前言
前面总结压测类型的时候有简单描述了不同压测类型的从准备-脚本设计-压测的整体过程,但是对于压测对象没有更深入的进行分析总结,导致在压测执行结束后,出现压测结果不准确的情况。所以这边就压测的对象进行单独的总结分析。
在执行压测的时候,压测模型和数据模型需要尽可能的模拟真实环境的请求情况,只有在这种模式下进行压测,产出的报告才具备参考性。
压测模型
我这边所要描述的压测模型,主要指我们设计压测脚本的具体的对象(内容),不同类型的压测目标,对应的需要进行压测模型就不一样。
这就好比我们点外卖点餐一样,老板要打包就需要明白打包的东西是什么?
1.客户点「白米饭」,那老板只要把白米饭给我们就好(其中白米饭就是具体的对象)
2.客户点「蛋炒饭」,那老板要把白米饭和蛋加工后,再一起提供给我们(其中白米饭和蛋就是具体的对象)
1.评估单个接口请求的性能瓶颈
针对核心功能请求量比较大的接口,在进行发布前会需要进行单个接口请求的性能瓶颈,就是对单个接口进行逐步提高请求压力,查看该接口的QPS极限,以及过程中出现的问题

2.评估指定业务场景的性能瓶颈
在指定场景,需要通过逐步提高压力来探查部分接口的性能瓶颈;例如热点推送、双十一等特殊时期,需要大量用户在同一个周期内点击查看推送内容、或者大量用户进行下单支付,这个流量突然增大的情况下,接口请求或者服务是否存在性能瓶颈问题。

3.评估当前服务整体的性能瓶颈
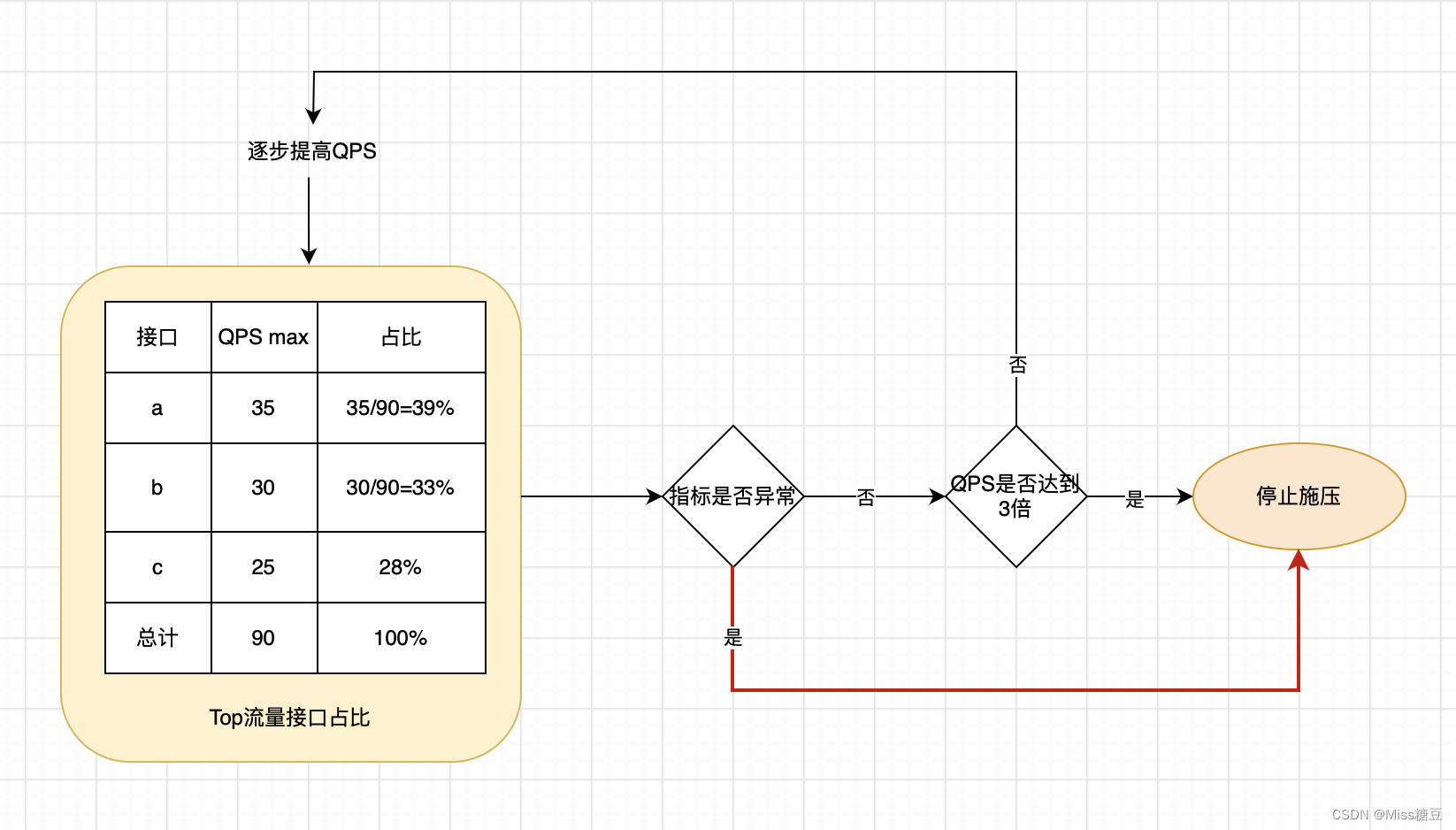
按照当前服务的top流量接口请求,计算每个接口的请求占比,按照占比同时进行施压:
1.grafana平台获取top流量接口列表
2.根据实际情况选择压测接口,必须满足以下2个条件
2.1 QPS>100(100是个参考值,可以根据实际业务情况进行调整,主要满足条件2.2即可)
2.2 选取的所有接口总流量/服务总流量>90%(流量占比越接近100%,压测模型就越贴近实际,压测结果更准确)
案例:
服务的QPS max峰值5000,选取的top流量接口有6个,6个接口的QPS max总和为4900,那么总流量占比=4900/5000*100%=98%
3.计算单个接口的压测流量占比
选择的top流量接口有5个分别是a、b、c、d、e,则各个接口的流量占比为:
接口a占比=a /(a+b+c+d+e)*100%,其他也同样进行计算
数据模型
梳理完压测的模型后,需要考虑接口传递的数据时什么样子的,也就时数据模型。
主要是准备压测时使用的测试数据,本次实践中总结出2点:
1.压测数据尽可能模拟大部分用户的真实场景
1.1面对数据:数据缓存、数据量、数据的其他特征情况
1.2面对用户:对单个用户、还是多个用户进行压测
2.环境尽可能贴近真实用户使用的环境
2.1服务资源配置:应用资源配置、数据库配置等
2.2数据库特殊处理:例如线上用户数据有分表,那么在压测时需要同样选择有分表的数据库进行压测
案例:
| 接口类型 | 数据要求 |
| 获取内容列表 | 总数据量:total=1w 单页查询数据量:pagesize=15 页码:pagenum=随机1-100之间 |
| 修改内容 | 1.随机获取内容 2.随机获取大json、小json对内容进行修改 |
在技术大佬的指导下,深入重新梳理分析了压测的流量模型和数据模型,最后输出的压测方案明显比前面自己绞尽脑汁、东拼西凑得到的方案显得更专业、更具有执行价值~在此感谢大佬的支援~♥️以上仅为个人本次性能实践的总结~仅供参考~
生活是自己的
千万别为难自己
有什么样的能力
就过什么样的生活