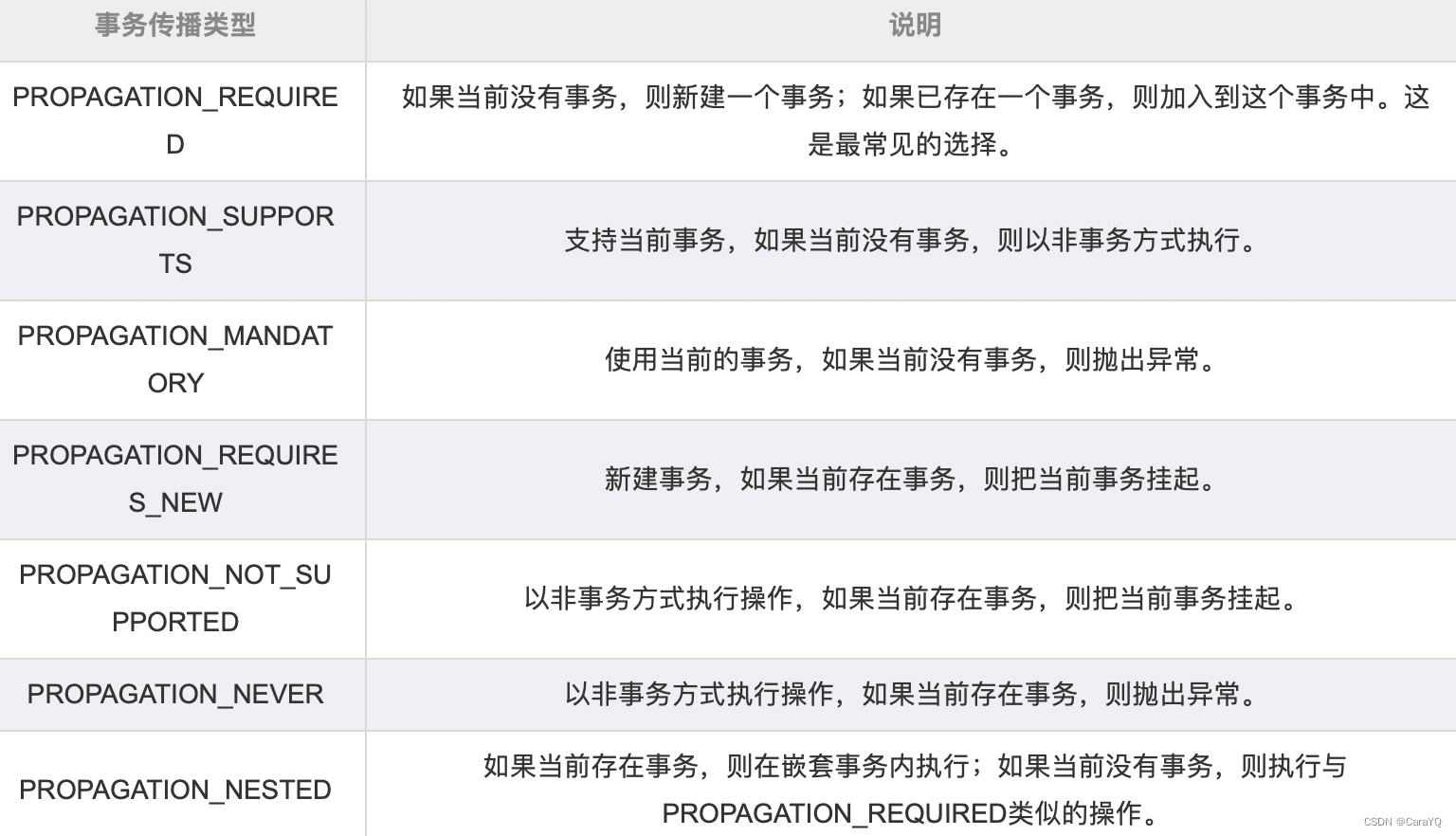
文章目录
- 一、概述
- 二、变量
- 1)变量定义
- 2)定义变量的规则
- 3)变量命名规范
- 4)变量类型转换
- 三、注释
- 1)单行注释
- 2)多行注释
- 1、单引号(''')注释
- 2、双引号(""")注释
- 四、运算符
- 1)算术运算符
- 2)关系运算符
- 3)赋值运算符
- 4) 逻辑运算符
- 5)位运算符
- 1、位与运算(A&B)
- 2、位或运算(A|B)
- 3、异或位运算(A^B)
- 4、按位取反运算(~A)
- 5、左右位移
- 五、数据类型
- 1)String(字符串)
- 1、创建字符串
- 2、字符串连接
- 3、字符串切片
- 4、字符串常用方法
- 【1】count()方法
- 【2】find()方法
- 【3】index()方法
- 【4】lower()方法和upper()方法
- 【5】lstrip()方法、rstrip ()方法和strip()方法
- 【6】replace() 方法
- 5、格式化字符串
- 【1】 %操作符
- 【2】format()方法
- 2)List(列表)
- 1、创建列表
- 2、访问列表中的值
- 3、更新列表
- 4、删除列表元素
- 5、列表截取与拼接
- 6、常用方法
- 3)Tuple(元组)
- 1、创建元组
- 2、访问元组
- 3、修改元组
- 4、删除元组
- 5、元组截取
- 6、常用函数
- 4)Dictionary(字典)
- 1、创建字典
- 2、访问字典里的值
- 3、修改字典
- 4、删除字典元素
- 5、常用方法
- 5)Set(集合)
- 1、创建集合
- 2、访问集合元素
- 3、添加集合元素
- 4、移除元素
- 5、常用函数
- 六、流程控制
- 1)选择结构
- 1、if语句
- 2、match..case语句
- 3)循环结构
- 1、while语句
- 2、for语句
- 4)break 和 continue 语句
- 1、break 语句
- 2、continue 语句
一、概述
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的解释性编程语言。其实python的基础语法跟其它编程语言都非常类似,只是写法有些不一样而已。
关于Python更详细的介绍和环境准备可以参考我这篇文章:Python 介绍和环境准备
二、变量
1)变量定义
语法规则:
变量名 = 值
变量名 = 变量名 = 值
例如:
var1 = 123
var2 = var3 = 456
定义变量的语法规则中间的=,并不是数学中等于号的意思,在编程语言中而是赋值的意思。赋值:其实程序在执行的时候,先计算等号(=)右边的值,然后把右边的值赋值给等号左边的变量名中。
注意点:变量名自定义,要满足标识符的命名规则。
2)定义变量的规则
变量命名规范 - 标识符命名规则是Python中定义各种名字的时候的统一规范,具体规范如下:
-
由数字、字母、下划线组成
-
不能以数字开头
-
不能使用Python内置关键字
-
严格区分大小写
下面是列举的常见关键字,这些关键字不用去背,在学习Python的过程中自然就会记得的,不用就不会犯错,也可以通过keyword模块查看
import keyword
print(keyword.kwlist)
# ['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']

3)变量命名规范
-
见名知义
-
大驼峰:即每个单词首字母都大写,例如:UserName
-
小驼峰:第二个(含)以后的单词首字母大写,力例如:userName
-
下划线:例如:user_name
4)变量类型转换
Python是弱类型语言,弱类型语言有下面两个特点:
- 变量不用先声明就可以直接赋值,对一个没声明的变量赋值就相当于定义了一个新变量。
- 变量的数据类型可以改变,如,一个变量可以先被赋值为字符串,后再被赋值为整数。
在Python中,为了应对不同的业务需求,把数据分为下面几种类型:
Number(数字)int:有符号整型long:长整型,也可以代表八进制和十六进制(Python3中没有)float:浮点型complex:复数
String(字符串)Boolean布尔类型True真False假
List(列表)Tuple(元组)Set(集合)Dictionary(字典)
Python3 的六个标准数据类型中:
【温馨提示】不管对于多大或者多小的整数,Python 3.x 只用 int 一种类型存储,表示为长整型,并且整数的取值范围是无限的。
示例如下:
# 类型转换
age = 18
#打印age看一下值,这里通过type()函数来输出age的类型
print(age, type(age))
# #强制类型转换把age转换为浮点型,再输出一下age的值和age的类型
age = float(age)
print(age, type(age))

常用的类型转换函数:
| 函数 | 功能 |
|---|---|
| int(x) | 把x转换为整数 |
| float(x) | 把x转换为浮点数 |
| str(x) | 把x转换为字符串类型 |
| list(x) | 把x转换为列表类型 |
| chr(x) | 把x转换为一个字符 |
| ord(x) | 把字符x转换为相应整数值 |
| hex(x) | 把整数x转换为十六进制字符串 |
| oct(x) | 把整数x转换为八进制字符串 |
三、注释
Python 中的注释有单行注释和多行注释,注释不会影响程序的执行,只会使代码更易于阅读和理解。
1)单行注释
Python 中单行注释以 # 开头,例如:
print("Hello, World!")
2)多行注释
多行注释用三个单引号 ‘’’ 或者三个双引号 “”" 将注释括起来,例如:
1、单引号(‘’')注释
#!/usr/bin/python3
'''
这是多行注释,用三个单引号
这是多行注释,用三个单引号
这是多行注释,用三个单引号
'''
print("Hello, World!")
2、双引号(“”")注释
#!/usr/bin/python3
"""
这是多行注释,用三个双引号
这是多行注释,用三个双引号
这是多行注释,用三个双引号
"""
print("Hello, World!")
四、运算符
Python的运算符,运算符是一些特殊的符号,通过运算符将不同的数据连接构成表达式。先通过一张图来看一下常用操作符。
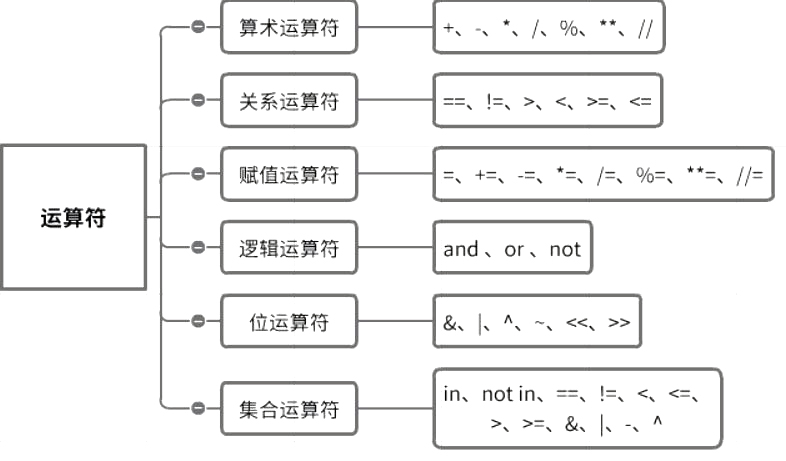
1)算术运算符
| 运算符 | 功能 | 输入 | 输出 |
|---|---|---|---|
| + | 加 | 66+22 | 88 |
| - | 减 | 66-22 | 44 |
| * | 乘 | 11*6 | 66 |
| / | 除 | 60/10 | 6 |
| % | 取余 | 10%9 | 1 |
| // | 整除 | 20//9 | 2 |
| ** | 幂 | 3**3 | 27,即三的三次方 |
2)关系运算符
定义:a=1,b=2
| 运算符 | 功能 | 输入 | 输出 |
|---|---|---|---|
| > | 大于 | a>b | False |
| < | 小于 | a<b | False |
| != | 不等于 | a!=b | True |
| == | 判段是否相等 | a==b | False |
| >= | 大于等于 | a>=b | False |
| <= | 小于等于 | a<=b | True |
3)赋值运算符
赋值运算符从字面上可以理解为赋给变量一个值,通常我们用=将右边的指赋给左边。下面来通过下表来看一下常用的赋值运算符:
| 运算符 | 功能 | 输入 |
|---|---|---|
| = | 赋值 | a=2 |
| -= | 减赋值 | a-=2(a=a-2) |
| += | 加赋值 | a+=2(a=a+2) |
| *= | 乘赋值 | a*=2(a=a*2) |
| /= | 除赋值 | a/=2(a=a/2) |
| %= | 取余赋值 | a%=2(a=a%2) |
| **= | 幂赋值 | a**=2(a=a**2) |
| //= | 整除赋值 | a//=2(a=a//2) |
4) 逻辑运算符
定义:a=5,b=1
| 运算符 | 功能 | 输入 | 输出 |
|---|---|---|---|
| and | 与 | a>0 and a>b | True |
| or | 或 | a>100 or a>b | True |
| not | 非 | not(a>b and a>0) | False |
5)位运算符
位操作符属于操作符中比较难的内容,位操作符以二进制为单位进行运算,操作的对象以及结果都是整数型。位操作符有如下几个:&(按位与)、|(按位或)、^(按位异或)、~(按位取反)、>>(右位移)和<<(左位移)。
具体说明看下表:
| 运算符 | 名称 | 例子 | 功能 |
|---|---|---|---|
| & | 按位与 | A&B | A和B进行位与运算 |
| | | 按位或 | A|B | A和B进行位或运算 |
| ~ | 按位取反 | ~A | A进行取反运算 |
| ^ | 按位异或 | A^B | A和B进行位异或运算 |
| >> | 右位移 | A>>c | A右移c位 |
| << | 左位移 | A<<c | A左移c位 |
1、位与运算(A&B)
位与运算中,A和B按位进行与运算,当每位对应全是1的时候对应结果位1,反之为0

【结论】可以看出,当10111001&00100011得到00100011。当对应位同时为1才为1。
2、位或运算(A|B)

【结论】可以看出,当10110010 | 01011110得到11111110,对应位置存在一个1的时候即为1。
3、异或位运算(A^B)

【结论】可以看出,10110010^01011110得到11101100,对应位置相反的时候,即0对应1,1对应0的时候得到1。
4、按位取反运算(~A)

【结论】按位取反的过程中需要运用补码运算,即0补为1,1补为0。
5、左右位移
右移时,(第一行为移动前,第二行为移动后)

【结论】右边最低位为溢出位被丢弃,在填充左侧最高位时,如果最高位是0,则填0,如果最高位是1,则填1。右移相当于除上2的n次方。
左移时, (第一行为移动前,第二行为移动后)

【结论】左边最高位为溢出位被丢弃,在最右边空位补0,左移相当于乘上2的n次方。
运算符优先级如下:

五、数据类型
Python3 中有七个标准的数据类型:
- Number(数字)
- Boolean(布尔类型)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
- Set(集合)
数字和布尔类型就没什么可说的了,这里主要讲一下另外五种类型:字符串、列表、元组、字典、集合
1)String(字符串)
1、创建字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号( ’ 或 " )来创建字符串。创建字符串很简单,只要为变量分配一个值即可。例如:
var1 = 'Hello World!'
2、字符串连接
字符串自带连接方法,在连接的时候我们可以使用+直接连接或追加一个字符串到另一个字符串的末尾。
示例如下:
>>> my_str = 'www.test.com'
>>> my_str
'www.test.com'
>>> his_str = '人生苦短,我用Python'
>>> my_str + his_str
'www.test.com人生苦短,我用Python'
3、字符串切片
字符串切片是非常常用的功能,示例如下:
>>> my_str = 'www.test.com'
>>> my_str
'www.test.com'
>>> my_str[0:2]#通过切片访问0-1
'ww'
>>> my_str[3:6]#3-5
'.te'
>>> my_str[7:10]#7-9
't.c'
>>> my_str[::2]#步长为2的访问整个字符串
'wwts.o'
>>> my_str[::-1]#逆置字符串
'moc.tset.www'
4、字符串常用方法
【1】count()方法
通常使用count()方法来统计字符串中的某个元素在字符串中出现的次数,如果不存在返回0,如果存在则返回存在的次数,语法格式如下:
my_str.count(x)
my_str 为我们要检索的字符串名,x为我们要统计的字符。
示例如下:
>>> my_str = 'www.test.com'
>>> my_str
'www.test.com'
>>> my_str.count('w')
3
>>> my_str.count('.')
2
>>> my_str.count('t')
2
>>> my_str.count('*')
0
返回的数字即该字符在字符串中出现的次数,因为*不存在,所以返回值为0。
【2】find()方法
find方法来检索字符串中是否包含指定元素,如果包含该元素则返回该元素第一次出现的索引位置,如果不存在该字符则返回-1,它的语法结构为:
my_str.find(x)
my_str 为要检索的字符串名,x为我们要寻找的元素。
示例如下:
>>> my_str = 'www.test.com'
>>> my_str
'www.test.com'
>>> my_str.find('w')#寻找字符w
0
>>> my_str.find('t')#寻找字符p
4
>>> my_str.find('m')#寻找字符m
11
>>> my_str.find('*')#寻找字符*,因为*不存在因而返回-1
-1
【3】index()方法
index()方法和find()方法类似,index()方法在检索到指定字符的时候也会返回该字符第一次出现的索引位置,但是如果检索不到就会抛出异常,它的语法格式为:
my_str.index(x)
my_str为要检索的字符串名,x为要寻找的元素。
示例如下:
>>> my_str = 'www.test.com'
>>> my_str.index('w')
0
>>> my_str.index('o')
10
>>> my_str.index('*')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
上面三种方法为他们的省略格式,在标准文档中,他们的格式分别为:
my_str.count(x[,start[,end]])
my_str.find(x[,start[,end]])
my_str.index(x[,start[,end]])
示例如下:
>>> my_str = 'www.test.com'
>>> my_str.index('o',6,13)#在6-12之间寻找o
10
>>> my_str.count('w',0,5)#统计w在0-4之间存在的次数
3
>>> my_str.find('t',3,9)#在3-8之间寻找t
4
【4】lower()方法和upper()方法
这两种方法和上一节的测试方法类似,前者lower()是返回一个副本,副本中把字符串中所有字符转换为了小写字符,而后者upper()是返回一个副本,副本中把字符串中所有字符转换为了大写字符。
示例如下:
>>> my_str = 'ABCabc'#包含大小写字母的字符串
>>> my_str.upper()#将字符串全部大写
'ABCABC'
>>> my_str.lower()#将字符串全部小写
'abcabc'
>>> my_str#再看一下原始字符串有没有改变
'ABCabc'
【5】lstrip()方法、rstrip ()方法和strip()方法
这三种方法的原理类型,他们都是用于处理字符串中的空白字符。
-
lstrip()方法会返回一个副本,副本中的字符串删除所有前导的空白字符。 -
rstrip()方法会返回一个副本,副本中的字符串删除所有后导的空白字符。 -
strip()方法会返回一个副本,副本中的字符串删除所有前导和后导的空白字符。
示例如下:
>>> my_str = ' \n\t www.test.com \t\n '
>>> my_str.rstrip()#返回删除后导空白字符的副本
' \n\t
>>> my_str.lstrip()#返回删除前导空白字符的副本
'www.test.com \t\n '
>>> my_str.strip()#返回删除前导后导空白字符的副本
'www.test.com'
【6】replace() 方法
replace()方法返回一个副本,副本中将我们需要替代的字符替换掉,它的语法格式为:
my_str.replace(old,new)
my_str为字符串名,old为要替换掉的字符,new为替换上的字符。
示例如下:
>>> my_str = 'www.test.com'
>>> my_str.replace('test','hello')
'www.hello.com'
5、格式化字符串
格式化字符串就是在先创建一个空间,然后再这个空间留几个位置,然后根据需求填入相应的内容,这里留出的位置相当于占位符,格式化字符串有两种方式。一种是使用%操作符,一种是使用format()方法。
【1】 %操作符
%操作符在我们格式化字符串的时候十分方便,它的语法结构如下:
'%[+][-][0][.m]格式化字符'%iteration
-
iteration为我们要填入的内容,第一个%后面为我们要选择的格式。 -
[+]为右对齐,数字大小代表对齐宽度。
-
[-]为左对齐,数字大小代表对齐宽度。
-
[.m]中的m为可选精度,表示保留小数点后几位小数。
-
格式化字符为我们需要选定的格式,它的常用类型为字符串
%s、十进制整数%d、单字符%c、浮点数%f、十六进制数%x、八进制数%o、字符%%。
示例如下:
>>> my_str =66666.66666
>>> print('保留2位小数格式为:%.2f'%my_str)保留2位小数格式为:66666.67
>>> for i in range(5):
... print('%-5d'%i,end=' ')#左对齐方式
... print('%5d'%i)#右对齐方式
...
0 0
1 1
2 2
3 3
4 4
【2】format()方法
format()方法提供了更多的方法去格式化字符串,它的基本语法是通过‘{}’和‘:’来代替‘%’。它的语法格式为:
str.format()
示例如下:
namea = '小明'
nameb = '小华'
print('{}是{}的好朋友'.format(namea,nameb))
2)List(列表)
列表是最常用的 Python 数据类型,它可以作为一个方括号内的逗号分隔值出现。在其它语言里叫做数组。
1、创建列表
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['Google', 'test', 1997, 2000]
list2 = [1, 2, 3, 4, 5 ]
list3 = ["a", "b", "c", "d"]
list4 = ['red', 'green', 'blue', 'yellow', 'white', 'black']
2、访问列表中的值
与字符串的索引一样,列表索引从 0 开始,第二个索引是 1,依此类推。
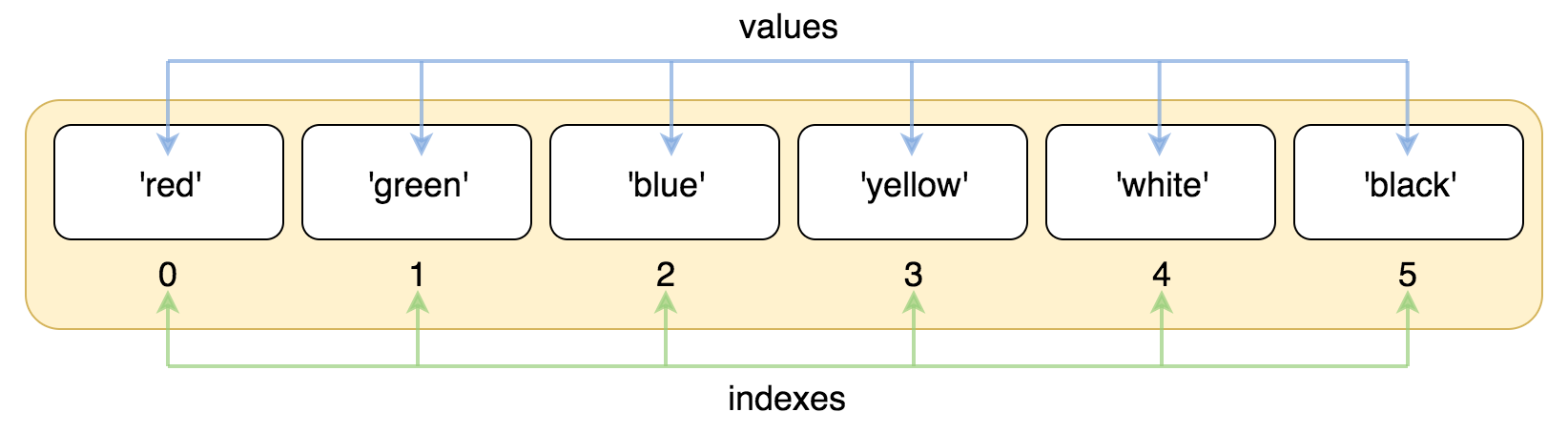
#!/usr/bin/python3
list = ['red', 'green', 'blue', 'yellow', 'white', 'black']
print( list[0] )
print( list[1] )
print( list[2] )
索引也可以从尾部开始,最后一个元素的索引为 -1,往前一位为 -2,以此类推。
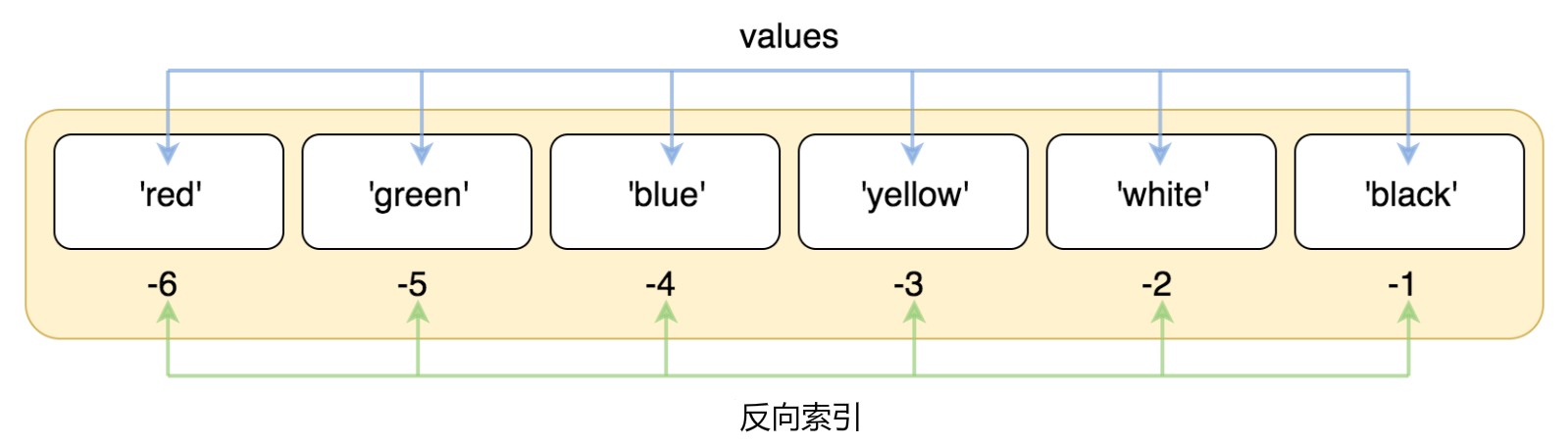
#!/usr/bin/python3
list = ['red', 'green', 'blue', 'yellow', 'white', 'black']
print( list[-1] )
print( list[-2] )
print( list[-3] )
3、更新列表
#!/usr/bin/python3
list = ['Google', 'test', 1997, 2000]
print ("第三个元素为 : ", list[2])
list[2] = 2001
print ("更新后的第三个元素为 : ", list[2])
list1 = ['Google', 'test', 'Taobao']
list1.append('Baidu')
print ("更新后的列表 : ", list1)
4、删除列表元素
#!/usr/bin/python3
list = ['Google', 'test', 1997, 2000]
print ("原始列表 : ", list)
del list[2]
print ("删除第三个元素 : ", list)
5、列表截取与拼接
列表截取示例如下:
>>>L=['Google', 'test', 'Taobao']
>>> L[2]
'Taobao'
>>> L[-2]
'Runoob'
>>> L[1:]
['test', 'Taobao']
>>>
列表拼接示例如下:
>>>squares = [1, 4, 9, 16, 25]
>>> squares += [36, 49, 64, 81, 100]
>>> squares
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
>>>
6、常用方法
len(list)——列表元素个数list(seq)——将元组转换为列表max(list)——返回列表元素最大值min(list)——返回列表元素最小值list.append(obj)——在列表末尾添加新的对象list.insert(index, obj)——在列表头部添加新的对象list.pop([index=-1])——移除列表中的一个元素(默认最后一个元素),并且返回该元素的值list.remove(obj)——移除列表中某个值的第一个匹配项list.reverse()——反向列表中元素list.sort( key=None, reverse=False)——对原列表进行排序- list.clear()——清空列表
3)Tuple(元组)
- Python 的元组与列表类似,不同之处在于元组的元素不能修改。
- 元组使用小括号
( ),列表使用方括号 [ ]。 - 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
1、创建元组
示例如下:
>>> tup1 = ('Google', 'test', 1997, 2000)
>>> tup2 = (1, 2, 3, 4, 5 )
>>> tup3 = "a", "b", "c", "d" # 不需要括号也可以
>>> type(tup3)
<class 'tuple'>
2、访问元组
元组可以使用下标索引来访问元组中的值,如下实例:
>>> tup1 = ('Google', 'test', 1997, 2000)
>>> tup2 = (1, 2, 3, 4, 5, 6, 7 )
>>> print ("tup1[0]: ", tup1[0])
tup1[0]: Google
>>> print ("tup2[1:5]: ", tup2[1:5])
tup2[1:5]: (2, 3, 4, 5)
>>>
3、修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合生成一个新的元组,原有的元组是不变的,如下实例:
>>> tup1 = (12, 34.56)
>>> tup2 = ('abc', 'xyz')
>>> tup3 = tup1 + tup2
>>> print (tup3)
(12, 34.56, 'abc', 'xyz')
>>>
4、删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
>>> tup = ('Google', 'Runoob', 1997, 2000)
>>> print (tup)
('Google', 'Runoob', 1997, 2000)
>>> del tup
>>> print ("删除后的元组 tup : ")
删除后的元组 tup :
>>> print (tup)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'tup' is not defined
>>>
5、元组截取
示例如下:
>>> tup = ('Google', 'test', 'Taobao', 'Wiki', 'Weibo','Weixin')
>>> tup[1]
'test'
>>> tup[-2]
'Weibo'
>>> tup[1:]
('test', 'Taobao', 'Wiki', 'Weibo', 'Weixin')
>>> tup[1:4]
('test', 'Taobao', 'Wiki')
>>>
6、常用函数
len(tuple)——计算元组元素个数。max(tuple)——返回元组中元素最大值。min(tuple)——返回元组中元素最小值。tuple(iterable)——将可迭代系列转换为元组。
4)Dictionary(字典)
字典和列表和元组不同,字典中存储的是一组数据,且可存储任意类型的数据。
字典的每个键值 key=>value 对用冒号 : 分割,每个对之间用逗号(,)分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2, key3 : value3 }
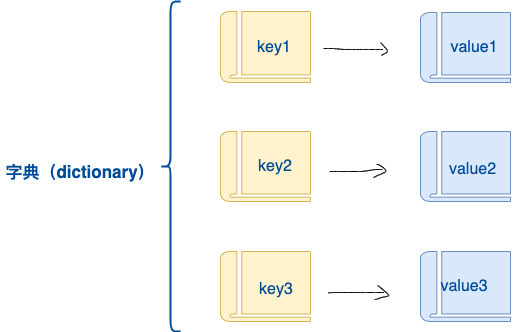
1、创建字典
tinydict1 = { 'abc': 456 }
tinydict2 = { 'abc': 123, 98.6: 37 }
2、访问字典里的值
>>> tinydict = {'Name': 'test', 'Age': 7, 'Class': 'First'}
>>> print ("tinydict['Name']: ", tinydict['Name'])
tinydict['Name']: test
>>> print ("tinydict['Age']: ", tinydict['Age'])
tinydict['Age']: 7
3、修改字典
>>> tinydict = {'Name': 'test', 'Age': 7, 'Class': 'First'}
>>> tinydict['Age'] = 8 # 更新 Age
>>> tinydict['School'] = "python教程" # 添加信息
>>> print ("tinydict['Age']: ", tinydict['Age'])
tinydict['Age']: 8
>>> print ("tinydict['School']: ", tinydict['School'])
tinydict['School']: python教程
>>>
4、删除字典元素
>>> tinydict = {'Name': 'test', 'Age': 7, 'Class': 'First'}
>>> del tinydict['Name'] # 删除键 'Name'
>>> tinydict.clear() # 清空字典
>>> del tinydict # 删除字典
>>> print ("tinydict['Age']: ", tinydict['Age'])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'tinydict' is not defined
>>> print ("tinydict['School']: ", tinydict['School'])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'tinydict' is not defined
>>>
但这会引发一个异常,因为用执行 del 操作后字典不再存在。
5、常用方法
len(dict)——计算字典元素个数,即键的总数。str(dict)——输出字典,可以打印的字符串表示。type(variable)——返回输入的变量类型,如果变量是字典就返回字典类型。dict.clear()——删除字典内所有元素。dict.get(key, default=None)——返回指定键的值,如果键不在字典中返回 default 设置的默认值key in dict——如果键在字典dict里返回true,否则返回false。dict.items()——以列表返回一个视图对象。dict.keys()——返回一个视图对象。dict.values()——返回一个视图对象。pop(key[,default])——删除字典 key(键)所对应的值,返回被删除的值。
5)Set(集合)
集合(set)是一个无序的不重复元素序列。可以使用大括号 { } 或者 set() 函数创建集合。
parame = {value01,value02,...}
或者
set(value)
【注意】创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
1、创建集合
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
2、访问集合元素
print(basket)
3、添加集合元素
s.add( x )
将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
示例如下:
>>> thisset = set(("Google", "test", "Taobao"))
>>> thisset.add("Facebook")
>>> print(thisset)
{'Taobao', 'Google', 'test', 'Facebook'}
>>>
还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等,语法格式如下:
s.update( x )
示例如下:
>>> thisset = set(("Google", "test", "Taobao"))
>>> thisset.update({1,3})
>>> print(thisset)
{1, 'Google', 3, 'Taobao', 'test'}
>>> thisset.update([1,4],[5,6])
>>> print(thisset)
{1, 'Google', 3, 4, 5, 6, 'Taobao', 'test'}
>>>
【温馨提示】添加的元素位置是不确定的,是随机的。
4、移除元素
语法格式如下:
s.remove( x )
示例如下:
>>> thisset = set(("Google", "test", "Taobao"))
>>> thisset.remove("Taobao")
>>> print(thisset)
{'Google', 'test'}
>>> thisset.remove("Facebook")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Facebook'
>>>
从上面可知,删除不存在的元素会报错,如果元素不存在,不会发生错误。格式如下所示:
s.discard( x )
示例如下:
>>> thisset = set(("Google", "test", "Taobao"))
>>> thisset.discard("Google")
>>> print(thisset)
{'Taobao', 'test'}
>>> thisset.discard("Facebook")
>>> print(thisset)
{'Taobao', 'test'}
>>>
5、常用函数
len(s)——计算集合元素个数。s.add(x)——给集合添加元素。s.update(x)——给集合添加元素。s.remove(x)——移除指定元素。s.union(s2)——返回两个集合的并集。s.clear()——清空集合。x in s——判断元素是否在集合中存在。
六、流程控制
流程控制三种结构,它们分别是顺序结构、选择结构、循环结构。
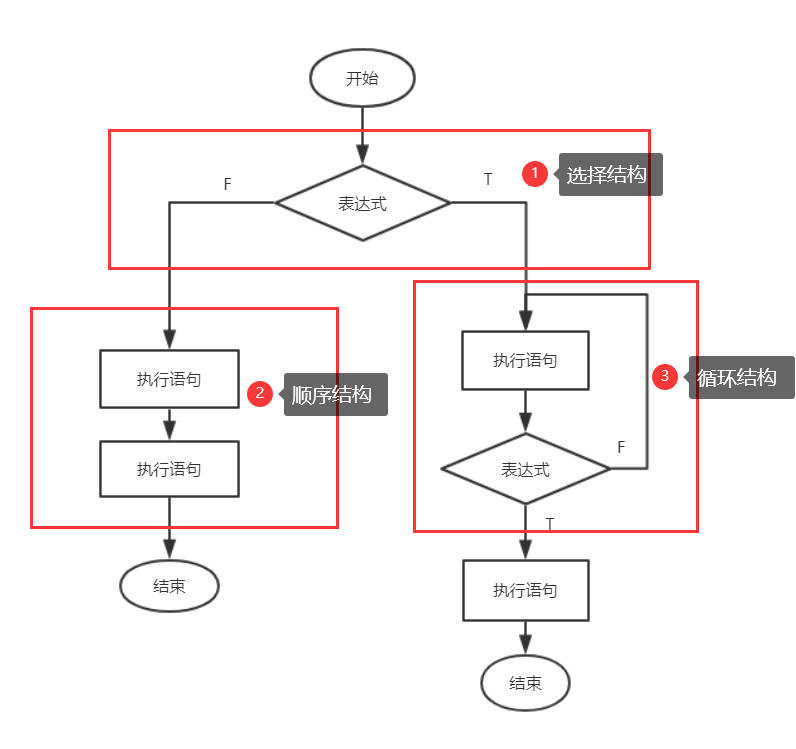
1)选择结构
1、if语句
Python 条件语句是通过一条或多条语句的执行结果(True 或者 False)来决定执行的代码块。
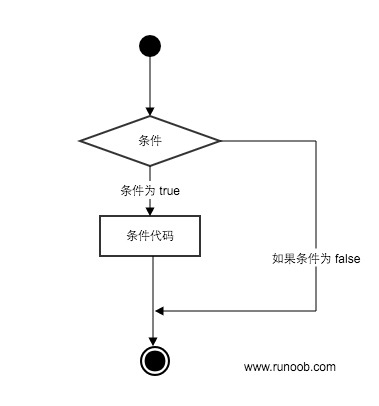
语法格式如下:
if 表达式1:
语句
if 表达式2:
语句
elif 表达式3:
语句
else:
语句
elif 表达式4:
语句
else:
语句
示例如下:
# !/usr/bin/python3
num=int(input("输入一个数字:"))
if num%2==0:
if num%3==0:
print ("你输入的数字可以整除 2 和 3")
else:
print ("你输入的数字可以整除 2,但不能整除 3")
else:
if num%3==0:
print ("你输入的数字可以整除 3,但不能整除 2")
else:
print ("你输入的数字不能整除 2 和 3")
2、match…case语句
Python 3.10 增加了 match…case 的条件判断,不需要再使用一连串的 if-else 来判断了。就跟其它语言switch…case一样。
语法格式如下:
match subject:
case <pattern_1>:
<action_1>
case <pattern_2>:
<action_2>
case <pattern_3>:
<action_3>
case _:
<action_wildcard>
case _:类似于 C 和 Java 中的 default:,当其他 case 都无法匹配时,匹配这条,保证永远会匹配成功。
示例如下:
mystatus=400
print(http_error(400))
def http_error(status):
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case _:
return "Something's wrong with the internet"
3)循环结构
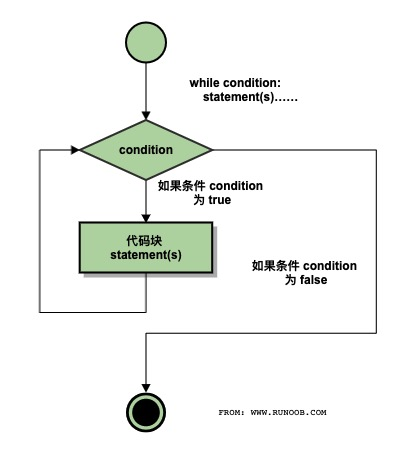
Python 中的循环语句有 while 和 for 语句。
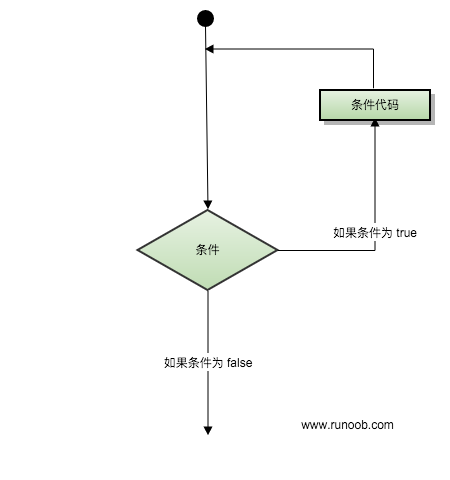
1、while语句
Python 中 while 语句的一般形式:
while 判断条件(condition):
执行语句(statements)……
执行流程图如下:
示例如下:
#!/usr/bin/env python3
n = 100
sum = 0
counter = 1
while counter <= n:
sum = sum + counter
counter += 1
print("1 到 %d 之和为: %d" % (n,sum))
执行结果如下:
1 到 100 之和为: 5050
while 循环使用 else 语句
语法格式如下:
while <expr>:
<statement(s)>
else:
<additional_statement(s)>
示例如下:
#!/usr/bin/python3
count = 0
while count < 5:
print (count, " 小于 5")
count = count + 1
else:
print (count, " 大于或等于 5")
执行以上脚本,输出结果如下:
0 小于 5
1 小于 5
2 小于 5
3 小于 5
4 小于 5
5 大于或等于 5
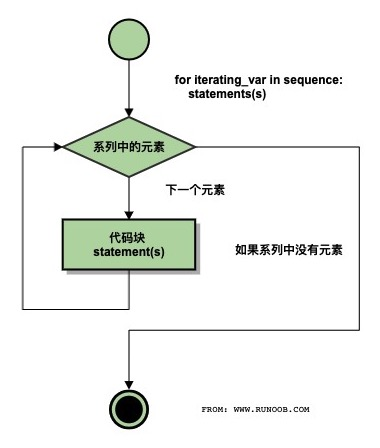
2、for语句
Python for 循环可以遍历任何可迭代对象,如一个列表或者一个字符串。
for循环的一般格式如下:
for <variable> in <sequence>:
<statements>
else:
<statements>
流程图:
示例如下:
#!/usr/bin/python3
sites = ["Baidu", "Google","Runoob","Taobao"]
for site in sites:
print(site)
以上代码执行输出结果为:
Baidu
Google
Runoob
Taobao
for…else 语法
在 Python 中,for…else 语句用于在循环结束后执行一段代码。
语法格式如下:
for item in iterable:
# 循环主体
else:
# 循环结束后执行的代码
示例如下:
for x in range(6):
print(x)
else:
print("Finally finished!")
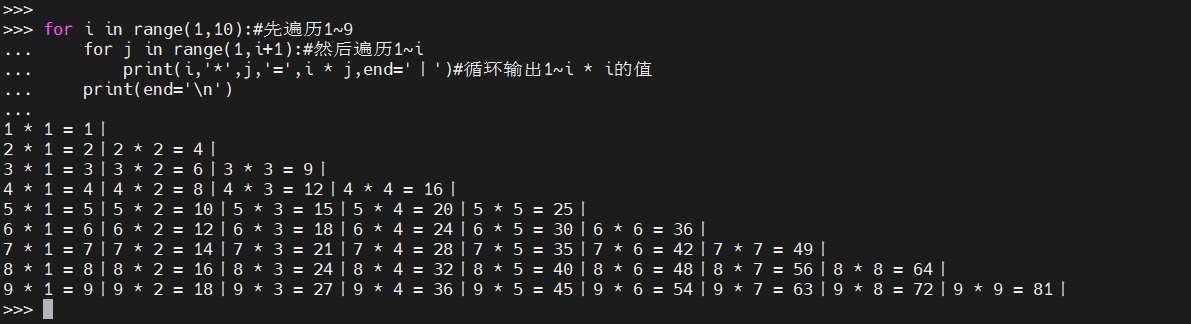
嵌套for循环示例如下(九九乘法表):
for i in range(1,10):#先遍历1~9
for j in range(1,i+1):#然后遍历1~i
print(i,'*',j,'=',i * j,end='丨')#循环输出1~i * i的值
print(end='\n')
输出信息:
1 * 1 = 1丨
2 * 1 = 2丨2 * 2 = 4丨
3 * 1 = 3丨3 * 2 = 6丨3 * 3 = 9丨
4 * 1 = 4丨4 * 2 = 8丨4 * 3 = 12丨4 * 4 = 16丨
5 * 1 = 5丨5 * 2 = 10丨5 * 3 = 15丨5 * 4 = 20丨5 * 5 = 25丨
6 * 1 = 6丨6 * 2 = 12丨6 * 3 = 18丨6 * 4 = 24丨6 * 5 = 30丨6 * 6 = 36丨
7 * 1 = 7丨7 * 2 = 14丨7 * 3 = 21丨7 * 4 = 28丨7 * 5 = 35丨7 * 6 = 42丨7 * 7 = 49丨
8 * 1 = 8丨8 * 2 = 16丨8 * 3 = 24丨8 * 4 = 32丨8 * 5 = 40丨8 * 6 = 48丨8 * 7 = 56丨8 * 8 = 64丨
9 * 1 = 9丨9 * 2 = 18丨9 * 3 = 27丨9 * 4 = 36丨9 * 5 = 45丨9 * 6 = 54丨9 * 7 = 63丨9 * 8 = 72丨9 * 9 = 81丨
4)break 和 continue 语句
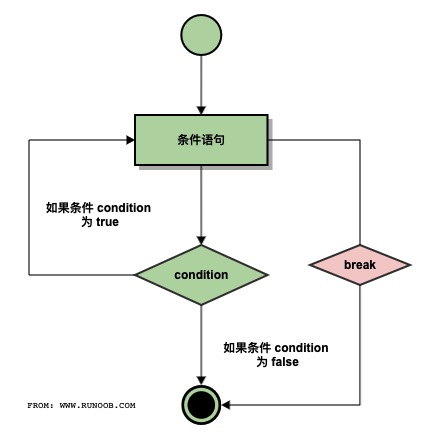
1、break 语句
break语句可以跳出 for 和 while 的循环体。如果你从 for 或 while 循环中终止,任何对应的循环 else 块将不执行。
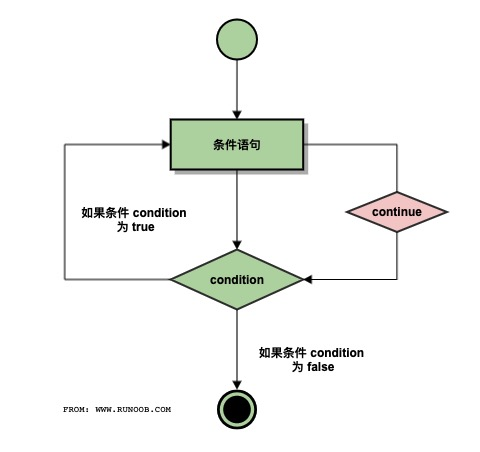
2、continue 语句
continue语句被用来告诉 Python 跳过当前循环,然后继续进行下一轮循环。
示例如下:
n = 5
while n > 0:
n -= 1
if n == 2:
continue
print(n)
print('循环结束。')
这些基础知识非常简单,也是非常重要的,其实网上有很多资料介绍,这里只是整理了一些常用的,由于篇幅比较长,剩余的部分放在下篇文章介绍,有疑问的小伙伴欢迎给我留言,也可关注我的公众号【大数据与云原生技术分享】进行深入技术交流~