《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》 (https://arxiv.org/abs/1810.04805)
摘要:前人优秀工作仅用了单向信息且不能很好的应用到各类下游任务,本文提出一种基于Transformer的双向处理预训练模型——BERT,在预训练完成后,采用统一的结构进行多个NLP下游任务微调,均达到SOTA。
BERT模型关键词:预训练;双向信息;MLM(Masked Language Model)预训练任务;NSP(Next Sentence Predict)预训练任务。
1.预训练相关工作
BERT之前的ELMo和GPT都是预训练机制,并且取得不错成绩,但他们都是基于单向的,存在缺点。 BERT为了解决单向预训练带来的不足,引入了MLM和NSP两个预训练任务,让模型能够从双向来理解语言。
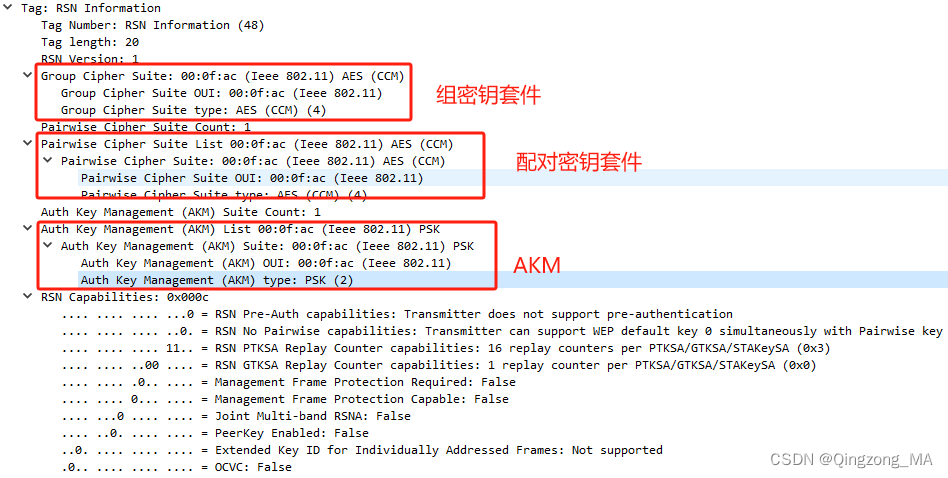
BERT模型结构
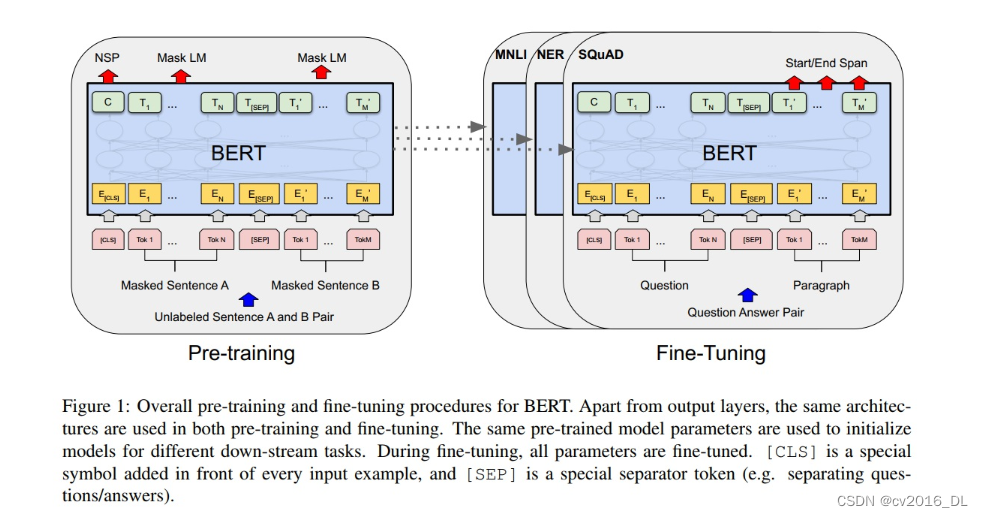
BERT的构建与使用分为两个阶段,预训练和微调。所有下游任务微调时,均采用预训练好的参数进行全局初始化、全 局训练。
BERT模型结构很简单,完全基于Transformer的encoder,并且有base和large两个版本,attention block、hidden size 和 head分别为(L=12, H=768, A=12, Total Parameters=110M) (L=24, H=1024,A=16, Total Parameters=340M)。
BERT的输入设计很巧妙,使得一个结构适应了多个NLP任务。输入设计为序列形式,将一个句子、两个句子都组装成为 一个序列,输入到模型中。输入上,设计了两个特殊的token,cls和sep。
cls:可以理解为序列的全局特征,用于文本分类、情感分析这类的seq2cls的任务。
sep:用于将句子1和句子2进行拼接的token。
在embedding处理上,设计了额外的segment embedding来标记句子是第一句、还是第二句。具体的输入embedding由 三部分组成,如下图所示:

2.BERT的预训练——MLM
BERT的第一种预训练任务是MLM(masked language model),是对一句话中的一些单词进行隐藏,然后让模型根据 上下文内容,在该mask的token位置上要求预测该单词。例如:“白切鸡” 经过MLM处理变为 “白mask鸡”,输入到BERT 模型,BERT模型的输出标签是“白切鸡“。
在进行mask是需要一定概率的,文章中对全文的15%的token进行遮罩,然后这15%里,80%真正变为mask,10%为随 机token,10%为原始token。这么做的原因是,下游任务中并没有mask这个特殊token,为了保障微调时的性能,这里做了这样的设置。( a downside is that we are creating a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. )
3.BERT的预训练——NSP
BERT的第一种预训练任务是NSP(Next Sentence Prediction),由于NLP任务中有一些是需要理解两个句子之间的关 系,例如QA和NLI任务。为了让BERT掌握句子之间的理解能力,设计了NSP。
NSP是一个二分类任务。输入的是两个句子组成的序列,输出的是IsText or Not Text。含义是这两个句子是否是前后两 句。论文举的例子:

预训练实验预训练采用了2个数据集:BooksCorpus (800M words) (Zhu et al.,2015) and English Wikipedia (2,500M words)。
预训练参数及耗时如下:bs=256, epoch=40, 100万step, 1万step预热, lr=1e-4, base:16个TPU训4天, large:64个TPU训4 天。
4.BERT的微调——下游任务
有了预训练好的BERT模型,可以快速方便的应用到各类NLP的下游任务,直接看下图列举的四种典型的任务:
(1)seq2cls:输入是多个句子,用sep拼接,输出用cls的特征向量接softmax实现分类。 (2)seq2cls:输入是单个句子,处理同上。
(3)seq2seq:输入是两段话构成的序列,输出是第二段话中要求各token输出3个类别,用于标记哪些是答案的开始、 答案的结束和无关内容。可以理解为词表为3的序列生成任务。
(4)seq2seq:输入是一句话,输出是每个token的分类类别,类别数根据任务而定,例如NER任务中,类别数是(实 体种类*2 + 1),一个实体需要两个类别,实体开始和实体结束两个标记,1表示无关类别。
5.下游任务微调实验
超参数基本固定,可以套用大部分任务:
Learning rate (Adam): 5e-5, 3e-5, 2e-5
Number of epochs: 2, 3, 4
Batch size: 16, 32
且采用的计算资源也很少,单个TPU一小时,单GPU几个小时即可,真实亲民的好模型。
7.论文小结
BERT是在ELMo和GPT之后提出来的一种基于Transformer的Encoder实现双向信息交互的预训练架构,并且可在一个模 型结构上实现多种下游任务的微调,具有统一结构。BERT对于NLP的预训练-微调,算得上开创性的作品,为NLP微调 范式打开了大门,后续的NLP任务大多基于BERT范式。
本论文需重点学习的几点如下:
1. BERT最大亮点是双向信息交互和MLM+NSP的预训练-微调范式;
2. MLM执行时,15%选中为mask候选token,再根据8:1:1比例进行真mask、随机token、原始token的设置
3. NSP任务采用sep特殊的token来拼接句子,实现一个序列输入,包含多个句子,sep的引入为模型统一多个任务提 供了可能
4. 预训练耗时4天,微调仅需数小时,此方案非常亲民。