(1)工业界推荐系统-小红书推荐场景及内部实践【业务指标、链路、ItemCF】
(2)工业界推荐系统-小红书推荐场景及内部实践【UserCF、离线特征处理】
(3)工业界推荐系统-小红书推荐场景及内部实践【矩阵补充、双塔模型】
(4)工业界推荐系统-小红书推荐场景及内部实践【正负样本选择】
(5)工业界推荐系统-小红书推荐场景及内部实践【线上召回和模型更新】
(6)工业界推荐系统-小红书推荐场景及内部实践【其他召回通道】
(7)工业界推荐系统-小红书推荐场景及内部实践【冷启动问题1】
(8)工业界推荐系统-小红书推荐场景及内部实践【冷启动问题2】
(9)工业界推荐系统-小红书推荐场景及内部实践【排序模型】
(10)工业界推荐系统-小红书推荐场景及内部实践【排序模型的特征】
(11)工业界推荐系统-小红书推荐场景及内部实践【粗排三塔模型】
(12)工业界推荐系统-小红书推荐场景及内部实践【交叉结构】
LastN特征
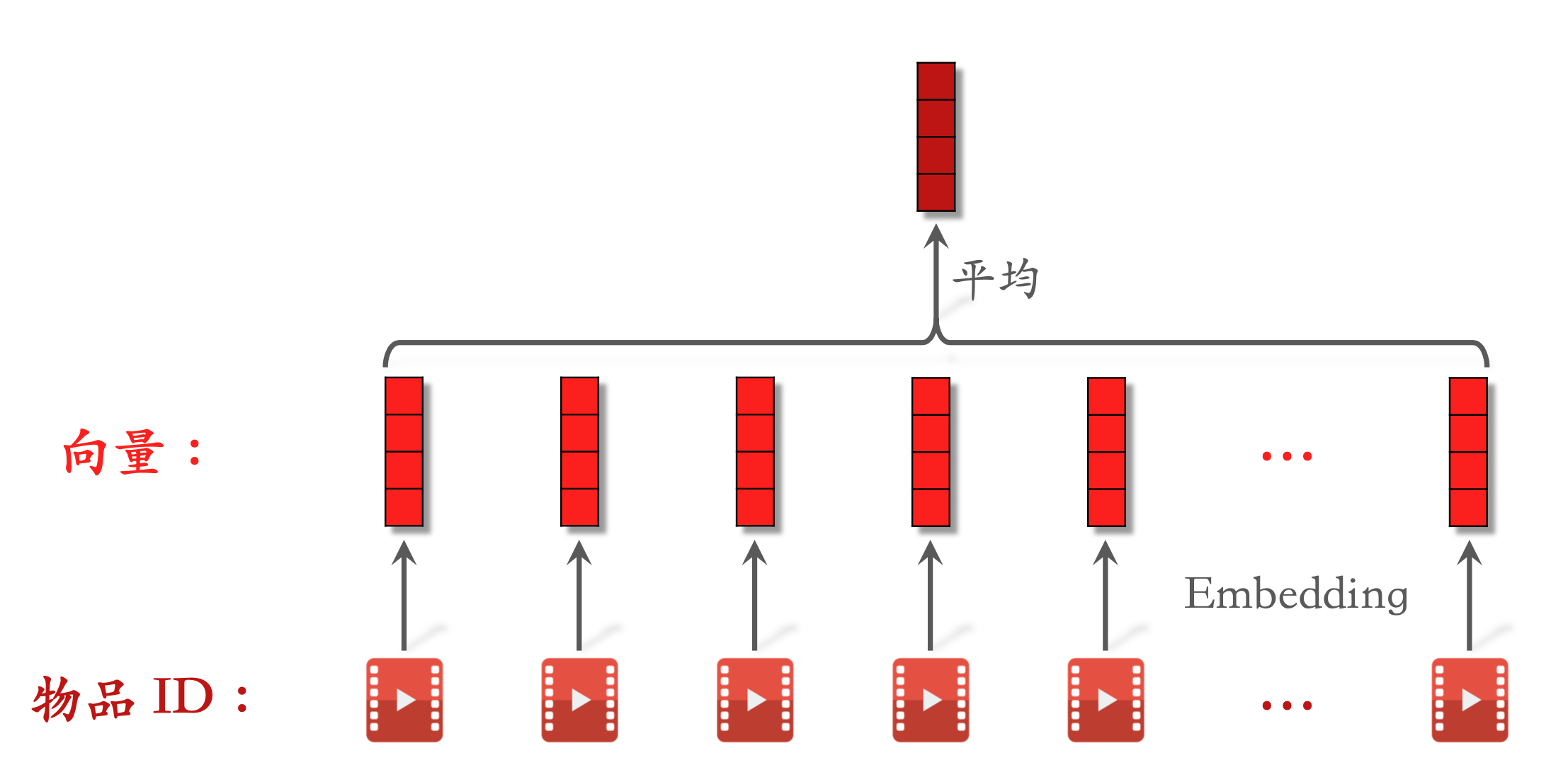
- LastN:用户最近的 𝑛 次交互(点击、点赞等)的物品ID。
- 对 LastN 物品 ID 做 embedding,得到 𝑛 个向量。
- 把 𝑛 个向量取平均,作为用户的一种特征。
- 适用于召回双塔模型、粗排三塔模型、精排模型。
Deep Neural Networks for YouTube Recommendations
DIN模型
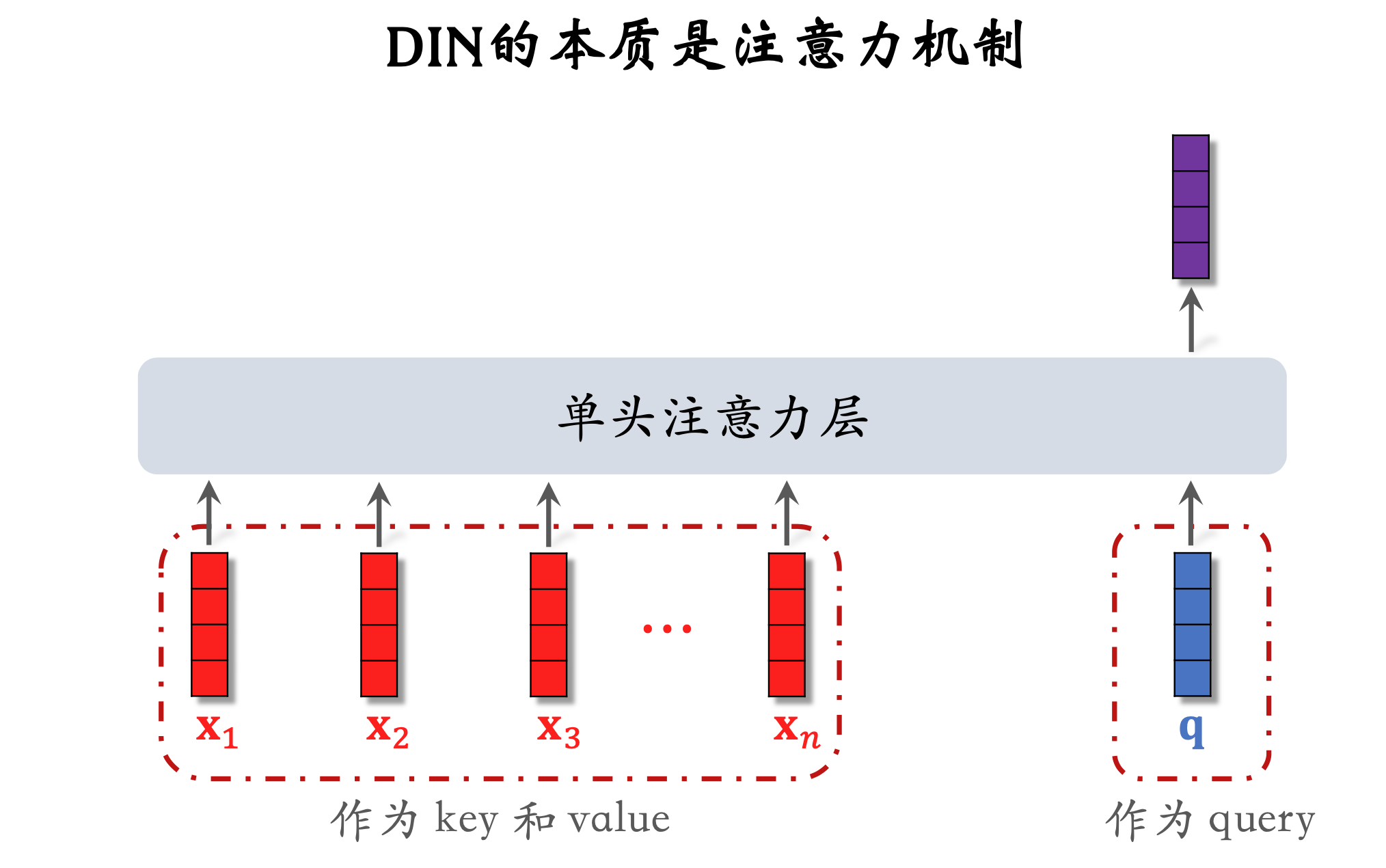
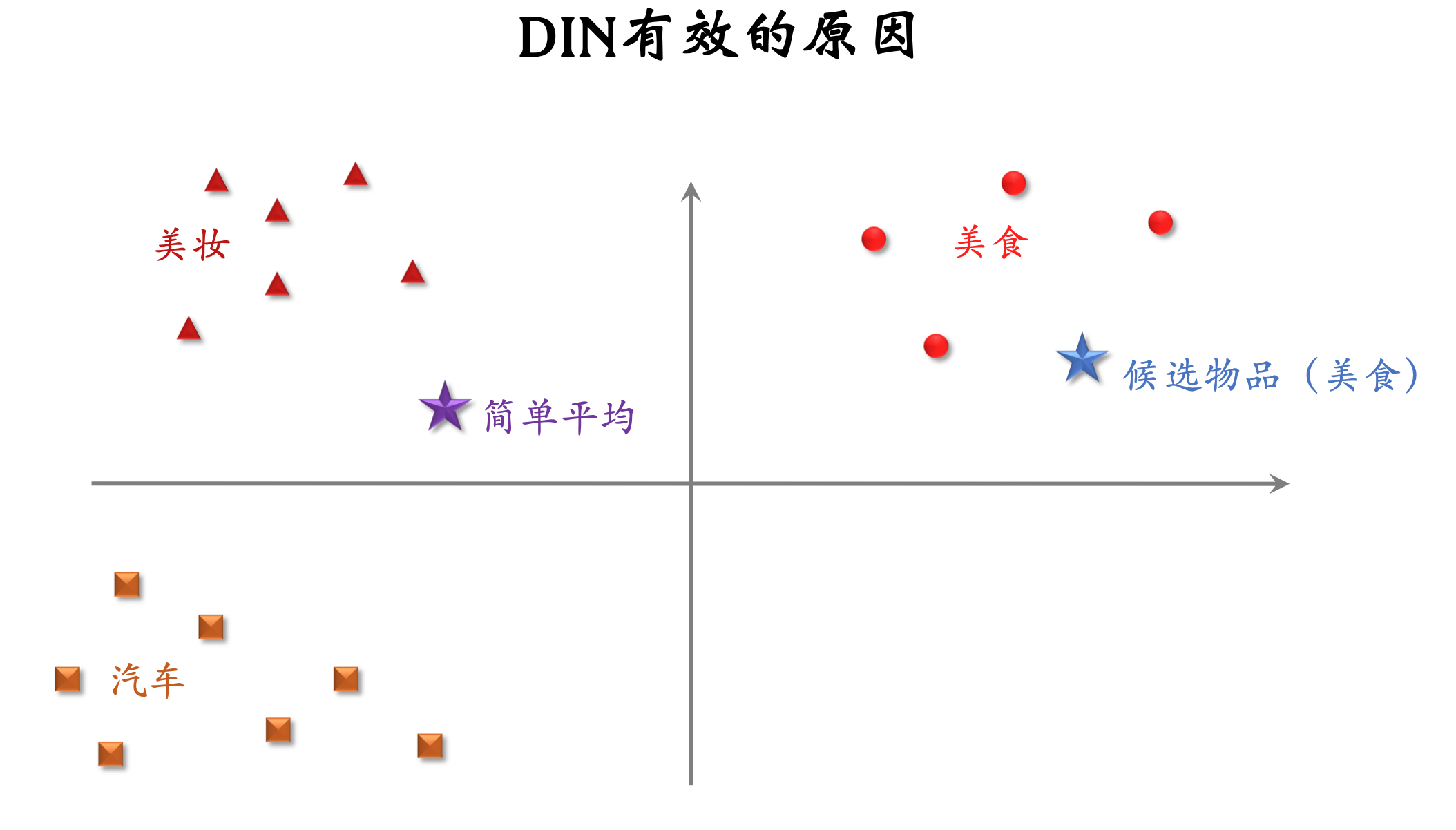
- DIN 用加权平均代替平均,即注意力机制 (attention)。
- 权重:候选物品与用户 LastN 物品的相似度。
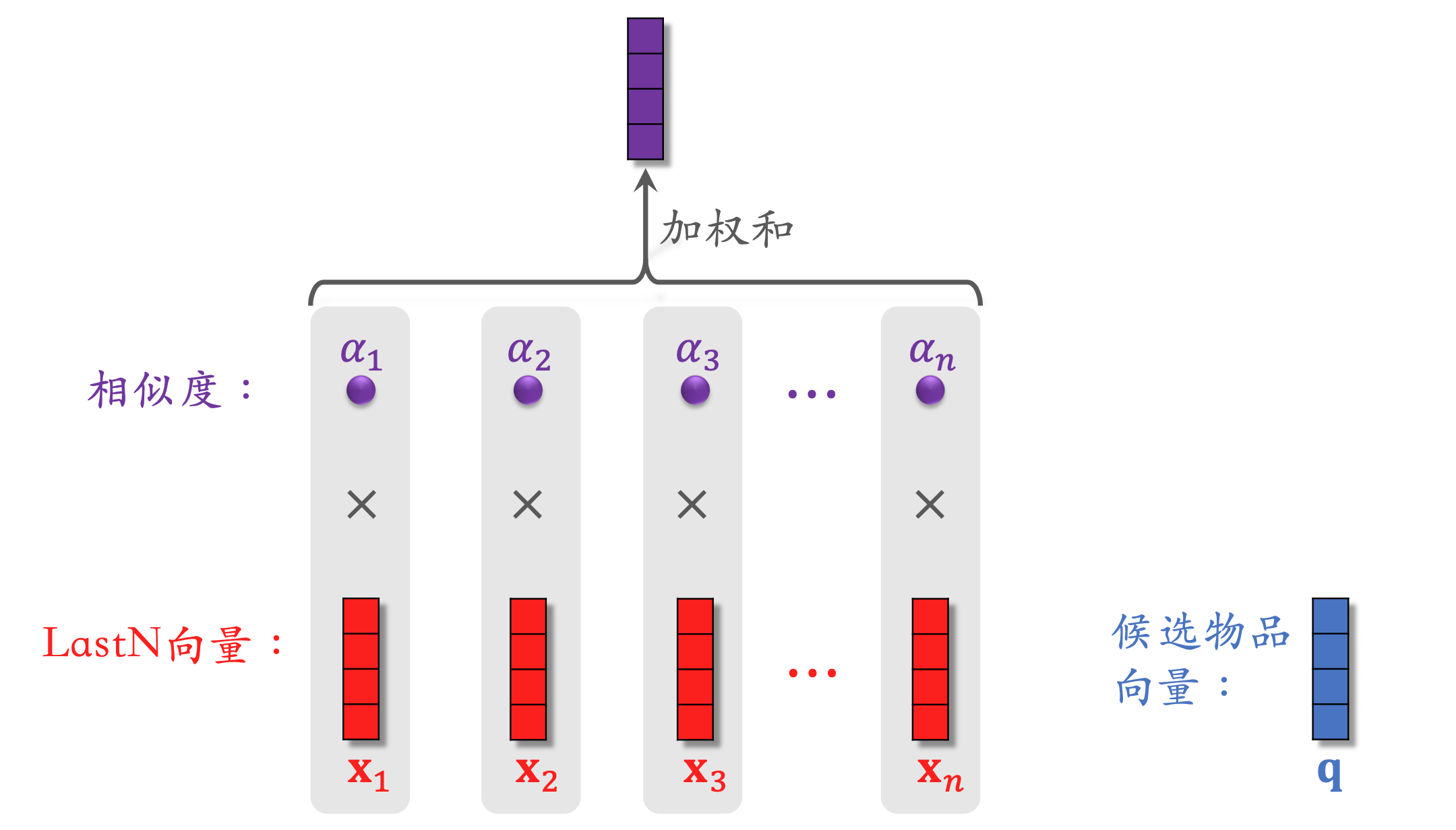
- 对于某候选物品,计算它与用户 LastN 物品的相似度。
- 以相似度为权重,求用户 LastN 物品向量的加权和,结果是一个向量。
- 把得到的向量作为一种用户特征,输入排序模型,预估(用户,候选物品)的点击率、点赞率等指标。
- 本质是注意力机制(attention)。

Deep interest network for click-through rate prediction
SIM模型
Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction
DIN模型的缺点
- 注意力层的计算量 ∝ 𝑛(用户行为序列的长度)。
- 只能记录最近几百个物品,否则计算量太大。
- 缺点:关注短期兴趣,遗忘长期兴趣。
如何改进DIN?
- 目标:保留用户长期行为序列(𝑛 很大),而且计算量不会过大。
- 改进 DIN:
- DIN 对 LastN 向量做加权平均,权重是相似度。
- 如果某 LastN 物品与候选物品差异很大,则权重接近零。
- 快速排除掉与候选物品无关的 LastN 物品,降低注意力 层的计算量。
SIM
- 保留用户长期行为记录,𝑛 的大小可以是几千。
- 对于每个候选物品,在用户 LastN 记录中做快速查找,找到 𝑘 个相似物品。
- 把 LastN 变成 TopK,然后输入到注意力层。
- SIM 模型减小计算量(从 𝑛 降到 𝑘)。
第一步 查找
- 方法一:Hard Search
- 根据候选物品的类目,保留 LastN 物品中类目相同的。
- 简单,快速,无需训练。
- 方法二:Soft Search
- 把物品做 embedding,变成向量。
- 把候选物品向量作为query,做 𝑘 近邻查找,保留 LastN 物品中最接近的 𝑘 个。
- 效果更好,编程实现更复杂。
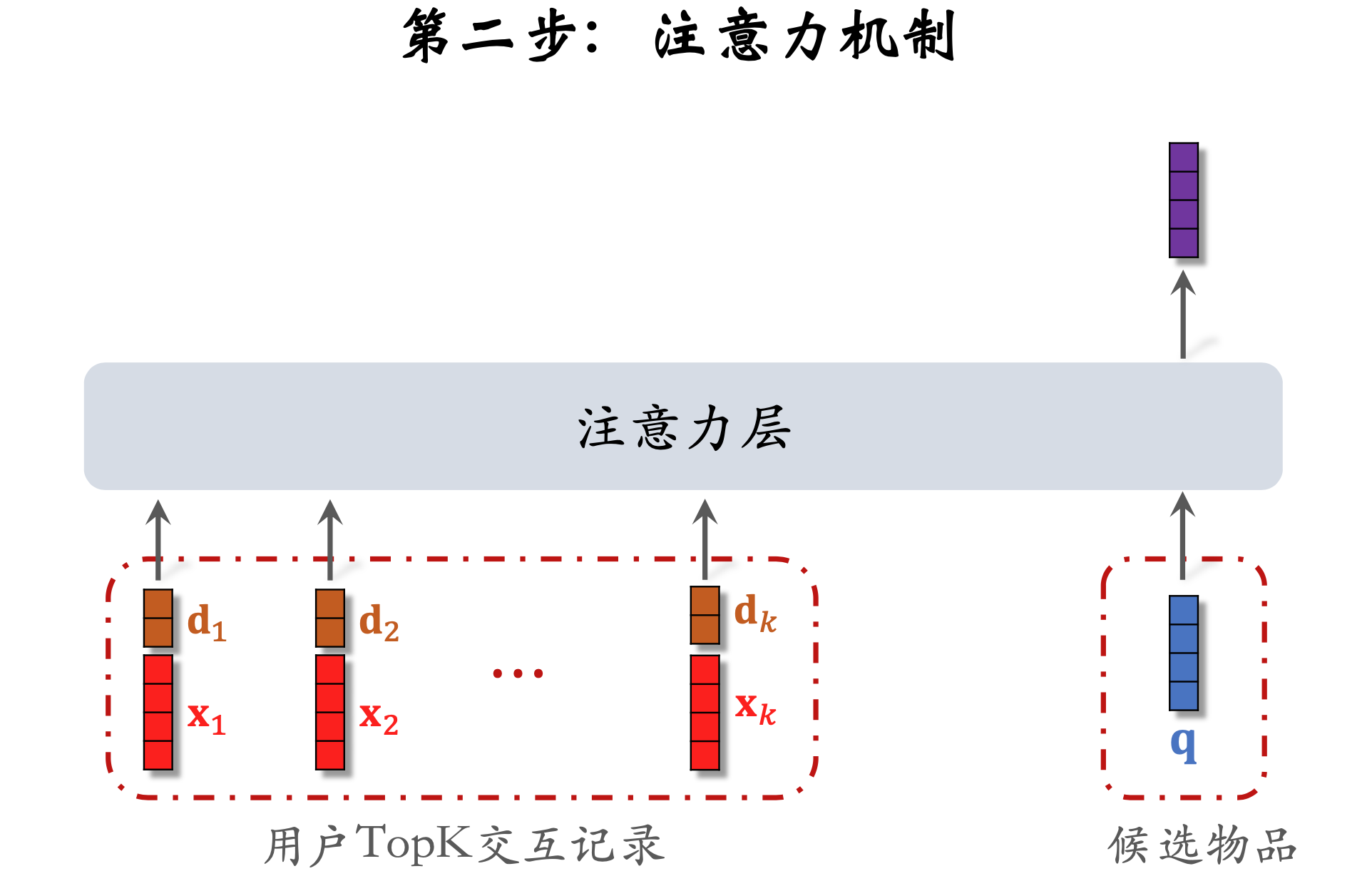
第二步 注意力机制
使用时间信息
- 用户与某个 LastN 物品的交互时刻距今为 𝛿。
- 对 𝛿 做离散化,再做 embedding,变成向量 𝐝。
- 把两个向量做 concatenation,表征一个 LastN 物品。
- 向量 𝐱 是物品 embedding 。
- 向量 𝐝 是时间的 embedding。
为什么 SIM 使用时间信息?
- DIN 的序列短,记录用户近期行为。
- SIM 的序列长,记录用户长期行为。
- 时间越久远,重要性越低。