前言:
对于lego-loam中点云聚类源码的学习,它使用了广度优先算法,并且使用了数组双指针技巧。
主要分为两个部分:
第一个是labelComponents函数,它的功能是为每个点及其相邻的4个点运算角度,在对角度小于60度的点进行标记。
第二个是cloudSegmentation函数,它的功能是对于标记过的点进行聚类划分。
一、标记
在labelComponents函数中实现。
float d1, d2, alpha, angle;
int fromIndX, fromIndY, thisIndX, thisIndY;
bool lineCountFlag[N_SCAN] = {false};d1,d2是邻近点之间的最大距离和最小距离;
fromIndX是当前点的x坐标;
fromIndY是当前点的y坐标;
thisIndX是邻近点的x坐标;
thisIndY是邻近点的y坐标;
lineCountFlag是记录scans的是否使用的flag。
queueIndX[0] = row;
queueIndY[0] = col;
int queueSize = 1;
int queueStartInd = 0;
int queueEndInd = 1;将输入的row赋值给queueIndX[0];
将输入的col赋值给queueIndY[0];
将queueSize赋值为1;
将queueStartInd赋值为0;
将queueEndInd赋值为1。
queueStartInd和queueEndInd是双指针,用来遍历每一个queue中的点云。
allPushedIndX[0] = row;
allPushedIndY[0] = col;
int allPushedIndSize = 1;allPushedIndX表示遍历过的indexX;
allPushedIndY表示遍历过的indexY;
设置allPushedIndSize为1表示已经有一个点遍历过了。
while(queueSize > 0){
...
}这是进入循环,根据queueSize的大小作为循环的条件,小于等于0表示queue中没有点了。
// Pop point
fromIndX = queueIndX[queueStartInd];
fromIndY = queueIndY[queueStartInd];
--queueSize;
++queueStartInd;将点云的在mat中的索引值放入fromIndX和fromInY,之后将queueSize值减小一个,并将queueStartInd指针向后移动一位。
// Mark popped point
labelMat.at<int>(fromIndX, fromIndY) = labelCount;在labelMat矩阵中将该点赋值为labelCount,但这个labelCount前面没有赋值,难道是赋值为0?
下面就进入了前面说的根据上下左右的点计算距离的for循环。
首先要定义一下上下左右的方向。
std::vector<std::pair<int8_t, int8_t> > neighborIterator; // neighbor iterator for segmentaiton process定义neighborIterator为一个vector里面是一个pair<int8_t, int8_t>。
std::pair<int8_t, int8_t> neighbor;
neighbor.first = -1; neighbor.second = 0; neighborIterator.push_back(neighbor);
neighbor.first = 0; neighbor.second = 1; neighborIterator.push_back(neighbor);
neighbor.first = 0; neighbor.second = -1; neighborIterator.push_back(neighbor);
neighbor.first = 1; neighbor.second = 0; neighborIterator.push_back(neighbor);将上下左右四个方向存入neighborIterator。
for (auto iter = neighborIterator.begin(); iter != neighborIterator.end(); ++iter){
...
}
结合上上面的neighborIterator存放的四个数据一起,可以看出这个是遍历点上下左右四个方向邻近点。
下面分析for里面的内容。
// new index
thisIndX = fromIndX + (*iter).first;
thisIndY = fromIndY + (*iter).second;
// index should be within the boundary
if (thisIndX < 0 || thisIndX >= N_SCAN)
continue;
// at range image margin (left or right side)
if (thisIndY < 0)
thisIndY = Horizon_SCAN - 1;
if (thisIndY >= Horizon_SCAN)
thisIndY = 0;
// prevent infinite loop (caused by put already examined point back)
if (labelMat.at<int>(thisIndX, thisIndY) != 0)
continue;fromIndX和fromIndY就是当前点,然后通过迭代器的值,求出下右左上点的索引值并赋值为thisIndX和thisIndY。
之后就是几个范围划定条件,不能小于0和大于N_SCAN。当thisIndY小于0时,邻点分到最右边的点。当thisIndY大于Horizon_SCAN就分到最左边的点。因为这个矩阵表示点云的一帧,一帧是360度的。
最后一个if是判断该点是否标记为已经经过计算的点,如果是,就直接跳过。
d1 = std::max(rangeMat.at<float>(fromIndX, fromIndY),
rangeMat.at<float>(thisIndX, thisIndY));
d2 = std::min(rangeMat.at<float>(fromIndX, fromIndY),
rangeMat.at<float>(thisIndX, thisIndY));d1是选中点和邻点与激光lidar距离最大的点;
d2是选中点和邻点与激光lidar距离最小的点。
if ((*iter).first == 0)
alpha = segmentAlphaX;
else
alpha = segmentAlphaY;这里是用来区分是水平分辨率还是竖直分辨率。

如上图所示,这是根据激光lidar的参数来划定的,用法在下面体现。
angle = atan2(d2*sin(alpha), (d1 -d2*cos(alpha)));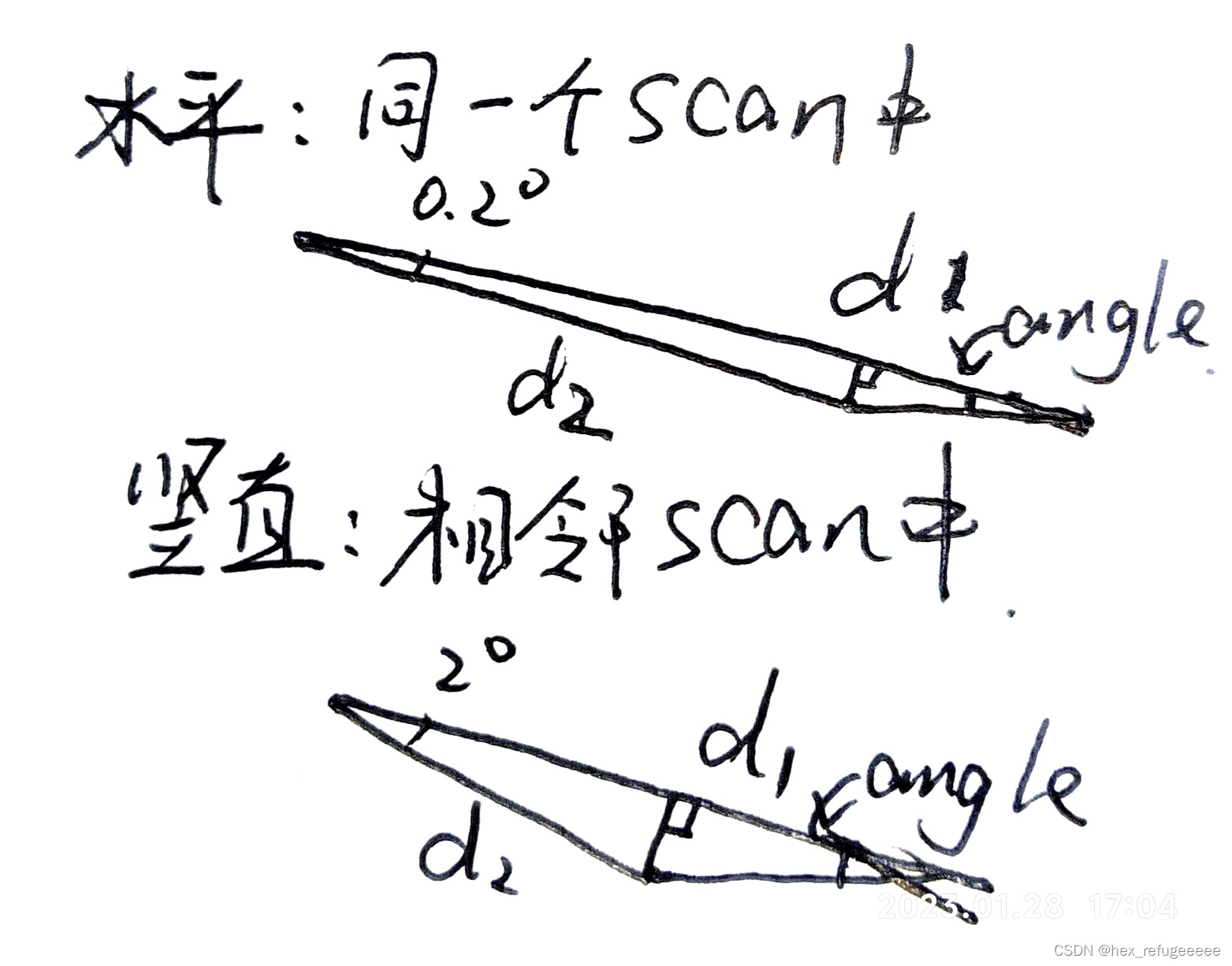
理由如上图所示。
if (angle > segmentTheta){
queueIndX[queueEndInd] = thisIndX;
queueIndY[queueEndInd] = thisIndY;
++queueSize;
++queueEndInd;
labelMat.at<int>(thisIndX, thisIndY) = labelCount;
lineCountFlag[thisIndX] = true;
allPushedIndX[allPushedIndSize] = thisIndX;
allPushedIndY[allPushedIndSize] = thisIndY;
++allPushedIndSize;
}segmentTheta设置为60度,当角度大于60度,作者就认为它是值的聚类。
并将它的邻点的索引值放入queueIndX和queueIndY中。然后queueSize自增1,尾指针向右移动一位。
然后将labelCount赋值给labelMat矩阵,并将记录每个scan是否被使用置为true。
最后把allPushedIndX和allPushedIndY数组填充如thisIndX和thisIndY,并将allPushedIndSize加1。
for循环的内容结束。
// check if this segment is valid
bool feasibleSegment = false;
if (allPushedIndSize >= 30)
feasibleSegment = true;
else if (allPushedIndSize >= segmentValidPointNum){
int lineCount = 0;
for (size_t i = 0; i < N_SCAN; ++i)
if (lineCountFlag[i] == true)
++lineCount;
if (lineCount >= segmentValidLineNum)
feasibleSegment = true;
}定义一个标志位feasibleSegment,并设置为false。
如果allPushedIndSize大于30就设置为true;
如果allPushedIndSize大于5就进入判断,设置lineCount为0,根据前面lineCountFlag数组,判断它是否被使用过,如果使用过就加一。最后当lineCount大于等于3就将feasibleSegment设置为true。
// segment is valid, mark these points
if (feasibleSegment == true){
++labelCount;
}else{ // segment is invalid, mark these points
for (size_t i = 0; i < allPushedIndSize; ++i){
labelMat.at<int>(allPushedIndX[i], allPushedIndY[i]) = 999999;
}
}这里就是判断,如果feasibleSegment是true,就将labelCount自增,如果是false就将所有的点都设置为999999。
二、聚类
聚类的实现是在cloudSegmentation函数里面。
// segmentation process
for (size_t i = 0; i < N_SCAN; ++i)
for (size_t j = 0; j < Horizon_SCAN; ++j)
if (labelMat.at<int>(i,j) == 0)
labelComponents(i, j);首先将所有的点进行标记。
int sizeOfSegCloud = 0;
// extract segmented cloud for lidar odometry
for (size_t i = 0; i < N_SCAN; ++i) {
segMsg.startRingIndex[i] = sizeOfSegCloud-1 + 5;
for (size_t j = 0; j < Horizon_SCAN; ++j) {
if (labelMat.at<int>(i,j) > 0 || groundMat.at<int8_t>(i,j) == 1){
// outliers that will not be used for optimization (always continue)
if (labelMat.at<int>(i,j) == 999999){
if (i > groundScanInd && j % 5 == 0){
outlierCloud->push_back(fullCloud->points[j + i*Horizon_SCAN]);
continue;
}else{
continue;
}
}
// majority of ground points are skipped
if (groundMat.at<int8_t>(i,j) == 1){
if (j%5!=0 && j>5 && j<Horizon_SCAN-5)
continue;
}
// mark ground points so they will not be considered as edge features later
segMsg.segmentedCloudGroundFlag[sizeOfSegCloud] = (groundMat.at<int8_t>(i,j) == 1);
// mark the points' column index for marking occlusion later
segMsg.segmentedCloudColInd[sizeOfSegCloud] = j;
// save range info
segMsg.segmentedCloudRange[sizeOfSegCloud] = rangeMat.at<float>(i,j);
// save seg cloud
segmentedCloud->push_back(fullCloud->points[j + i*Horizon_SCAN]);
// size of seg cloud
++sizeOfSegCloud;
}
}
segMsg.endRingIndex[i] = sizeOfSegCloud-1 - 5;
}首先设置sizeOfSegCloud为0;
然后进入两个for循环遍历所有的点;
然后判断labelMat矩阵大于0和groundMat矩阵中为1的进入循环处理;
将labelMat中999999的点中i大于3且j每隔5个的点放入outline中;
将groundMat矩阵中为1的点中j大于5且j小于Horizon_SCAN-5且不被5整除的j都continue,留下的是可以被5整除的。
后面部分就是对于segMsg的设置赋值,并保存等操作。
if (pubSegmentedCloudPure.getNumSubscribers() != 0){
for (size_t i = 0; i < N_SCAN; ++i){
for (size_t j = 0; j < Horizon_SCAN; ++j){
if (labelMat.at<int>(i,j) > 0 && labelMat.at<int>(i,j) != 999999){
segmentedCloudPure->push_back(fullCloud->points[j + i*Horizon_SCAN]);
segmentedCloudPure->points.back().intensity = labelMat.at<int>(i,j);
}
}
}
}将全部符合条件的点云放入segmentedCloudPure里面。
三、总结
对于广度优先算法的实现理解不够透彻,需要学习一下相关的实现。lego-loam中关于label部分的实现很巧妙,给我很大的启发。