本篇是 minibend 系列的第二期,将会介绍 Data Source 部分的设计与实现,当然,由于是刚开始涉及到编程的部分,也会提到包括 类型系统 和 错误处理 之类的一些额外内容。
前排指路视频和 PPT 地址
视频(哔哩哔哩):https://www.bilibili.com/video/BV1A84y1Y7Ff/
PPT:https://psiace.github.io/databend-internals/minibend/ppt/minibend-002-datasource.pdf
类型系统和 Arrow
这里仅仅是进行一个初步的介绍,类型系统相关的实现请期待下一期内容。
类型系统
在构建查询引擎的时候,很重要的一个问题就是「数据在查询引擎中是如何表示的?」。这往往意味着我们需要考虑引入一套类型系统来完成这一工作。
为了能够让查询引擎处理来自不同数据源的数据,通常情况下,会选择设计并构建一套能够涵盖所有数据源所涉及的全部数据类型的类型系统,并引入一些额外的机制使得数据能够从数据源轻松转换到这套类型系统之上。
当然,如果查询引擎仅仅针对单一数据源设计,或许可以考虑复用数据源的类型系统。
行存或者列存
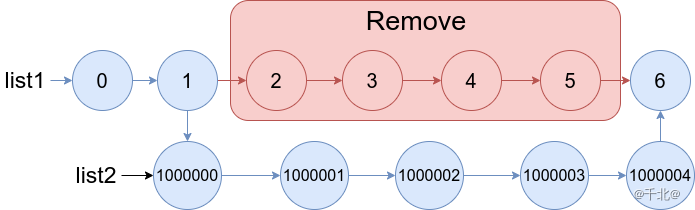
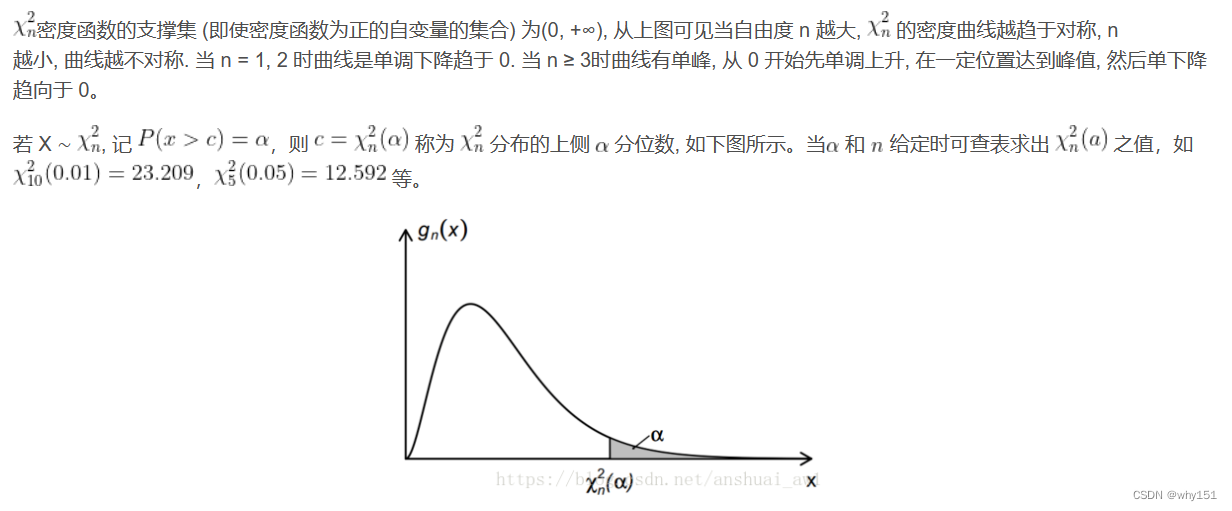
解决了数据类型的问题,那么就该考虑数据存储时候的模型。行式存储和列式存储都属于流行的方案,当然,这往往取决于要面对什么样的查询任务。另外还有混合行式和列式存储的方案,但这并不在今天讨论的范畴之中。
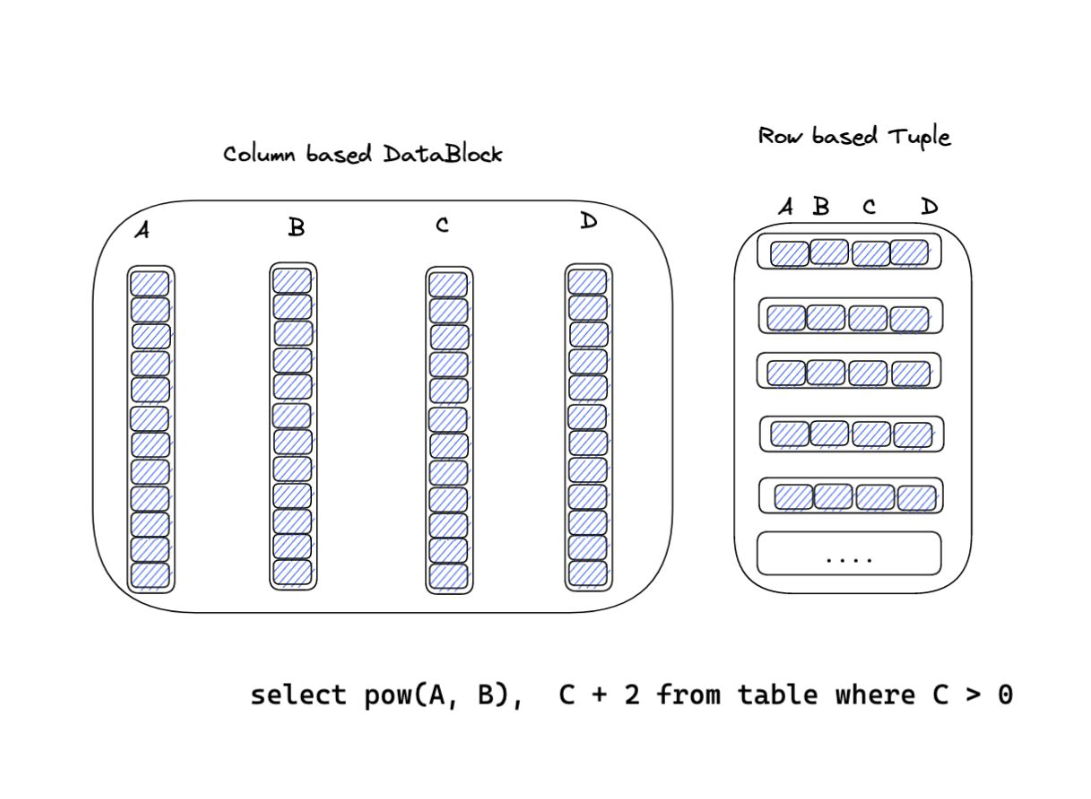
而行式存储则如右图所示,同一行的数据在内存中是连续的。
对于 OLAP 系统,往往处理大量数据,更需要关注数据的吞吐量和执行效率,采用列式存储具有天然的优势。
- 只需要读取需要的列,无需经 IO 读取其余列,从而避免不必要的 IO 开销。
- 同一列的数据中往往存在大量的重复项,压缩率会非常高,进一步节约 IO 资源。
- 利用向量化处理和 SIMD 指令进行优化,提高性能。
Arrow
Apache Arrow 是一套通用、跨语言、高性能的列式数据内存格式规范,能够充分利用现代硬件的向量化执行能力。
通过引入 Apache Arrow 作为标准的数据交换格式,可以有效提高各种大数据分析系统和应用程序之间的互操作性:
- 高级语言在调用低级语言时,可以通过指针来传递数据,从而免于复制数据。
- 数据可以在进程之间有效地传输,减少序列化开销。
- 可以在各种开源和商业项目之间建立连接,使得大数据生态之间能够更好集成。
Apache Arrow 现在有多种不同语言的实现,包括 C++、Java、Rust 等。
值得关注的基于 Apache Arrow 的 Rust 实现的项目包括 pola-rs/polars、apache/arrow-datafusion,当然,还有 Databend 。
从 Databend 到 minibend
Databend 是面向海量数据设计的云数仓,面向分析型工作负载进行设计,采用列式存储,使用 Apache Arrow 作为内存格式规范,并在此基础上设计开发类型系统。minibend 在这一点上将会与 Databend 保持一致。
有趣的事实
Databend 当前实现使用的是 arrow2 而非 arrow-rs ,主要有以下几个原因:
- arrow2 代码质量更高,设计上弥补了很多 arrow-rs 的缺点。
- Databend 早期也是基于 arrow-rs ,但是 arrow-rs 推动 issue、pr 流程较慢,不适合 Databend 的快速迭代节奏。而 arrow2 的作者往往能够提供更加及时和友好的建议和修复,可以和 Databend 一同快速迭代。
Databend 从 arrow2 0.1 和 parquet2 0.1 发布 开始 考虑向 arrow2 迁移 ,十天左右完成 [commons] arrow -> arrow2 并在部分查询上获得性能提高。尽管从当时而言,切换到还处于早期的 arrow2 有些激进,但长远来看是利大于弊的。
Data Source
Data Source(数据源)是数据处理系统的重要部分,但通常只能依赖经验来谨慎处理。
数据源
顾名思义,数据源就是数据的来源,倘若没有数据源,数据处理系统就像无根浮萍,自然也谈不上用武之地。
数据源可以以不同的形态出现,比如各种各样格式的文件:CSV、JSON、Parquet 等;当然也可以是数据库,之前有很多朋友问过比如 Databend 能不能查询 MySQL 里面的数据(将 MySQL 作为数据源);也可以是内存对象,一个不那么典型的例子是 Databend 里面实现了用于测试向量化性能的 number 表。
与不同数据源交互的处理逻辑也有所不同,为了能够更好接入不同数据源,查询引擎需要定义一套统一的接口,并确保能够返回符合预期的数据。对于查询引擎而言,主要关心两类数据:一类是 schema ,用来描述数据的结构,这可以帮助查询引擎对查询计划和表达式进行验证,但并不是所有数据都具有统一的/有效的结构,比如 JSON ;另一类就是具体的数据了,但考虑到查询引擎只需要处理关心的特定数据,所以应该有能力对数据进行过滤,只提取需要的列。
Parquet
ApacheParquet 是一种开源的、面向列的数据文件格式,用于高效的数据存储和检索。它提供了高效的数据压缩和编码方案,增强了处理大量复杂数据的性能。Parquet 支持多种语言,包括 Java、 C + + 、 Python 等等。.
Parquet 受到 Google Dremel 格式启发,作为大数据领域的存储格式,被 iceberg 、hive 等各种系统使用。

上图展示了 Parquet 文件的结构,Parquet 的存储模型主要由行组(Row Group)、列块(Column Chuck)、页(Page)组成。
- 行组,Row Group:Parquet 在水平方向上将数据划分为行组,默认行组大小与 HDFS Block 块大小对齐,Parquet 保证一个行组会被一个 Mapper 处理。
- 列块,Column Chunk:行组中每一列保存在一个列块中,一个列块具有相同的数据类型,不同的列块可以使用不同的压缩。
- 页,Page:Parquet 是页存储方式,每一个列块包含多个页,一个页是最小的编码的单位,同一列块的不同页可以使用不同的编码方式。
从 Databend 到 minibend
Databend 的底层存储格式为 Parquet ,过去其他格式的数据需要通过 Streaming Load 或者 Copy Into 等方式转换到 Databend 支持的 Parquet 格式。而在近期的设计和实现中,Databend 开始逐步实现对位于本地/远端的文件进行查询的支持。
minibend 将会考虑优先从查询本地现有数据文件开始进行支持。首先是支持 Parquet 作为数据源,但为了方便浏览数据和审计查询结果,或许对 CSV 格式的支持应该提上日程。
有趣的事实
Databend 中同样包含读取 Parquet 文件作为数据源的代码。关于读取 Parquet 文件作为表的第一版实现可以参考 new table function read_parquet to read parquet files as a table 。
在这个基础上,受 clickhouse-local 启发,@eastfisher 为 Databend 实现 databend-local,支持在不启动 Databend 集群的情况下查询本地文件。
代码时间
请查阅视频和 PPT 中的对应部分,或者查看 PR #40 | minibend: impl parquet data source 中的代码。
前进四:回顾与展望
回顾
在今天的内容中,我们简单介绍了类型系统和数据源的一些相关内容:
- 类型系统用于处理数据在查询引擎中的表示。
- 对于 OLAP 系统而言,基于列式存储会更能发挥现代硬件的能力。
- 数据源可以是多种多样的,文件、数据库、内存对象都可以作为数据源。
- Apache Arrow 和 Apache Parquet,前者是一套通用、跨语言、高性能的列式数据内存格式规范,后者是一种旨在实现最大空间效率的存储格式。
当然,在这一期的代码时间,我们初步建立了 minibend 的基础,并支持使用 Parquet 文件作为数据源。
展望
下一期,我们将会进入到类型系统相关的部分,并进一步扩展到逻辑计划和表达式。
阅读材料
这一次推荐两个博客给大家:
一个是 风空之岛 ,@mwish 的技术博客,有关于 Parquet 的一个更详细的系列介绍,并且还有论文阅读的部分。
另一个是 数据库内核月报 ,来自阿里云 PolarDB 数据库内核团队。