭的。
我们可以去设置。
那么为什么默认关闭呢?就是myql他不在推荐使用。
那么为什么mysql不在推荐他自己自带的缓存了呢?
主要是:自带的缓存模块他有很多的限制。
- 就是他要求我们的sql语句必须是一摸一样的,连一个空格都不能不一样。
- 只要我们表中一条数据发生变化,我们的缓存就会失效。
所以这样一来这个缓存就比较鸡肋。
所以缓存这一块我们还是交给专业缓存服务去处理,要么是我们的ORM框架,比如mybatis,默认开启,比如redis.他在8.0已经去掉了
如果没有缓存,下一步做什么呢?
七、解析
解析器,他一共做了两件事情:
- 词法解析
- 语法解析
此词法的解析:就是把我们的sql语句,打碎成一个一个的单词,
语法解析:就是比如我们的单引号是否闭合,对SQL中的关键字去做一个分类等等。
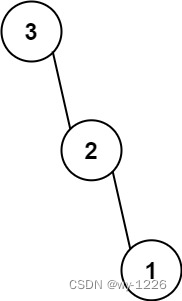
经过这两个,他最后会得到一个数据结构:
我们称之为解析树:
解析树

我们通过上面一个sql得到了他的一个解析树。它是一种数据结构。
我们任何数据库的软件,包括中间件,等等。你既然你要帮我做语句的路由,你必然去要去对我们的sql语句去进行分析一遍,所以在他们里面这个两个词法分析,和语法分析势必毕不少的。
那么此时我们的词法和语法分析都没有问题,然后我们去执行一个表明不存在的表,此时他会报错,那么这个错误他是在哪里报的呢?
所以在这一步完成时候之后再mysql有一个预处理器
八、预处理器
它使用来检查语义的。就是我们的词法分析和语法分析不能识别的一些事情。
比如:我们的表名,别名,列名,等等是不是存在,这是他做的一件事情,然后他得到的结果还是解析树,不过他得到的是一个经过处理的新的解析树。
那么经过此步骤,接下来,他是不是要去执行我们的sql语句了呢?
这里我们有一个问题:我们任何一条sql语句,他发送到服务端去执行的时候,是不是只有一种执行方式,或者说我们发送给服务端的执行语句,最终是不是就是按照我发送的sql去执行的呢?
不是的。因为我们sql语句他有很多的执行方式,和执行路径。只不过他最终得到的结果是相等的。是等价的。那么既然一条sql他有很多的执行方式,那么我们是怎么得到的这些方式的?
或者我们得到了这么多的执行sql,那么我最终应该选择哪一条去执行的呢?
根据一个什么样的判断标准去选择呢?
所以在我们mysql里面有一个很重要的东西:优化器
九、优化器
他要去对我们的sql语句去进行优化。
这个叫做查询优化器,这个目的是什么呢?在执行前要把我们的解析树交给他去优化一下子呢?
他就是根据我们的解析树去生成不同的执行计划:Execution Plan。然后再这诶生成的执行计划里面,去选择一种,成本最小的,或者开销最小的方式去执行。所以哪一种开销小,我就选择哪一种。
那么我们怎么去看每一条sql语句的开销呢?
他同样有命令去查看。
那么我们的优化器,他到底可以做什么样的事情呢?
比如我们有join等关联查询,他会去选择基于那张表作为基础表,比如多个索引,他会选择一个索引去执行。
但是需要注意的是:我们的优化器他一定不是万能的。你的sql写的太垃圾了,优化器是没有办法帮你去优化的。
如果我么想去看优化器到底生成哪些sql,哪有分别效率是多少,我们有一个优化器查询追踪的命令。
我们要记住,优化器他最终执行的执行计划,并不一定是最优的计划,因为他可能覆盖不到有点执行方式。
我们想去查看执行计划,可以通过expalin 命令.
那么有了这个之最终执行计划,那么我们的sql是不是就可以去执行了呢?
所以这里又有一个问题,从逻辑上来说,
我们的数据他们是放到哪里的呢?或者说是放在什么样的结构里面的呢?
还有就是我们的执行计划数据结构,他是在哪里执行的呢?有谁执行的呢?
所以回答第一个问题:在关系型数据库中,我们的数逻辑上是存在table 表中的。那么我们可以吧table理解为我们可见的excel可见的电子表。
所以在我们的表存储数据的同时,你去存储数据,还要去组织数据存储的结构,那么这个结构,它是由什么决定呢?
他是由存储引擎决定的,所以我们也可以把存储引擎,叫做表类型tableType。
那么在mysql中,有非常多的存储引擎的,而且他们是可以替换的,所以叫做插件是的存储引擎。
那么在mysql里面为什么搞这么多的存储引擎呢?
那么在数据库中我们呢而又这么多张表,那么怎么看这么多张表的存储引擎呢?
我们可以通过命令去查看我们数据每张表所使用的的存储引擎。
在mysql里面存储引擎使用的单位,是表。就是说每一张表都可以有不同的存储引擎,而不是说,一个数据库公用一个存储引擎,并且他的存储引擎是可以修改的。
那么说如果一张表使用的存储引擎,决定了我们存储数据的方式,在服务器上他们到底是怎么样去存储的呢?
那么我们要去找到数据存储的目录。
然后我们可以看到,每一个数据库他在我们的磁盘上都会有一个目录。
然后我们会看到,不同的存储引擎,他们的存储文件数量都是不一样的。所以就说明的不同的存储引擎他们是采用不同的存储方式去存储的。

那么不同的存储引擎他们的特性是什么呢?
| 存储引擎 | 描述 |
|---|---|
| ARCHIVE | 用于数据存档的引擎,数据被插入后就不能在修改了,且不支持索引。 |
| CSV | 在存储数据时,会以逗号作为数据项之间的分隔符。 |
| BLACKHOLE | 会丢弃写操作,该操作会返回空内容。 |
| FEDERATED | 将数据存储在远程数据库中,用来访问远程表的存储引擎。 |
| InnoDB | 具备外键支持功能的事务处理引擎 |
| MEMORY | 置于内存的表 |
| MERGE | 用来管理由多个 MyISAM 表构成的表集合 |
| MyISAM | 主要的非事务处理存储引擎 |
| NDB | MySQL 集群专用存储引擎 |
MySQL :: MySQL 8.0 Reference Manual :: 16 Alternative Storage Engines
MySQL存储引擎有哪些?
从官网看,他支持不同的存储引擎,所以我们的可以根据不同的业务来决定表使用哪一个存储引擎。
所以存储引擎他是一个可插拔式的。
那么我们怎么去选择呢?
数据我们业务找中,需要事务的支持,innerDb
需要的查询数据比较高 myisam
如果提供不满足,那么你就可以去自定义是实现一个,它支持自定扩展存储引擎。
既然我们知道存储引擎是来存储数据的。
那么回到上面思路,是由来操作我们的执行计划,用存储引擎来存储数据的.
十、查询执行引擎
是他用我们的得到的执行计划,去操作我们的存储引擎,那么为什么我们一张表的存储引擎是可以替换,而且我们sql语句的操作不需要做修改的呢?就是因为所有的存储引擎,他们必须提供相同的API.
所以我们的查询执行引擎直接去操作我们的存储引擎API就行了。
然后我们的查询执行请求,操作之后,就会把我们的数据返回给客户端,如果有缓存,就会写入缓存。
这个就是我们的一条sql的执行流程。
十一、Mysql系统架构总结

- Connector:用来支持各种语言和 SQL 的交互,比如 PHP,Python,Java 的 JDBC;
- Management Serveices & Utilities:系统管理和控制工具,包括备份恢复、 MySQL 复制、集群等等;
- Connection Pool:连接池,管理需要缓冲的资源,,就是管理服务端的连接,包括用户密码权限线程等 等;
- SQL Interface:sql语句的接口。用来接收用户的 SQL 命令,返回用户需要的查询结果
- Parser:用来解析 SQL 语句;就是词法解析,语法解析,预处理等等,他会把语句打散成一个个单词。
- Optimizer:查询优化器;
- Cache and Buffer:查询缓存,除了行记录的缓存之外,还有表缓存,Key 缓 存,权限缓存等等;
- Pluggable Storage Engines:插件式存储引擎,它提供 API 给服务层使用, 跟具体的文件打交道。他是我们去组织数据存放的一种形式,一种方式。不同而存储引擎他存储方式不同。
那么基于这个内部模块,我们也有一个简单的层次的划分。
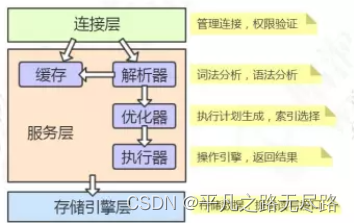
简单的可以分为三层。
- 连接层:他是跟客户端进行对接的,他会管理连接,做权限的认证。
- 服务层:他是真正去做我们的sql语句的处理和执行,他里面做了很多的事情。
- 存储引擎层:就是来存储数据的,作用就是规定了数据存储时的存储结构。存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数 据等技术的实现方法
这是他的一个架构的简单介绍,那么我们来看一下,一个条,sql他的更新的语句怎么执行的呢?
十二、一条sql是如何更新的
那么这个更新的sql的执行跟我们的查询的执行有什么区别呢?
我们可以才想到,他们的前面的基础的流程基本是一致的,你要去更新一个数据呢。那么你就需要去拿到这个数据。
所以你也要经过:解析器的处理,优化器的处理等等这些环节是跑不掉的,最终都会交给 我们的执行器。
那么不同的存储引擎在什么地方不一样呢?
就是在拿到了符合条件的之后的这些操作,
首先我们要知道一个概念,我们的数据他都是存在磁盘上的,那么在InnerDB里面他有一个操作数据,也就是把我们磁盘呢数据加载到内存中的最小的执行单位:叫做页,page.我们的数据他是在页里面的。
我们对数据的操作,并不是每一次都去操作磁盘。因为磁盘的操作速度太慢了,所以他使用了一个缓冲池的技术,也就是把我们磁盘读到的页的信息,把数据放在一块内存的区域里面。那么这个区域我么就叫做:buffer pool。
那么下一次我们再去读取数据的时候,我会先到内存的buffer pool内存的缓冲池里面去判断,我们要操作的页是不是在这个缓冲池里面。如果是的话,我直接去读取了,我就不需要,去访问磁盘了,
那么修改数据的时候是什么样的呢?
如果你在缓冲池里面了,我就去直接修改缓冲池里面页。我在内存中去修改了数据,如果内存的数据跟磁盘的数据不一致的时候,那么我们就把他叫做脏页。
那么我们的内存数据他有怎么样最终存储到磁盘的呢?
所以在InnerDB里面,他后台其实有很多的线程去工作,就是把buffer中的数据写入到磁盘。他可能是每隔一段时间,把多个修改一次性写入磁盘里面。然后我们就把这个把脏页数据同步到磁盘的操作叫做:刷脏。
然后我们在buffer pool的内部又可以分为几个区域。
所以我们来看看buffer pool的内部结构是什么样的?
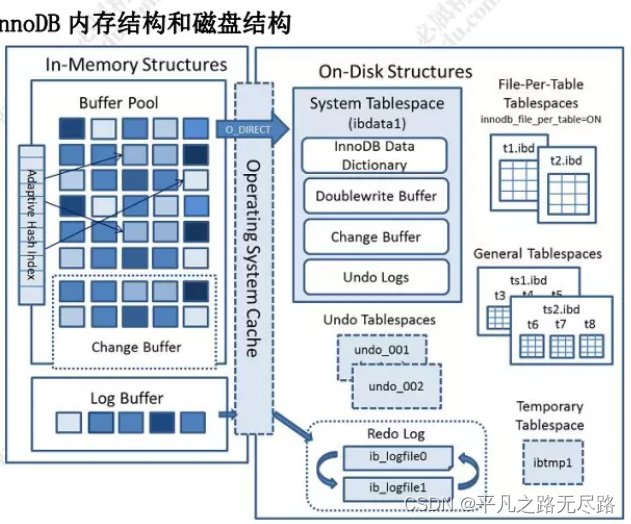
这张图我们可以看到,inner DB这张图他分成一个内存的结构和磁盘的结构。比较总要一张图。
这里面最终要的一块区域就是我么说的buffer pool区域。
他是为了提升我们查询和修改数据的性能。
数据库-sql执行深度剖析以及redo log和undo log(下)(二)_平凡之路无尽路的博客-CSDN博客