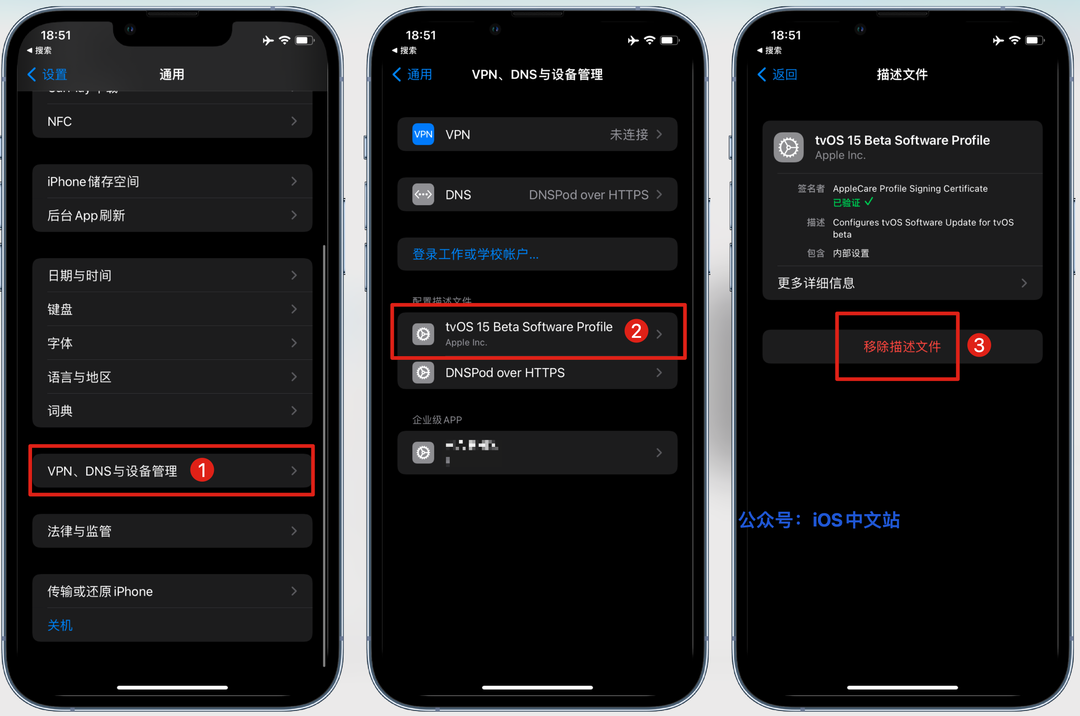
partitionColumn是应该用于确定分区的列。
lowerBound并upperBound确定要获取的值的范围。完整数据集将使用与以下查询对应的行:
SELECT * FROM table WHERE partitionColumn BETWEEN lowerBound AND upperBound
numPartitions确定要创建的分区数。lowerBound和之间的范围upperBound分为numPartitions每个,步幅等于:
upperBound / numPartitions - lowerBound / numPartitions
例如,如果:
lowerBound: 0
upperBound: 1000
numPartitions: 10
步幅等于 100,分区对应于以下查询:
- SELECT * FROM table WHERE partitionColumn BETWEEN 0 AND 100
- SELECT * FROM table WHERE partitionColumn BETWEEN 101 AND 200
- …
- SELECT * FROM table WHERE partitionColumn >= 901
验证
mysql表数据:
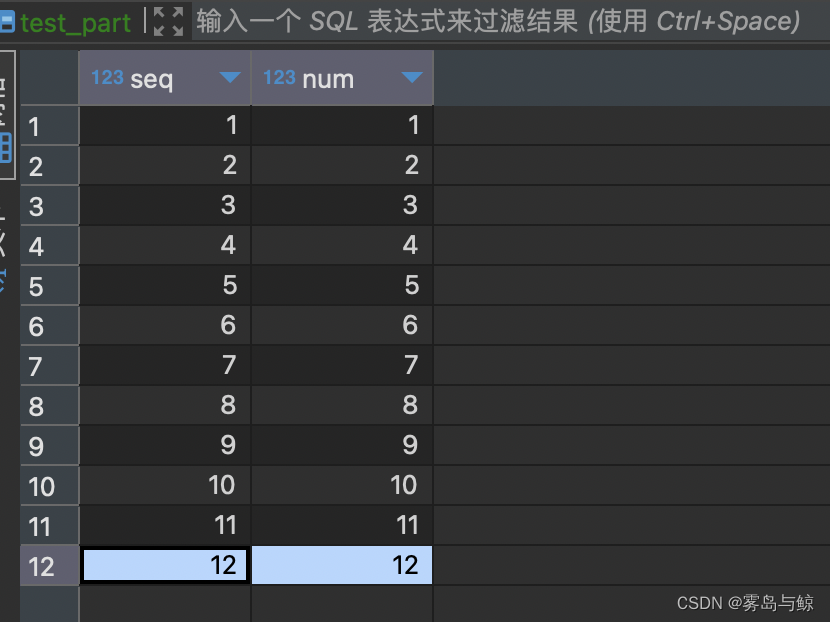
验证代码:
import org.apache.spark.TaskContext
import org.apache.spark.sql.SparkSession
object SpkPartApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName(SpkPartApp.getClass.getSimpleName)
.enableHiveSupport()
.getOrCreate()
val jdbcDF = spark.read.format("jdbc")
.options(Map("url" -> "jdbc:mysql://127.0.0.1:3306/data_test?user=root&password=123456",
"dbtable" -> "data_test.test_part",
"fetchSize" -> "20",
"partitionColumn" -> "seq",
"lowerBound" -> "0",
"upperBound" -> "10",
"numPartitions" -> "5"))
.load()
println(jdbcDF.rdd.getNumPartitions)
jdbcDF.foreach(row => {
println("partitionId:" + TaskContext.get.partitionId)
})
spark.stop()
}
}
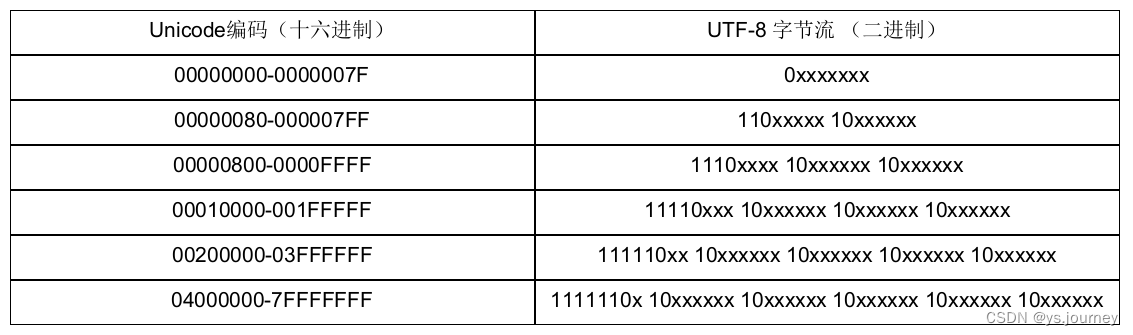
![[Android Studio] Android Studio设置杂项](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)