一、工具下载
https://download.csdn.net/download/huangbangqing12/87400984
二、工具使用方式
目录文件如下所示:
请先在word.txt文件里放入目标长尾词,一行一个:
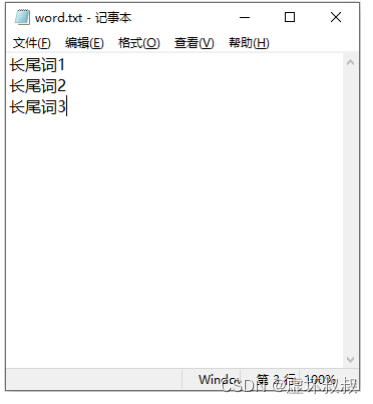
文件-另存为:
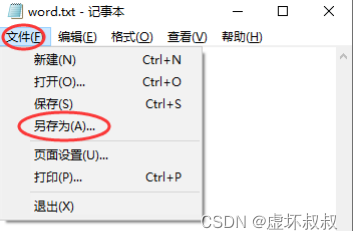
选择utf-8编码并直接保存替换原文件:
打开程序文件“WordCount.exe”:
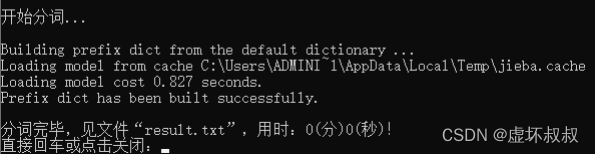
程序自动执行到完毕,看到最底部的提示即可关闭。
数据结果保存在“result.txt”文件里。
程序自动执行到完毕,看到最底部的提示即可关闭。
数据结果保存在“result.txt”文件里。
其他文件作用
“userdict.txt” – 自定义词库
比如 贴吧 这个词分词程序把它分开了,变成了 贴 吧,因为程序不认识它,它不是什么常见
词,但是我们知道它是一个具体的名词,我希望分词程序把它看成一个整体,于是在这个文件
里加入 贴吧 n,一行一个,中间有空格:
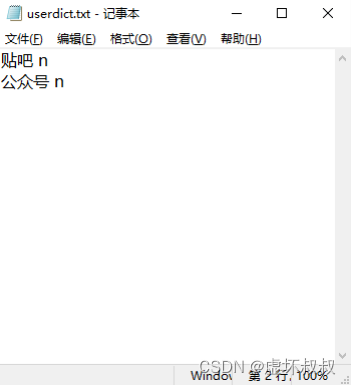
这样程序就会知道“贴吧”是一个词,遇到时要当成一个词看待。
n 代表名称,如果只是担心程序不认识所以加入自定义词库,默然写n即可。
delword.txt – 自定义分词
比如 百度贴吧 程序把它看成一个词,但我希望百度是百度,贴吧是贴吧,于是在这份文件里
加入 百度贴吧 也是一行一个:

这样程序就会对这个词再进一步分割成更细的词汇:百度 贴吧。
flag.txt – 屏蔽词性表
n 对程序来说表示名称,v 表示动词,我不希望词频结果里有动词,所以在这个文件里加入 v
也是一行一个:
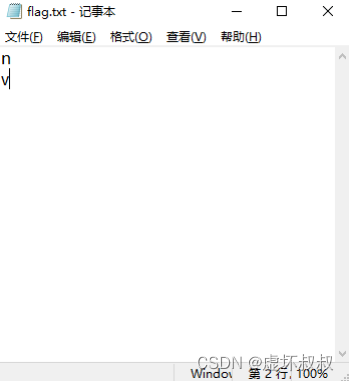
这样程序在计算过程中就会忽略目标类型的词。
PS:所有TXT文件在修改后保存时均采用“文件”-“另存为”-“utf-8”的方式,由于win系统可 能存在编码问题,不可直接保存
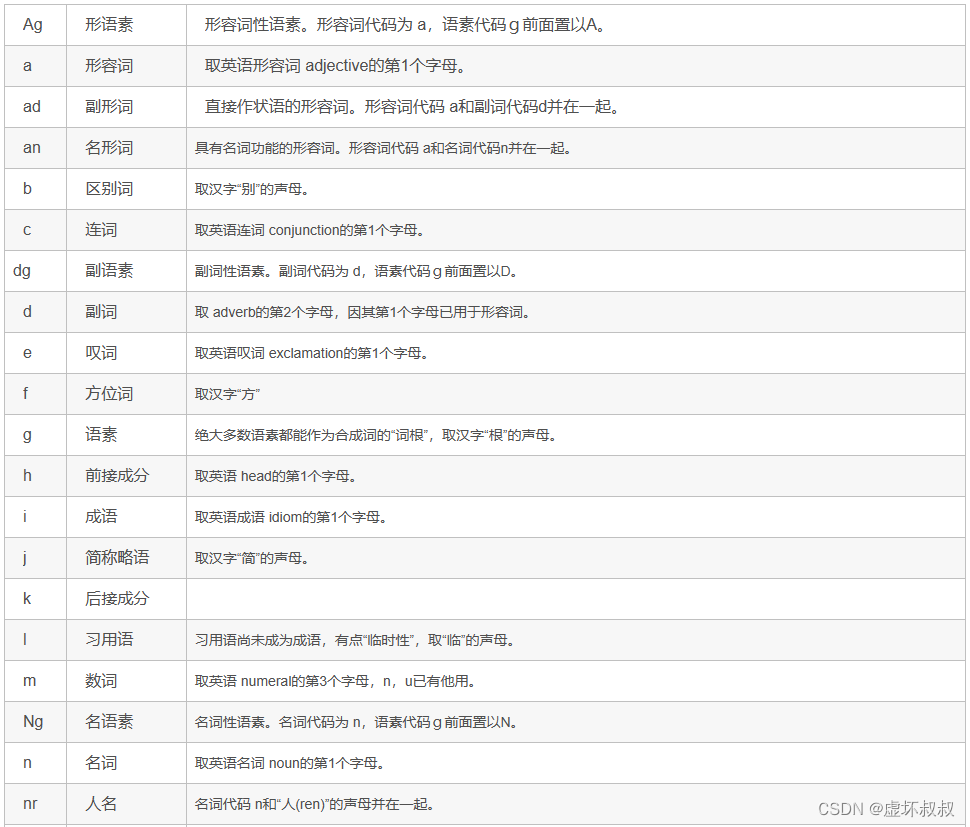
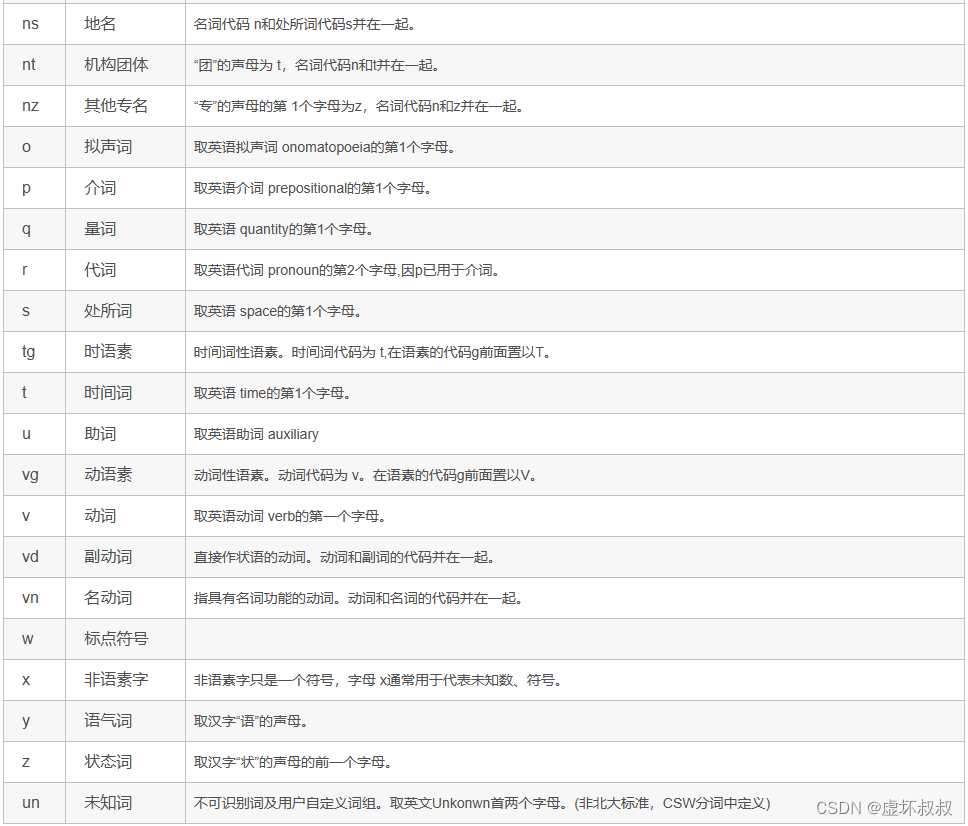
三、Jieba分词词性标注以及词性说明
import jieba
import jieba.analyse
import jieba.posseg
def dosegment_all(sentence):
'''
带词性标注,对句子进行分词,不排除停词等
:param sentence:输入字符
:return:
'''
sentence_seged = jieba.posseg.cut(sentence.strip())
outstr = ''
for x in sentence_seged:
outstr+="{}/{},".format(x.word,x.flag)
#上面的for循环可以用python递推式构造生成器完成
# outstr = ",".join([("%s/%s" %(x.word,x.flag)) for x in sentence_seged])
return outstr
Example:
苹果官网iPhone降价!再次惊觉了神网友们的才华 一群同学
苹果/n,官网/n,iPhone/n,降价/n,!/x,再次/d,惊觉/a,了/ul,神/n,网友/n,们/k,的/uj,才华/nr, /x,一群/m,同学/n,