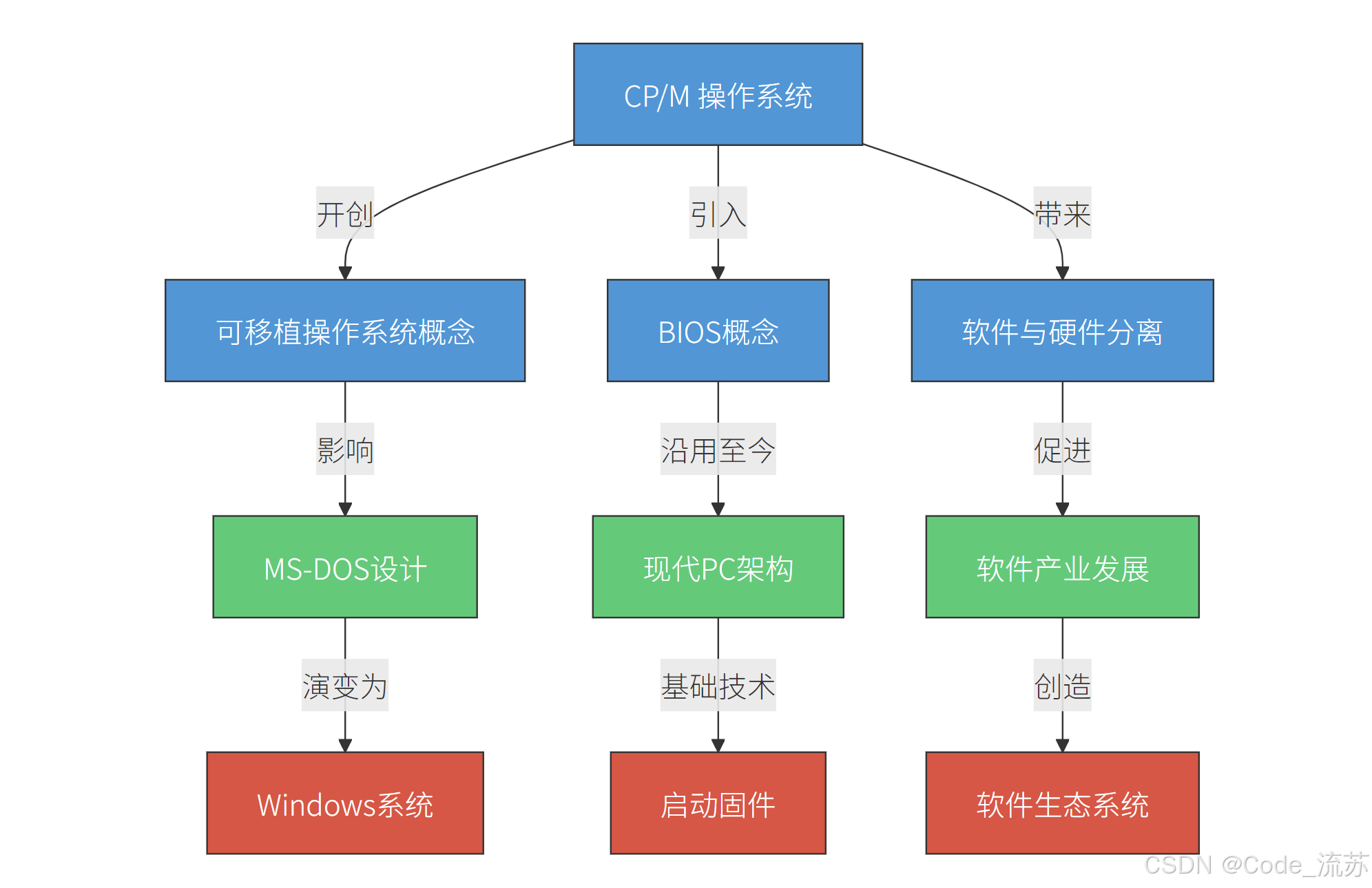
1. 分析 :
年轻代GC正常,说明年轻代的对象回收没有问题,可能大部分对象都是朝生夕死的,所以Minor GC能有效清理。但Full GC频繁,通常意味着老年代空间不足,导致频繁进行Full GC来回收老年代。而内存缓慢上涨,可能是有对象在慢慢积累,最终填满老年代。
2. 猜测:
可能的原因有几个:内存泄漏,某些对象无法被回收,逐渐进入老年代;或者大对象直接分配在老年代,比如大数组;还有可能是元空间或永久代的问题,不过这个通常会有不同的表现。另外,JVM参数设置不当,比如老年代过小,或者没有合适的GC策略,也可能导致Full GC频繁。
3. 验证:
检查 JVM 参数
# 查看堆内存分配、GC策略等参数
jinfo -flags <pid>
关注 -Xmx(最大堆)、-Xms(初始堆)、-XX:NewRatio(年轻代/老年代比例)等参数是否合理。
观察 GC 日志
# 添加GC日志参数后重启应用
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/path/to/gc.log
关键指标:Full GC 触发频率、老年代回收前后使用率变化。
二、内存泄漏定位
监控老年代内存走势:
# 每5秒采样一次,持续观察
jstat -gcutil <pid> 5000
关注:OU(老年代使用率)是否在 Full GC 后持续上涨,若无法回落则存在内存泄漏
堆内存分析:
# 生成堆转储文件
jmap -dump:live,format=b,file=heap.hprof <pid>
# 1. 快速定位可疑类(无需停机)
jmap -histo:live <pid> | head -n20
# 2. 对比两次采样结果(间隔2小时)
diff <(jmap -histo:live <pid>) <(ssh user@host "jmap -histo:live <pid>")
# 重点关注Object、byte[]、自定义类实例数增长
# 3. 轻量级堆分析(当无法生成完整dump时)
jcmd <pid> GC.class_histogram | grep -E 'MyService|Processor'
特殊场景检查清单
1.元空间泄漏:
# 监控元空间使用
jstat -gcmetacapacity <pid>
# 常见问题:未设置MaxMetaspaceSize(默认无限制但会触发GC)
JVM参数建议:-XX:MaxMetaspaceSize=512m
2.堆外内存泄漏
# 检查NIO DirectBuffer使用
jcmd <pid> VM.native_memory summary | grep 'Internal (reserved)'
3. jvm 参数调整
# 生产环境推荐基线配置
-Xmx4g -Xms4g
-XX:NewRatio=3 # 老年代与年轻代1:3
-XX:SurvivorRatio=8 # Eden与Survivor区8:1:1
-XX:MaxMetaspaceSize=512m
-XX:+UseG1GC # 推荐G1收集器
-XX:InitiatingHeapOccupancyPercent=45 # 降低Full GC触发阈值