👀日报&周刊合集 | 🎡ShowMeAI官网 | 🧡 点赞关注评论拜托啦!
1. 2024年欧洲杯来了!AI预测比赛结果的玩法,也越来越高级了~
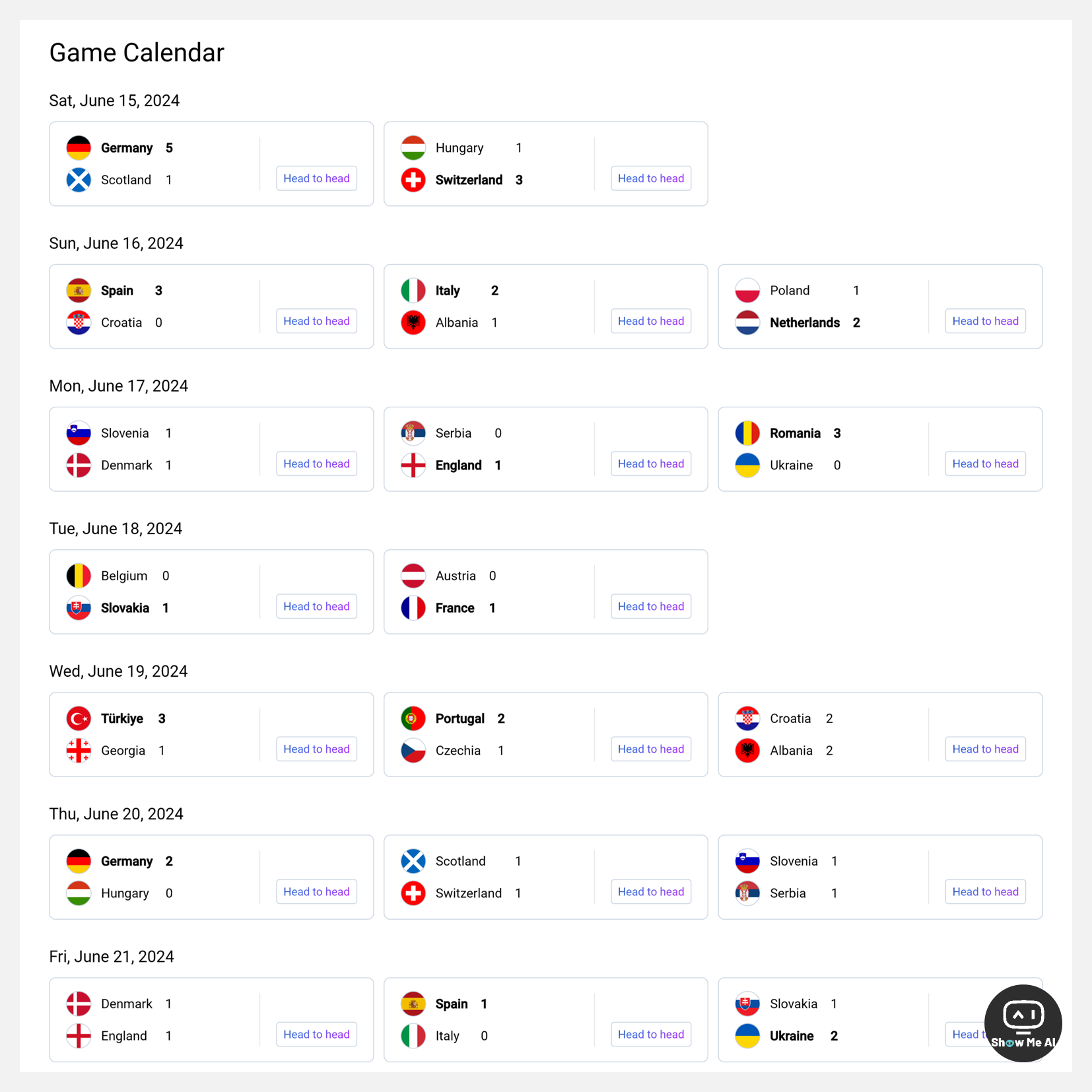
2024 年欧洲杯于6月14日至7月14日在德国举行,共有24支国家队参加。目前处于小组赛阶段。
每逢大型体育赛事,科技博主们总会有一些「结合AI预测比赛结果」的新活儿。今年,这个项目则完全交给了AI。
luzmo 根据各球队和球员的历史数据,制作并上线了一套智能预测分析系统。系统可以综合评估参赛队伍的实力和比赛表现,并以此预测胜负。
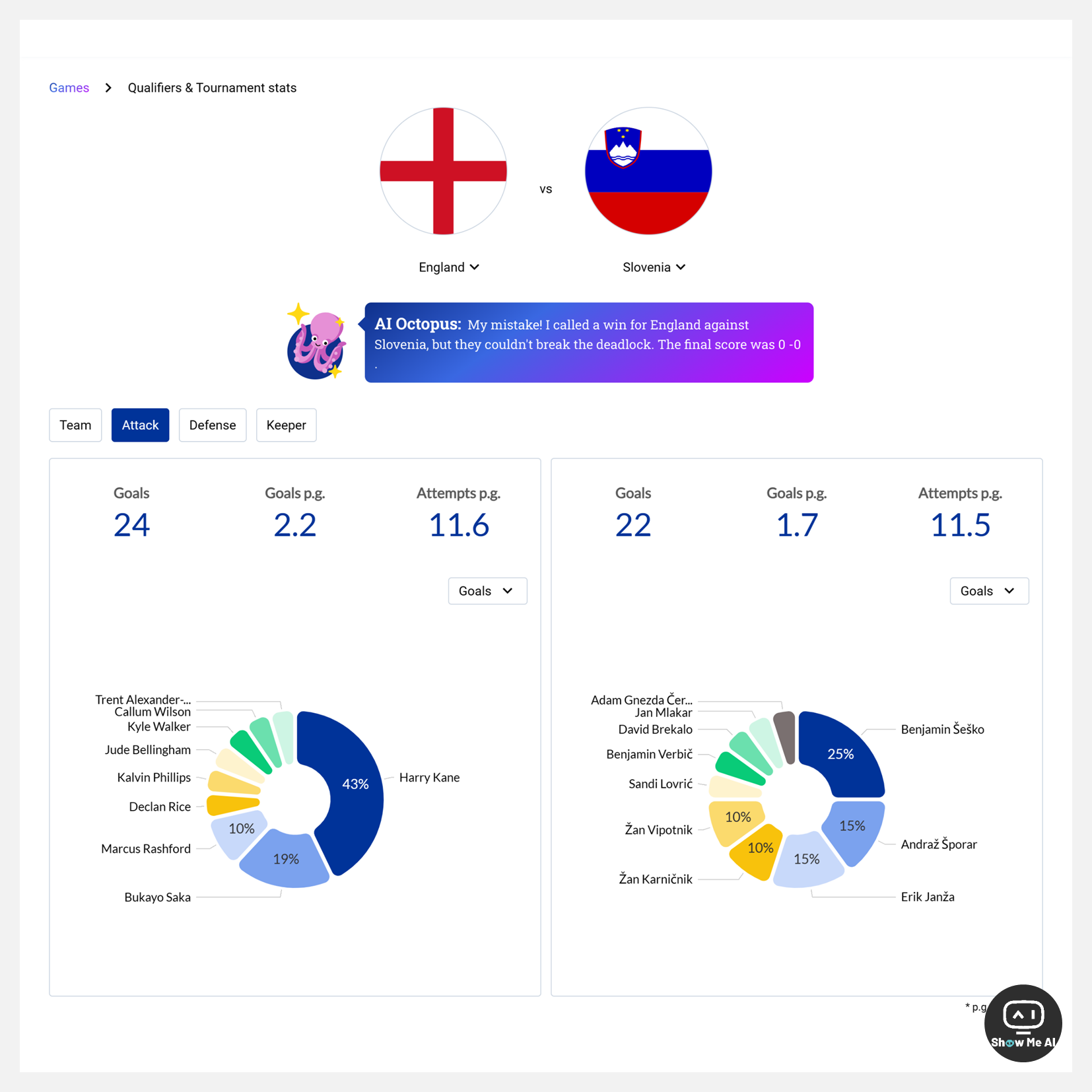
用户只需要点击「head to head」按钮,就可以查看当前小组赛中AI对两支球队的全方位预测分析,包括最终比分、比赛各阶段晋级概率、球员的攻防表现等等。
对比赛和AI都感兴趣的话!可以试试这个网站,感觉很有意思呀~
官网链接 → https://euro2024.luzmo.com/calendar
2. 该来的总会来的:环球+索尼+华纳起诉 Suno 和 Udio音乐侵权,索赔 3.5 亿美元

最近AI版权方向比较大的动静,应该就是环球音乐集团 (Universal Music Group) 、索尼音乐 (Sony Music) 华纳唱片 (Warner Records) 对AI音乐生成公司 Suno 和 Udio 提起的诉讼:指控这两家AI音乐公司训练模型使用的音乐素材,涉嫌大规模侵犯了三大唱片公司的版权。
这次起诉中一个比较重要的细节是,三大唱片公司非常具体地起诉 Suno 涉嫌抄袭 662 首歌,Udio 涉嫌抄袭 1670 首歌,每首歌索赔15万美元,共计索赔 3.5 亿美元。
这么具体的数字说明三件事。
-
以三大海量的曲库来看,662 + 1670 是非常微小的数字,这说明传统唱片公司要证明 AI侵权其实非常困难。当然这也可能是博弈策略,没有一次拿出所有的侵权证据。
-
三大想要的是钱,不是想消灭AI音乐。索赔金额 3.5 亿美元,对这两家AI公司而言肯定是拿不出来的,但也还有得谈。
这次的诉讼,与纽约时报曾经对 OpenAI 提起的版权诉讼类似,都借版权的由头,分未来AI世界的一杯羹。
所以,诉讼走向也大致类似,庭外讨价还价 (甚至不惜动用舆论手段) ,最终达成一个模式复杂的合作框架,通过多种方式进行收入分配,包括但不限于:打包年付授权费、按照 AI平台年收入分成、成立双方共同参与的产业联盟等等。
原文 → https://arstechnica.com/information-technology/2024/06/music-labels-sue-AI-music-generators-for-copyright-infringement/
说明:此条部分观点引自@杨樾
3. 文生视频的「可控性」测试集:10个用例,测出AI视频应用的成色

最近「AI视频」领域很火爆呀!Runway、PixVerse 更新,Luma、 (快手) 可灵发布,社群里的伙伴们测得不亦乐乎!!
准备了 10 个测试用例,都是精心设计的,可以帮助你快速摸到一款AI视频应用的「可控性」边界。
快快收藏吧!测试时直接复制,不仅快速高效,还能对生成结果有明确的分析方向~
[1] 测试目标:单场景,单主体,单一常见动作
- 中文提示:一位女孩在漂亮晚霞掩映的沙滩上跳芭蕾。
- 英文提示:A young girl is dancing ballet on the beach under a beautiful sunset.
[2] 测试目标:单场景,单主体,两个常见动作衔接
- 中文提示:一只狐狸跳过一把椅子,然后再跳回来。
- 英文提示:A fox jumped over a chair then jumped back.
[3] 测试目标:单场景,单主体,常见动作,主体的一部分拥有单独动作
- 中文提示:一辆高速行驶的汽车的左前轮脱落。
- 英文提示:A car’s left front wheel came off while it was speeding.
[4] 测试目标:单场景,单主体,常见动作,近景特写
- 中文提示:一只劳力士手表的秒针突然停止,特写镜头。
- 英文提示:The second hand of a Rolex watch suddenly stopped moving, close-view.
[5] 测试目标:单场景,双主体,常见动作,有虚构成分
- 中文提示:一只红色狐狸与一个女孩握手。
- 英文提示:A red fox and a young girl shake hands.
[6] 测试目标:单场景,单主体,常见动作,精确的位置描述
- 中文提示:在自顶向下的俯视镜头里,一只狐狸从麦田左上角跑到右下角。
- 英文提示:A fox runs from the upper left corner to the lower right corner of a wheat field in a top-down shot.
[7] 测试目标:单场景,双主体,连续两个常见动作,双主体间的位置关系
- 中文提示:一个男人越过一只奔跑的狐狸,然后跑进小木屋。
- 英文提示:A man jumped over a running fox then ran into a hut.
[8] 测试目标:单场景,单主体 (虚构人物) ,常见动作,精确道具控制
- 中文提示:一个外星人在白板上画出两个正方形。
- 英文提示:An alien draws two squares on a whiteboard.
[9] 测试目标:单场景,多主体,多个常见动作,精确的动作目标和动作顺序
- 中文提示:一个日本小姑娘把一只手表藏进橱柜,警察随即闯入并逮捕了小姑娘。 (为适应可灵的内容过滤,不得已改成了“一个小姑娘把一只手表藏进橱柜,厨师随即进入并拉住了小姑娘”)
- 英文提示:A young Japanese girl hides a watch in a closet, whereupon the police, who break in, quickly arrest the girl.
[10] 测试目标:单场景,多主体,虚构动作,复杂位置关系
- 中文提示:一辆无人骑行的自行车缓缓穿越道路,路边的旁观者纷纷露出惊讶、诧异的神情。
- 英文提示:A riderless bicycle slowly rides across the road, while the onlookers at the roadside show expressions of surprise and astonishment.
🔔 小结
-
抽卡。抽卡。抽卡。
-
快手可灵的提示词,要尤其注意规避系统敏感词 😂
-
快手可灵 VS Luma:单一主体,单一动作时,快手可灵对中文提示的理解准确度,好于 Luma 对英文提示的理解。
-
想单通过提示词就对生成结果的时间/空间关系做精确控制,或者多动作/较复杂动作的衔接&组合,或者较复杂的逻辑或交互,目前都还比较困难。
⋙ 阅读原文,可以观看测试对比视频
4. AI搜索应用「ThinkAny」开发者万字复盘:产品&技术的系统科普文

AI搜索 🔍 是少数业内形成共识的方向,因此大家纷纷下场:大厂开疆拓土,小厂垂直深挖,个人开发者积累手感。
最近,AI搜索领域又有几朵水花。
前百度高管景鲲和朱凯华创立的 Genspark,前阿里高管吴翰清 (道哥) 创立的快找找kFind,陆续走进公众视野。
科技媒体 Wired 在网站发文破口大骂「Perplexity is a bullshit machine」,点进去一看,原来是传统媒体和AI搜索引擎之间的胡扯头花。
Perplexity 之所以有此一劫,大概率是因为推出了 Pages 功能,即用户可以将包含图片、视频、文字的搜索结果页面,作为一篇文章进行发布。这一举动意在构建自己的内容生态,构建自产自销的闭环,却也极大侵蚀了传统出版商的生存空间。
AI搜索公司想要颠覆传统的搜索引擎,只有单边的检索生成功能是不足够的,打造内容生态势在必行。上面提到的 Genspark 主推的特色功能也是 Sparkpage。
GenSpark (需要魔法 🔮) → https://www.genspark.ai
快找找kFind (需要魔法 🔮) → https://kfind.kmind.com
Perplexity is a bullshit machine → https://www.wired.com/story/perplexity-is-a-bullshit-machine/

如果你想快速、清晰地了解「AI搜索」领域的技术、现状和发展趋势,那么强烈推荐你读 @艾逗笔 的新文章!
艾逗笔正在优化自己的AI搜索产品「ThinkAny」。
他在文中清晰地介绍了这款产品的诞生过程以及当前的运营数据 (UV 3K,PV 20K,月访问量近 600K,付费率 0.03%,还没有实现收支平衡),并基于此分析了 AI 搜索产品所涉及的技术栈、核心技术要点、以及如何差异化、如何提升准确度、如何提升可玩性、当前行业布局、未来发展方向等等,是一篇专业且真诚的分享~
日报挑选一些话题,整理了内容要点。原文精彩的介绍和总结超多!感兴趣可以直接阅读原文 📜
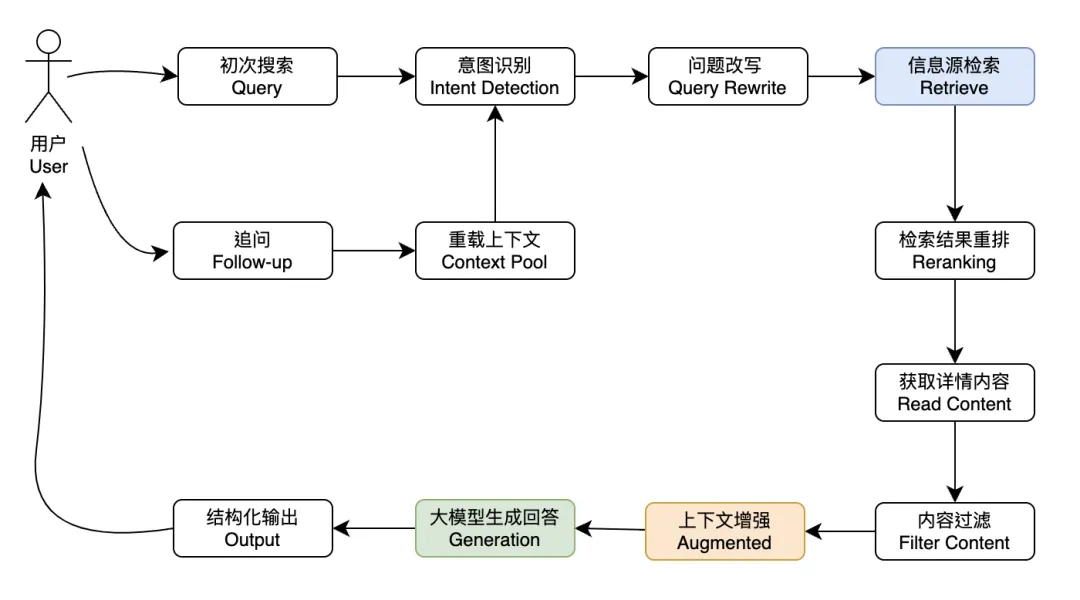
🔔 AI 搜索的标准流程
🔔 ThinkAny 的产品特性

🔔 AI 搜索如何提升准确度
-
意图识别 Intent Detection:通过分析用户查询,判断其搜索意图,并决定是否需要联网检索,以提高搜索效率。
-
问题改写 Query Rewrite:对用户查询进行精准改写,以增强检索的召回率和准确性。
-
多信息源聚合 Multi Source:整合不同来源的信息,提供全面的答案,增强搜索结果的丰富性。
-
搜索结果重排 Reranking:对检索结果进行重新排序,确保最相关的内容被优先展示。
-
搜索内容读取 Read Content:获取并分析链接的详细内容,以提升信息的深度和准确性。
-
构建上下文内容池 Context Pool:利用历史数据构建内容池,动态更新以支持更准确的搜索和回答。
-
提示词工程 Prompt Engineering:精心设计提示词,引导大模型提供更准确、更符合需求的回答。
-
多模态检索 Multi Mode:结合文本、图片、视频等多种信息形式,提高搜索结果的信息密度和多样性。
🔔 AI 搜索如何提升可玩性
-
AI 搜索平台化:构建开放的AI搜索平台,允许集成多样化的功能和第三方服务,增加用户互动和个性化体验。
-
开放接口 API:提供标准化的API接口,使其他应用能够快速集成AI搜索功能,促进技术应用的广泛传播。
-
自定义信息源 Source:允许用户指定个性化的信息源,实现更精准的搜索结果,满足特定需求。
-
自定义提示词 Prompt:用户可以设定个性化的提示词,影响AI的回答风格和内容,实现定制化服务。
-
自定义插件 Plugin:通过插件扩展AI搜索的功能,允许第三方参与创新,丰富平台的可用性。
-
自定义智能体 Agent:创建特定场景下的智能体,封装自定义操作,提供专业领域的搜索和回答服务。
-
工作流 Workflow:通过工作流编排,实现复杂搜索任务的自动化处理,提高效率并拓展应用场景。
🔔 对 AI 搜索的看法
-
AI 搜索引擎的第一要义是准确度。AI搜索引擎的核心在于提供高度准确的搜索结果。
-
ChatGPT自己做搜索,首先保证了问答底座模型的智能程度。ChatGPT通过使用先进的模型确保了问答系统的智能性。
-
我并不觉得大模型厂商自己做 AI 搜索 就一定会比第三方做的好。
-
做好 AI 搜索引擎,最重要的三点是准 / 快 / 稳,即回复结果要准,响应速度要快,服务稳定性要高。
-
AI 搜索引擎是一个持续雕花的过程。
-
AI Search + Agents + Workflows 是趋势。
-
我个人不是太看好垂直搜索引擎。垂直搜索引擎虽有特定优势,但可能面临市场规模和用户需求多样性的限制。
-
AI 搜索是一个巨大的市场,短时间内很难形成垄断。
-
AI 搜索引擎需要尽早考虑成本优化。
ThinkAny → https://thinkany.ai/zh
⋙ 阅读原文
5. AI工程师「搜索」必知 55 条,快速构建你的知识框架

@Doug Turnbull 这篇文章《What AI Engineers Should Know about Search》很不错!全文总结了「搜索」领域最高频、最重要的 55 条结论,是 AI 工程师非常好的入门引导。
-
选择向量数据库的重要性不如人们想象的那么高。相比之下,将检索解决方案的各个部分 (如词汇、向量、重排、查询理解等) 有机整合更为关键。越来越多的人已经意识到这一点,我们可能已经度过了盲目追捧向量数据库的热潮。
-
与那些看似花哨的解决方案相比,建立一个科学的评估框架来衡量搜索结果的质量,才是真正重要的。
-
标记搜索结果的相关性有多种方法,包括众包人工标注、分析点击流数据、利用大语言模型 (LLM) 通过提示评估搜索结果等。每种方法都有其优缺点。
-
在搜索领域,这些标记通常被称为「judgment 评判」。历史上,在TREC等早期信息检索竞赛中,「评判员」会对某个查询的搜索结果进行打分,判断其相关性。
-
不同的评估方法都存在各自的偏见。例如,在人工评估中,我们可能会遇到非专业人士的判断、评估者疲劳、以及人们倾向于认为靠前的结果比靠后的结果更相关等问题。
-
基于点击流的评判也有其局限性。我们只能为搜索系统返回的前 N 个结果 (即可点击的内容) 提供标签。同时,我们还需要应对用户出于本能点击不相关但吸引眼球的图片等情况。
-
搜索用户界面中的呈现偏差是一个不容忽视的问题。简而言之,用户只会点击他们看到的内容。
-
要克服呈现偏差,需要采取主动学习或强化学习的思路 - 我们既要「利用」当前对搜索相关性的理解,也要寻找「探索」新结果的方法。《AI Powered Search (AI驱动的搜索)》这本书第12章是解决这一问题的宝贵资源。
-
点击模型可以将点击流数据转化为评判结果。《Click Models for Web Search》这本书能帮你深入理解用户对搜索结果的点击和转化行为。
-
有许多指标可用于衡量查询的质量。例如,如果对「zoolander」进行查询并返回了一些搜索结果,我们可以参考这些评判来判断所提供的结果是否相关。(n) DCG、ERR、MAP、精确率、召回率、F1分数等统计指标在搜索行业中被广泛使用。
-
搜索总是伴随着精确率和召回率之间的权衡。如果你进行广泛搜索,可能会获得更多相关结果,但同时也可能向用户展示大量不相关的内容。
-
搜索专家经常谈到「信息需求」 - 这是对用户所需信息的一种非正式描述。用户通常通过多个查询来表达这种信息需求。
-
信息需求可能非常多样化 - 从通过 ID 查找特定商品,到比较/对比产品,再到对某一主题进行深入研究并整理笔记。每种需求都可能需要在排名和用户体验上进行特别处理。
-
用户的搜索方式正变得越来越复杂。他们对问答系统、社交媒体、电子商务、RAG 等有着不同的期望。
-
你可能听说过 BM25 算法。它本质上是对 TF*IDF 进行了大量调整和优化的算法。
-
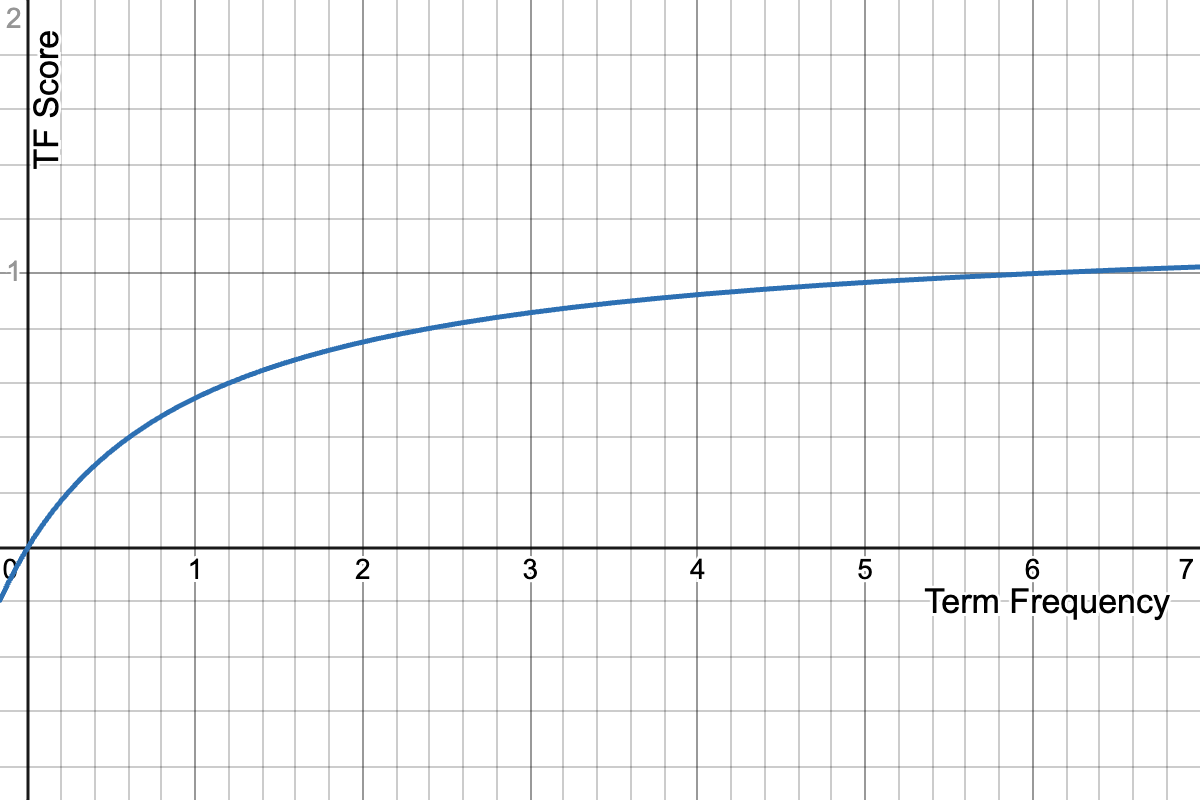
BM25 对 TF*IDF 中的词频部分进行了饱和处理。其背后的直觉是,相关性和词频并非线性关系,但在一个词被提及足够多次后,它并不会突然变得更加相关。
-
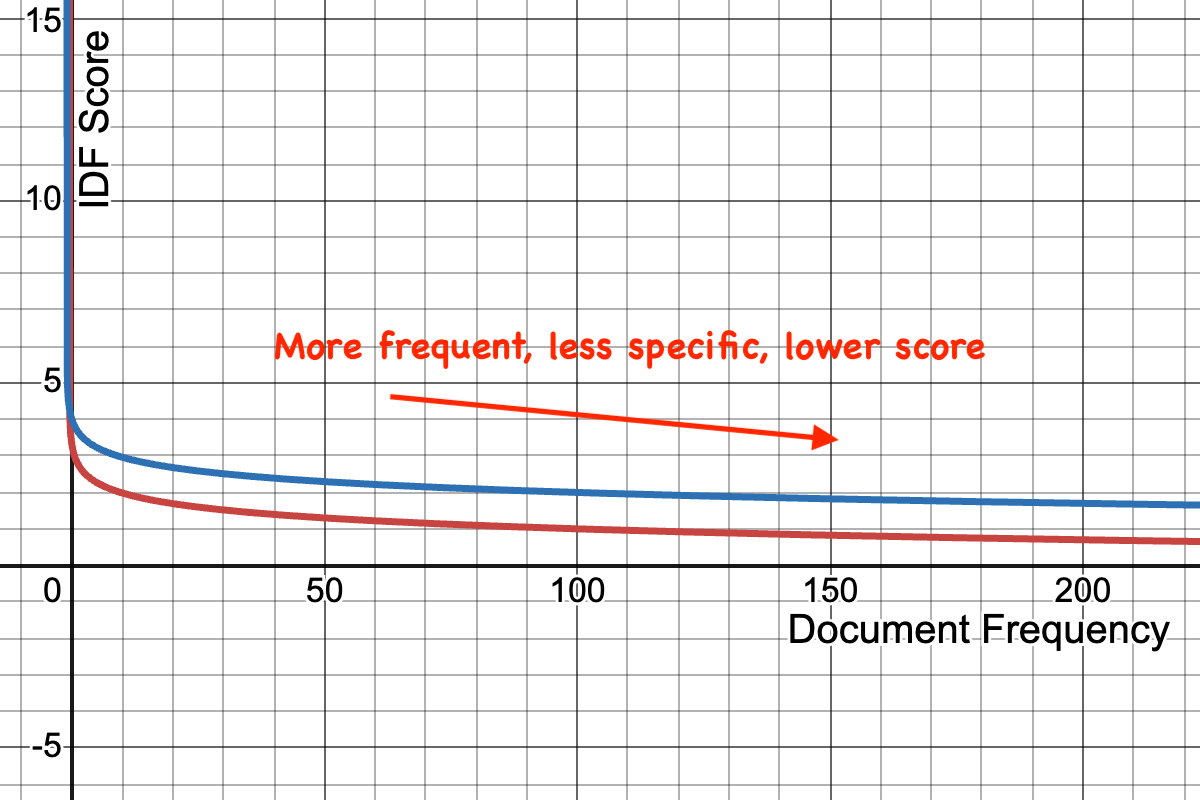
IDF (1/文档频率) 用于衡量一个词的特异性。词越罕见,对用户意图的重要性就越高。例如,在搜索 [luke] 或 [skywalker] 时,「skywalker」更为罕见和具体,因此得分更高。
-
实际上,IDF 并非原始的 IDF,每个相似度系统都有自己的非线性饱和 IDF 曲线。
- BM25还倾向于偏好较短的字段。因为在一条简短的推文中提到「Luke Skywalker」的可能性,远小于它在一本厚重的教科书中偶尔出现一次。
-
可以通过参数 k1 和 b 来调整 BM25。参数 k1 控制词频的饱和度 - 对于短文本片段可以很快达到饱和,而对于长文本片段则可以慢慢饱和。
-
参数 b 调整字段长度对得分的影响。如果将b设置得很高,那么超过平均长度的字段会受到更大的惩罚,而低于平均长度的字段受到的惩罚则较小。
-
BM25 只是众多词汇相似性评分方法中的一种。例如,Elasticsearch提供了多种选项,甚至包括相似度的脚本编写功能。
-
BM25F 是 BM25 的一个变种,它考虑了不同字段 (每个字段都有其独立的词项统计数据) 中的匹配情况。这里的「字段」指的是不同的文本属性,比如标题、摘要或标签等。
-
在许多词汇搜索引擎中,你可能会惊讶地发现,一个字段中的常见词在另一个字段中实际上非常罕见。这可能会干扰 BM25 的计算,导致一个看似不相关的文档意外地排在前面。
-
存在一些工具可以计算词项的「真正」特异性,这超出了直接的 IDF 计算范畴。例如,在不同字段间混合 IDF,或者将所有文本合并为一个大型字段。
-
合理组合和权衡不同字段非常重要。搜索中的字段扮演着不同的角色,需要分别进行分词和打分。例如,标题匹配的优先级应该高于正文中较难发现的内容。
-
搜索是一个生态系统的一部分。有些字段可能容易被用户滥用 (如关键词堆砌)。而有些字段由于其重要性,用户有强烈的动机保持其内容的真实性和相关性 (例如标题)。我们对每个字段的评分方式,很大程度上取决于我们对该内容的信任程度。
-
在搜索生态系统中,最有效的搜索策略之一是鼓励用户对他们的内容进行搜索引擎优化 (SEO)。这样,他们会主动调整内容以更好地适应我们的搜索算法,而不是我们去调整算法以适应他们的低质量内容。
-
搜索是生态系统的一部分 - 最糟糕的情况是用户意识到他们可以通过 SEO 来操纵我们的搜索结果,然后他们可能会滥用或调整内容,使其变成垃圾信息,甚至接近恶意行为。
-
分词不仅在词汇搜索中至关重要,在嵌入技术中也同样重要。分词 (如 n-gram、word-piece、整词分词) 以及相关的处理,如词干提取、标点符号处理等,可能会显著影响搜索的性能。
-
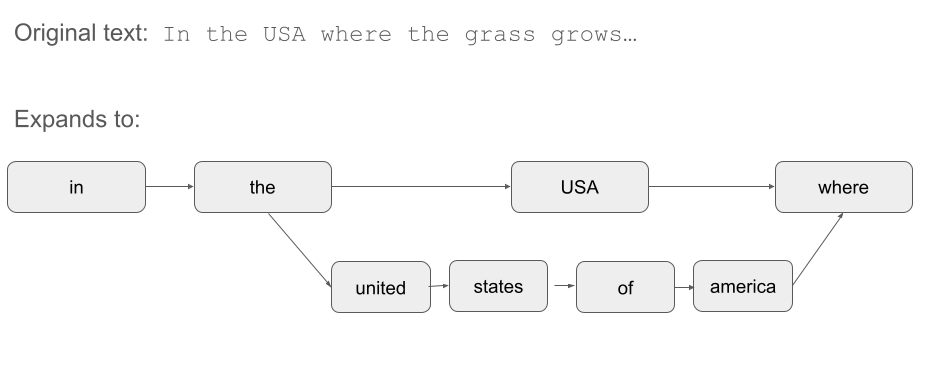
词汇分词流程实际上是一种图结构 - 在任何位置,等效的分词 (如同义词或不同的表达方式) 只是这个图上的一个分支,而且不同的分支可能长度不同 (例如,USA与United States of America)。
-
搜索不仅仅关乎词项匹配 - 短语也同样重要。短语对应于用户经常搜索的重要实体,或是人们标记在事物上的标签,或是我们预期的其他许多内容。在科学、工程或法律研究等专业领域,这一点尤其重要,因为那里的短语可能有非常特定的含义。
-
短语需要编码词项的位置 - 构建一个包含所有词项组合的庞大词汇表是不现实的。因此,词汇搜索系统必须在如 roaring bitmap 这样的数据结构中编码词项的位置。
-
由于短语需要分词,并且在给定位置可能产生等效的词项,它们本质上也是图结构!如果你希望 USA 被视为 United States of America 的同义词,那就是一个图结构。一个优秀的查询解析器必须将对「USA」的搜索视为对「USA」或「United States of America」的搜索。
-
某些词对在统计上经常一起出现,如「Palo Alto」或「Nacho Cheese」。这些被称为搭配,可以被视为一种「简单实体」。
-
词汇搜索不仅仅是关于BM25,更重要的是以一种尊重分词流程图结构本质的方式构建短语搜索。
-
通常,搜索系统由一系列的预处理 (如查询/意图理解) 和后处理 (如重排/后过滤) 阶段组成,在这些阶段之间有一个或多个检索引擎。
-
查询理解有多种形式。从广泛的、粗粒度的类别分类 (比如这是对一张图片的搜索),到从查询中提取实体 (比如这是关于「San Francisco」的搜索),再到将查询映射到向量以进行向量检索。
-
将机器学习应用于优化排名通常被称为「学习排序」。由于它涉及将相关结果在列表中优先于不相关结果,这可能与分类或回归等类型的机器学习有所不同。
-
学习排序功能有着悠久的研究历史。SVMRank 是一个简单的支持向量机,它使用二元分类器 SVM 对相关与不相关的对进行分类。LambdaMART 尝试使用梯度提升来优化列表式相关性度量,如 NDCG。
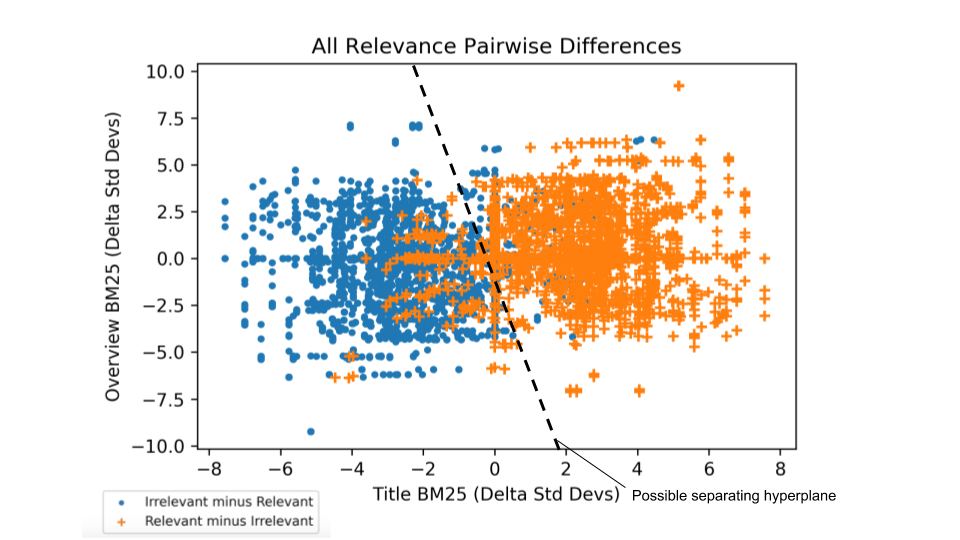
-
LambdaMART 就像 BM25 那样,是一种传统算法。虽然看起来有些老派,但它确实非常有效,值得学习。这里有一个附带笔记本的高质量博客文章,从零开始介绍了这个算法。
-
当存在大量词汇表特征时,LambdaMART 特别有用,比如你想要用于排名的各种统计数据。
-
LambdaMART 非常适合对成百上千的搜索结果进行相对低成本的重排。
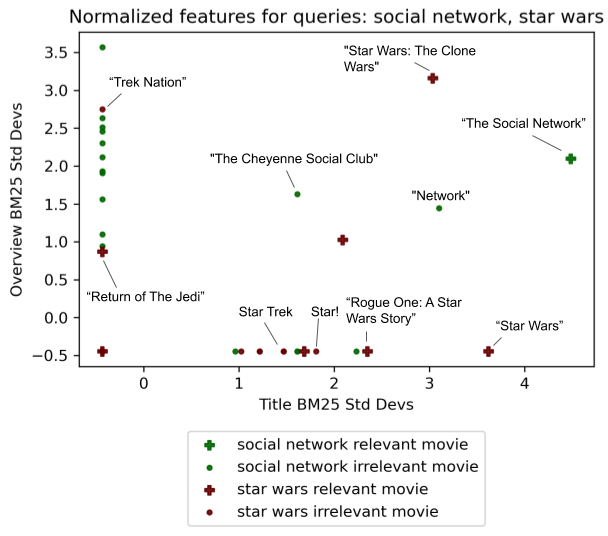
- 相关性与特征之间的关系往往非常非线性。有些因素,比如时效性,在搜索新闻时可能至关重要。而其他因素在搜索规范信息时可能更为重要。甚至在电影搜索中,相关性与标题/概述BM25之间的简单关系也是复杂的。
-
在学习排序的训练数据中,一个常用技巧是将其他查询的正面结果作为当前查询的负面例子进行采样 - 这类似于对比学习的思想。
-
拥有多个重排阶段是相当普遍的做法。从针对前 1000 个结果优化的简单重排器开始,到重排少量搜索结果的复杂交叉编码器。
-
流行的搜索系统 (如Solr、Elasticsearch、Vespa、OpenSearch) 在收集学习排序特征、存储和对排名模型进行推理方面的功能水平各不相同。
-
学习排序系统中的优质特征应该既与现有特征正交,又能增加价值。正交意味着它们测量不同的维度,可能来自不同的系统 (比如BM25与嵌入 vs ??),这几乎保证了没有一种通用的搜索解决方案。
-
排名和相似度是两个截然不同的概念!两段文本可能在相似度上很接近 (通过嵌入、BM25或其他方式测量),但仍然可能是垃圾信息、过时或价值低的内容。
-
有时候你并不需要一个复杂的重排器!很多人通过使用遗传算法或贝叶斯优化等技术,仅仅通过优化首次通过的评分就能取得不错的效果。
-
在搜索中,「取巧」是可以接受的!一个常见的技巧是构建一个集合,比如一个信号集合,它记住了对某个查询特别有吸引力的结果。然后当用户搜索时,你可以提升那些高度吸引人的内容 (或者降低那些已经有足够曝光机会的内容)。
-
可以将查询结果反馈给你的系统!通过跟踪交互的内容类型,你可以对你的查询了解很多。比如它们倾向于与哪一类内容相关联,或者哪种图像的嵌入倾向于被点击。了解关于相关性反馈的知识。
-
有许多工具可以为你的原型设计服务。从 SearchArray 到 BM25S,你可以试用不同的词汇解决方案来解决你的问题!
-
阅读 Manning 等人的《Introduction to Information Retrieval (信息检索导论)》。它是搜索领域的圣经,涵盖了搜索和检索的基本概念。
-
一定要查看关于搜索和信息检索的众多资源,一个很棒的资源列表在 Awesome Search Github 仓库中 → https://github.com/frutik/awesome-search
原文 → https://softwaredoug.com/blog/2024/06/25/what-ai-engineers-need-to-know-search

◉ 点击 👀日报&周刊合集 ,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ > 前往 🎡ShowMeAI ,获取结构化成长路径和全套资料库,用知识加速每一次技术进步!