由于最近涉及下游任务微调,预训练任务中的框架使用的是pytorch-lightning,使用了典型的VLP(vision-language modeling)的训练架构,如Vilt代码中:https://github.com/dandelin/ViLT,这类架构中只涉及到预训练,但是在下游任务中微调没有出现如何调参的过程。因此可以使用wandb的sweeps来对下游任务进行超参数搜索。
- 问题
Vilt的目录结构:
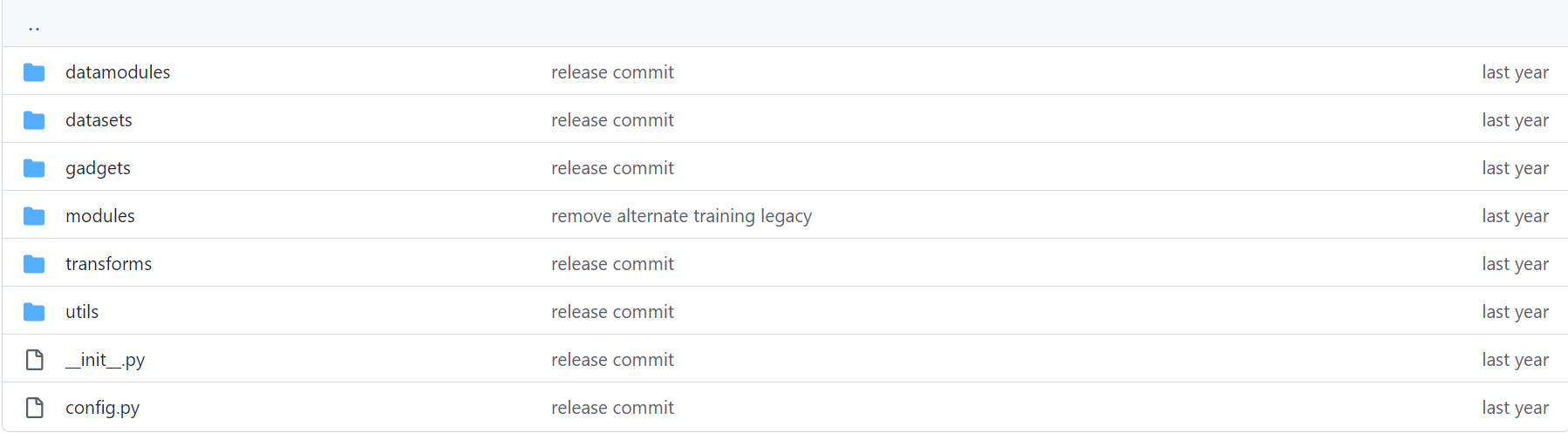
这类预训练大模型,涉及到大量的参数,这些参数均使用Sacred框架进行统一管理(放在上图中的config.py文件中),其中大部分的参数是固定的(即预训练模型固定参数),下游任务只是对学习率、batch_size、最后一层全连接层等的配置,因此我们超参数搜索只是其中一小部分,然而对wandb的超参数搜索sweeps来说,它有自带的参数管理,因此两者的参数管理会存在冲突。
2、解决问题
第一步:定义sweeps 配置,设置超参数搜索方法和搜索范围
新建一个文件夹,用于存储sweeps的配置,命名为sweeps_config.py:
# sweeps_config.py
import math
sweep_config = {
"name": "sweep_with_launchpad", # 自定义,用于命名sweep超参数的名称
"metric": {"name": "val/the_metric", "goal": "maximize"}, # 监控指标,name值应为wandb.log对象中出现key值,goal为maximize或者minimize
"method": "grid", # 搜索方式,这里为网格搜索,还有"random"等设置
"parameters": { # 搜索的范围
"batch_size": {
"value": 128
},
"max_steps": {
"value": 100 # 如果是值,注意为"value"
},
"max_epoch": {
"value": 100
},
"learning_rate": {
"values": [5e-6,1e-5,5e-5] # 如果是范围,注意为"values"
}
}
}第二步:初始化sweep
在主函数main中,初始化sweep:
sweep_id = wandb.sweep(sweep_config,project='myCLIP') # project是在wandb中的项目名称第三步:代码嵌入
由于模型已经预训练好了,模型结构基本不变,仅仅微调,因此新建finturn.py文件作为微调的运行文件,代码如下:
import os
import numpy as np
import random
import time
import datetime
import torch
import copy
from config import ex
import pytorch_lightning as pl
from datamodules.datamodules_multitask import MTDataModule
from models.myCLIP import myCLIP
from hyparam_search.sweep_config import sweep_config # 导入搜索范围
from pytorch_lightning.loggers import WandbLogger
import wandb
wandb.login()
os.environ["TOKENIZERS_PARALLELISM"] = "false"
@ex.automain
def main(_config):
# 初始化参数
start_time = time.time()
# _config是Scale管理的参数,即config.py中的参数
_config = copy.deepcopy(_config)
if _config['is_pretrain'] == False: # 下游微调
sweep_id = wandb.sweep(sweep_config,project='myCLIP') # 这是第二步中的初始化sweep
# wandb.init(project="") # 此处不能init,如果init了,会报错。
# 训练函数
def train(config=None):
# 设置种子
pl.seed_everything(_config["seed"])
#################################(下面为重点代码)#####################################
with wandb.init(config=None): # 初始化wandb
# print(wandb.config)
config = wandb.config # 如果调用了wandb.agent函数,wandb.config会对sweep_config中的参数自动更新,选择一组未被使用过的超参数。每调用一次train,超参数config会更新一次
print(config)
_config.update(config) # 将config中选出的训练参数更新到_config中,用于训练模型
print(_config)
#################################(下面为正常设置)#####################################
dm = MTDataModule(_config, dist=False)
model = myCLIP(_config)
exp_name = f'{_config["exp_name"]}'
# 日志打印文件
os.makedirs(_config["log_dir"], exist_ok=True)
# checkpoint保存配置
checkpoint_callback = pl.callbacks.ModelCheckpoint(
save_top_k=1,
verbose=True,
monitor="val/the_metric", # 想监视的指标
mode=_config['mode'],
save_last=False,
dirpath=_config['checkpoint_save_path'],
filename="{epoch:02d}-{global_step}-64",
)
wandb_logger = WandbLogger(project="myCLIP")
# 学习率回调函数
lr_callback = pl.callbacks.LearningRateMonitor(logging_interval="step")
callbacks = [checkpoint_callback, lr_callback]
num_gpus = (
_config["num_gpus"]
if isinstance(_config["num_gpus"], int)
else len(_config["num_gpus"])
)
# 4096 / (4*1*1)
grad_steps = max(_config["batch_size"] // (
_config["per_gpu_batchsize"] * num_gpus * _config["num_nodes"]
), 1)
max_steps = _config["max_steps"] if _config["max_steps"] is not None else None
trainer = pl.Trainer(
gpus=_config["num_gpus"], # 使用gpu列表
num_nodes=_config["num_nodes"], # 节点数
precision=_config["precision"], # 指定训练精度
accelerator="cuda", #
benchmark=True,
deterministic=not _config['is_pretrain'], # 预训练为False,用到了gather函数。微调用True,可复现
max_epochs=_config["max_epoch"] if max_steps is None else 200,
max_steps=max_steps,
callbacks=callbacks, # 回调函数,保存checkpoint
logger=wandb_logger, # 打印日志
replace_sampler_ddp=False, #
accumulate_grad_batches=grad_steps, # 每k次batches累计一次梯度
log_every_n_steps=10, # 更新n次网络权重后记录一次日志
resume_from_checkpoint=_config["resume_from"], #
fast_dev_run=_config["fast_dev_run"],
val_check_interval=_config["val_check_interval"],
# strategy="ddp_find_unused_parameters_false"
)
# 训练
if not _config["test_only"]:
trainer.fit(model, datamodule=dm)
# 调用agent函数,这是第四步:运行
wandb.agent(sweep_id, train, count=50)
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print('Training time {}'.format(total_time_str))第四步:运行
启动一个运行 10 次训练的agent,使用 Sweep Controller 返回的网格生成的超参数值。
sweep_id : 是第二步中初始化时的id。
train : 是第三步中main函数中嵌入的train函数。
count :一个整数值,自定义。
wandb.agent(sweep_id, train, count=10)执行代码sh:
python finturn.py with task_finetune第五步:实验记录
进入wandb官网(友好上网),登录后进入project(我的是"myCLIP"),进入后点击Sweeps列表,即可看到该次运行的结果:


参考资料:
https://zhuanlan.zhihu.com/p/436385177
https://docs.wandb.ai/ref/python/agent