Rust机器学习之petgraph
图作为一种重要的数据结构和表示工具在科学和技术中无处不在。因此,许多软件项目会以各种形式用到图。尤其在知识图谱和因果AI领域,图是最基础的表达和研究工具。Python有著名的NetworksX库,便于用户对复杂网络进行创建、操作和学习。Rust有对应的petgraph库——一个用 Rust 开发的通用图形库。本文将用简短易懂的代码向大家介绍petgraph的主要功能特性。
本文是“Rust替代Python进行机器学习”系列文章的第六篇,其他教程请参考下面表格目录:
| Python库 | Rust替代方案 | 教程 |
|---|---|---|
numpy | ndarray | Rust机器学习之ndarray |
pandas | Polars | Rust机器学习之Polars |
scikit-learn | Linfa | Rust机器学习之Linfa |
matplotlib | plotters | Rust机器学习之plotters |
pytorch | tch-rs | Rust机器学习之tch-rs |
networks | petgraph | Rust机器学习之petgraph |
数据和算法工程师偏爱Jupyter,为了跟Python保持一致的工作环境,文章中的示例都运行在Jupyter上。因此需要各位搭建Rust交互式编程环境(让Rust作为Jupyter的内核运行在Jupyter上),相关教程请参考 Rust交互式编程环境搭建

文章目录
- 关于petgraph
- 安装petgraph
- 基本用法
- 图的构造
- 变量
- 列表
- 表
- 树
- 环形缓冲器
- 字典
- 图的实现
- `Graph`
- `StableGraph`
- `GraphMap`
- `Csr`
- 图的遍历
- 广度优先
- 深度优先
- 后序深度优先
- 图算法
- 寻路算法
- 其他算法
- 结论
关于petgraph
petgraph是Rust中最受欢迎的图算法库,它有着不输NetworkX的功能,但性能远超纯Python实现的NetworkX,因此很多项目都依赖petgraph库。
petgraph包含三个主要部分:
- 数据结构:包含4个不同的图实现,他们各有侧重,有的专注功能,有的专注性能,开发者可以根据实际需要权衡选择;
- 遍历:支持深度优先和广度优先遍历算法;
- 图算法:包括常见的图算法,如寻路算法。
安装petgraph
安装petgraph很简单,如果是标准rust项目,只需要在项目目录下运行:
cargo add petgraph
或在Cargo.toml文件中加入
petgraph = "0.6.2"
在机器学习中,我们更喜欢使用Jupyter。如果你已经搭建好Rust交互式编程环境(可以参考 《Rust交互式编程环境搭建》),可以直接通过下面代码引入petgraph :
:dep petgraph = "0.6.2"
:dep petgraph-evcxr = "*"
extern crate petgraph;
use petgraph_evcxr::draw_graph;
这里我们需要用到petgraph-evcxr的draw_graph方法让petgraph在Jupyter环境中绘制图。
基本用法
我们先来手动创建一个图。
在petgraph中手动建图很容易,首先初始化Graph结构,然后向其添加节点和边,例如:
use petgraph::graph::Graph;
let mut g : Graph<&str, &str> = Graph::new();
let a = g.add_node("Node A");
let b = g.add_node("Node B");
g.add_edge(a, b, "edge A->B");
draw_graph(&g);
输出结果如下图:

⚠注意:
petgraph_evcxr::draw_graph不支持显示中文字符,因此图中所有显示文本都用英文。
petgraph有多种内存实现(详见图的实现),上面的例子用的是Graph结构。Graph又分有向图和无向图。我们用Graph::new()创建有向图,用Graph::new_undirected()创建无向图。
⚠注意:有向图和无向图的内存结构中是一样,都是有向图,区别在于某些算法行为会不同。
你可能留意到,Graph是支持泛型的,上面例子中我们给定Graph的两个参数为&str和&str类型。第一个参数表示节点的权重,第二个参数表示边的权重。这里权重在不同场景下含义不同,上面例子可以简单地将权重理解为标签,在寻路算法中权重表示路径的cost(详见图算法)。权重的数据类型完全可以灵活地自定义。
图的构造
图是一种通用数据结构,绝大多数常见数据结构都可以表示为图的形式。下面列举一些常见数据结构如何表示成图:
变量
理论上,变量可以表示为单例图(只有一个节点的图)。
let mut singleton : Graph<&str, &str, petgraph::Undirected> = Graph::new_undirected();
let singleton_node = singleton.add_node("Single Node");
draw_graph(&singleton);

列表
let mut list : Graph<&str, &str, petgraph::Undirected> = Graph::new_undirected();
let item1 = list.add_node("a");
let item2 = list.add_node("b");
let item3 = list.add_node("c");
list.add_edge(item1, item2, "");
list.add_edge(item2, item3, "");
draw_graph(&list);

表
let mut table : Graph<&str, &str, petgraph::Undirected> = Graph::new_undirected();
let cellA1 = table.add_node("A1");
let cellA2 = table.add_node("A2");
let cellA3 = table.add_node("A3");
let cellB1 = table.add_node("B1");
let cellB2 = table.add_node("B2");
let cellB3 = table.add_node("B3");
let cellC1 = table.add_node("C1");
let cellC2 = table.add_node("C2");
let cellC3 = table.add_node("C3");
// 列
table.add_edge(cellA1, cellA2, "");
table.add_edge(cellA2, cellA3, "");
table.add_edge(cellB1, cellB2, "");
table.add_edge(cellB2, cellB3, "");
table.add_edge(cellC1, cellC2, "");
table.add_edge(cellC2, cellC3, "");
// 行
table.add_edge(cellA1, cellB1, "");
table.add_edge(cellB1, cellC1, "");
table.add_edge(cellA2, cellB2, "");
table.add_edge(cellB2, cellC2, "");
table.add_edge(cellA3, cellB3, "");
table.add_edge(cellB3, cellC3, "");
draw_graph(&table);

树
let mut tree : Graph<&str, &str, petgraph::Directed> = Graph::new();
let tree_item1 = tree.add_node("a");
let tree_item2 = tree.add_node("b");
let tree_item3 = tree.add_node("c");
let tree_item4 = tree.add_node("d");
let tree_item5 = tree.add_node("e");
tree.add_edge(tree_item1, tree_item2, "");
tree.add_edge(tree_item1, tree_item3, "");
tree.add_edge(tree_item2, tree_item4, "");
tree.add_edge(tree_item2, tree_item5, "");
draw_graph(&tree);

环形缓冲器
let mut ring : Graph<&str, &str> = Graph::new();
let ring_item1 = ring.add_node("a");
let ring_item2 = ring.add_node("b");
let ring_item3 = ring.add_node("c");
let ring_item4 = ring.add_node("d");
ring.add_edge(ring_item1, ring_item2, "");
ring.add_edge(ring_item2, ring_item3, "");
ring.add_edge(ring_item3, ring_item4, "");
ring.add_edge(ring_item4, ring_item1, "");
draw_graph(&ring);

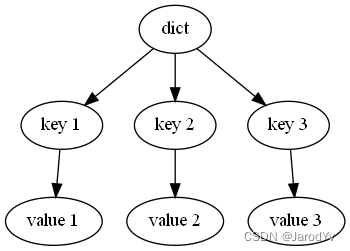
字典
let mut dict : Graph<&str, &str> = Graph::new();
let core = dict.add_node("dict");
let key1 = dict.add_node("key 1");
let key2 = dict.add_node("key 2");
let key3 = dict.add_node("key 3");
let value1 = dict.add_node("value 1");
let value2 = dict.add_node("value 2");
let value3 = dict.add_node("value 3");
dict.add_edge(core, key1, "");
dict.add_edge(core, key2, "");
dict.add_edge(core, key3, "");
dict.add_edge(key1, value1, "");
dict.add_edge(key2, value2, "");
dict.add_edge(key3, value3, "");
draw_graph(&dict);
图的实现
petgraph中的图有4种实现方式,它们的主要区别在于图在内存中的数据结构不同。根据场景不同,不同的实现可能带来不同的时间和空间性能。我们有必要了解这4种实现的区别,从而在使用时根据场景选择恰当的实现。
Graph
Graph背后的内存模型是邻接表,其对节点和边的类型无任何限制。节点和边分别通过 NodeIndex 和 EdgeIndex 的值访问。这些值可以访问背后的数值索引,这些索引在删除操作下不稳定。另外,Graph支持最多petgraph图算法。
StableGraph
与Graph类似,StableGraph背后的内存模型也是邻接表;但与Graph不同的是,从 StableGraph 中删除节点或边不会使现有索引失效。
GraphMap
GraphMap背后的内存模型是Map。其用节点作为Key,因此节点必须实现Copy, Eq, Ord, 和Hash。与其他三种实现不同,GraphMap 可以直接操作节点和边标签,无需中间操作。
Csr
Csr是Compressed Sparse Row(压缩稀疏行或稀疏矩阵)的简称,它是表示稀疏矩阵数据(大部分图都是稀疏数据)的有效方法,通过快速边查询可以降低内存消耗。虽然Csr对节点或边类型没有限制,但是,Csr 的 API 是所有图中限制最多的。
图的遍历
petgraph支持三种遍历形式:
- 广度优先
- 深度优先
- 后序深度优先
每种形式都实现为迭代器,且都考虑了边的方向性。
广度优先
广度优先需要用到petgraph::visit::Bfs,广度优先遍历实现方式如下:
use petgraph::visit::Bfs;
let mut bfs_graph = Graph::<(),(), petgraph::Undirected>::new_undirected();
// 0
// /|\
// 1 2 3
// |
// 4
bfs_graph.extend_with_edges(&[
(0, 1), (0, 2), (0, 3), (3, 4)
]);
for start in bfs_graph.node_indices() {
let mut bfs = Bfs::new(&bfs_graph, start);
print!("[{}] ", start.index());
while let Some(visited) = bfs.next(&bfs_graph) {
print!(" {}", visited.index());
}
println!();
};
上面代码会输出广度优先遍历顺序:
[0] 0 3 2 1 4
[1] 1 0 3 2 4
[2] 2 0 3 1 4
[3] 3 4 0 2 1
[4] 4 3 0 2 1
深度优先
深度优先需要用到petgraph::visit::Dfs,用法跟广度优先一样,只需要将Bfs替换成Dfs即可。
use petgraph::visit::Dfs;
let mut dfs_graph = Graph::<(),(), petgraph::Undirected>::new_undirected();
// 0
// /|\
// 1 2 3
// |
// 4
dfs_graph.extend_with_edges(&[
(0, 1), (0, 2), (0, 3), (3, 4)
]);
for start in dfs_graph.node_indices() {
let mut dfs = Dfs::new(&dfs_graph, start);
print!("[{}] ", start.index());
while let Some(visited) = dfs.next(&dfs_graph) {
print!(" {}", visited.index());
}
println!();
};
上面代码会输出深度优先遍历顺序:
[0] 0 1 2 3 4
[1] 1 0 2 3 4
[2] 2 0 1 3 4
[3] 3 0 1 2 4
[4] 4 3 0 1 2
后序深度优先
有时我们可能需要先迭代节点的邻居,然后是节点本身。petgraph为这种遍历顺序提供了DfsPostOrder。使用方式与深度遍历相同:
use petgraph::visit::DfsPostOrder;
let mut dfs_graph = Graph::<(),(), petgraph::Undirected>::new_undirected();
// 0
// /|\
// 1 2 3
// |
// 4
dfs_graph.extend_with_edges(&[
(0, 1), (0, 2), (0, 3), (3, 4)
]);
for start in dfs_graph.node_indices() {
let mut dfs = DfsPostOrder::new(&dfs_graph, start);
print!("[{}] ", start.index());
while let Some(visited) = dfs.next(&dfs_graph) {
print!(" {}", visited.index());
}
println!();
};
上面代码会输出后序深度优先遍历顺序:
[0] 1 2 4 3 0
[1] 2 4 3 0 1
[2] 1 4 3 0 2
[3] 1 2 0 4 3
[4] 1 2 0 3 4
图算法
petgraph支持许多图算法,这些算法都封装在algo包中。
寻路算法
在所有图算法中,日常用的最多的是寻路算法,比如被学校广泛教授的优雅的Dijkstra算法。下面列举一些需要用到寻路算法的场景:
- 计算机网络中两个节点之间边权重为ping时长
- 计算机网络中两个节点之间边权重为数据传输成本
- 计算机网络中两个节点之间边权重为ping时长和数据传输成本之和
- 地图上两个地点间的权重为两点间的距离
- 交易市场中边权重为两样商品或证券的兑换成本
上述列举的场景都可以通过 petgraph 建模,然而,petgraph 可能不适合建模地理空间图,我们需要使用专门的程序库或数据库来完成地理空间建模,例如Postgres,Postgres 可以使用 postgis 插件存储地理空间数据,并使用 pgRouting 查找最短路径。专用的地理空间路由引擎能够使用空间启发式算法(例如方向)来显著加速路径查找。
petgraph内置了3个寻路算法:
- Dijkstra算法:经典寻路算法
- A*算法:向Dijkstra算法中加入启发式算法
- Bellman_Ford算法:让Dijkstra算法支持负权重
这里拿最经典的Dijkstra算法给大家演示petgraph如何寻找最短路径:
use petgraph::algo;
let mut graph = Graph::<(),()>::new();
// 0
// /|\
// 1 2 3
// |
// 4
graph.extend_with_edges(&[
(0, 1), (0, 2), (0, 3), (3, 4)
]);
for start in graph.node_indices() {
println!("--- {:?} ---", start.index());
println!("{:?}", algo::dijkstra(&graph, start, None, |_| 1));
};
上面的代码以图上每一点作为起点,分别调用algo::dijkstra方法计算所能到达最终节点的最短路径。algo::dijkstra的接口定义如下:
pub fn dijkstra<G, F, K>(
graph: G,
start: G::NodeId,
goal: Option<G::NodeId>,
edge_cost: F
) -> HashMap<G::NodeId, K> where
G: IntoEdges + Visitable,
G::NodeId: Eq + Hash,
F: FnMut(G::EdgeRef) -> K,
K: Measure + Copy,
其中start代表起始节点;edge_cost是一个函数,返回节点间路径的cost,用于计算路径消耗,cost一定为非负数,在上面代码中我们恒定返回1;goal是个可选值,如果goal不为空,则一旦计算出目标节点的成本,算法就会终止。
注意,这里的返回值不是一条路径,而是一个Map,它包含了起始节点到每一个可达节点的最短路径成本。
上面的代码会输出如下信息:
--- 0 ---
{NodeIndex(1): 1, NodeIndex(3): 1, NodeIndex(2): 1, NodeIndex(4): 2, NodeIndex(0): 0}
--- 1 ---
{NodeIndex(1): 0}
--- 2 ---
{NodeIndex(2): 0}
--- 3 ---
{NodeIndex(3): 0, NodeIndex(4): 1}
--- 4 ---
{NodeIndex(4): 0}
0节点可以到达{0,1,2,3,4}节点,到达每个节点的最短路径消耗分别为{0, 1, 1, 1, 2};
1节点只能到达{1}节点,最短路径消耗为0;
2节点只能到达{2}节点,最短路径消耗为0;
3节点可以到达{3,4}节点,到达每个节点的最短路径消耗分别为{0, 1};
4节点只能到达{4}节点,最短路径消耗为0;
其他算法
除了寻路算法,petgraph还有很多其他算法,这里简单列举一些常用的算法:
- all_simple_paths: 返回给定节点上所有路径的迭代器
- condensation: 将每个强连接节点归并到一个节点
- connected_components:返回连通节点数
- has_path_connecting:如果两个节点间存在连通路径则返回True
- is_cyclic_directed:如果图中包含至少一个有向环则返回True
- is_cyclic_undirected: 如果图中包含至少一个环则返回
- kosaraju_scc:用 Kosaraju 算法返回强连通分量的向量
- min_spanning_tree:以树的形式返回每一个连通部分
- tarjan_scc:用 Tarjan 算法返回强连通分量向量
- toposort:返回按拓扑顺序排列的节点向量
结论
petgraph几乎涵盖了日常项目中所需的大部分功能,4种图实现能够满足绝大部分场景需求,并且使用Rust迭代器进行遍历带来了极大的灵活性和强大的功能,Rust的性能优势也非常凸显。但不幸的是,4种图实现缺乏通用接口,并且某些算法与某些图实现不兼容。如果所需的算法petgraph有实现,那么用petgraph是一个不错的选择。