💡 作者:韩信子@ShowMeAI
📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40
📘 本文地址:https://www.showmeai.tech/article-detail/394
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容
如果你是数据科学家、数据分析师、机器学习工程师,或者任何 python 数据从业者,你一定会高频使用 pandas 这个工具库——它操作简单功能强大,可以很方便完成数据处理、数据分析、数据变换等过程,优雅且便捷。
📘 Python数据分析实战教程

在本文中,ShowMeAI给大家汇总介绍 21 个 Pandas 的提示和技巧,熟练掌握它们,可以让我们的代码保持整洁高效。
💡 1:DataFrame.copy()
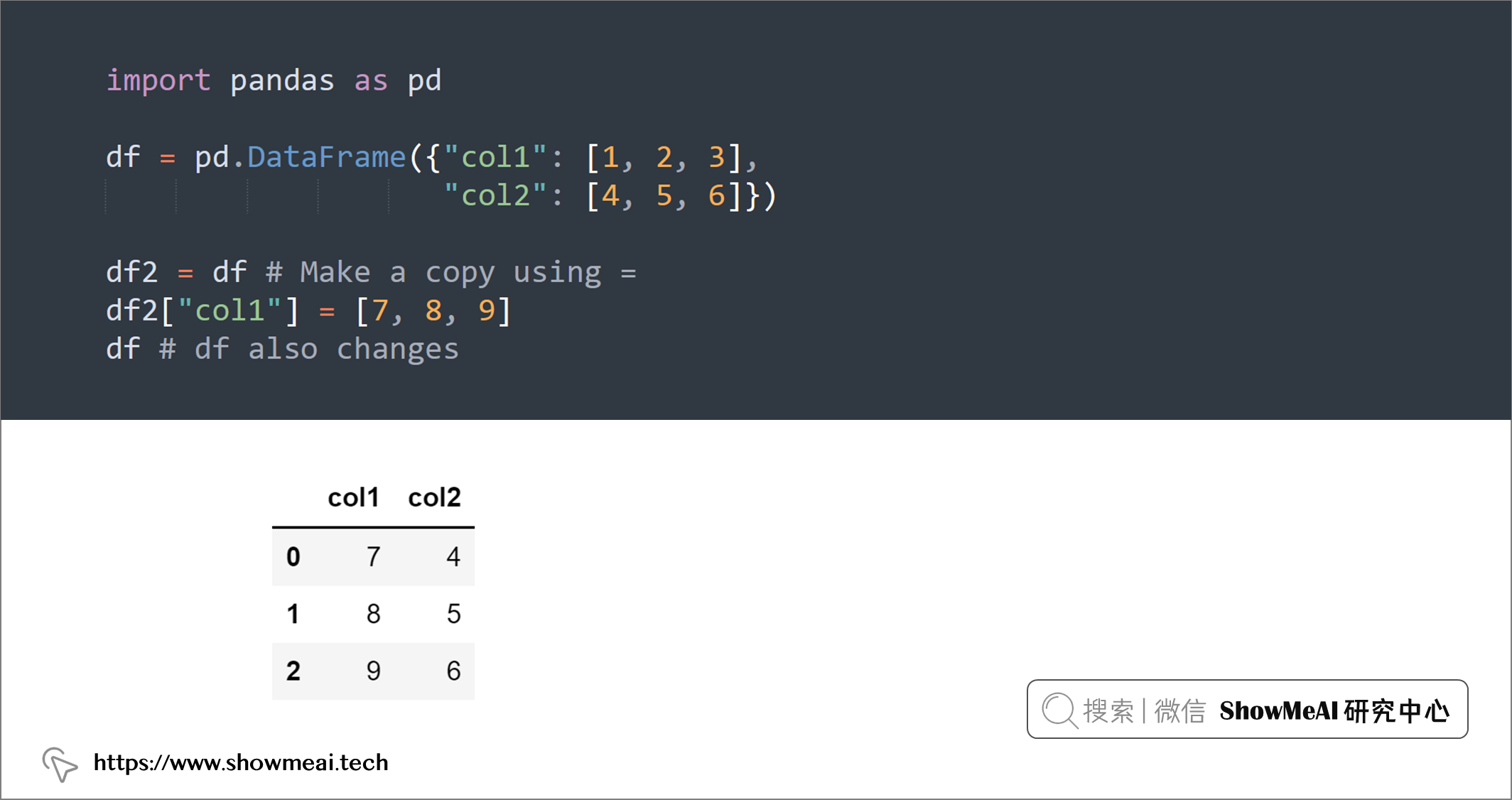
如果我们希望对DataFrame操作,但是不希望改变原始DataFrame,我们可以使用df.copy()制作副本,如下例所示:
import pandas as pd
df = pd.DataFrame({"col1": [1, 2, 3],
"col2": [4, 5, 6]})
df2 = df # Make a copy using =
df2["col1"] = [7, 8, 9]
df # df also changes
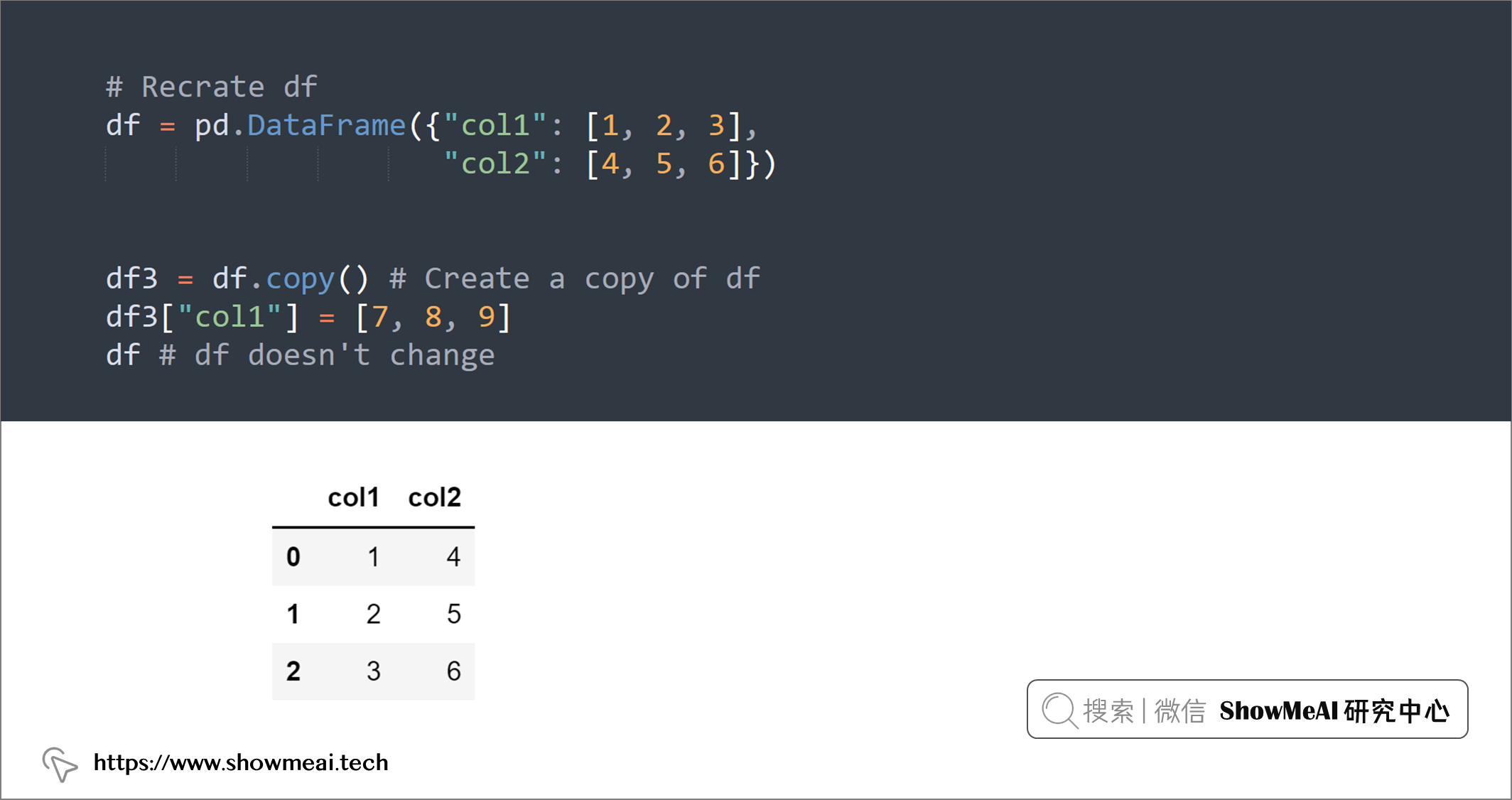
# Recrate df
df = pd.DataFrame({"col1": [1, 2, 3],
"col2": [4, 5, 6]})
df3 = df.copy() # Create a copy of df
df3["col1"] = [7, 8, 9]
df # df doesn't change
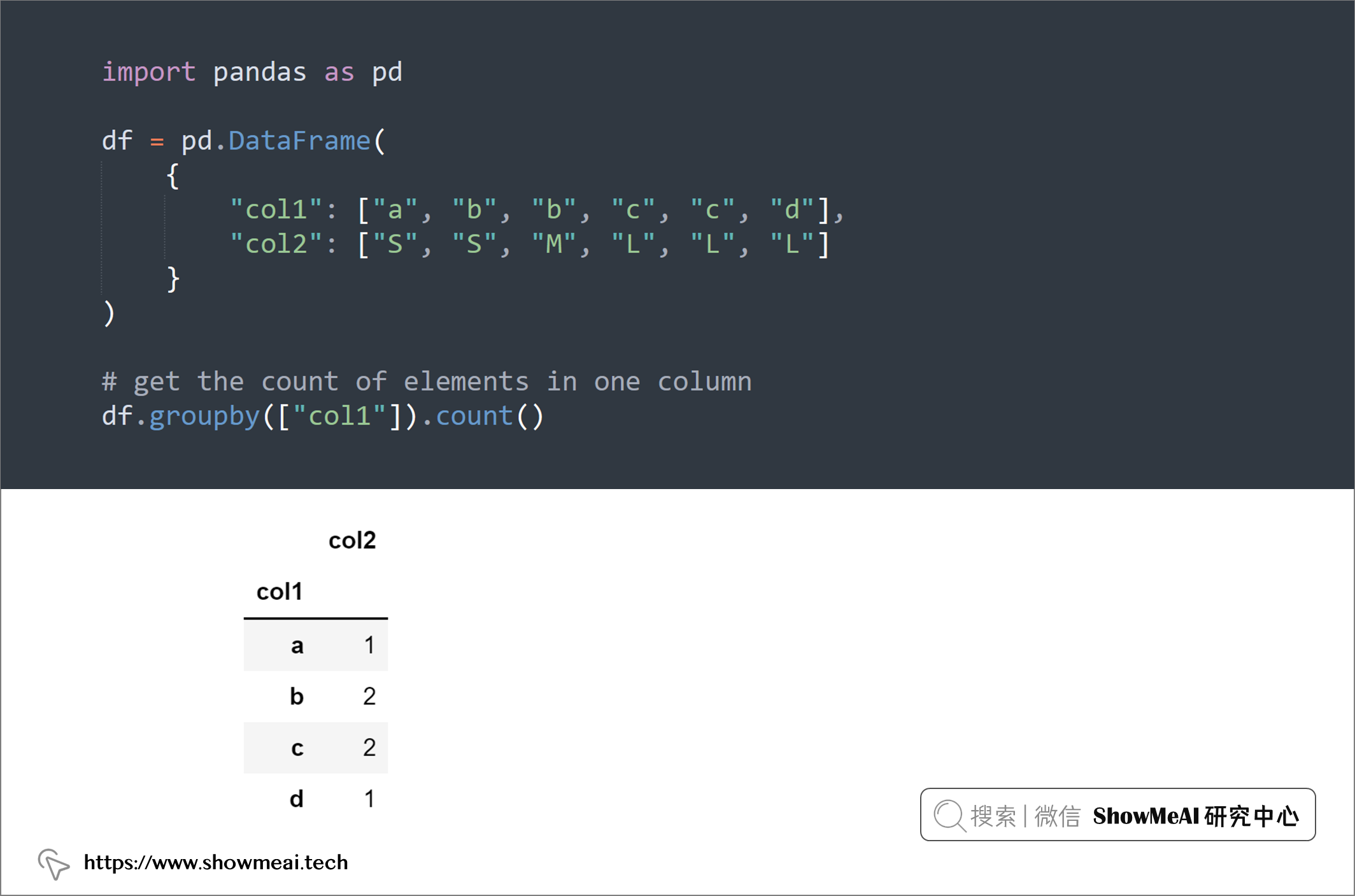
💡 2:Groupby().count 与 Groupby().size
如果你想获得 Pandas 的一列的计数统计,可以使用groupby和count组合,如果要获取2列或更多列组成的分组的计数,可以使用groupby和size组合。如下所示:
import pandas as pd
df = pd.DataFrame(
{
"col1": ["a", "b", "b", "c", "c", "d"],
"col2": ["S", "S", "M", "L", "L", "L"]
}
)
# get the count of elements in one column
df.groupby(["col1"]).count()
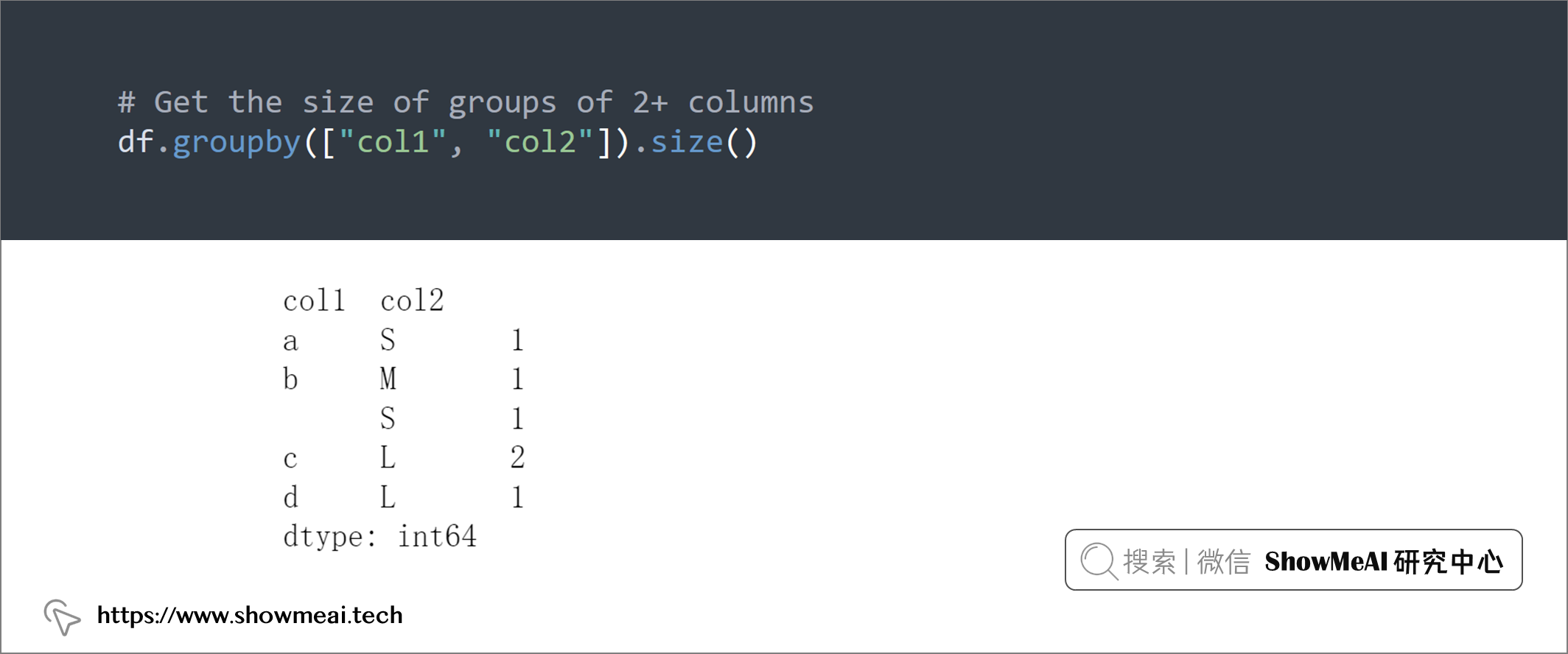
# Get the size of groups of 2+ columns
df.groupby(["col1", "col2"]).size()
💡 3:归一化值计数
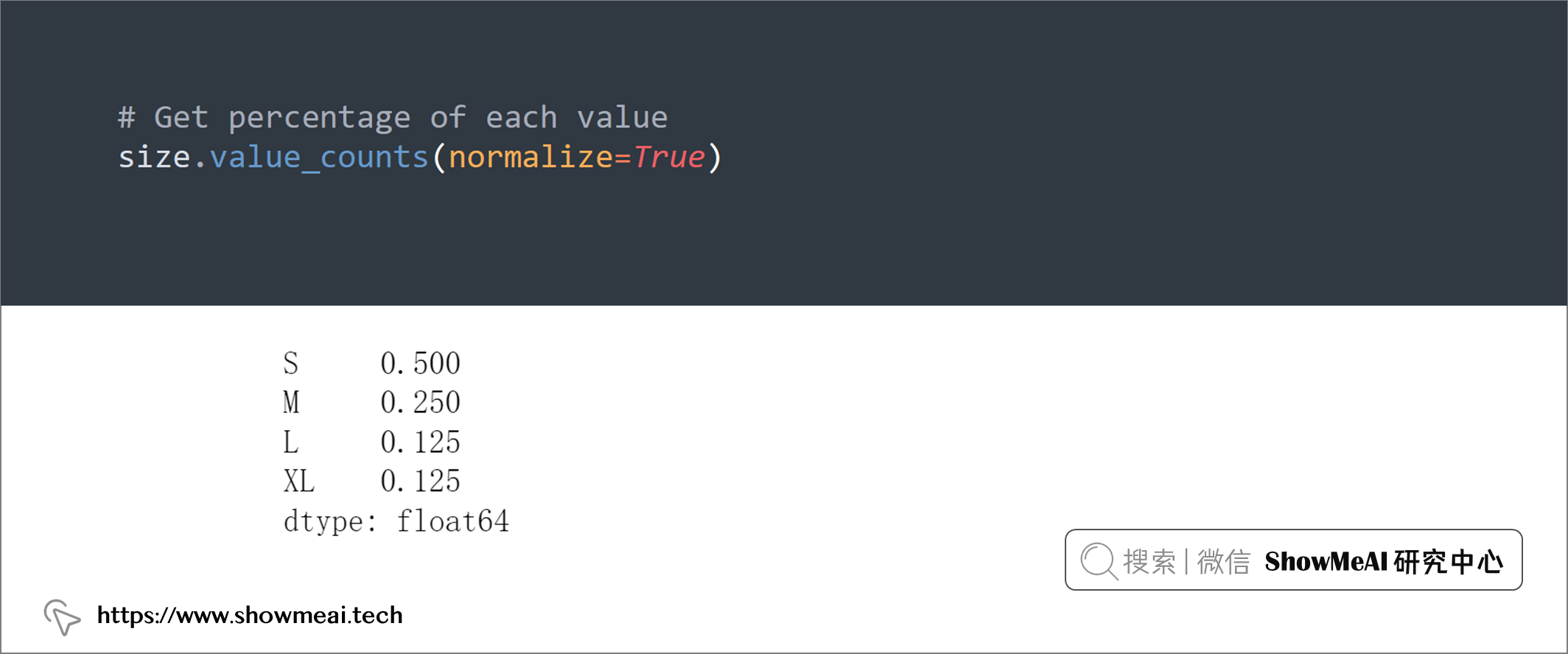
大家都知道,我们可以使用value_counts获取列里的取值计数,但是,如果要获取列中某个值的百分比,我们可以添加normalize=True至value_counts参数设置来完成:
import pandas as pd
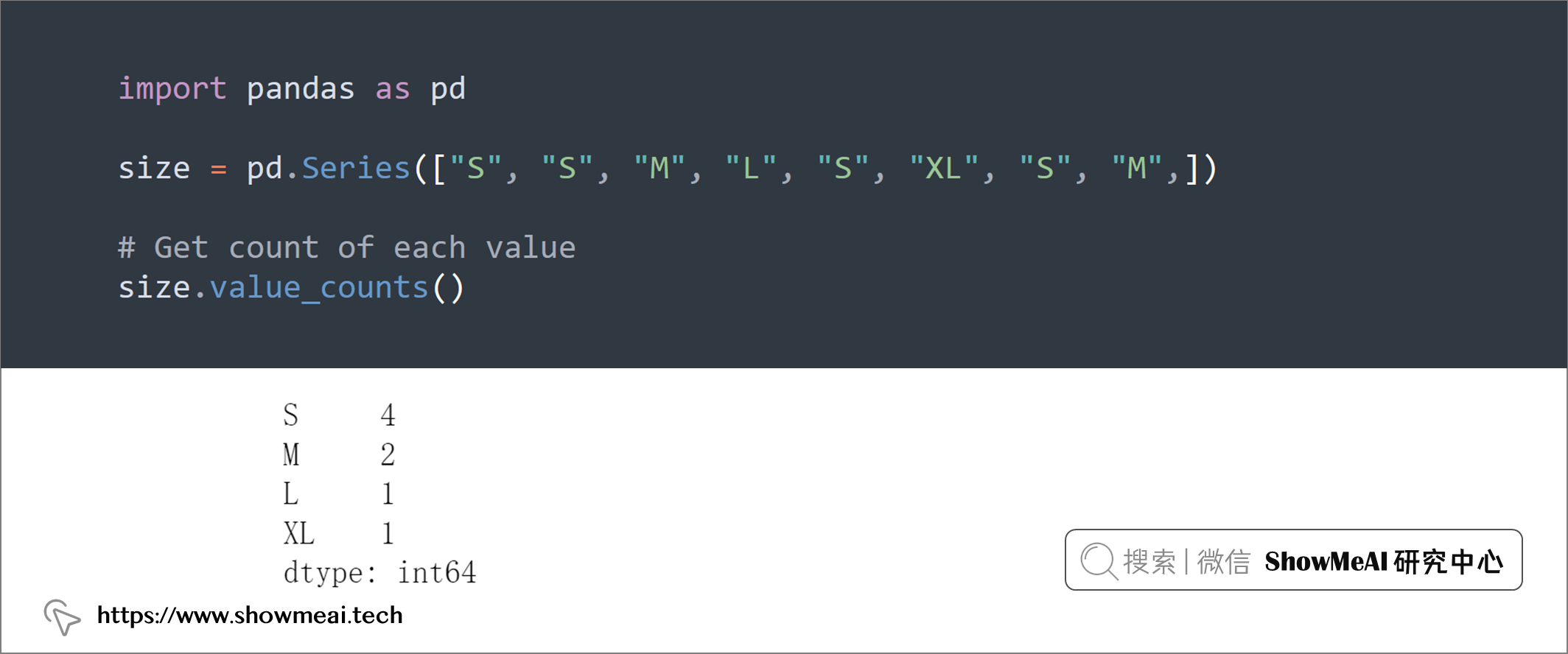
size = pd.Series(["S", "S", "M", "L", "S", "XL", "S", "M",])
# Get count of each value
size.value_counts()
# Get percentage of each value
size.value_counts(normalize=True)
💡 4:值计数(包含缺失值)
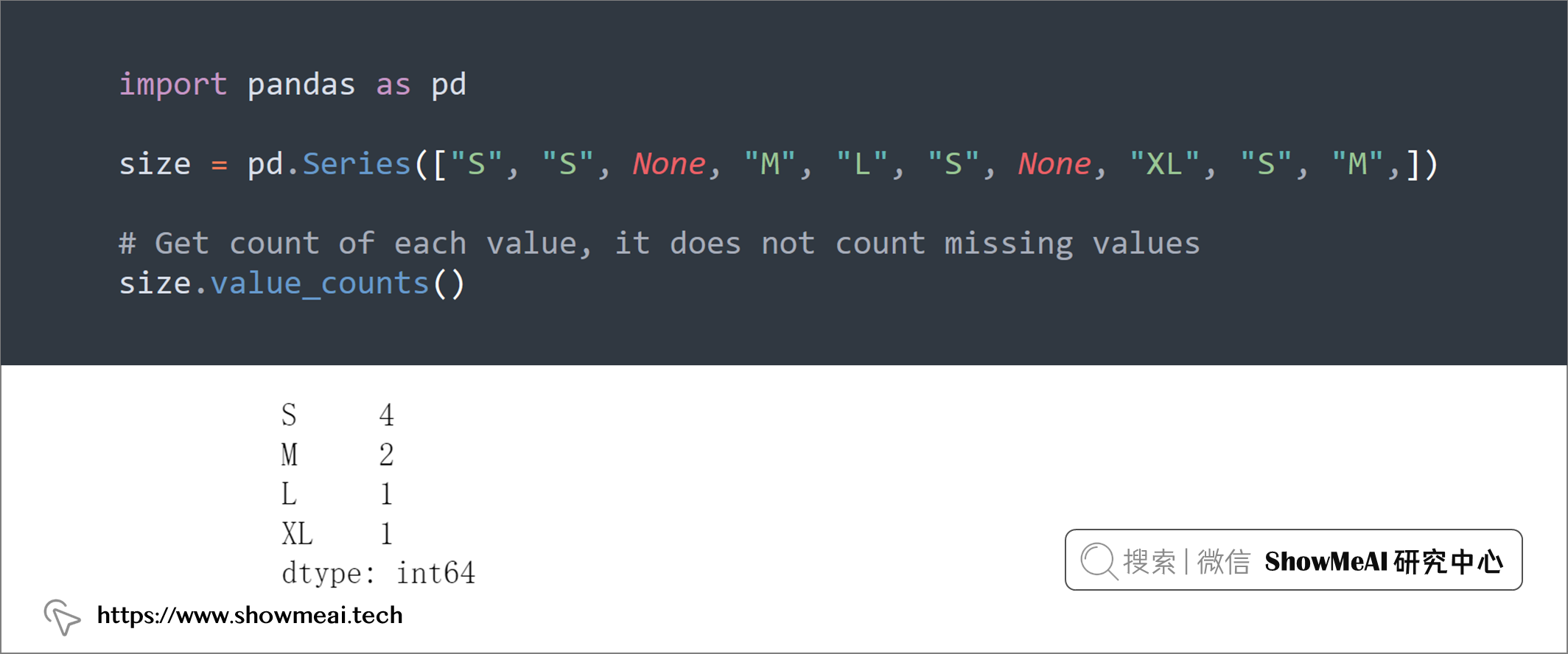
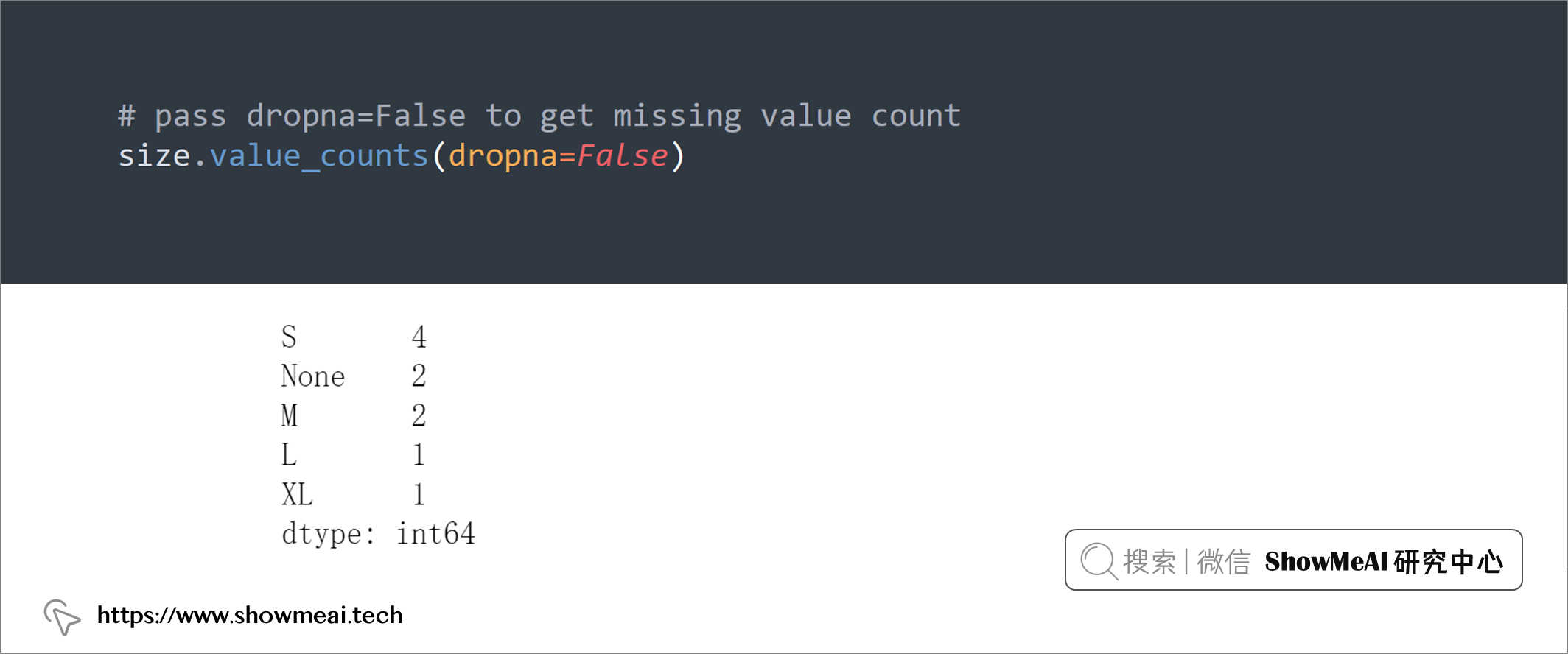
我们知道可以通过value_counts很方便进行字段取值计数,但是pandas.value_counts()自动忽略缺失值,如果要对缺失值进行计数,要设置参数dropna=False。
import pandas as pd
size = pd.Series(["S", "S", None, "M", "L", "S", None, "XL", "S", "M",])
# Get count of each value, it does not count missing values
size.value_counts()
# pass dropna=False to get missing value count
size.value_counts(dropna=False)
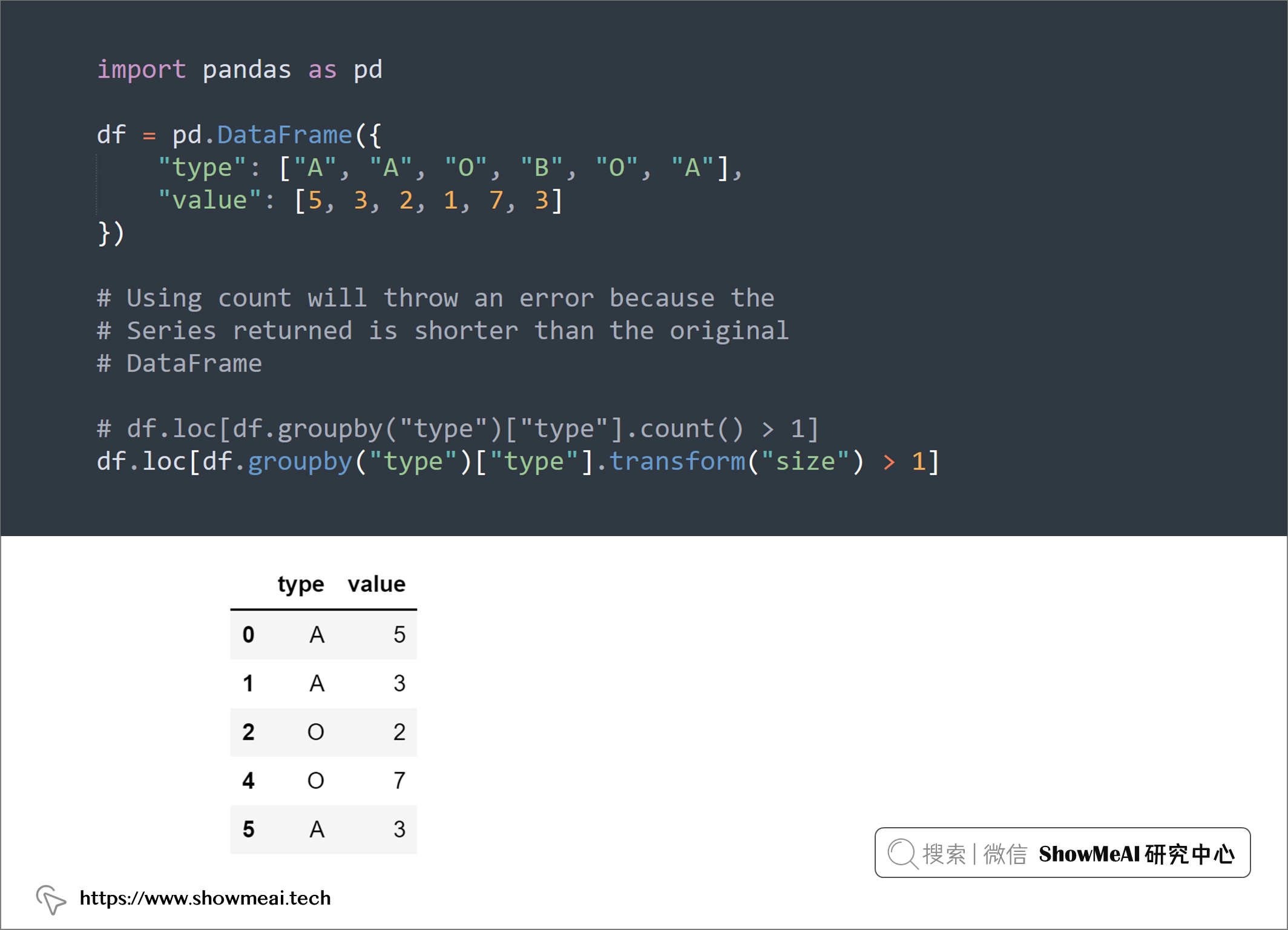
💡 5:df.transform() 与 df.count()
如下例所示,如果我们要对列的取值统计并进行计数过滤,使用count会报错,使用transform是恰当的方法,如下例所示:
import pandas as pd
df = pd.DataFrame({
"type": ["A", "A", "O", "B", "O", "A"],
"value": [5, 3, 2, 1, 7, 3]
})
# Using count will throw an error because the
# Series returned is shorter than the original
# DataFrame
# df.loc[df.groupby("type")["type"].count() > 1]
df.loc[df.groupby("type")["type"].transform("size") > 1]
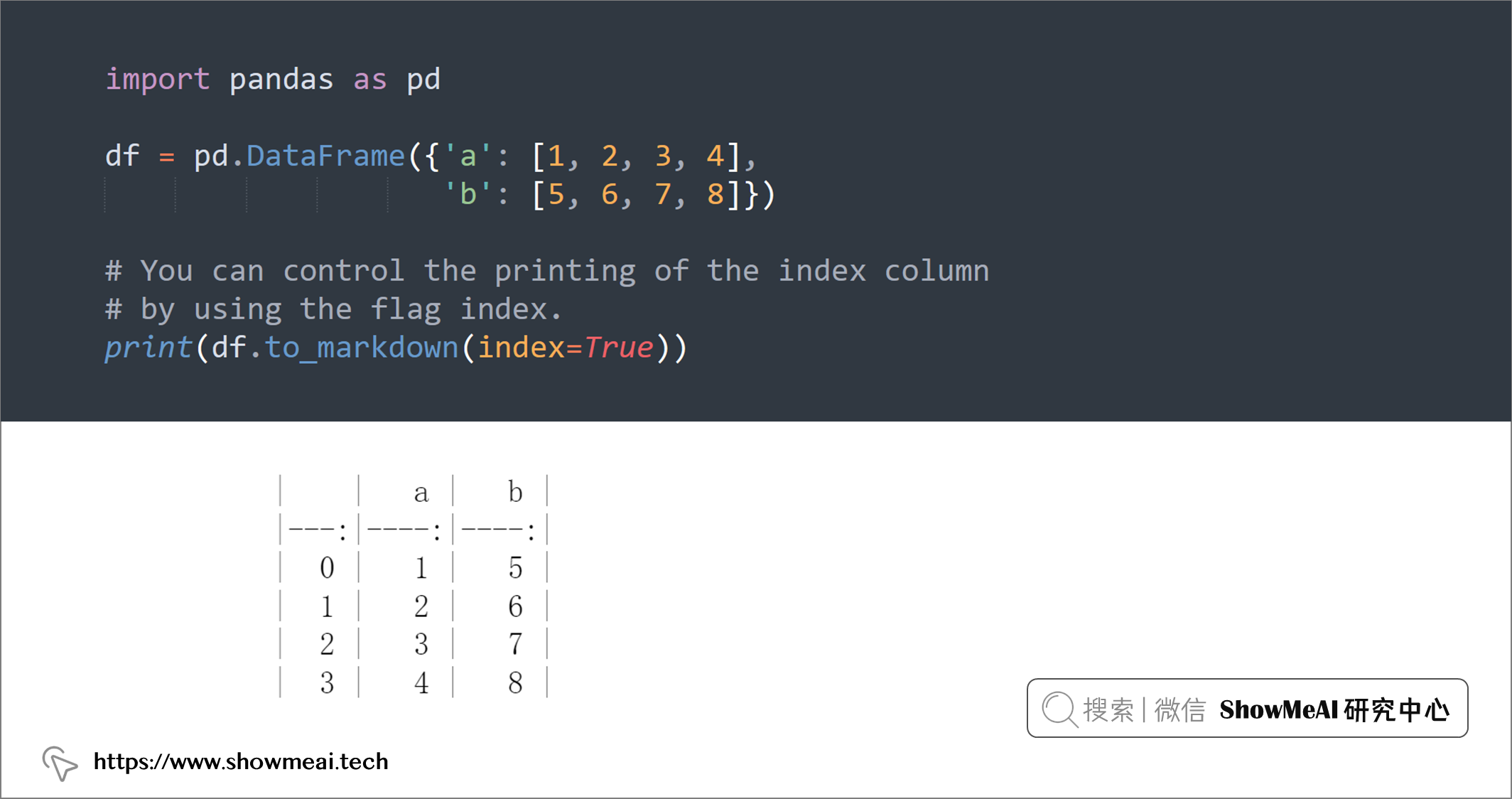
💡 6:打印Markdown表格
Markdown 是一种轻量级标记语言,用于使用纯文本编辑器创建格式化文本。我们有时候会想在 markdown 格式中打印一个DataFrame,这时可以使用to_markdown()功能:
import pandas as pd
df = pd.DataFrame({'a': [1, 2, 3, 4],
'b': [5, 6, 7, 8]})
# You can control the printing of the index column
# by using the flag index.
print(df.to_markdown(index=True))
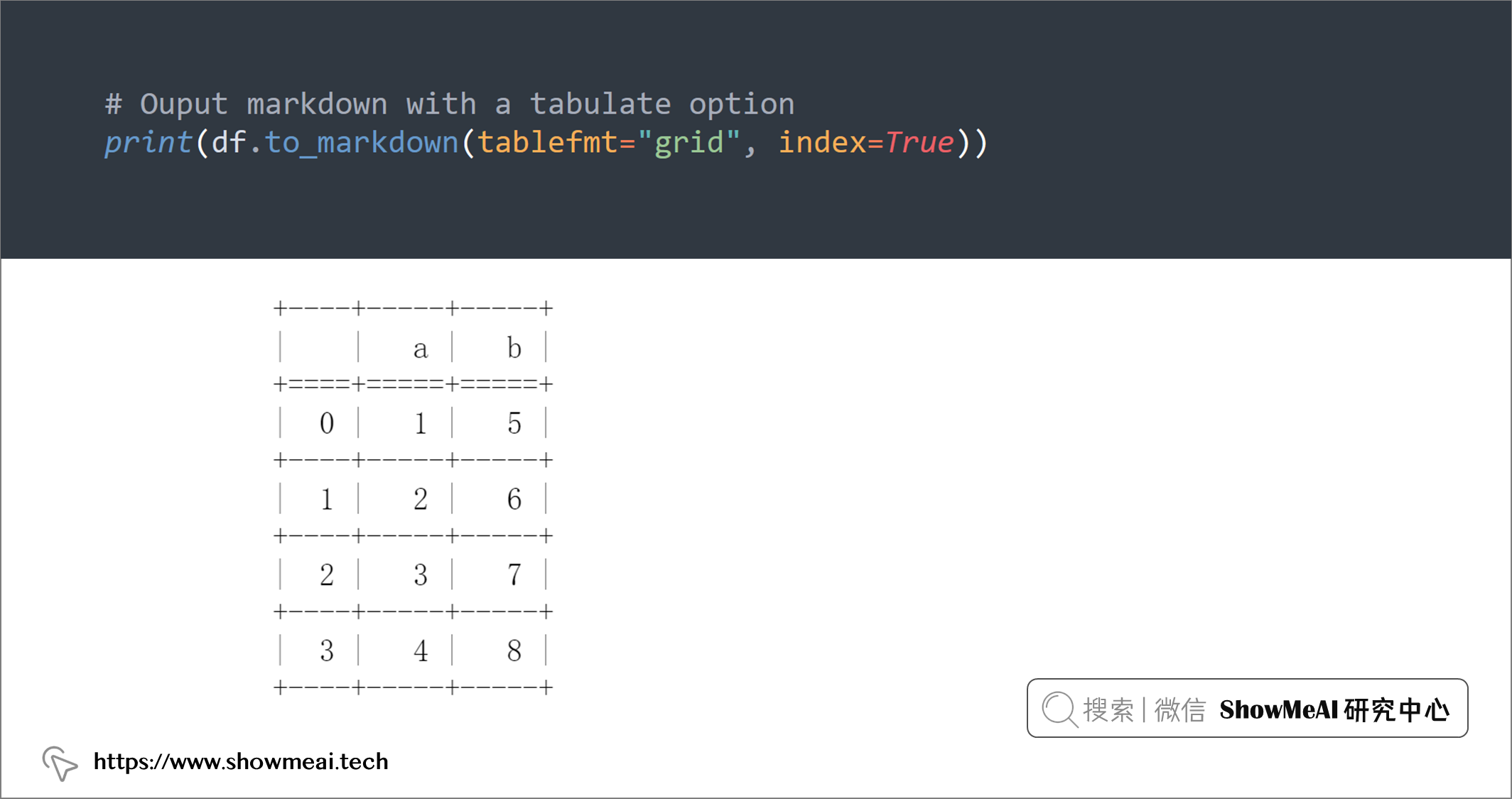
# Ouput markdown with a tabulate option
print(df.to_markdown(tablefmt="grid", index=True))
# To create a markdown file from the dataframe, pass
# the file name as paramters
df.to_markdown("README.md", tablefmt="grid", index=True)
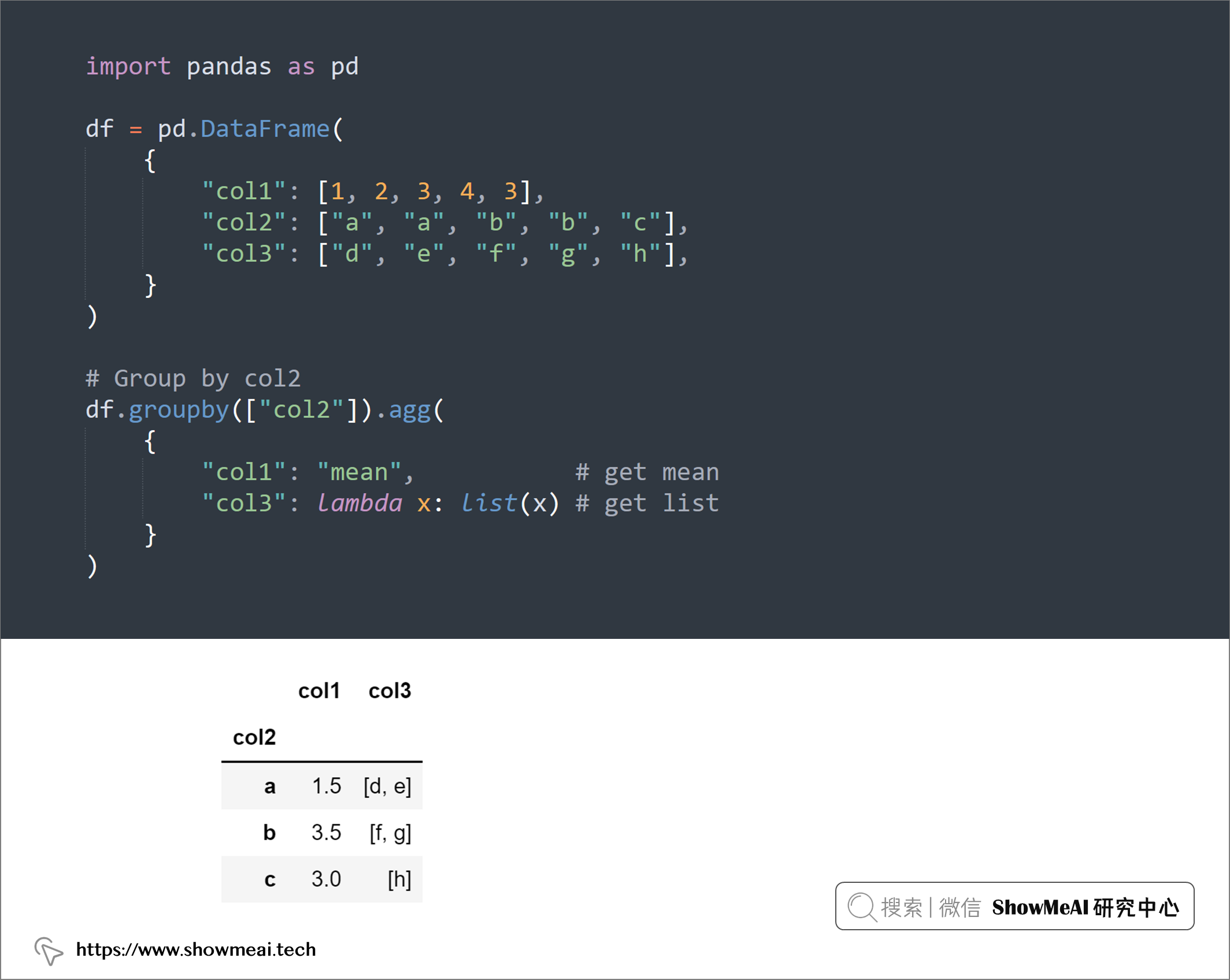
💡 7:将分组后字段聚合为列表
我们经常会使用groupby对数据进行分组并统计每组的聚合统计信息,例如计数、平均值、中位数等。如果您想将分组后的数据字段整合成列表,可以使用lambda x:list(x),如下示例:
import pandas as pd
df = pd.DataFrame(
{
"col1": [1, 2, 3, 4, 3],
"col2": ["a", "a", "b", "b", "c"],
"col3": ["d", "e", "f", "g", "h"],
}
)
# Group by col2
df.groupby(["col2"]).agg(
{
"col1": "mean", # get mean
"col3": lambda x: list(x) # get list
}
)
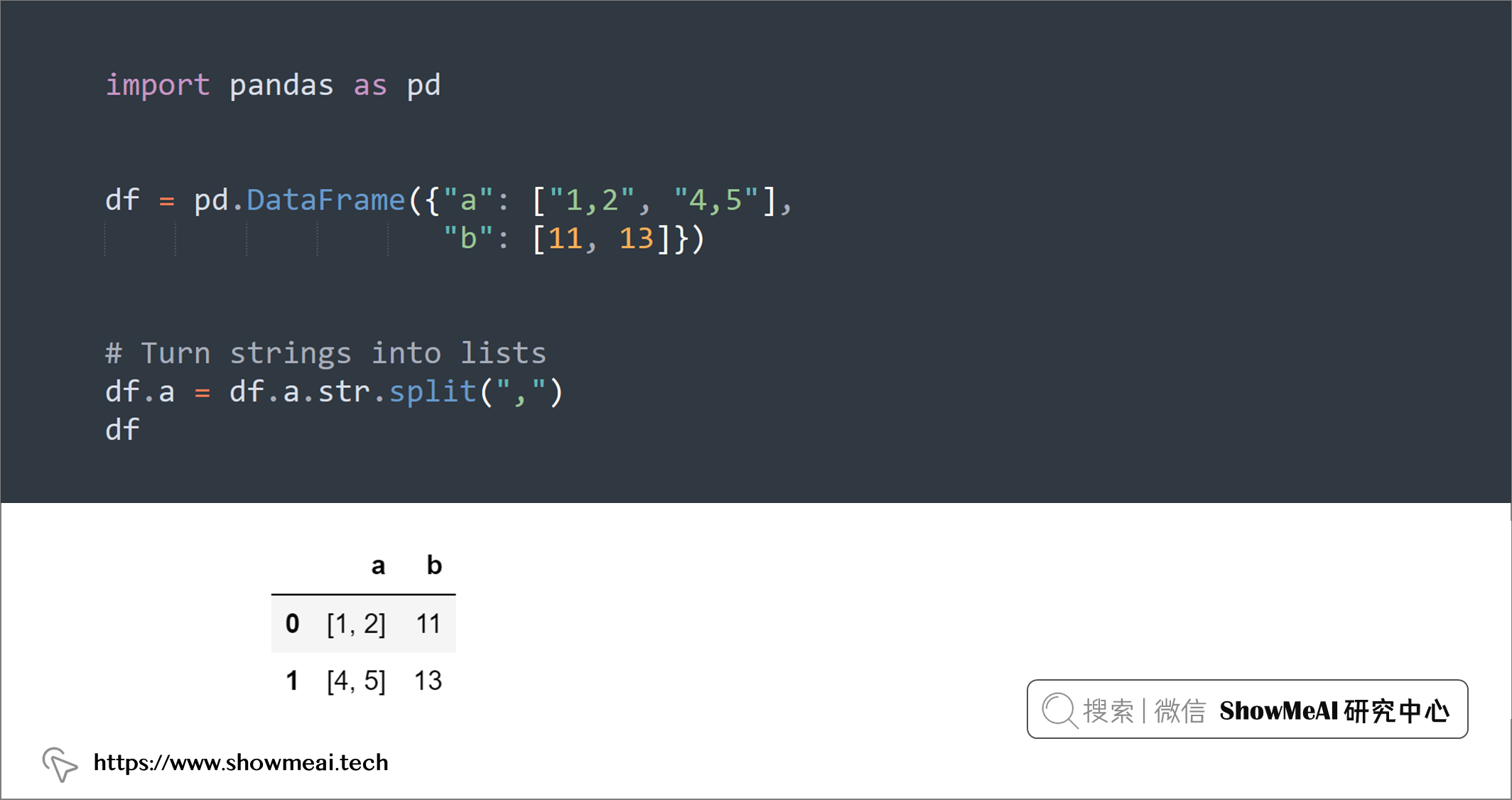
💡 8:DataFrame.explode()
类似于上例,如果你想把一个DataFrame中某个字符串字段(列)展开为一个列表,然后将列表中的元素拆分成多行,可以使用str.split()和explode()组合,如下例:
import pandas as pd
df = pd.DataFrame({"a": ["1,2", "4,5"],
"b": [11, 13]})
# Turn strings into lists
df.a = df.a.str.split(",")
df
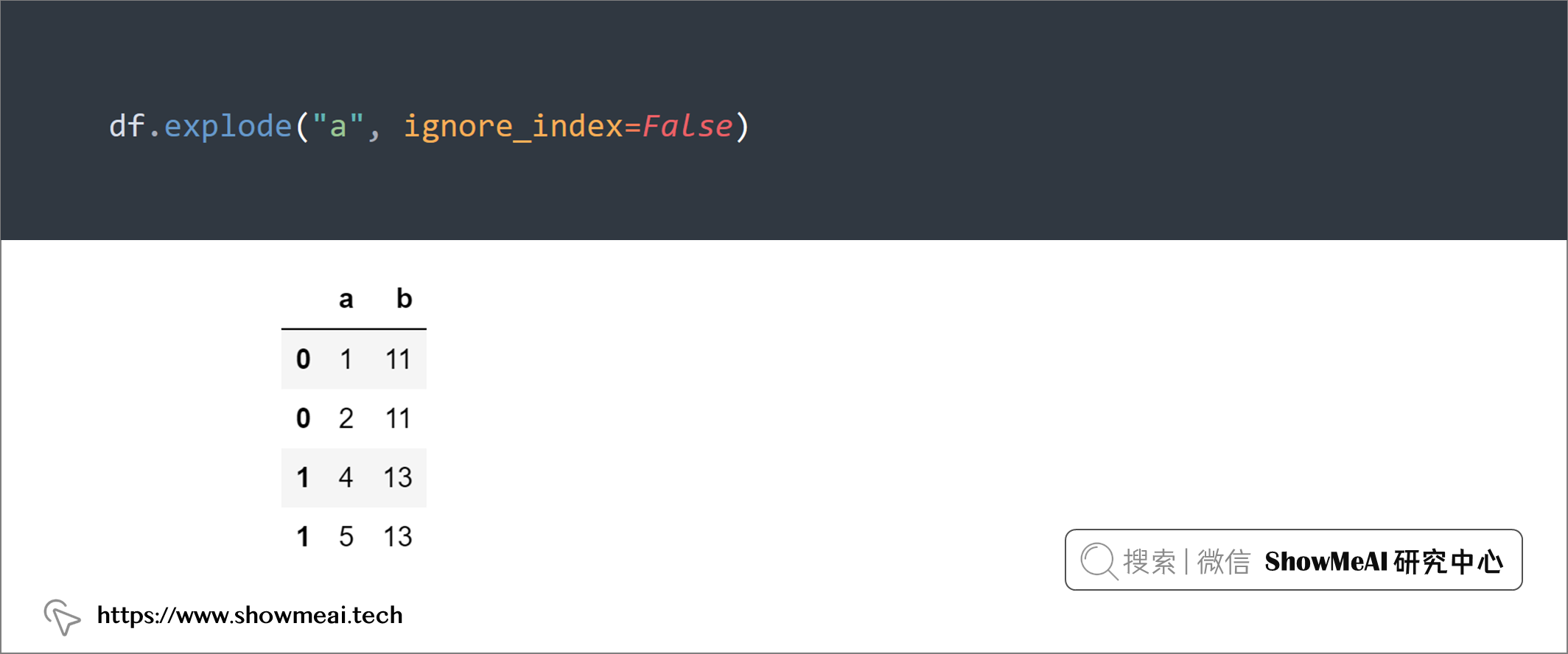
print(df.explode("a", ignore_index=False))
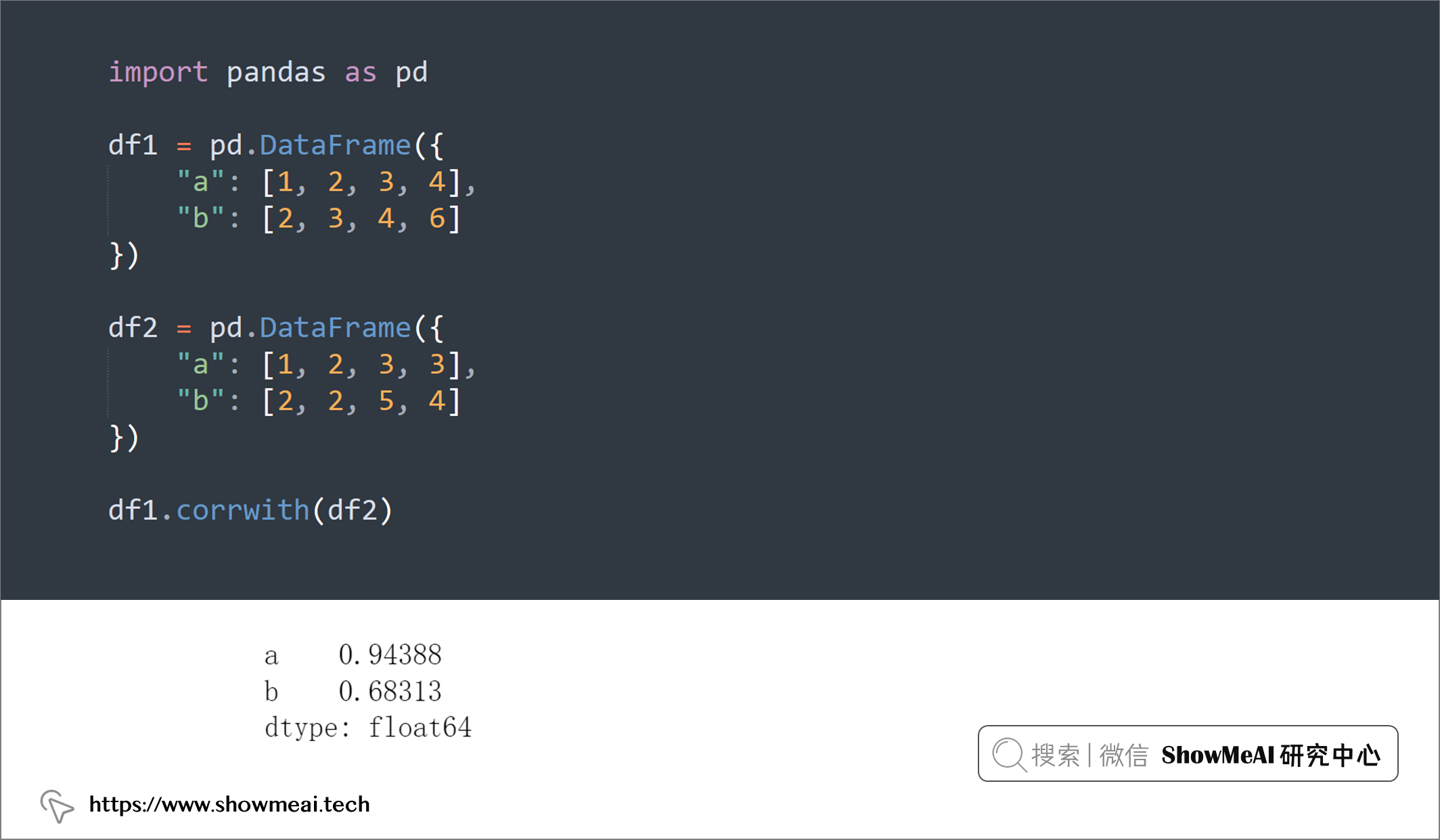
💡 9:数据相关性
如果要计算两个 DataFrame 的行或列之间的相关性,可以使用.corrwith():
import pandas as pd
df1 = pd.DataFrame({
"a": [1, 2, 3, 4],
"b": [2, 3, 4, 6]
})
df2 = pd.DataFrame({
"a": [1, 2, 3, 3],
"b": [2, 2, 5, 4]
})
df1.corrwith(df2)
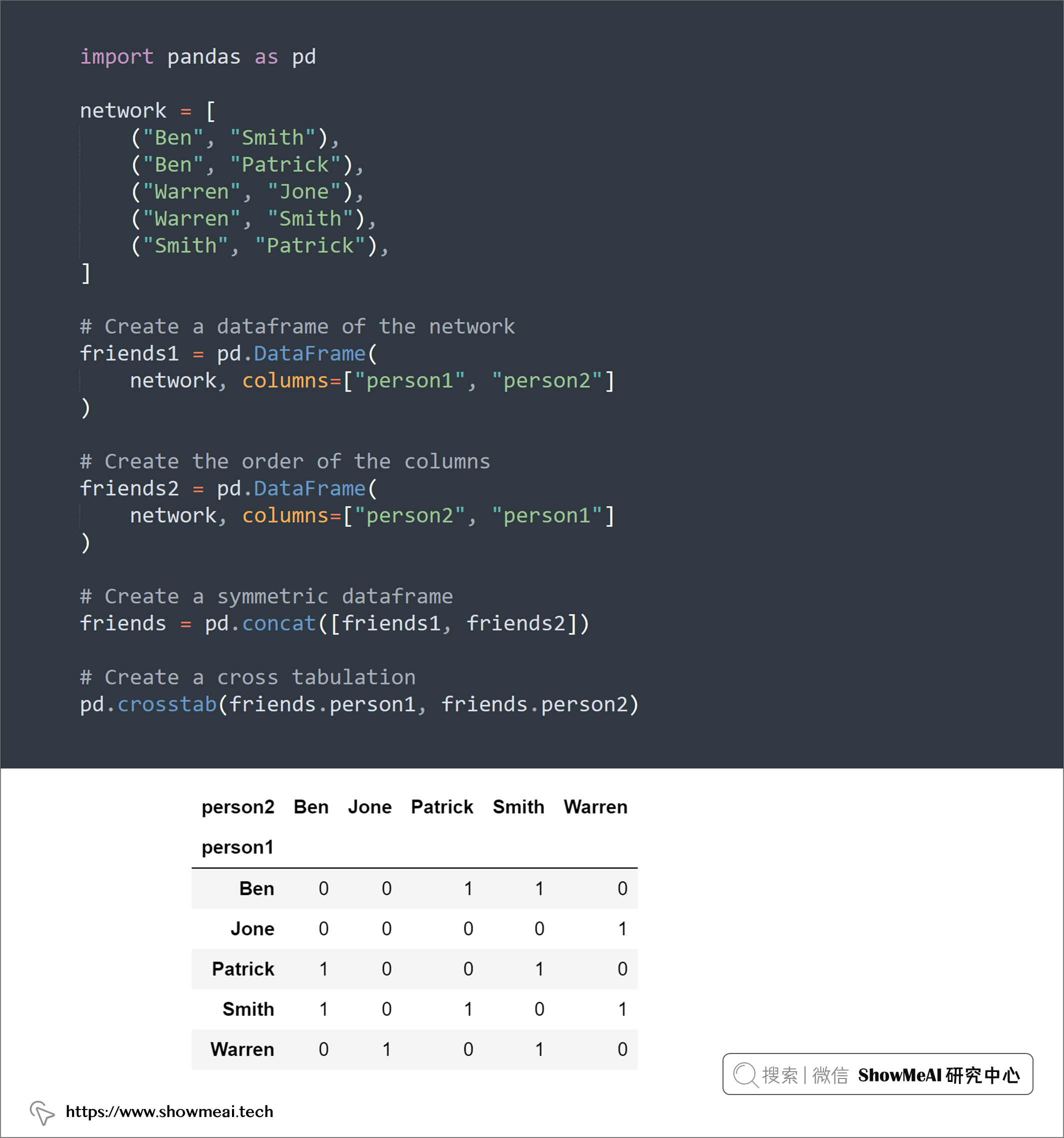
💡 10:交叉制表
交叉制表支持我们分析多个变量之间的关系,可以使用pandas.crosstab()功能:
import pandas as pd
network = [
("Ben", "Smith"),
("Ben", "Patrick"),
("Warren", "Jone"),
("Warren", "Smith"),
("Smith", "Patrick"),
]
# Create a dataframe of the network
friends1 = pd.DataFrame(
network, columns=["person1", "person2"]
)
# Create the order of the columns
friends2 = pd.DataFrame(
network, columns=["person2", "person1"]
)
# Create a symmetric dataframe
friends = pd.concat([friends1, friends2])
# Create a cross tabulation
pd.crosstab(friends.person1, friends.person2)
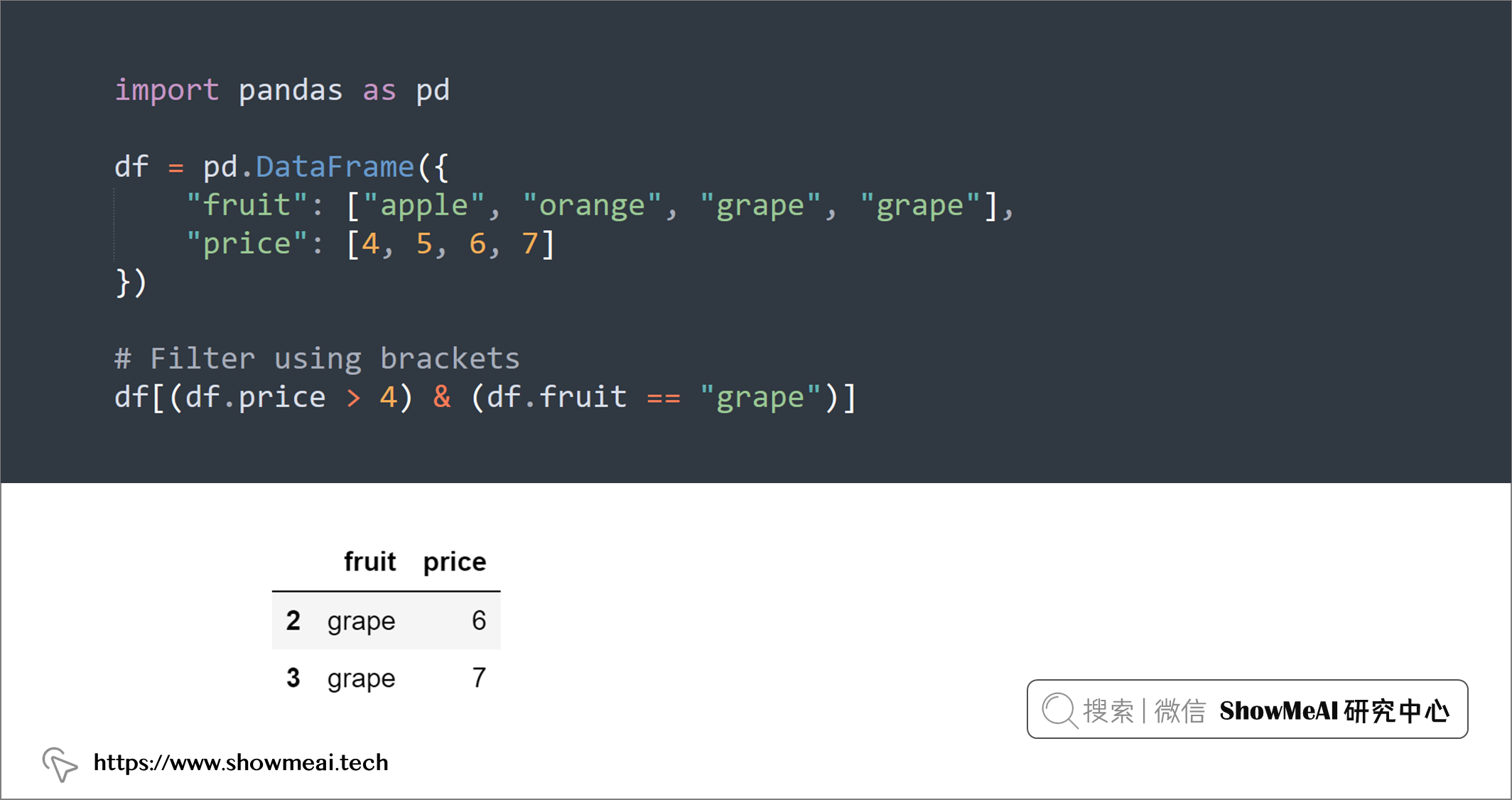
💡 11:DataFrame.query()
我们可以使用df.query()功能进行数据过滤,它支持以简洁的方式叠加很多个条件。
import pandas as pd
df = pd.DataFrame({
"fruit": ["apple", "orange", "grape", "grape"],
"price": [4, 5, 6, 7]
})
# Filter using brackets
df[(df.price > 4) & (df.fruit == "grape")]
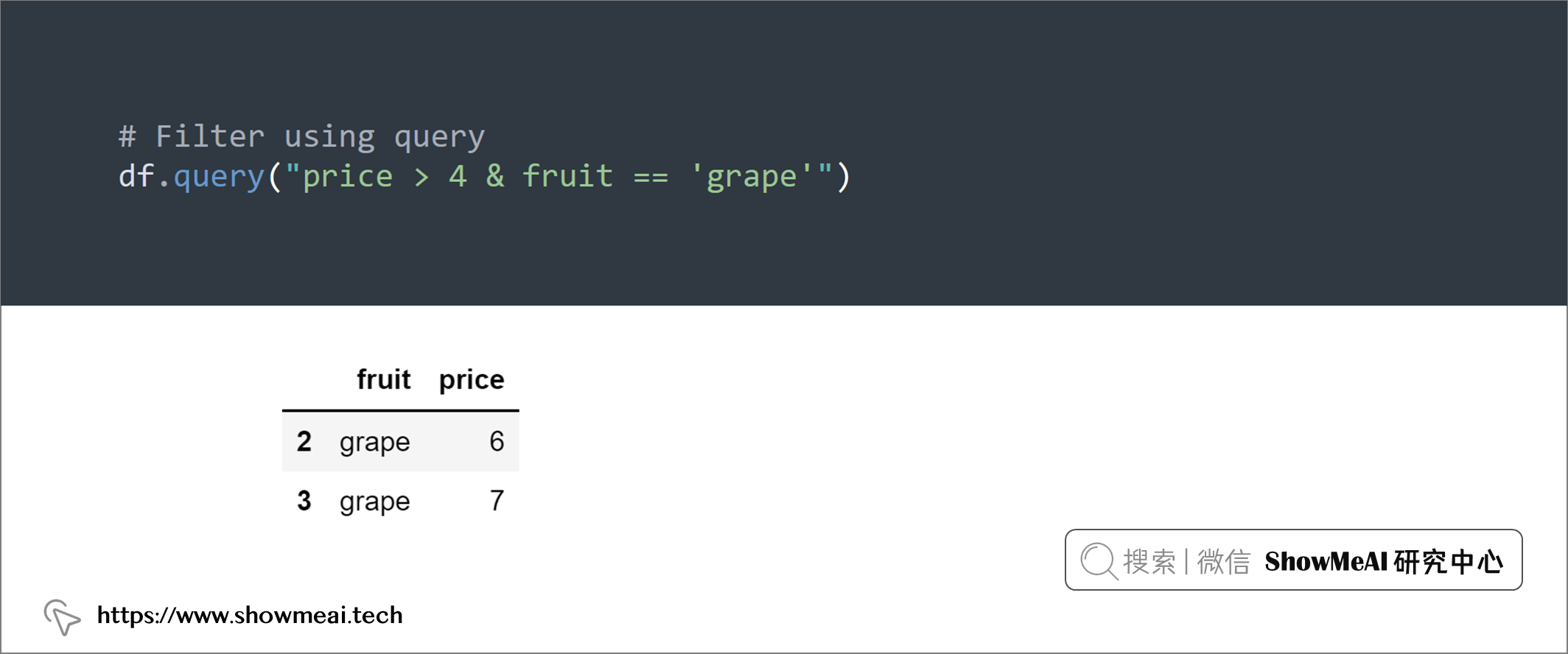
# Filter using query
df.query("price > 4 & fruit == 'grape'")
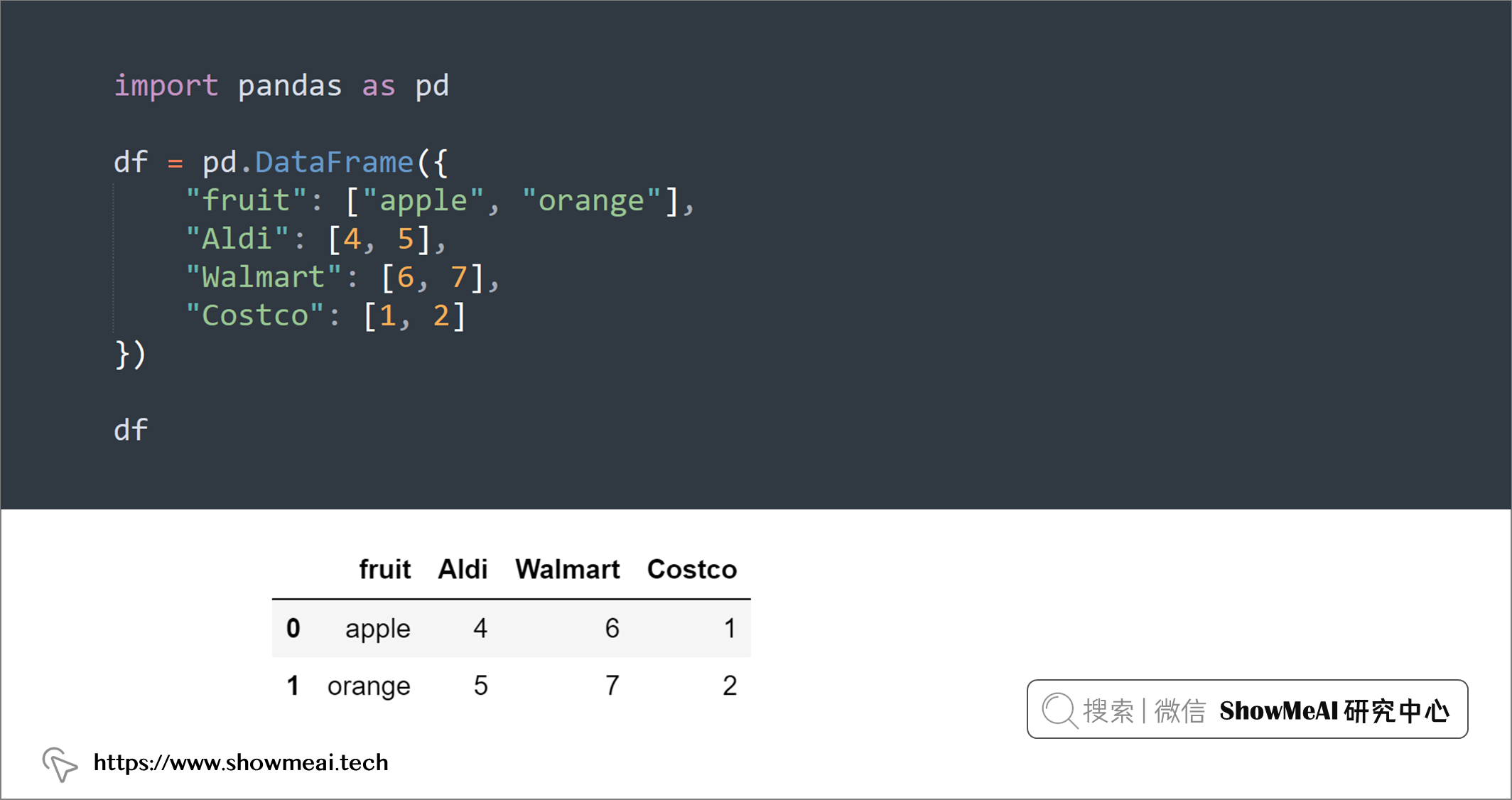
💡 12:逆透视数据表
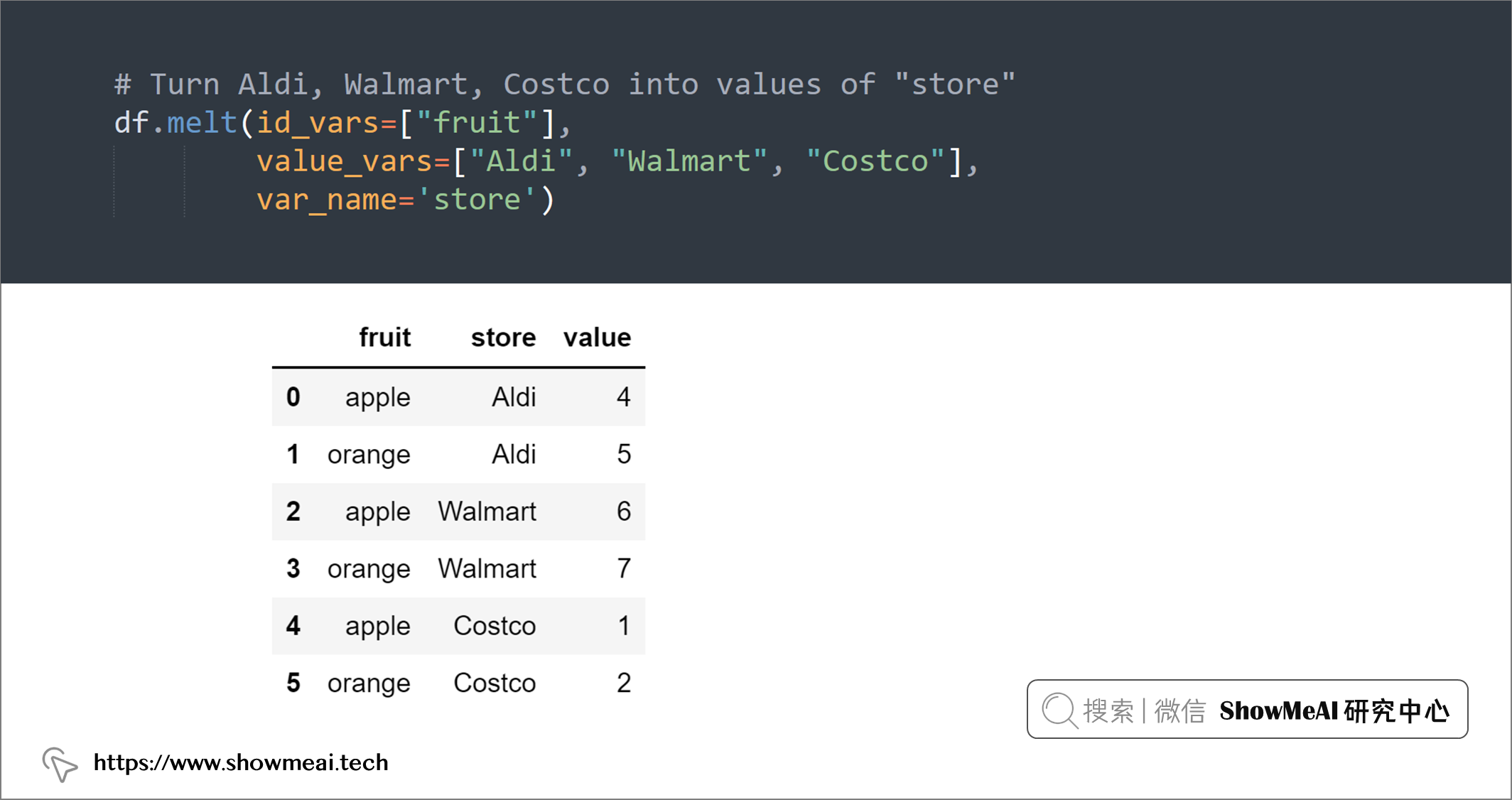
如果要将 DataFrame 从宽表格式转换为长表格式,可以使用pandas.melt()。
- 如下例,我们可以使用
pandas.melt()将多列(“Aldi”、“Walmart”、“Costco”)转换为一列(“store”)的值。
import pandas as pd
df = pd.DataFrame({
"fruit": ["apple", "orange"],
"Aldi": [4, 5],
"Walmart": [6, 7],
"Costco": [1, 2]
})
df
# Turn Aldi, Walmart, Costco into values of "store"
df.melt(id_vars=["fruit"],
value_vars=["Aldi", "Walmart", "Costco"],
var_name='store')
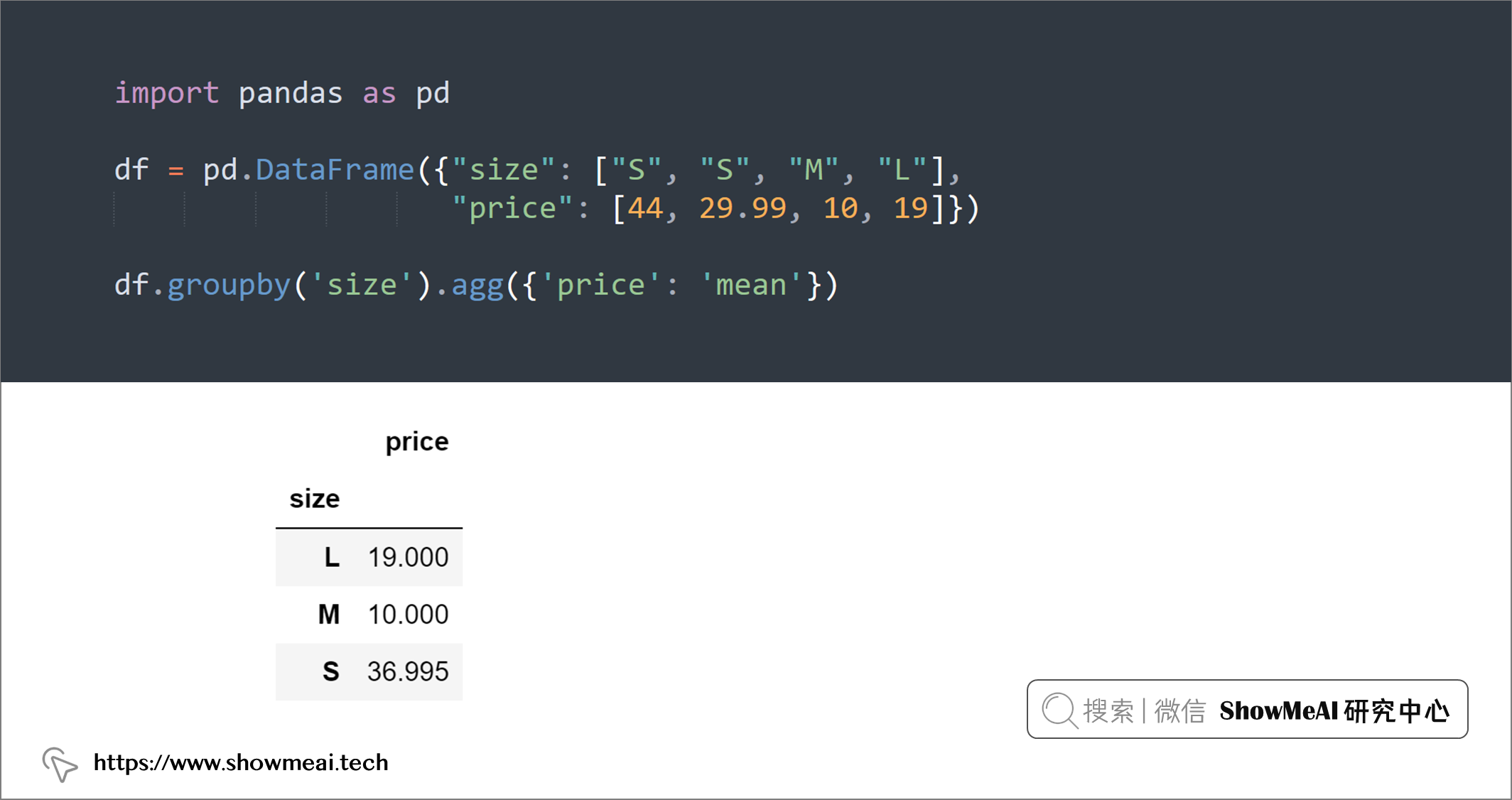
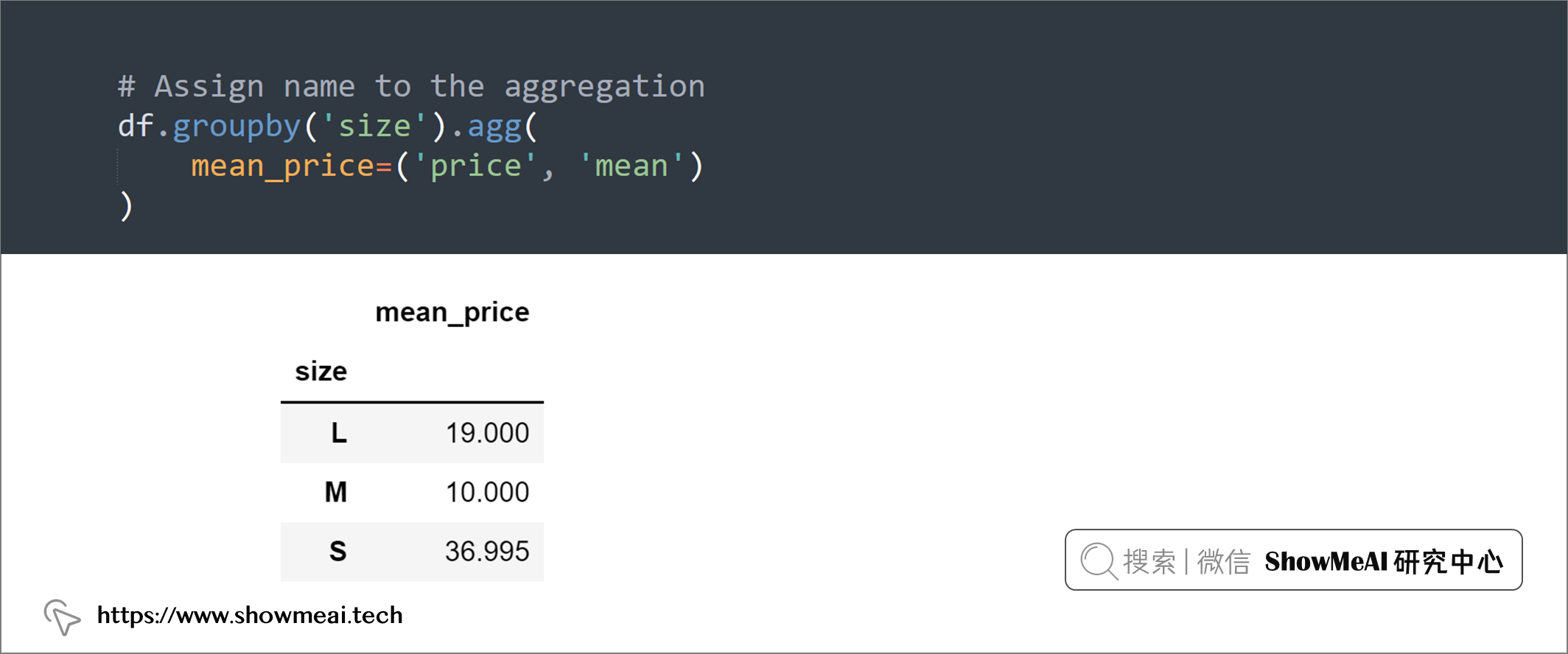
💡 13:重命名聚合列
我们经常会使用分组聚合的功能,如果要为聚合分配新名称,可以使用name = (column, agg_method)方法:
import pandas as pd
df = pd.DataFrame({"size": ["S", "S", "M", "L"],
"price": [44, 29.99, 10, 19]})
df.groupby('size').agg({'price': 'mean'})
# Assign name to the aggregation
df.groupby('size').agg(
mean_price=('price', 'mean')
)
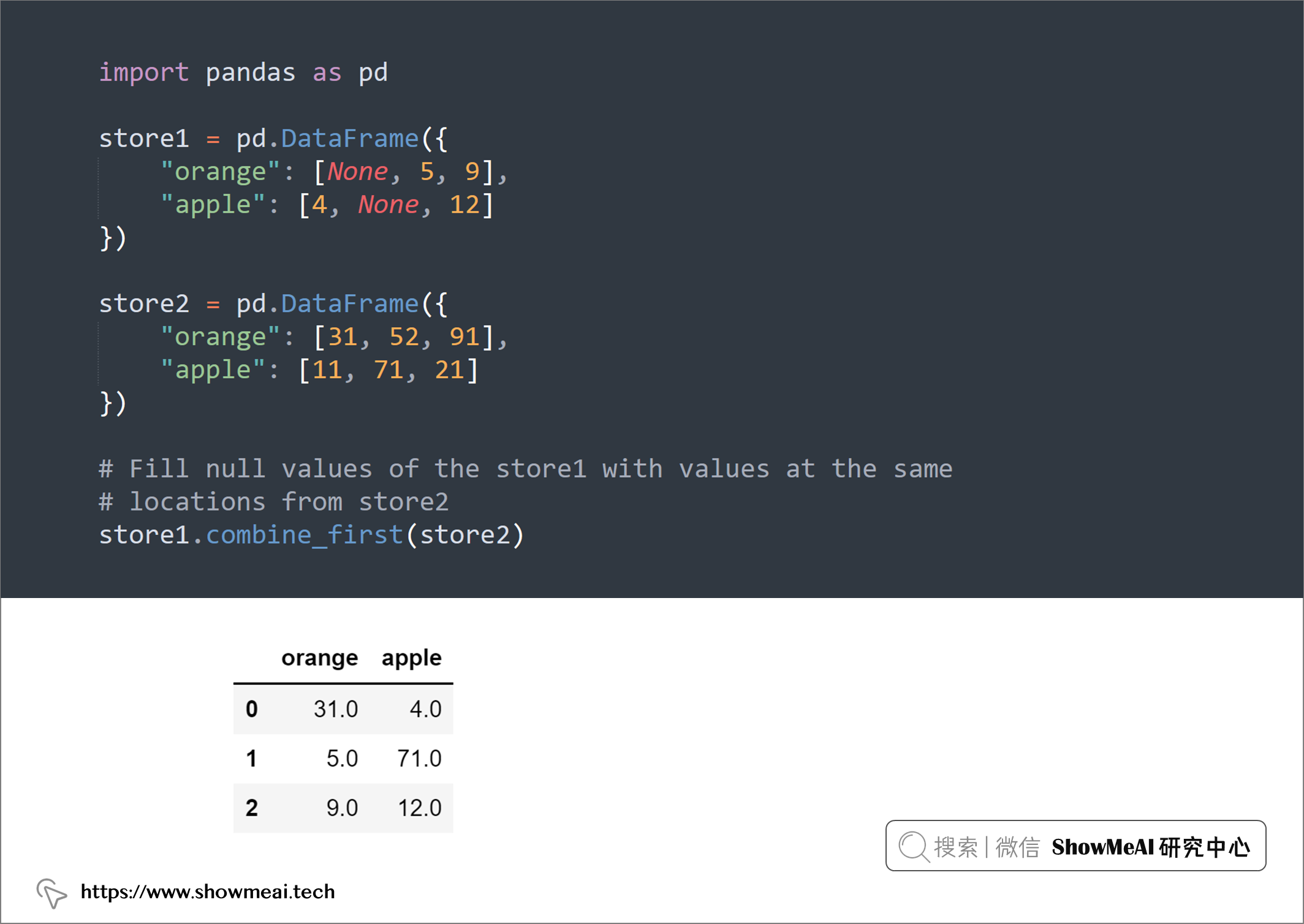
💡 14:填充空值
pandas.DataFrame.combine_first对两个 DataFrame 进行联合操作,实现合并的功能。
combine_first()方法根据 DataFrame 的行索引和列索引,对比两个 DataFrame 中相同位置的数据,优先取非空的数据进行合并。
如果调用combine_first()方法的 df1 中数据非空,则结果保留 df1 中的数据,如果 df1 中的数据为空值且传入combine_first()方法的 df2 中数据非空,则结果取 df2 中的数据,如果 df1 和 df2 中的数据都为空值,则结果保留 df1 中的空值(空值有三种:np.nan、None 和 pd.NaT)。
即使两个 DataFrame 的形状不相同也不受影响,联合时主要是根据索引来定位数据的位置。
import pandas as pd
store1 = pd.DataFrame({
"orange": [None, 5, 9],
"apple": [4, None, 12]
})
store2 = pd.DataFrame({
"orange": [31, 52, 91],
"apple": [11, 71, 21]
})
# Fill null values of the store1 with values at the same
# locations from store2
store1.combine_first(store2)
💡 15:过滤 DataFrame 中的列
我们可以根据名称中的子字符串过滤 pandas DataFrame 的列,具体是使用 pandas 的DataFrame.filter功能。
import pandas as pd
df = pd.DataFrame({'Temp': ['Hot', 'Cold', 'Warm', 'Cold'],
'Degree': [35, 3, 15, 2]})
print(df)
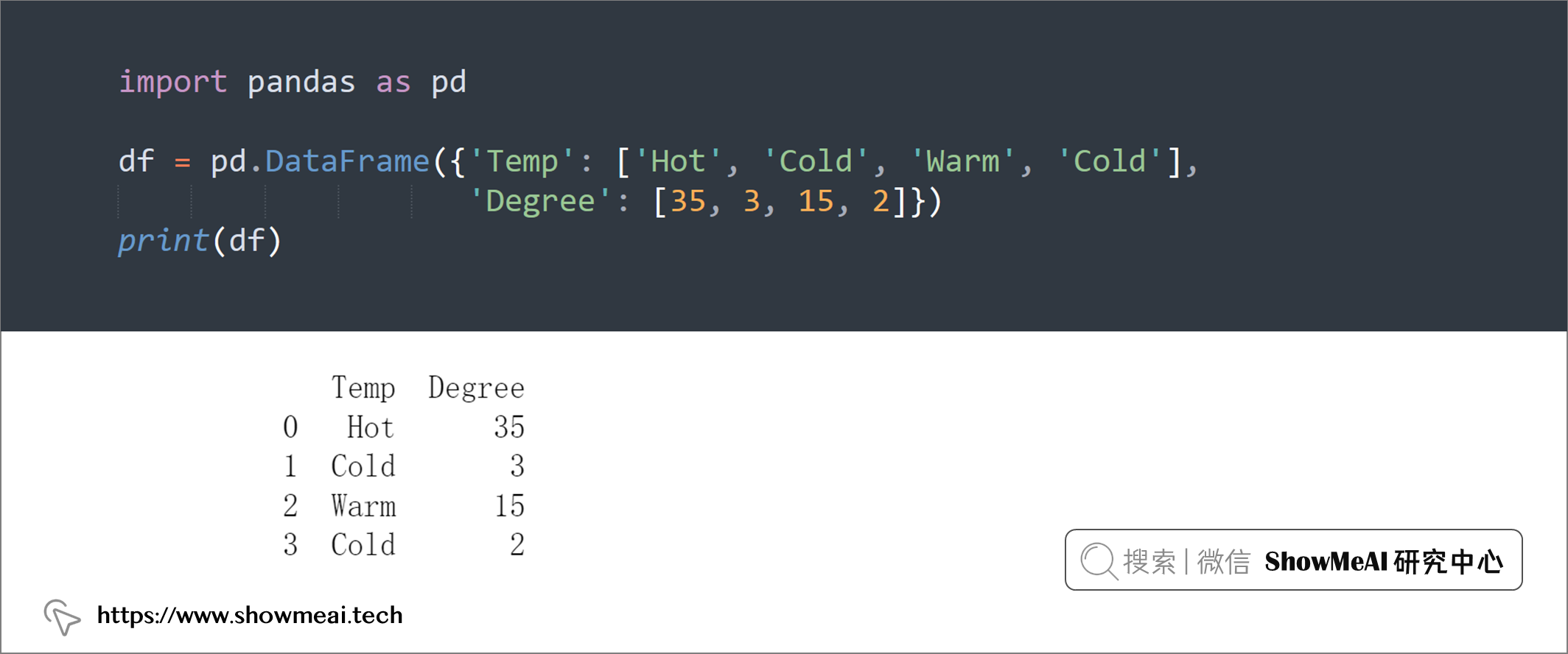
df = pd.get_dummies(df, columns=['Temp'])
print(df)
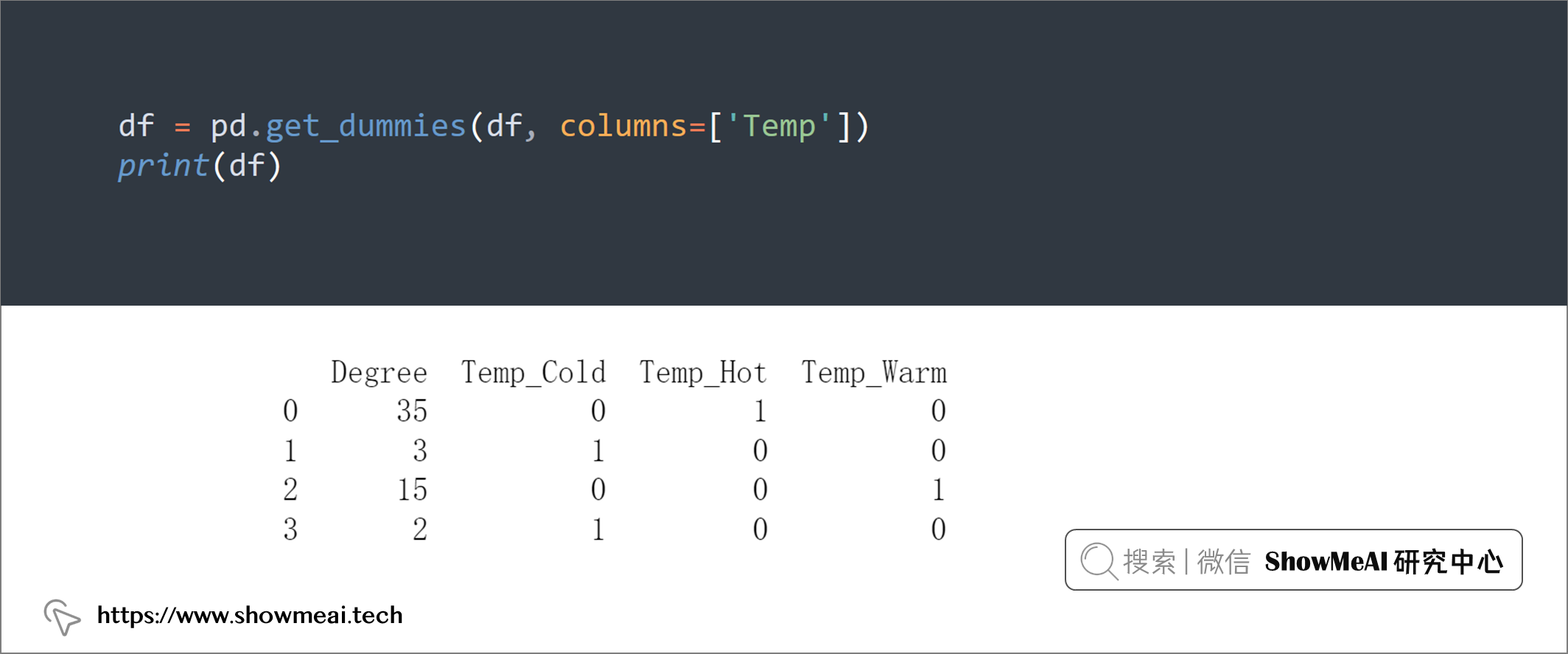
print(df.filter(like='Temp', axis=1))
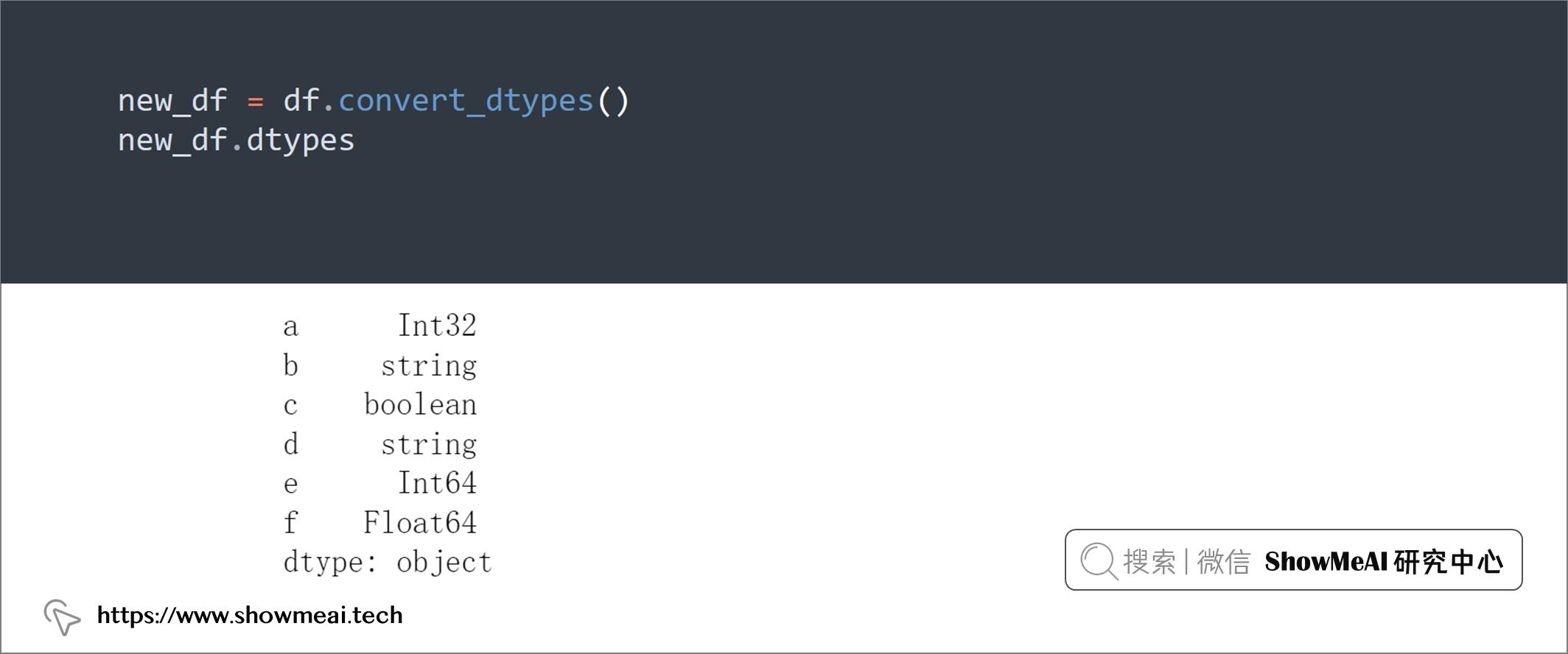
💡 16:自动转换数据类型
对于 DataFrame 中的列,我们可以调整其数据类型,使用convert_dtypes()可以快速将它转换为我们需要的数据类型。
import pandas as pd
import numpy as np
df = pd.DataFrame(
{
"a": pd.Series([1, 2, 3], dtype=np.dtype("int32")),
"b": pd.Series(["x", "y", "z"], dtype=np.dtype("O")),
"c": pd.Series([True, False, np.nan], dtype=np.dtype("O")),
"d": pd.Series(["h", "i", np.nan], dtype=np.dtype("O")),
"e": pd.Series([10, np.nan, 20], dtype=np.dtype("float")),
"f": pd.Series([np.nan, 100.5, 200], dtype=np.dtype("float")),
}
)
df.dtypes
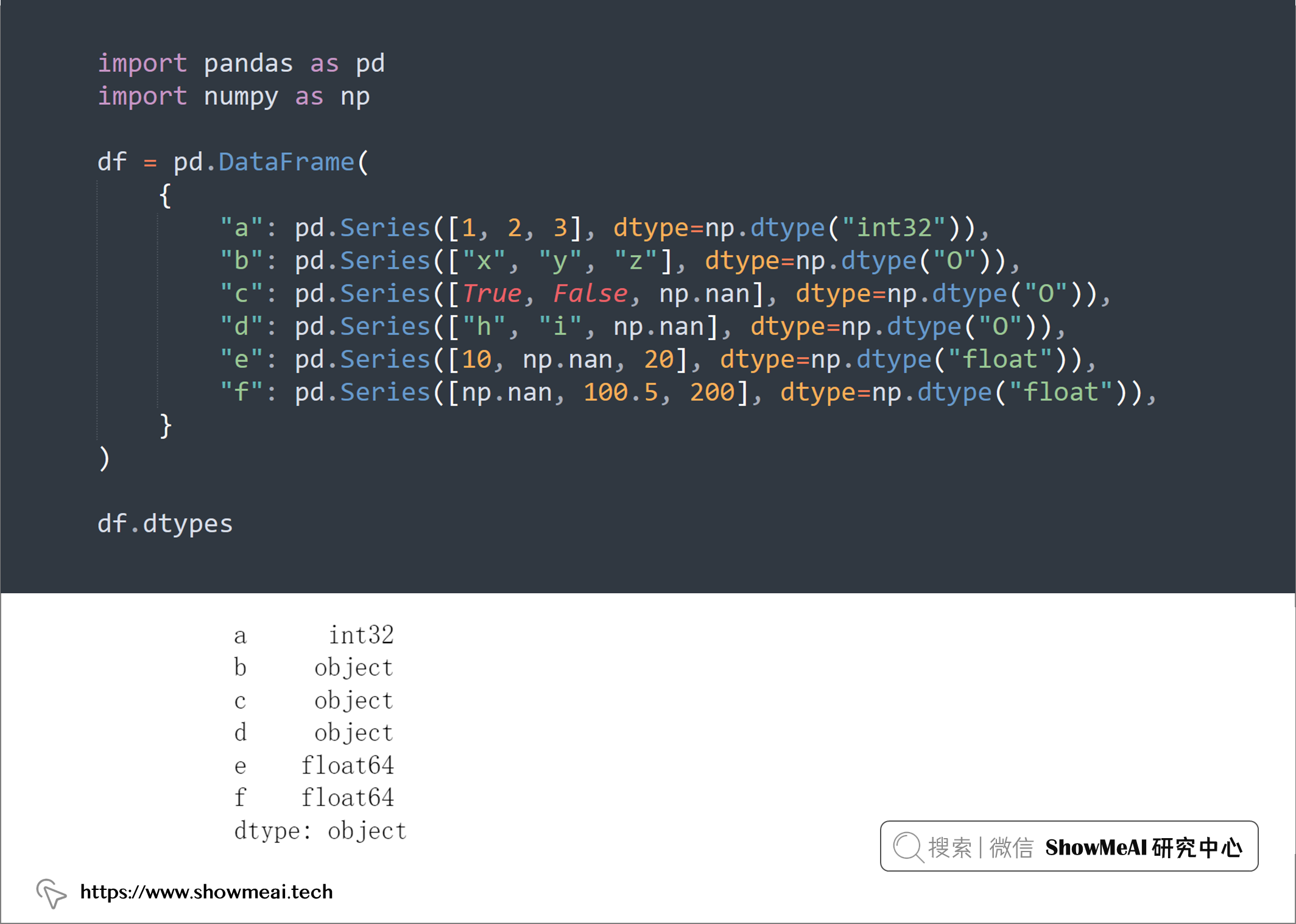
new_df = df.convert_dtypes()
new_df.dtypes
💡 17:将新列分配给 DataFrame
在我们处理数据的时候,有时需要根据某个列进行计算得到一个新列,以便后续使用,相当于是根据已知列得到新的列,这个时候assign函数非常方便。
import pandas as pd
time_sentences = ["Saturday: Weekend (Not working day)",
"Sunday: Weekend (Not working day)",
"Monday: Doctor appointment at 2:45pm.",
"Tuesday: Dentist appointment at 11:30 am.",
"Wednesday: basketball game At 7:00pm",
"Thursday: Back home by 11:15 pm.",
"Friday: Take the train at 08:10 am."]
df = pd.DataFrame(time_sentences, columns=['text'])
# Use Assign instead of using direct assignment
# df['text'] = df.text.str.lower()
# df['text_len'] = df.text.str.len()
# df['word_count'] = df.text.str.count(" ") + 1
# df['weekend'] = df.text.str.contains("saturday|sunday", case=False)
print((
df
.assign(text=df.text.str.lower(),
text_len=df.text.str.len(),
word_count=df.text.str.count(" ") + 1,
weekend=df.text.str.contains("saturday|sunday", case=False),
)
))

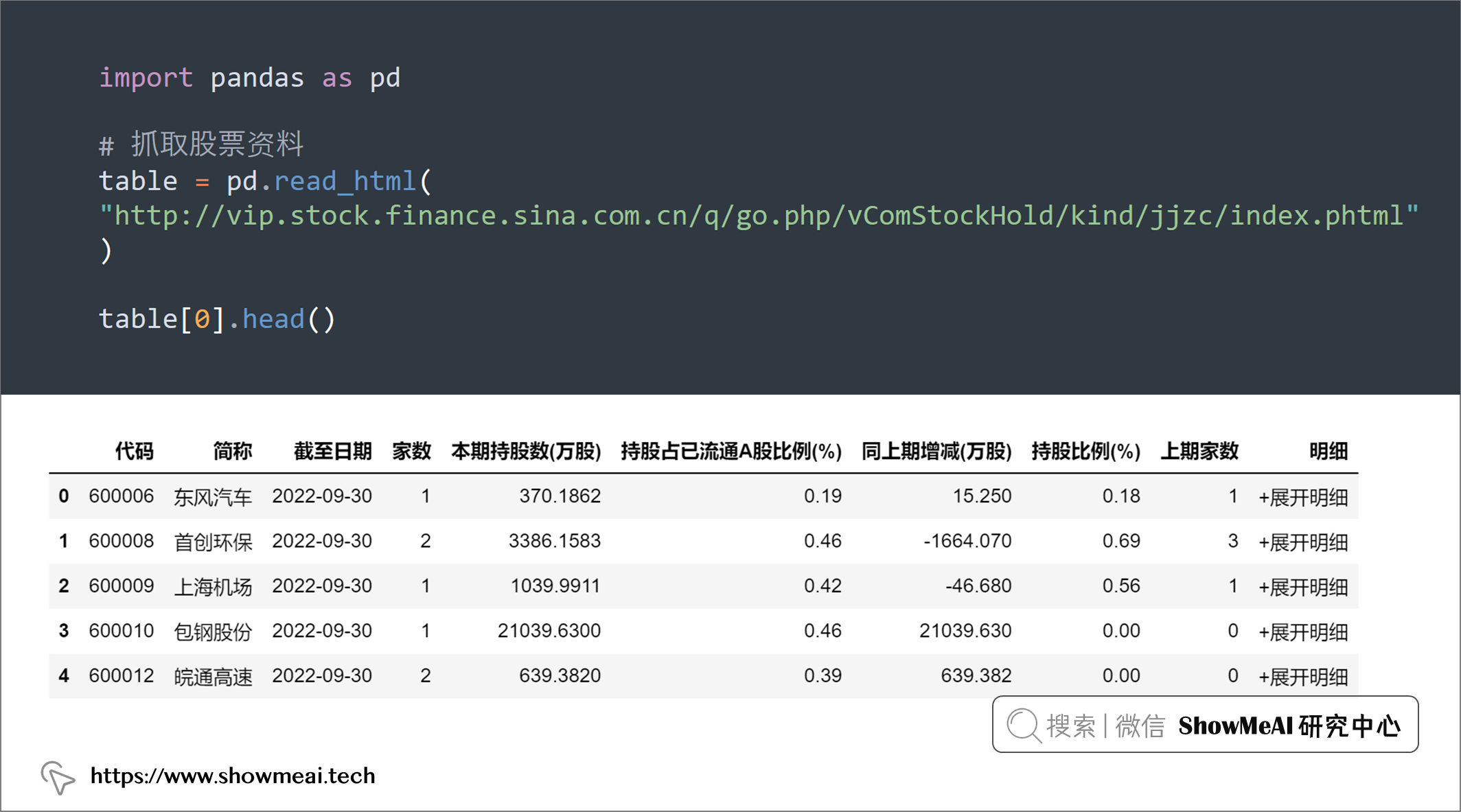
💡 18:读取 HTML 表格
我们可以使用.read_html()可用于快速合并来自各种网站的表格,我们不用关心它是如何抓取网站HTML的。
import pandas as pd
# 抓取股票资料
table = pd.read_html(
"http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml"
)
table[0].head()
💡 19:nlargest 和 nsmallest
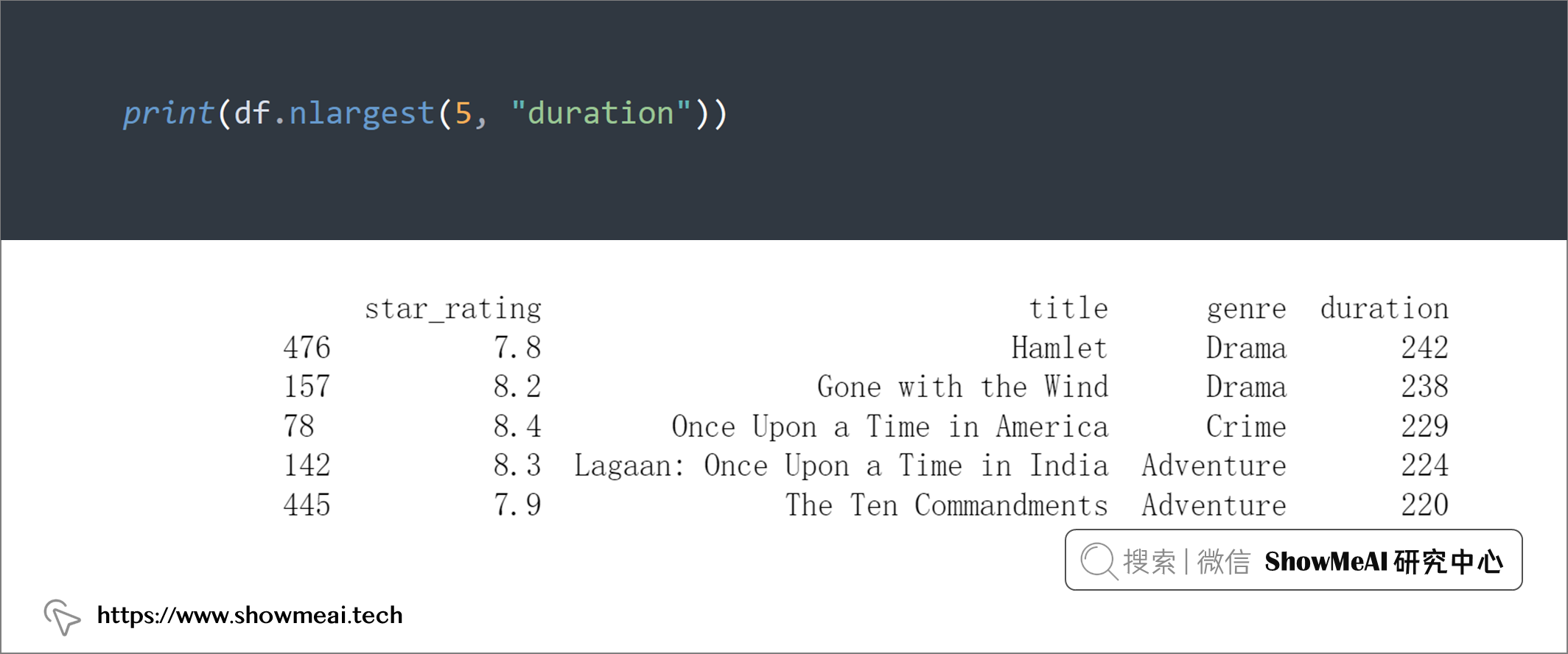
如果我们需要对数据字段进行排序,可以使用.sort_values(),但是它会对所有数据排序,如果我们要获取最大或者最小的 n 个数,可以利用.nlargest()和.nsmallest()。
这里用到的数据集是 🏆IMDB电影评分数据集,大家可以通过 ShowMeAI 的百度网盘地址下载。
🏆 实战数据集下载(百度网盘):公✦众✦号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [65]资深数据科学家整理的21个Pandas技巧 『imdbratings数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
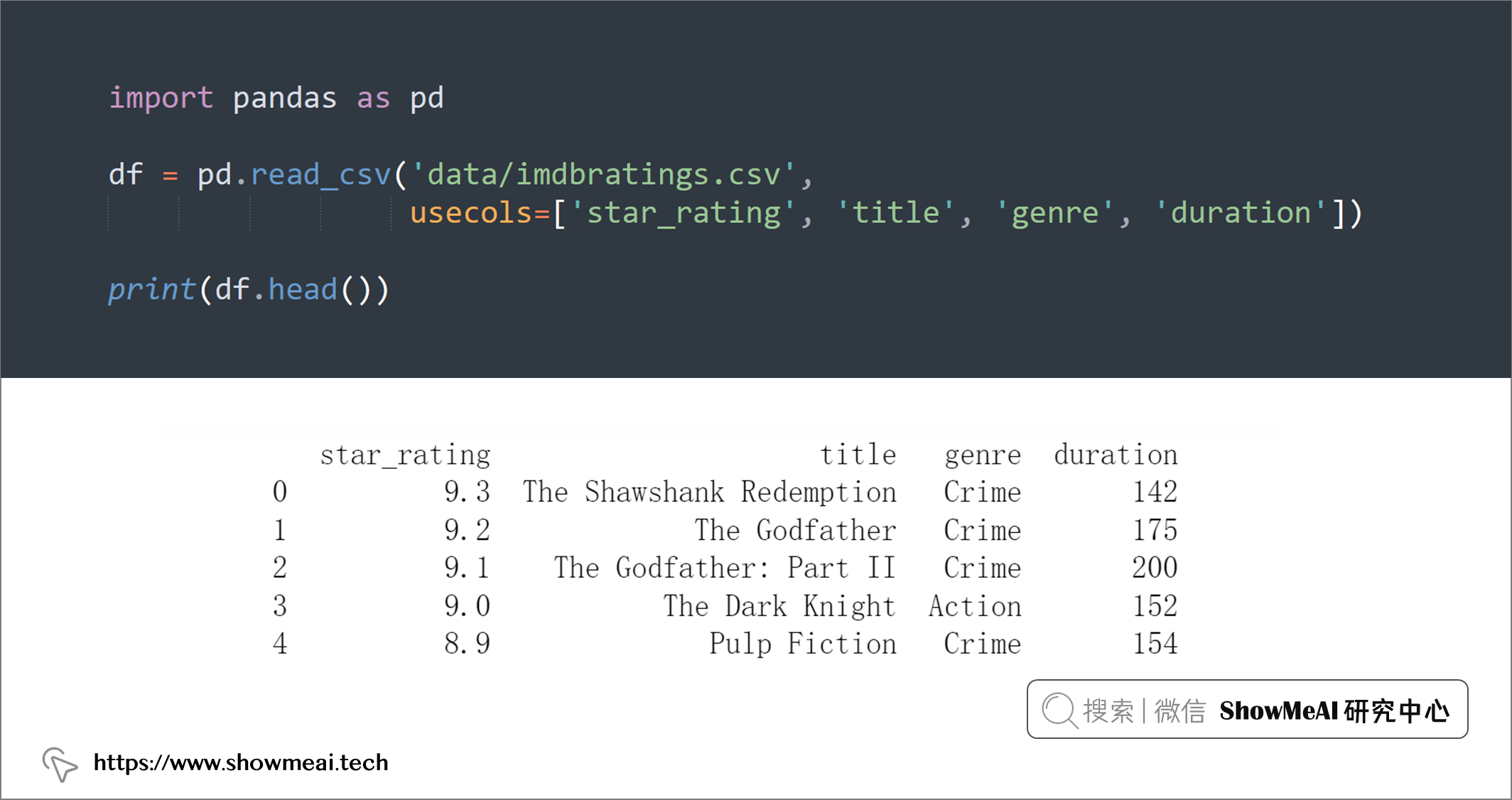
import pandas as pd
df = pd.read_csv('data/imdbratings.csv',
usecols=['star_rating', 'title', 'genre', 'duration'])
print(df.head())
print(df.nlargest(5, "duration"))
print(df.nsmallest(5, "duration"))

💡 20:创建排序列
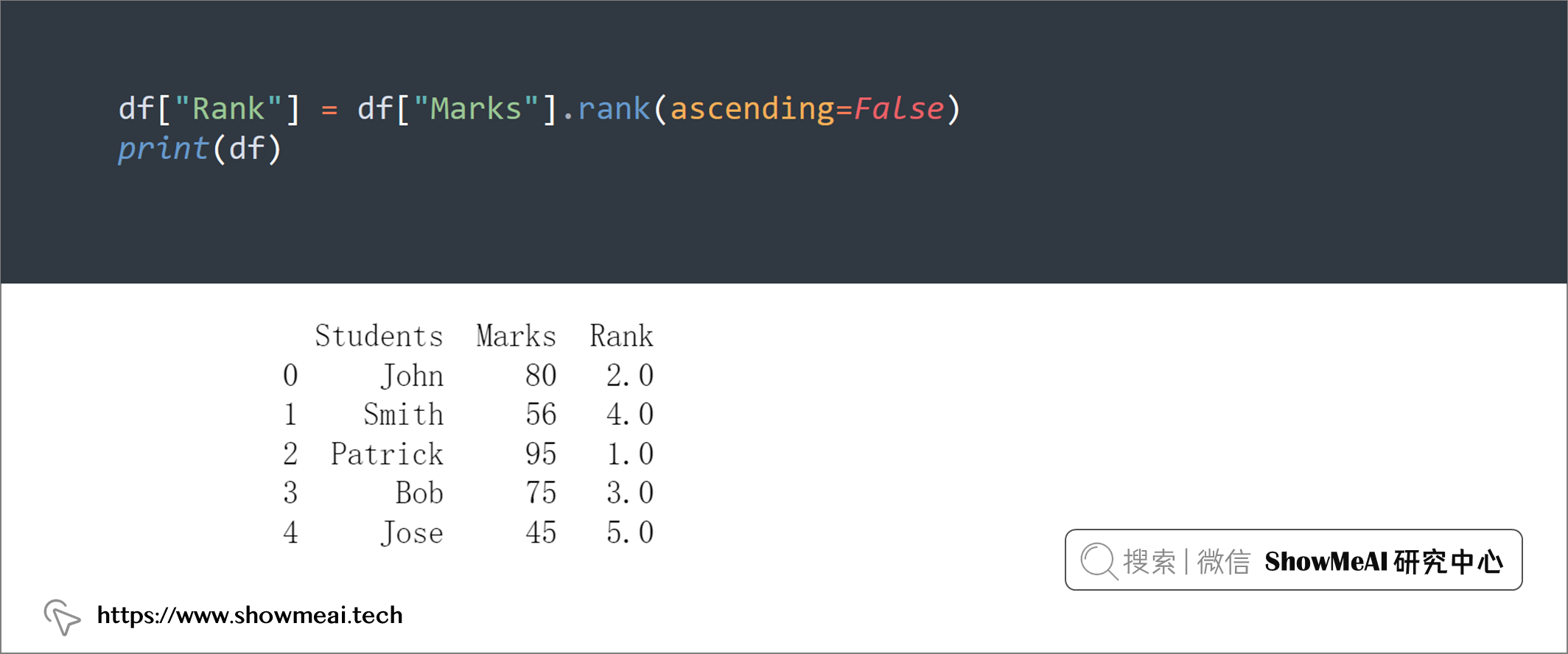
pandas 的DataFrame.rank()函数可以返回字段每个取值的排名。
在以下示例中,创建了一个新的排名列,该列按学生的分数对学生进行排名:
import pandas as pd
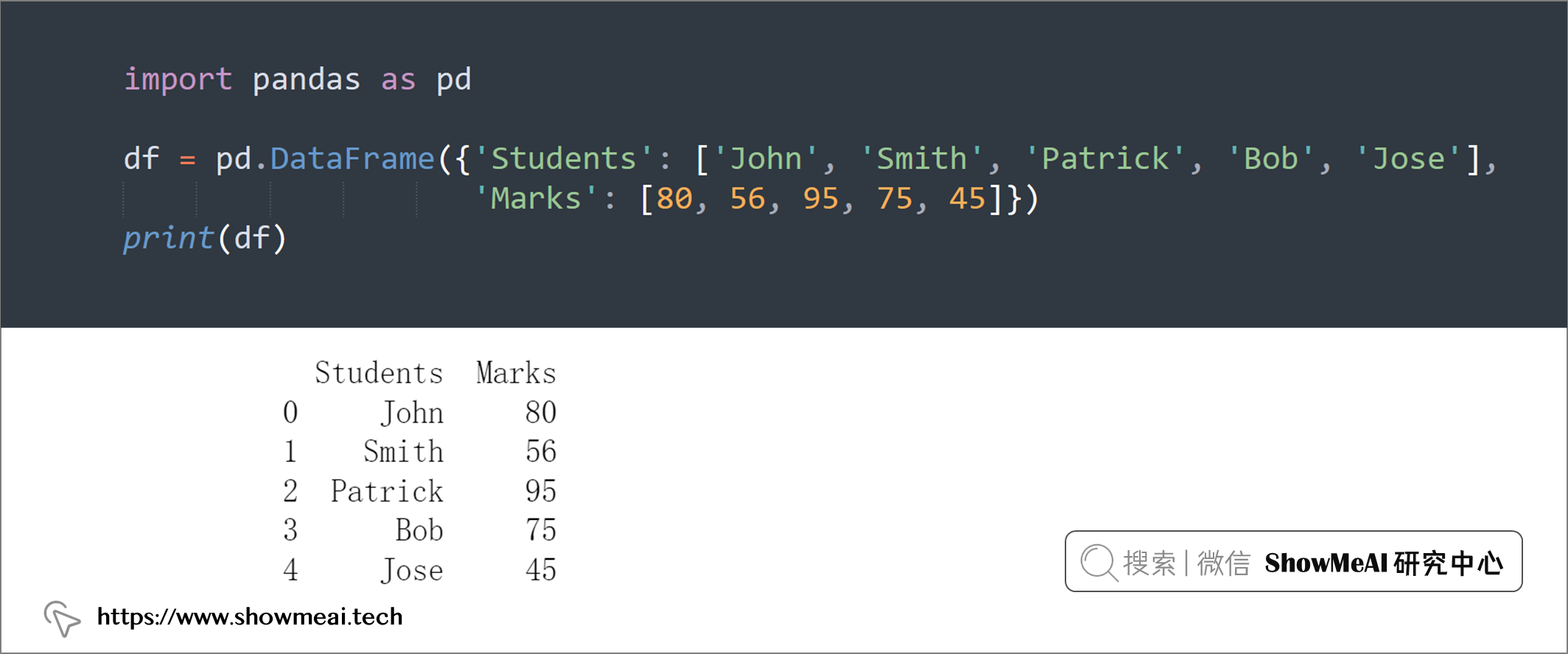
df = pd.DataFrame({'Students': ['John', 'Smith', 'Patrick', 'Bob', 'Jose'],
'Marks': [80, 56, 95, 75, 45]})
print(df)
df["Rank"] = df["Marks"].rank(ascending=False)
print(df)
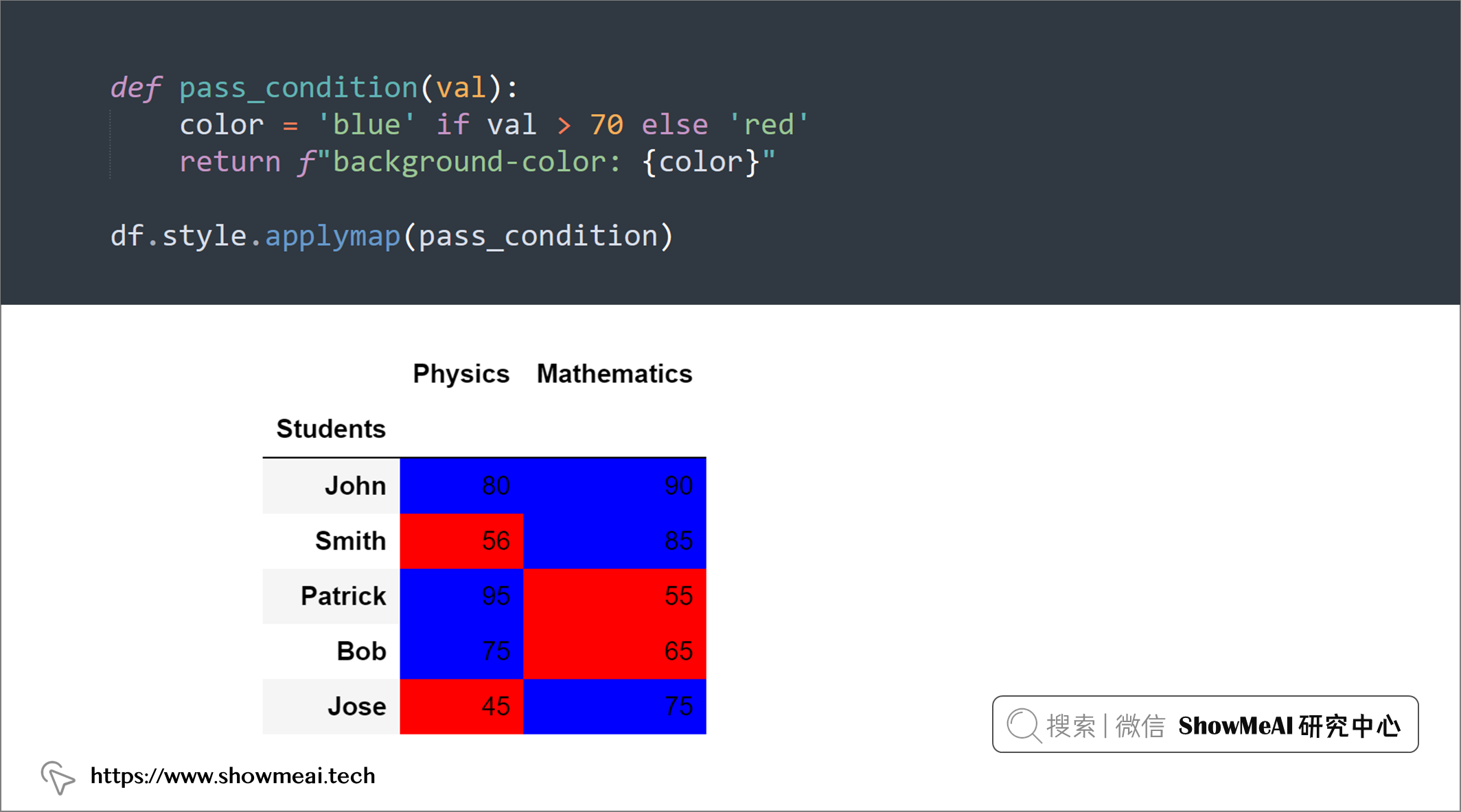
💡 21:DataFrame 中的颜色值
可以为 dataframe 添加颜色样式,增加更多的可读性。Pandas 具有 style 属性,可以设置颜色应用于 DataFrame。
import pandas as pd
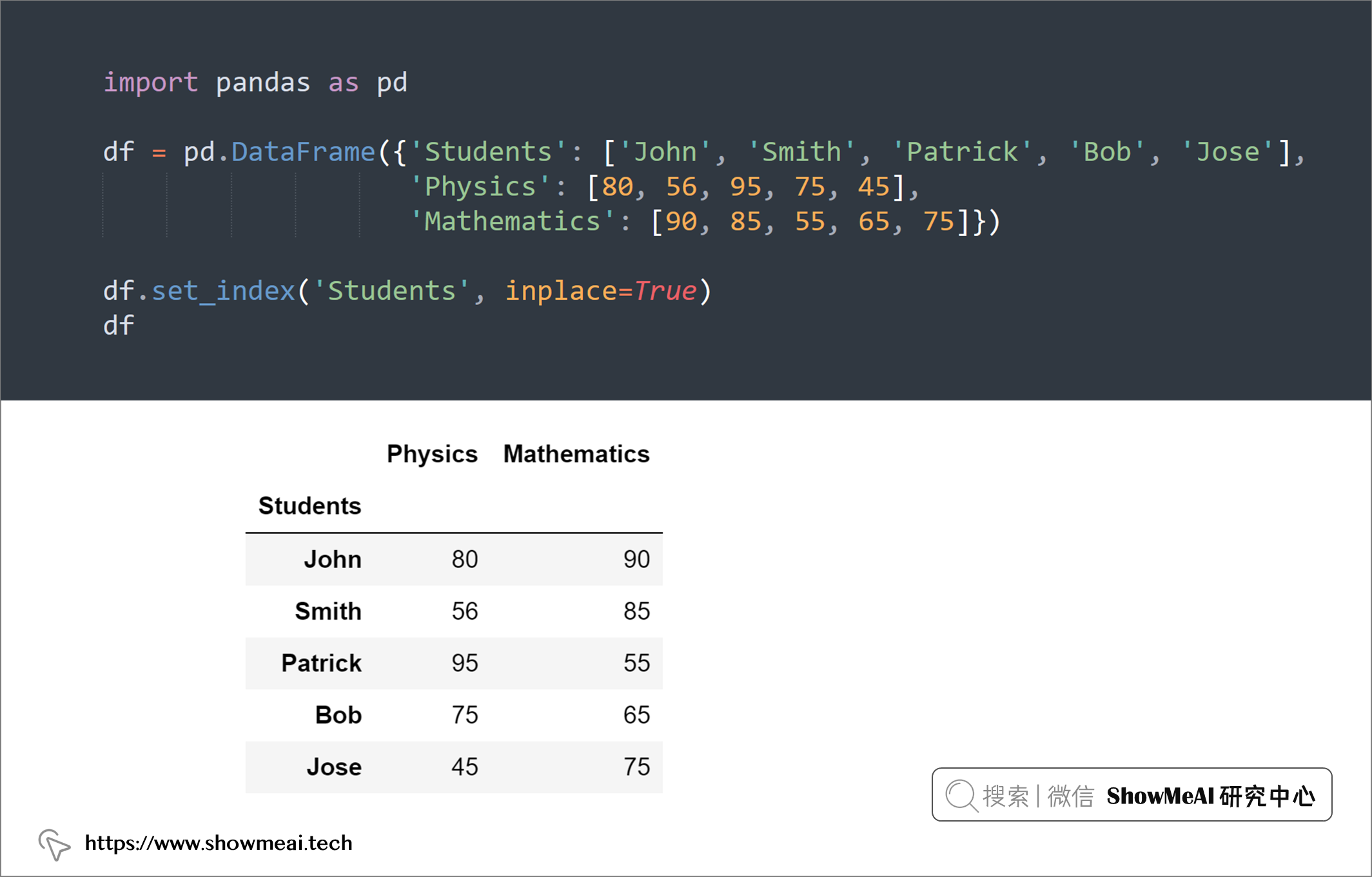
df = pd.DataFrame({'Students': ['John', 'Smith', 'Patrick', 'Bob', 'Jose'],
'Physics': [80, 56, 95, 75, 45],
'Mathematics': [90, 85, 55, 65, 75]})
df.set_index('Students', inplace=True)
df
def pass_condition(val):
color = 'blue' if val > 70 else 'red'
return f"background-color: {color}"
df.style.applymap(pass_condition)
参考资料
- 📘 Python数据分析实战教程 :https://www.showmeai.tech/tutorials/40
- 📘 数据科学工具库速查表 | Pandas 速查表:https://www.showmeai.tech/article-detail/101