前言:本文内容较多(字数1w),不仅包含理论知识,还进行了全面实践。本文对前三章理论内容粗略解释,建议去b站观看哈工大和王道考研的操作系统中虚拟存储相关章节,然后对于设计实现就游刃有余了。
博主写这篇文章,主要是以实现CacheSim模拟器为主,目的是对CPU模拟器进行丰富,来研究cpu乱序执行机制与回滚机制带来的meltdown漏洞。
文章目录
- 一、概述
- 1.1 简介
- 1.2 cache和主存的关系
- 1.3 Cache的基本结构
- 1.4 Cache的读操作
- 1.5 Cache的写操作
- 1.6 Cache的改进
- 二、Cache——主存的地址映射
- 2.1、直接映射
- 2.2、全相联映射
- 2.3、组相联映射
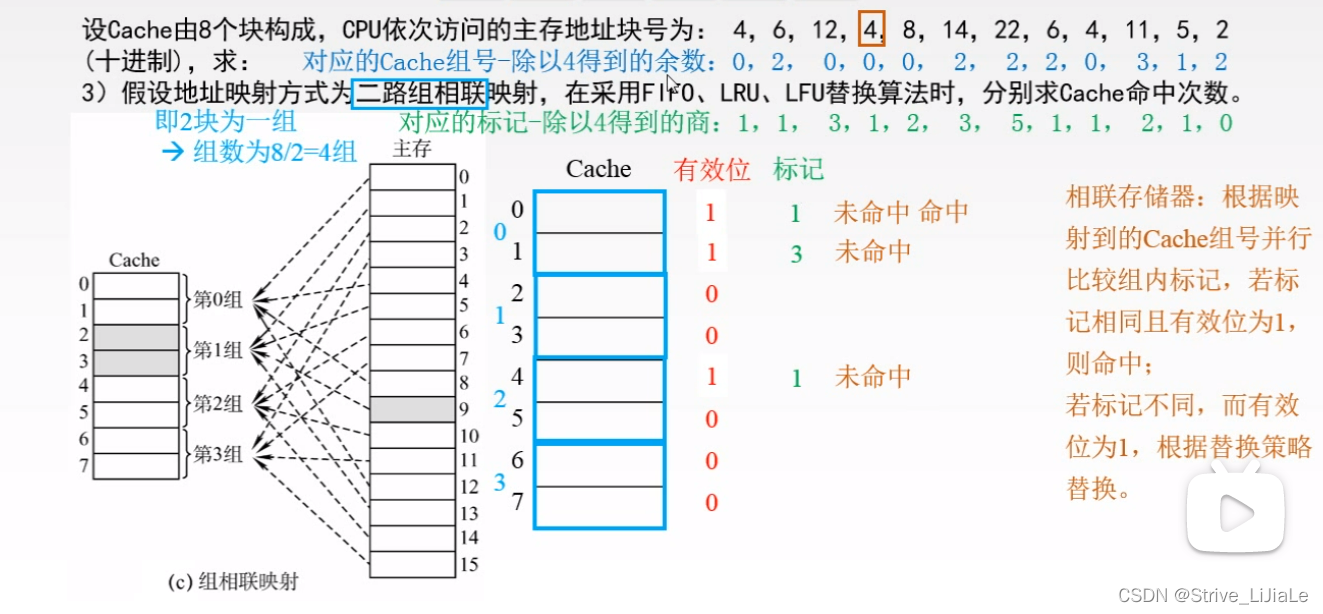
- 三、替换算法
- 四、设计
- 4.1 设计流程
- 4.2文件编写
- 4.2.1Cache_line类
- 4.2.2 变量
- 4.2.3 函数
- 4.2.4 常量
- 五、详细实现
- 5.1 程序入口
- 5.2 初始化
- 5.3 load_trace 加载trace文件函数
- 5.4 check_cache_hit 检查是否cache命中
- 5.5 命中之后的操作
- 5.6 未命中后的操作
- 5.7 get_cache_free_line获得当前可用的line函数
- 5.8 set_cache_line将cache line中的数据写回到内存函数
一、概述
1.1 简介
在计算机系统中,CPU高速缓存(英语:CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。 当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。 缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。 在处理器看来,缓存是一个透明部件。因此,程序员通常无法直接干预对缓存的操作。但是,确实可以根据缓存的特点对程序代码实施特定优化,从而更好地利用缓存。
1.2 cache和主存的关系
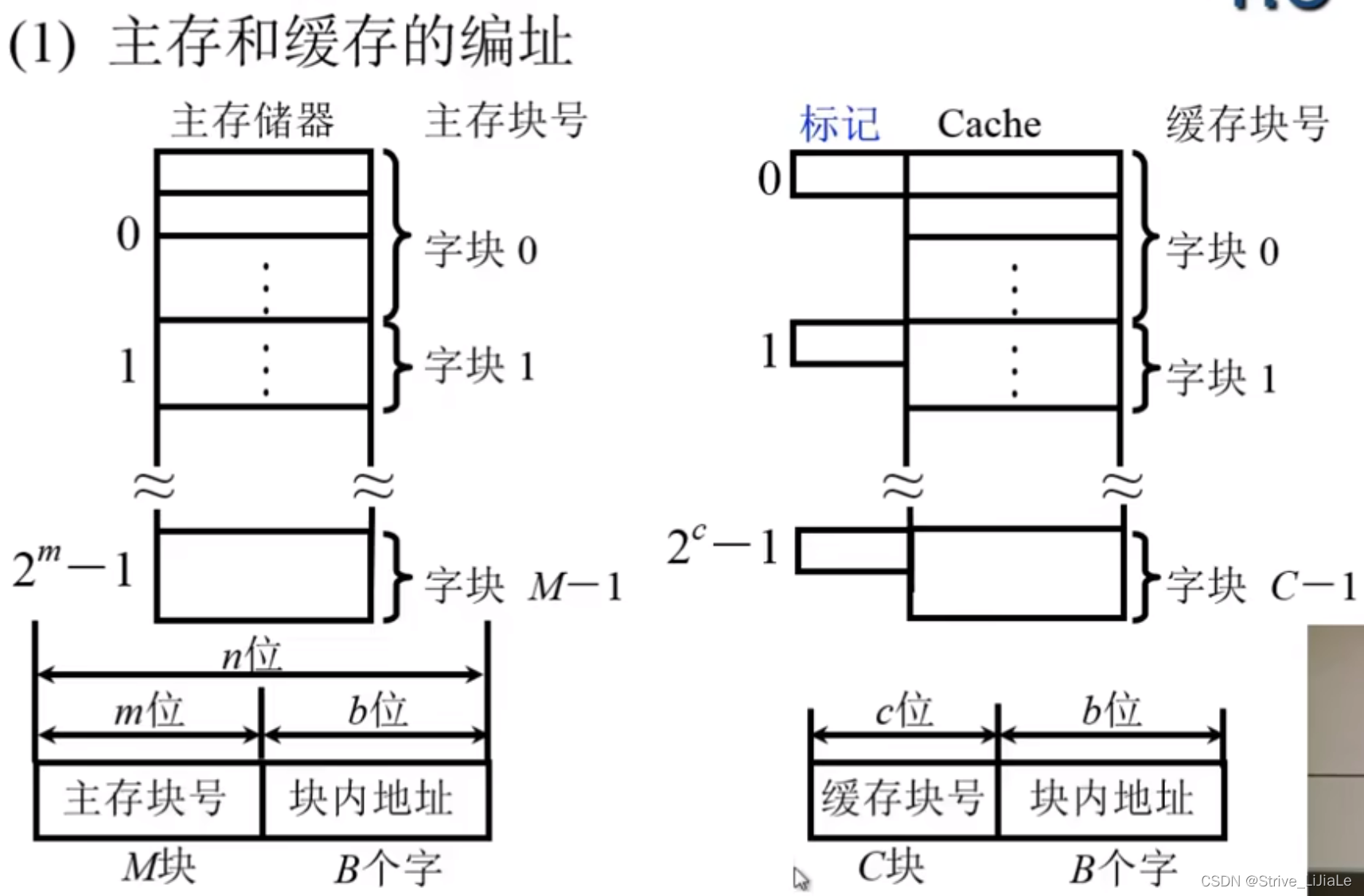
一个块包含16个字节,并且内存的编制单位是字节,那么块内地址就是4位,剩余的部分就是储存块的编号。
1.为什么不需要计算cache地址?
由于主存块和cache块大小是相同的,所以块内地址位数是完全相同的,当某一个块,在内存和cache中进行传送的时候,是以整体进行的,块内并无变化所以两者的块内地址部分,值是完全相同的。
2.cache上的标记是来标记什么的?
标记了主存块和cache块之间的对应关系。如果将主存中的块调入到cache中,就可以将主存块号写入到这个标记中,当接受来自cpu给出的访存地址,就可以确定是否在cache中,将地址中的块号和标记进行比较即可,若相等,并且该cache块是有效的,就可以直接从cache中获取信息。
3.命中率与块长大小关系?
块太小,就没有充分用到局部性原理;块太大,导致块数过少,若块中只有少部分信息是cpu
有用的,其他信息没有用到,也会影响命中率。
1.3 Cache的基本结构
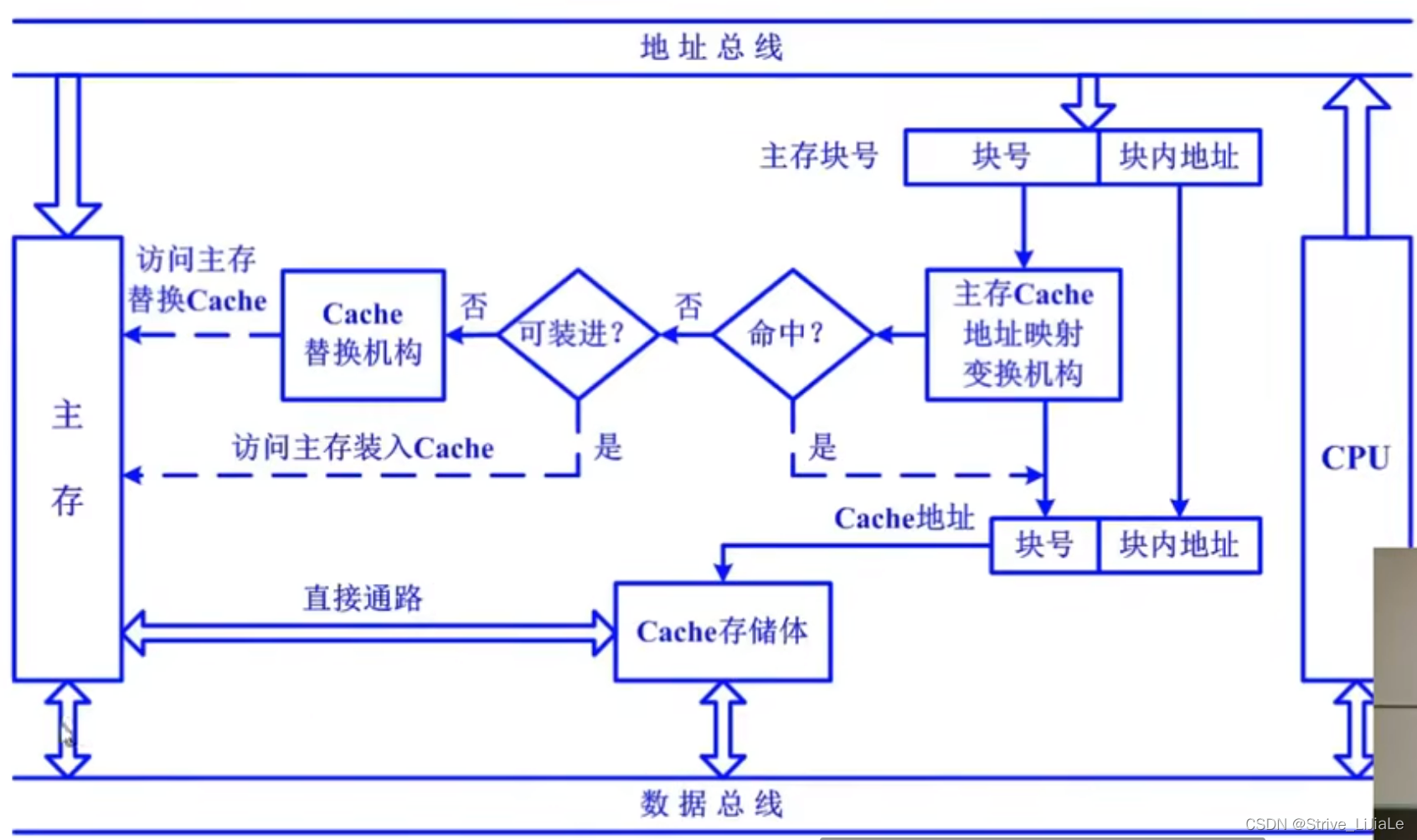
1.地址映射(存:装入):
map,主存当中的一个块,如果要放到cache当中的话,它可以被放到cache的哪一个块或者那些块当中,这就是映射规则。
2.变换结构(取:查找):
把主存的块号给它转换成相应的cache的块号,或者把主存的地址转换成cache的地址,在cache当中找到相应的主存块进行访问。
3.替换算法
1.4 Cache的读操作
1.5 Cache的写操作
Cache和主存的一致性问题:
- 写直法:
写操作时数据既写入主存又写入cache
写操作的时间就是访问主存的时间
cache块退出时不需要对主存执行写操作,更新策略比较容易实现
但对于累加求和的程序,需要反复访存 - 写回法
写操作时只把数据写入cache而不写入主存
当Cache数据被替换出去时才写回主存
但保持不了一致性(并行计算机系统)
1.6 Cache的改进
(1)增加级数
片内cache
片外cache
(2)统一缓存和分立缓存
指令cache
数据cache
(与指令执行的控制方式有关:是否流水)
二、Cache——主存的地址映射
2.1、直接映射
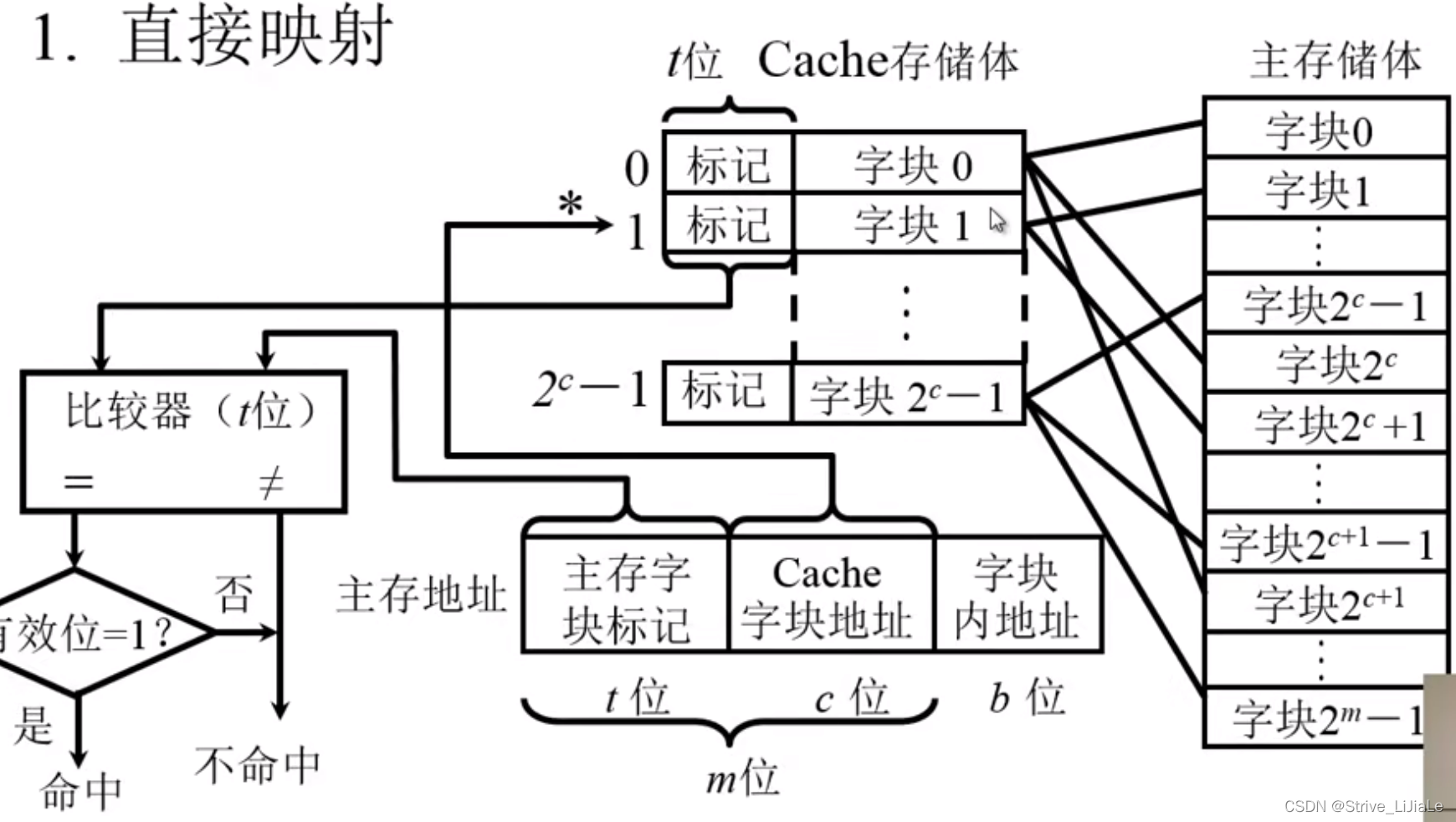
定义:主存中的某一指定块,它只能映射到或者只能装载到某一指定的Cache块当中,任何一个区它的第一块只能放到Cache存储体的字块0当中,即
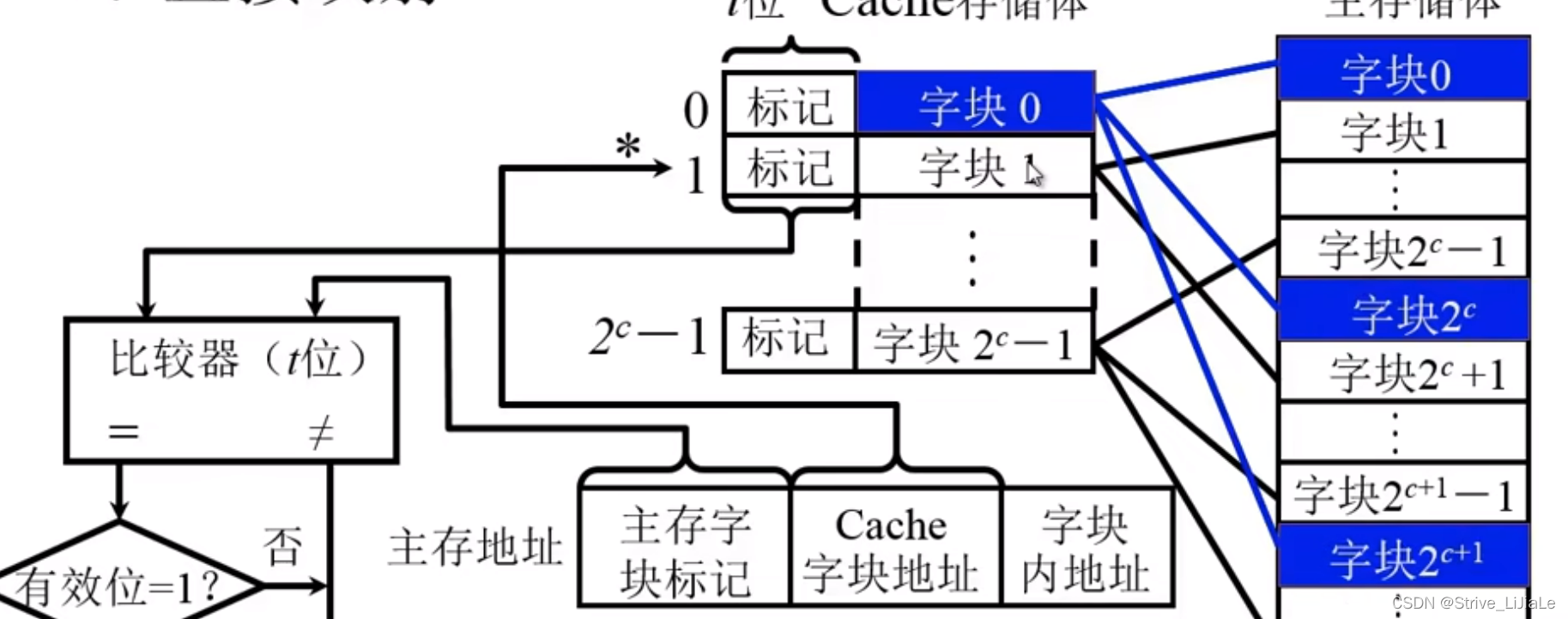
如果cpu给出一个地址,将其分为三部分:区号 | 块号 | 块内偏移地址
区号:主存字块标记(与“标记”占相同t位数)
块号:Cache字块地址
偏移地址:字块内地址
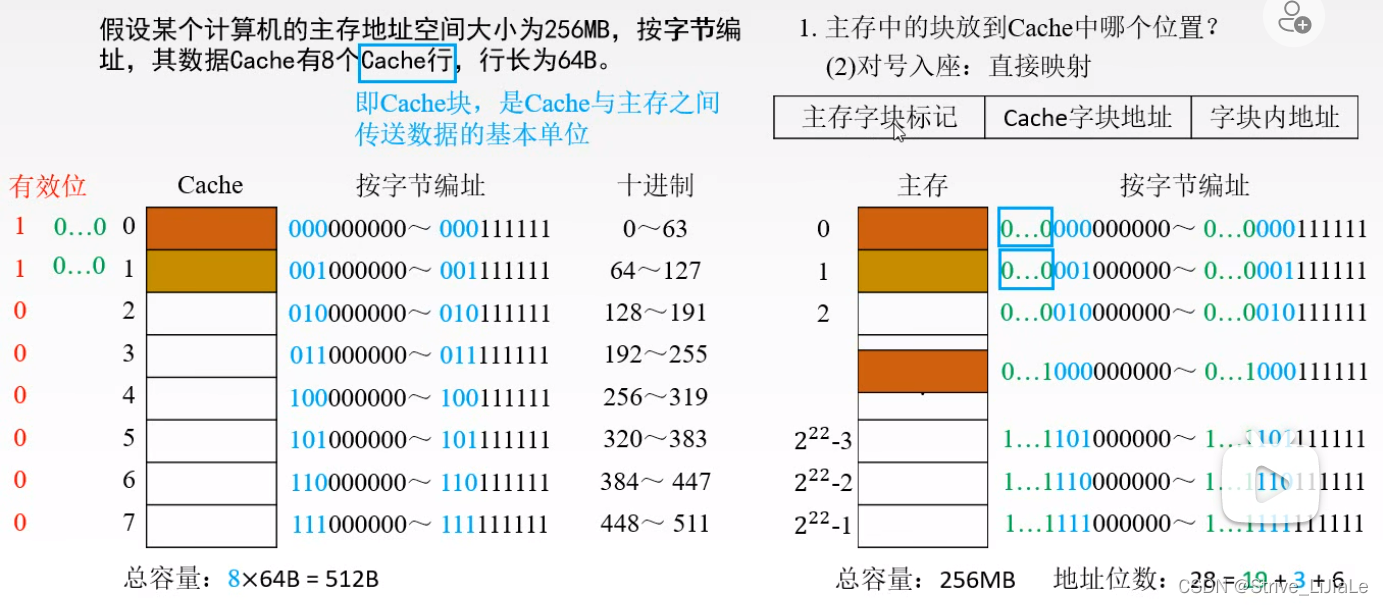
由于cache里面的字块0(第零块),它可能装载的是主存当中任何一个区大的第一块,到底是哪个区的第零块呢?需要将区号写到Cache存储体的“标记”当中。即“标记”记录主存的区号
根据Cache字块地址可从Cache中找到块号,对于此块是否为要找的指定区的指定块,就需要将地址给出的区号与Cashe中现在的区号(标记)进行比较即可。
缺点:当第二次需要使用主存2的c次方的内容时,需要重新将内容代替Cache的第零块以及下面的块,因为直接映射的规则就是某一区的第一块只能放在cache第零块中。
每个缓存块 i 都可以和若干个主存块对应
但是每个主存块 j 只能和一个缓存块对应
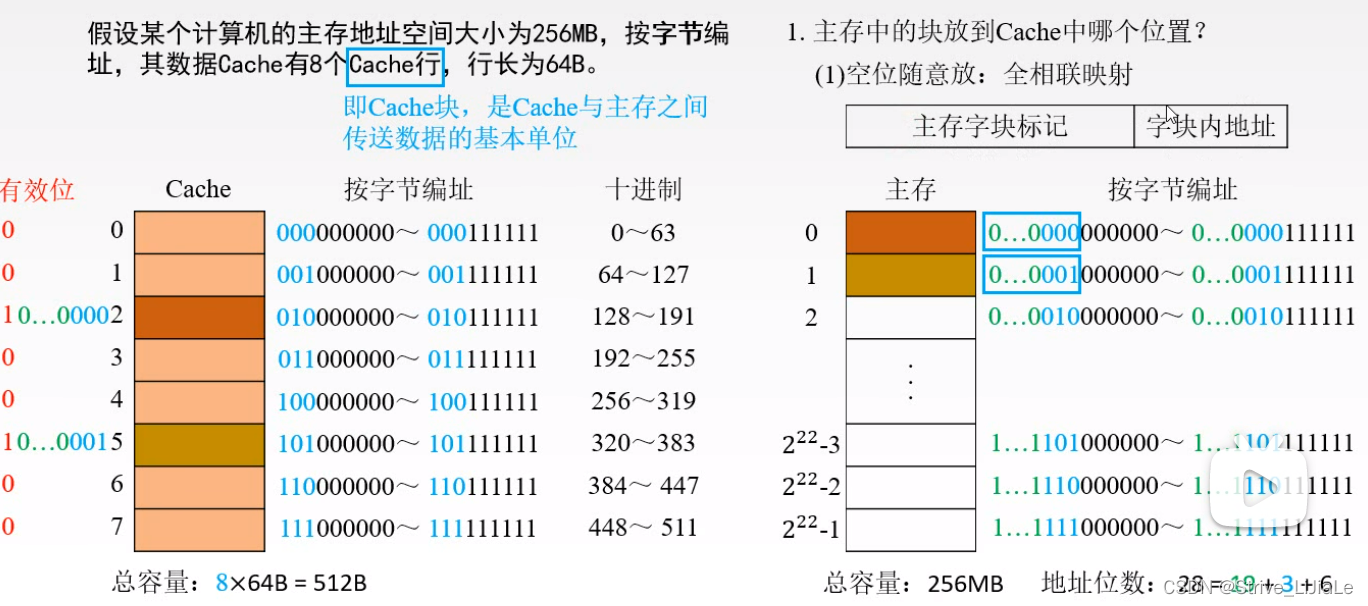
2.2、全相联映射
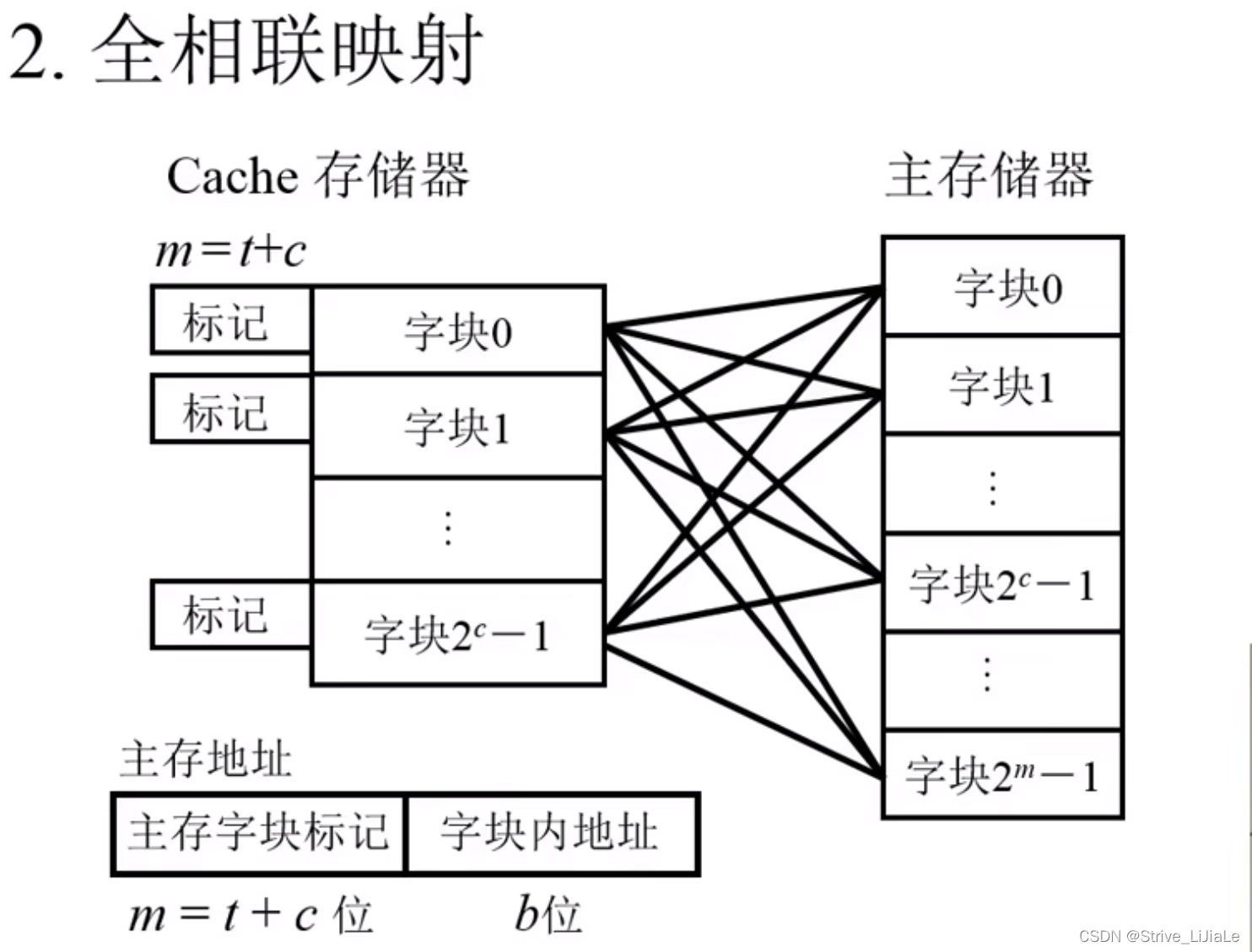
主存当中任何一个块都可以被放入到Cache的任何一个块当中。只要Cache中有空闲块就可以将主存块调入进来,提高了Cache利用率。但是如果主存中某一块调入Cache中,那它可能在Cache的任意一个块中,所以需要将主存地址的主存块号标记与Cache中的所有块的标记进行比较(直接映射是直接从Cache中找块,然后只需要一次比较即可,即主存块号标记与Cache中该块的标记进行比较),另外比较器的长度也会长(t+c)。
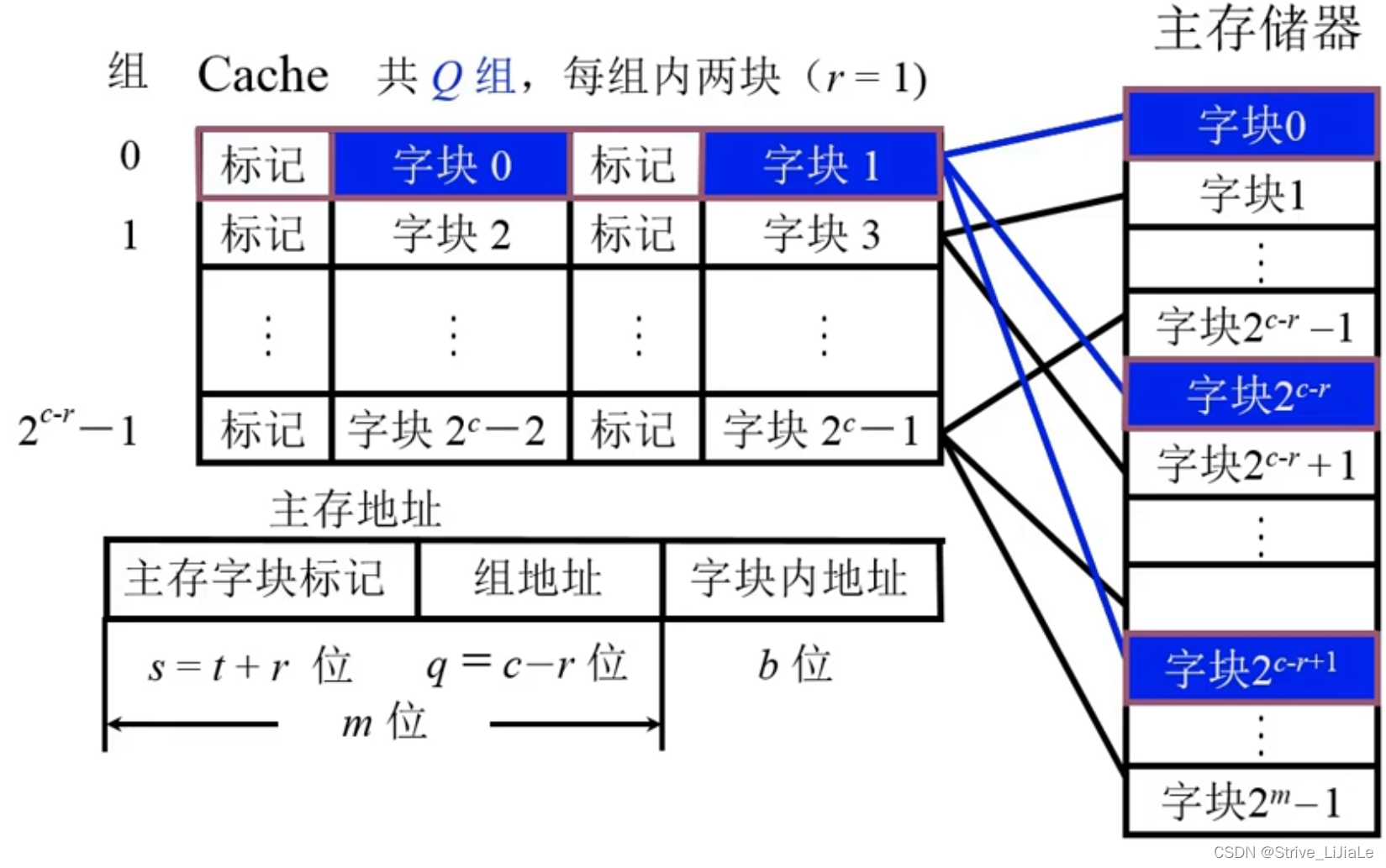
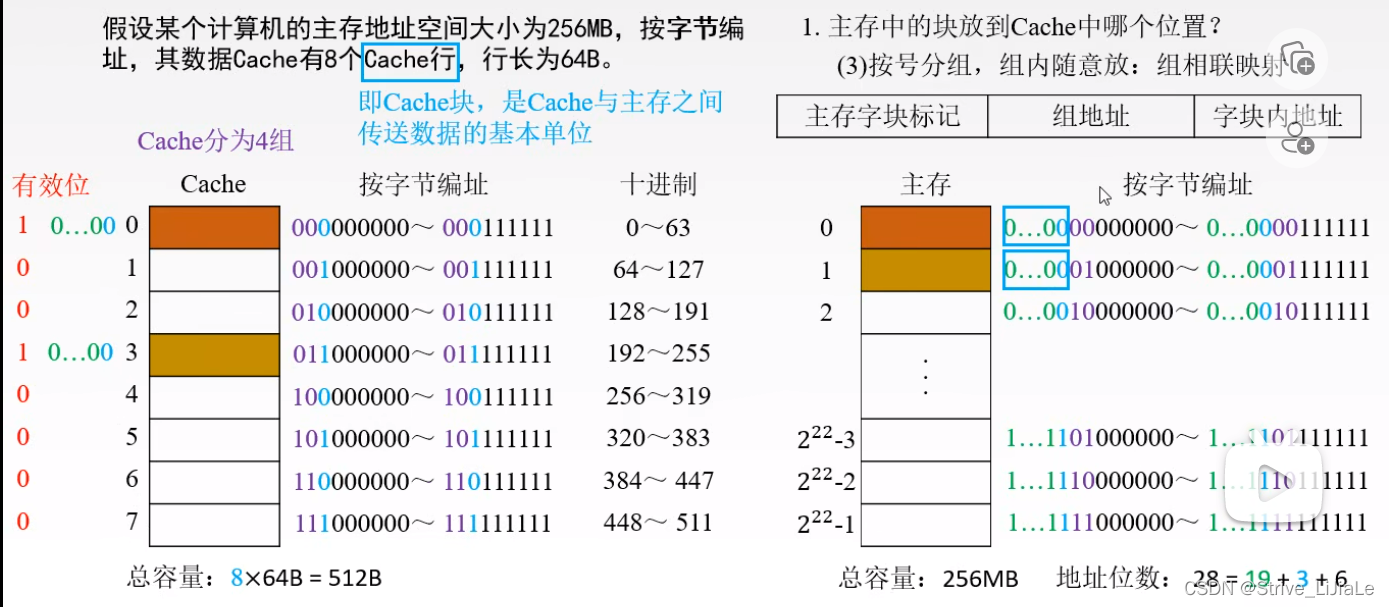
2.3、组相联映射
折中方案:既不是随意放,也不是指定放,而是指定部分位置随意放。
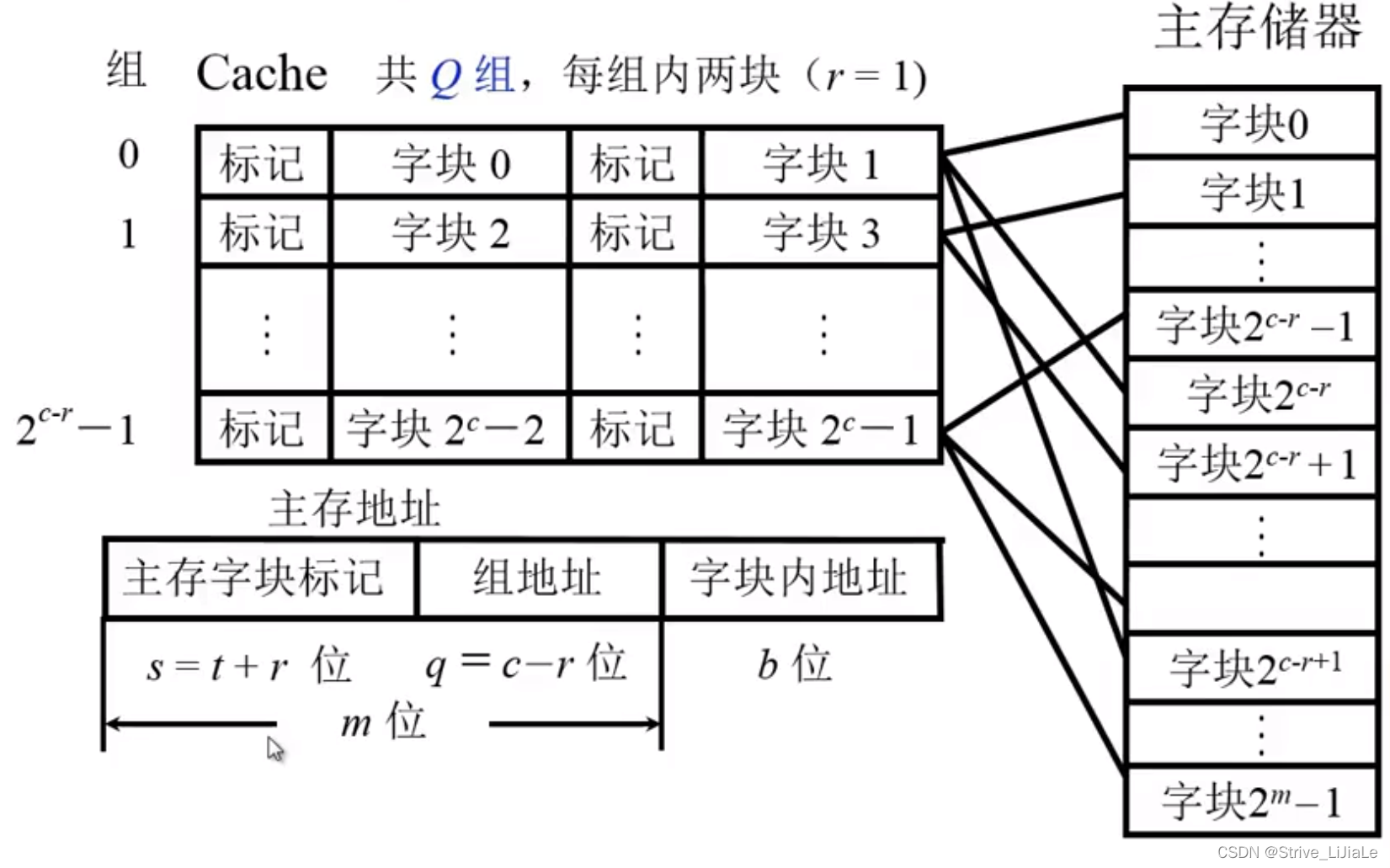
1.先把Cache分成块,这些块再被划分成若干个组。
每组当中包含两块。
2.再将主存分成块,这些块进行划分成区,每个区的大小和Cache中组数是相同的(每个区的块数=组数)。
主存储器的第零块可以放在Cache第零组的任意一个位置(全相联的特性),而区号指定对应标记(直接映射的特性)。
这就保证了同一区的块,只要满足对应组内有位置,就可以调入(全相联的特性)。
当需要查看是否已存在Cache中时,只需要给出区号和区内块号,给出块的标号(j)后,就可以找到(映射Q)给定的组(i),将给定的组当中的几个块的标记与区号进行比较即可,不需要和每一个Cache块比较(直接映射特性)。
三、替换算法
四、设计
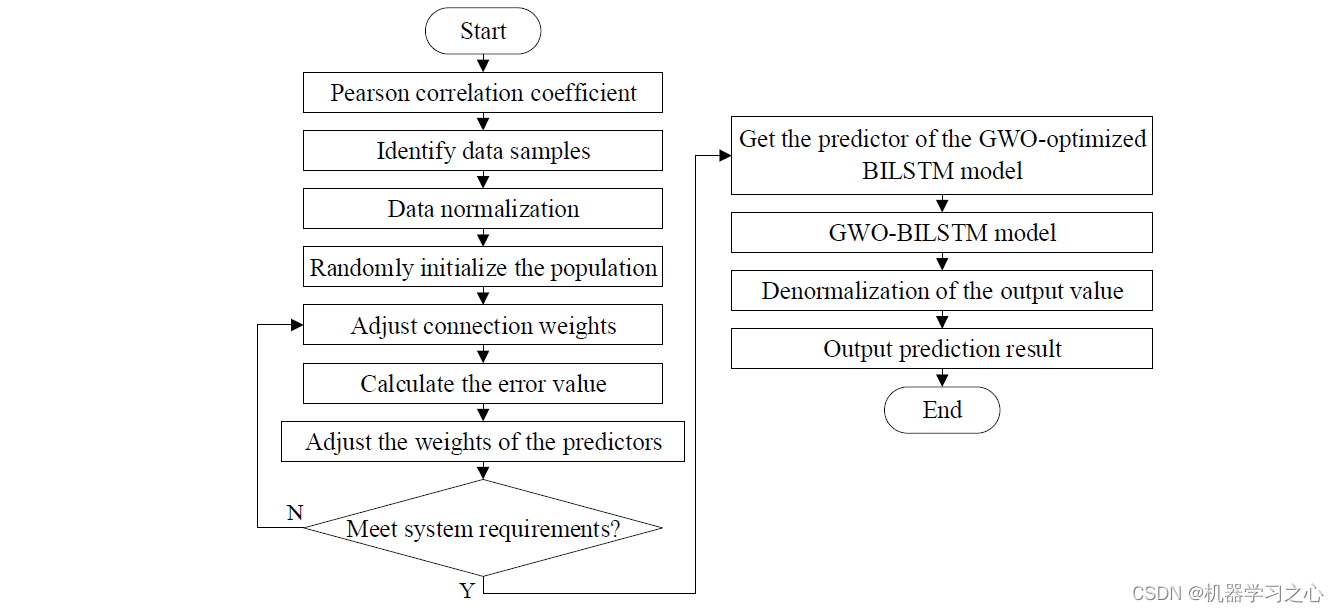
4.1 设计流程
- 1 指令读取
由于主存访问trace以文件形式给出, trace文件下载 所以需要从文件中读取访存trace。其中trace的格式如下:
s 0x1fffff50 1
每行的第一个字符是表示该条指令的类型,s为写(store),r为读(read)。中间的十六进制数为内存地址,最后一个整数是指存储器访问指令之间的间隔指令数。例如第5条指令和第10条指令为存储器访问指令,且中间没有其他存储器访问指令,则间隔指令数为4。 我们写的模拟器中暂不考虑最后这个参数的使用。
- 2 对一条指令进行分析
在从trace文件中读取一条指令之后,对指令进行分析,对地址进行变换,查看地址里的数据是否在cache中,获得命中与否的结果。
- 3 检查是否命中
通过对地址进行操作,检查是否命中
- 4 查找空闲line
如果读命中,则只需要更新时间戳,如果是写操作,则标记脏位。 如果之前没有命中,则需要从当前Cache中找到可以使用的块,优先当前是invaild状态的line,否则执行替换算法,找到需要被替换的块,同时如果要替换的块中原来的数据是脏的,写回到内存中。
- 5 将数据加载到cache line中
如果miss,通过1.4找到可以放置数据的cache line,下一步则就是将数据从主存中加载到cache line上。
4.2文件编写
4.2.1Cache_line类
Cache_Line单独做一个类,tag采用无符号32位
class Cache_Line {
public:
_u32 tag;
/**计数,FIFO里记录最一开始的访问时间,LRU里记录上一次访问的时间*/
union {
_u32 count;
_u32 lru_count;
_u32 fifo_count;
};
_u8 flag;
_u8 *buf;
};
count用来记录访问的时间,采用union数据结构,后面在更新count的时候,只需要针对不同的替换算法,进行特殊赋值即可,而且不会导致一直使用count出现的思路混乱。这个值的变化后面讲替换算法重点说明。 buf本意是存储内存里的数据,参看上一章中结构说明的bank。 flag则是一些标记位的存储:
| 位数 | 7~3 | 2 | 1 | 0 |
|---|---|---|---|---|
| 作用 | 保留 | Locking位 | 脏位 | 有效位 |
4.2.2 变量
| 变量 | 意义 |
|---|---|
| cache_size | cache总大小,单位byte |
| cache_line_size | 一个cache line的大小,单位byte |
| cache_line_num | cache一共有多少个line |
| cache_mapping_ways | 几路组相联 |
| cache_set_size | 整个cache有多少组(set) |
| cache_set_shifts | 在内存地址划分中占的位数,log2(cache_set_size) |
| cache_line_shifts | 在内存地址划分中占的位数,log2(cache_line_num) |
| caches | 真正的cache数组 |
| tick_count | 指令计数器 |
| cache_buf | cache bank,存内存数据的地方 |
| cache_free_num | 当前空闲cache line的数量 |
| cache_r_count, cache_w_count | cache读写内存总数据量 |
| cache_hit_count, cache_miss_count | hit和miss计数 |
| swap_style | 替换算法 |
4.2.3 函数
| 函数 | 功能 |
|---|---|
| check_cache_hit | 检查是否命中 |
| get_cache_free_line | 获得当前空闲的cache line,如果没有空闲的则执行替换算法,返回一个可以替换的块 |
| set_cache_line | 将内存中的数据加载到通过get_cache_free_line获得的cache line上去 |
| do_cache_op | 对一条指令进行分析 |
| load_trace | 加载trace文件,开始进行分析 |
| set_swap_style | 设置本次的缓存替换算法 |
4.2.4 常量
const unsigned char CACHE_FLAG_VAILD = 0x01; //有效位
const unsigned char CACHE_FLAG_DIRTY = 0x02; //脏位
const unsigned char CACHE_FLAG_LOCK = 0x04; //Lock位
const unsigned char CACHE_FLAG_MASK = 0xff; //初始化
对应本文中的第一个表格,lock位是留着后面做cache locking用的。后续会修改项目实现这个功能。CACHE_FLAG_MASK主要是在写入cache line时进行初始化flag用到。其他则是通过与cache line中的flag进行&操作,判断有效性或者脏位与否。
五、详细实现
5.1 程序入口
main.cpp主要针对一个测试文件,配置了不同cache line大小,不同组相联路数,不同的替换策略。默认使用写回法。默认cache大小32KB(0x8000 Bytes)。 在每次循环里,首先初始化cache的配置,然后设置替换策略,最后读入trace文件并开始模拟内存读写过程。
5.2 初始化
在类CacheSim的构造函数里,主要根据上一章一些变量的意义进行了初始化,主要还是注意shifts的两个变量,使用库函数log2()算出位数。 cache line实际是存储在caches变量中,memset填充0,则cache line的flag默认也是填充的0。 注意记得析构函数中对caches和cache_buf的释放。
5.3 load_trace 加载trace文件函数
通过fgets函数读文件到buf字符数组里,然后sscanf从buf里格式化读入一行指令,注意,原文件里是s 0x1fffff50 1的格式,最后一个参数我们先不考虑,因此只读入了指令类型(store or read)和内存地址。 通过判断style来决定是读还是写,每读取(执行)一条,我们的tick_count就++,同样用来记录是读写的计数器也相应++。 rcount/wcount是来统计读写指令的数量,而cache_r_count/cache_w_count是统计内存和cache进行数据读写的次数。在cache miss找到替换line时,如果找到的line中是脏数据,需要将其写回到内存中,此时就产生了数据通信,同样将数据从内存中加载到这个替换line中也有数据通信。 trace文件处理完成后,就是打印结果。目前主要关注的三个方面:
- 指令计数
- miss率/hit率
- 读写数据通信
5.4 check_cache_hit 检查是否cache命中
do_cache_op分析一条指令
传入参数是地址和读写的标记(s or r)。对于load和store指令而言,只有两种情况:hit or miss。则中间主要涉及三个部分:检查是否命中、命中之后的操作、miss之后的操作。
int CacheSim::check_cache_hit(_u32 set_base, _u32 addr) {
/**循环查找当前set的所有way(line),通过tag匹配,查看当前地址是否在cache中*/
_u32 i;
for (i = 0; i < cache_mapping_ways; ++i) {
if ((caches[set_base + i].flag & CACHE_FLAG_VAILD) && (caches[set_base + i].tag == ((addr >> (cache_set_shifts + cache_line_shifts))))) {
return set_base + i;
}
}
return -1;
}
int CacheSim::check_cache_hit(_u32 set_base, _u32 addr)
检查命中的传参有两个,一个是set的基址,一个是当前trace中的内存地址。
set = (addr >>cache_line_shifts) % cache_set_size;
set_base = set * cache_mapping_ways;
根据组相联中我们对地址的区域划分,来获取当前地址映射到了cache的哪一个set中去了。(line占的位数是块内偏移地址,set占的位数是组索引,所以去掉line占的位数,带着剩余的高位,即tag+set,直接取余,或者去掉tag占的高位后进行取余也许)
而cache在模拟器中是作为一维数组对待的,所以还需要获取这个set的首地址。(知道了第几组,那么首地址=组数*组的大小)
命中与否的判定则是根据tag的匹配情况,如果当前地址addr的tag和我们cache中映射set中的某一个line tag相同(caches[set_base + i].tag == ((addr >> (cache_set_shifts + cache_line_shifts)))),且这个line是有效的(caches[set_base + i].flag & CACHE_FLAG_VAILD),那么返回这个line的在这个一维数组cache的index(即第几个cache line /块号)。如果当前set中没有找到,说明这个addr中的数据并没有加载到cache上,返回-1。
5.5 命中之后的操作
if (index >= 0) {
cache_hit_count++;
//只有在LRU的时候才更新时间戳,第一次设置时间戳是在被放入数据的时候。所以符合FIFO
if (CACHE_SWAP_LRU == swap_style)
caches[index].lru_count = tick_count;
//直接默认配置为写回法,即要替换或者数据脏了的时候才写回。
//命中了,如果是改数据,不直接写回,而是等下次,即没有命中,但是恰好匹配到了当前line的时候,这时的标记就起作用了,将数据写回内存
if (!is_read)
caches[index].flag |= CACHE_FLAG_DIRTY;
}
如果命中了,皆大欢喜,命中计数++,如果替换算法是LRU,则更新一下时间戳(有关时间戳的事情后面会详细说明)。 如果是一个写内存的操作,则需要把命中的这个cache line标志设置为脏,因为指令的意思是往这个内存地址写数据,而cache中原来有一份数据,由于我们的默认cache写的方式是写回法(写回法,write back,即写cache时不写入主存,而当cache数据被替换出去时才写回主存),因此这里只是先标记为脏数据,等该line要被替换出去的时候,再把该line中的数据写回到内存。
5.6 未命中后的操作
index = get_cache_free_line(set_base);
set_cache_line((_u32)index, addr);
if (is_read) {
cache_r_count++;
} else {
cache_w_count++;
}
cache_miss_count++;
如果miss了,先获得可用的line(5.7)(可能是当前set恰好不满,有空闲,也可能是通过替换算法获得可以替换的line),然后将addr内存地址中的数据写入到cache line里,相应的读写通信次数也要++,cache_r_count已经在5.3中的load_trace函数部分介绍过了。
5.7 get_cache_free_line获得当前可用的line函数
_u32 CacheSim::get_cache_free_line(_u32 set_base)
当然是从当前映射的set里找可用的line,传入在“一维数组”的cache里映射set的index。
for (i = 0; i < cache_mapping_ways; ++i) {
if (!(caches[set_base + i].flag & CACHE_FLAG_VAILD)) {
if (cache_free_num > 0)
cache_free_num--;
return set_base + i;
}
}
循环当前set一遍,判断标志位中的有效位,如果有无效的cache line,那么就意味这个line是“空闲”的。直接返回它的index即可。 循环完都没有找到,说名当前的cache set是满的,那么执行替换算法:
free_index = 0;
if(CACHE_SWAP_RAND == swap_style){
free_index = rand() % cache_mapping_ways;
}else{ //FIFO
min_count = caches[set_base].count;
for (j = 1; j < cache_mapping_ways; ++j) {
if(caches[set_base + j].count < min_count ){
min_count = caches[set_base + j].count;
free_index = j;
}
}
}
if (CACHE_SWAP_LRU == swap_style)
caches[index].lru_count = tick_count;
随机替换算法的种子在CacheSim的构造函数里进行过初始化了。 对于FIFO(First in, first out)先进先出替换算法,其cache line的时间戳记录的是这个line被填充数据时的时间,即进入“使用队列”时的时间,因此FIFO是找到最先进入这个队列的line,将其替换出去。 LRU(Least Recently Used)最近最少使用替换算法,则当line被访问的时候,就需要更新其时间戳,因此在do_cache_op函数里,当cache 命中时,需要更新其时间戳。
min_count在FIFO中获得是最早进入队列的line,而在LRU中,则是这个队列中已经很长时间没有访问的line。
如果通过替换算法获得的这个line中原有的数据是脏数据,那么标记其脏位
if (caches[free_index].flag & CACHE_FLAG_DIRTY) {
caches[free_index].flag &= ~CACHE_FLAG_DIRTY;
cache_w_count++;
}
5.8 set_cache_line将cache line中的数据写回到内存函数
void CacheSim::set_cache_line(_u32 index, _u32 addr) {
Cache_Line *line = caches + index;
// 这里每个line的buf和整个cache类的buf是重复的而且并没有填充内容。
line->buf = cache_buf + cache_line_size * index;
// 更新这个line的tag位
line->tag = addr >> (cache_set_shifts + cache_line_shifts );
line->flag = (_u8)~CACHE_FLAG_MASK;
line->flag |= CACHE_FLAG_VAILD;
line->count = tick_count;
}
传入的是“一维数组”cache中要写回的line的index以及要写入line的内存地址。 这里的buf并没有什么作用,只是表示将内存里的数据写入了当前这个line,而在我们的cache模拟器里,并没有真正的数据流动。 更新tag则根据第一章中地址划分的内容,对addr进行移位操作即可。 flag先清空,CACHE_FLAG_MASK = 0xff则~CACHE_FLAG_MASK = 0x00,然后将最后一位有效位置为有效,并更新时间戳。
完成后代码会放在评论区