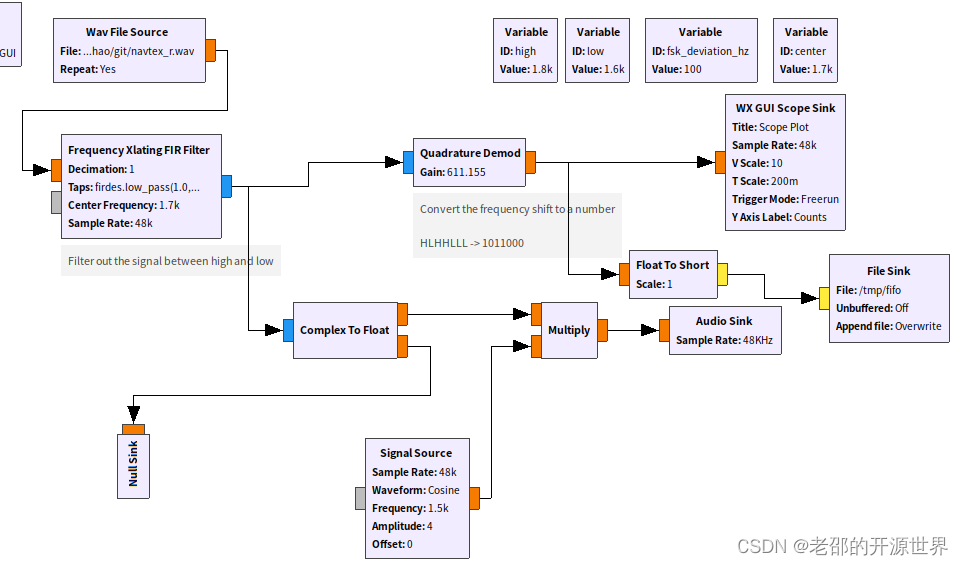
C语言源文件要经过编译、链接才能生成可执行程序:
1) 编译(Compile)会将源文件(.c文件)转换为目标文件。对于 VC/VS,目标文件后缀为.obj;对于GCC,目标文件后缀为.o。
编译是针对单个源文件的,一次编译操作只能编译一个源文件,如果程序中有多个源文件,就需要多次编译操作。
2) 链接(Link)是针对多个文件的,它会将编译生成的多个目标文件以及系统中的库、组件等合并成一个可执行程序。
在实际开发中,有时候在编译之前还需要对源文件进行简单的处理。例如,我们希望自己的程序在 Windows 和 Linux 下都能够运行,那么就要在 Windows 下使用 VS 编译一遍,然后在 Linux 下使用 GCC 编译一遍。但是现在有个问题,程序中要实现的某个功能在 VS 和 GCC 下使用的函数不同(假设 VS 下使用 a(),GCC 下使用 b()),VS 下的函数在 GCC 下不能编译通过,GCC 下的函数在 VS 下也不能编译通过,怎么办呢?
这就需要在编译之前先对源文件进行处理:如果检测到是 VS,就保留 a() 删除 b();如果检测到是 GCC,就保留 b() 删除 a()。
这些在编译之前对源文件进行简单加工的过程,就称为预处理(即预先处理、提前处理)。
预处理主要是处理以#开头的命令,例如#include <stdio.h>等。预处理命令要放在所有函数之外,而且一般都放在源文件的前面。
预处理是C语言的一个重要功能,由预处理程序完成。当对一个源文件进行编译时,系统将自动调用预处理程序对源程序中的预处理部分作处理,处理完毕自动进入对源程序的编译。
编译器会将预处理的结果保存到和源文件同名的.i文件中,例如 main.c 的预处理结果在 main.i 中。和.c一样,.i也是文本文件,可以用编辑器打开直接查看内容。
C语言提供了多种预处理功能,如宏定义、文件包含、条件编译等,合理地使用它们会使编写的程序便于阅读、修改、移植和调试,也有利于模块化程序设计。
实例
下面我们举个例子来说明预处理命令的实际用途。假如现在要开发一个C语言程序,让它暂停 5 秒以后再输出内容,并且要求跨平台,在 Windows 和 Linux 下都能运行,怎么办呢?
这个程序的难点在于,不同平台下的暂停函数和头文件都不一样:
Windows 平台下的暂停函数的原型是void Sleep(DWORD dwMilliseconds)(注意 S 是大写的),参数的单位是“毫秒”,位于 <windows.h> 头文件。
Linux 平台下暂停函数的原型是unsigned int sleep (unsigned int seconds),参数的单位是“秒”,位于 <unistd.h> 头文件。
不同的平台下必须调用不同的函数,并引入不同的头文件,否则就会导致编译错误,因为 Windows 平台下没有 sleep() 函数,也没有 <unistd.h> 头文件,反之亦然。这就要求我们在编译之前,也就是预处理阶段来解决这个问题。请看下面的代码:
#include<stdio.h>
//不同的平台下引入不同的头文件
#if _WIN32 //识别windows平台
#include<windows.h>
#elif __linux__ //识别linux平台
#include<unistd.h>
#endif
intmain(){
//不同的平台下调用不同的函数
#if _WIN32 //识别windows平台
Sleep(5000);
#elif __linux__ //识别linux平台
sleep(5);
#endif
puts("http://csdn.net/");
return0;
}#if、#elif、#endif 就是预处理命令,它们都是在编译之前由预处理程序来执行的。这里我们不讨论细节,只从整体上来理解。
对于 Windows 平台,预处理以后的代码变成:
#include<stdio.h>
#include<windows.h>
intmain(){
Sleep(5000);
puts("http://csdn.net/");
return0;
}对于 Linux 平台,预处理以后的代码变成:
#include<stdio.h>
#include<unistd.h>
intmain(){
sleep(5);
puts("http://csdn.net/");
return0;
}你看,在不同的平台下,编译之前(预处理之后)的源代码都是不一样的。这就是预处理阶段的工作,它把代码当成普通文本,根据设定的条件进行一些简单的文本替换,将替换以后的结果再交给编译器处理。