17周期末考试
重点从第五章 scala语言开始
比如:映射(匿名函数)

11.3.1创建属性图
import org.apache.spark.graphx._
import org.apache.spark.rdd.RDD
//创建一个顶点集的RDD
val users: RDD[(VertexId ,(String,String))] = sc.parallelize(
Array(
(3L,("rxin","student")),
(7L,("jgonzal","postdoc")),
(5L,("franklin","prof")),
(2L,("istoica","prof")),
))
//创建一个边集的RDD
val relationships:RDD[Edge[String]] = sc.parallelize(Array(
Edge(3L,7L,"collab"),
Edge(5L,3L,"advisor"),
Edge(2L,5L,"colleague"),
Edge(5L,7L,"pi"),
))
//定义边中用户缺失时的默认(缺失)用户,
val defaultuser = ("John Doe" , "Missing")
//使用users和relationships两个RDD实例化Graph类建立一个Graph对象
val graph = Graph(users, relationships , defaultuser)
//查看图的顶点信息
graph.vertices.collect.foreach(println)
graph.edges.collect.foreach(println)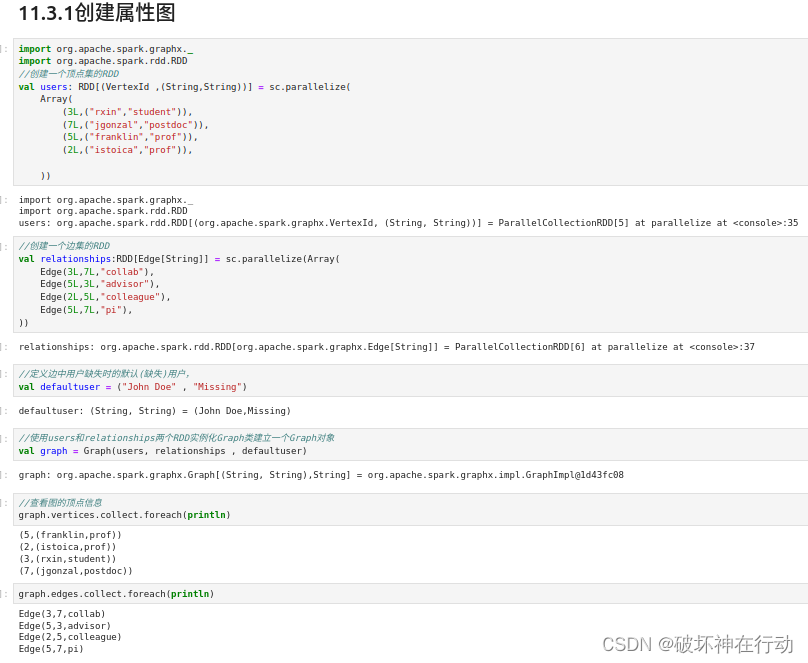
11.3.2使用边集合的RDD创建属性图
//读取本地文件创建属性图
val recordRDD: RDD[String] = sc.textFile("edges .txt")
val EdgeRDD = recordRDD.map{
x =>val fields = x.split(" ");
Edge(
fields(0).toLong,
fields(1).toLong,
fields(2)
)
}
//使用EdgeRDD实例化Graph类建立一个Graph对象
val graphInfo = Graph.fromEdges(EdgeRDD,"VerDefaultAttr")
//查看属性图的顶点信息
graphInfo.vertices.collect.foreach(println)
//查看属性图的边信息
graphInfo.edges.collect.foreach(println)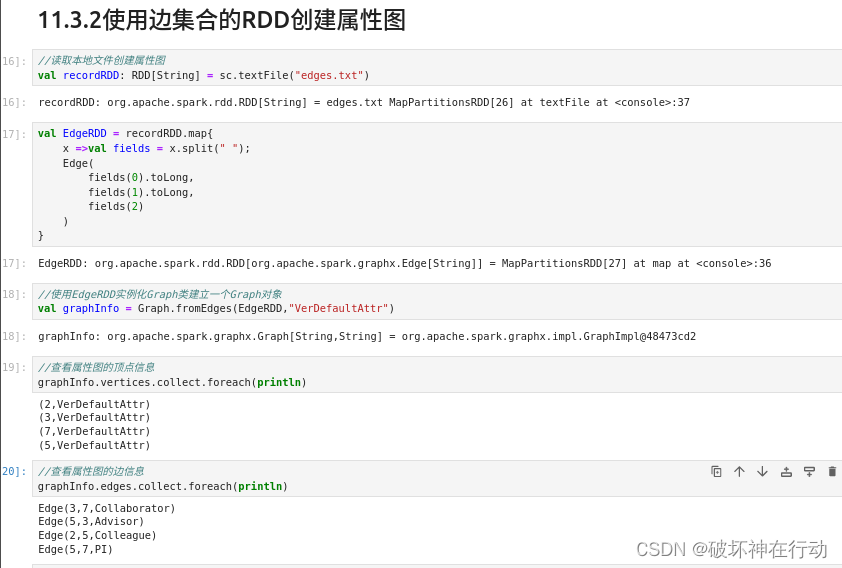
11.3.3使用边的两个顶点的ID所组成的二元组RDD创建属性图
val recordRDD: RDD[String] = sc.textFile("edges.txt")
//创建源点ID和目的点ID二元组集合的RDD
val EdgeTupleRDD = recordRDD.map{
x=> val fields = x.split("");
(fields(0).toLong,fields(1).toLong)
}
//使用EdgeTupleRDD实例化Graph类建立一个Graph对象
val graph_fromEdgeTuples = Graph.fromEdgeTuples(EdgeTupleRDD,168L)
graph_fromEdgeTuples.vertices.collect.foreach(println)
graph_fromEdgeTuples.edges.collect.foreach(println) 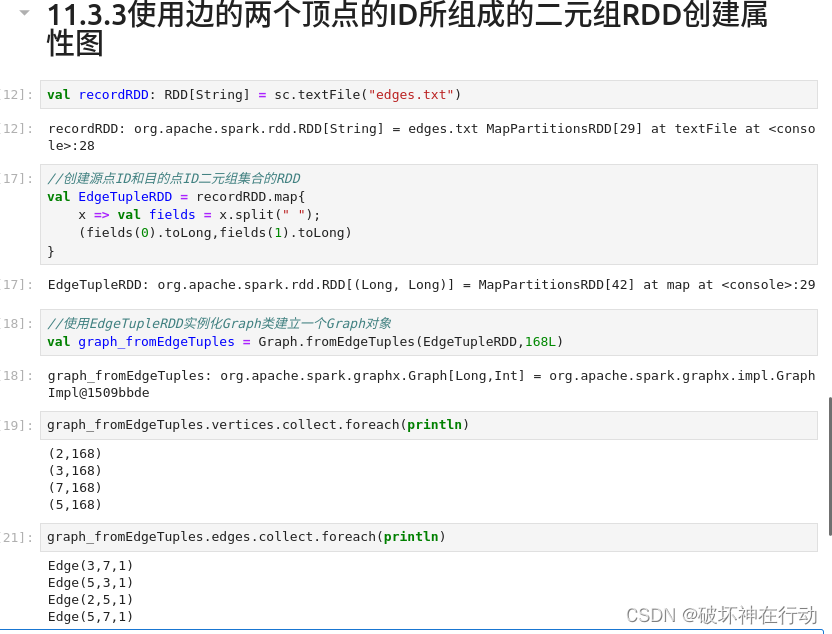
11.4属性图操作
import org.apache.spark.graphx._
import org.apache.spark.rdd.RDD
//创建一个顶点集的RDD,VertexId是Long 类型数据,顶点属性是二元组
val users:RDD[(VertexId,(String, Int))]=sc.parallelize(Array(
(1L,("非菲",22)),
(2L,("乔乔",17)),
(3L,("王强",19)),
(4L,("王刚",21)),
(5L,("李倩",20)),
(6L,("林锋",25))
))
//创建一个边集的RDD
val relationships: RDD[Edge[Int]] = sc.parallelize(Array(
Edge(1L, 3L, 15),
Edge(2L, 1L, 10),
Edge(2L, 3L, 21),
Edge(2L, 4L, 22),
Edge(3L, 6L, 10),
Edge(4L, 5L, 17),
Edge(5L, 6L, 20)
))
//定义边中用户缺失时的默认(缺失)用户
val defaultUser =("某某",18)
//使用users 和relationships 两个RDD实例化Graph 类,建立一个Graph 对象
val userGraph = Graph(users,relationships,defaultUser)11.4.1图的属性操作
下面通过图的属性获取属性图的边的数量、居性图的顶点的数量、属性图的所有顶点的入度、属性图的所有顶点的出度,以及属性图的所有项点的入度与出度之和。
1.获取属性图的边的数量
使用属性图对象的numEdges 属性返回属性图的边的数量,返回值类型为Long。
//获取属性图的边的数量
scala> userGraph.numEdges
resl: Long = 7 2.获取属性图的顶点的数量
使用属性图对象的mumVertices 属性返回属性图的顶点的数量,返回值类型为Long
scala> userGraph.numVertices
res2:Long = 6//获取顶点的数量
3.获取属性图的所有顶点的人度
使用属性图对象的inDegrees 属性返回属性图的所有顶点的人度,返回值类型为
VertexRDD[Int]。
scala> userGraph.inDegrees.collect.foreach(println)//输出所有顶点的人度
4.获取属性图的所有顶点的出度
使用属性图对象的outDegrees 属性返回属性图的所有顶点的出度,返回值类型为
VertexRDD[Int]。
scala> userGraph.outDegrees.collect.foreach(println)//输出所有顶点的出度
5.获取属性图的所有顶点的入度与出度之和
使用属性图对象的degrees属性返回属性图的所有顶点的入度与出度之和,返回值类型
为VertexRDD[Int]。
scala> userGraph.degrees.collect.foreach(x=>print(x+","))//输出所有顶点的入度和出度之和
(4,2),(1,2),(6,2),(3,3),(5,2),(2,3),
11.4.2图的视图操作
1.顶点视图
//输出所有顶点
userGraph.vertices.collect.foreach(println)
(4,(王刚,21)) (1,(非菲,22)) (5,(李倩,20)) (6,(林锋,25)) (2,(乔乔,17)) (3,(王强,19))
//case模式匹配
userGraph.vertices.map{
case(id,(name,age)) =>
(age,name)
}.collect.foreach(println)
(21,王刚) (22,非菲) (20,李倩) (25,林锋) (17,乔乔) (19,王强)
//过滤
userGraph.vertices.filter{
case(id,(name,age)) =>
age<20
}.collect.foreach(println)
(2,(乔乔,17)) (3,(王强,19))
Selection deleted
//元组索引查看顶点信息
userGraph.vertices.map{
v => ("姓名:" + v._2._1,
"年龄:" + v._2._2,
"ID:" + v._1)
}.collect.foreach(println)
(姓名:王刚,年龄:21,ID:4) (姓名:非菲,年龄:22,ID:1) (姓名:李倩,年龄:20,ID:5) (姓名:林锋,年龄:25,ID:6) (姓名:乔乔,年龄:17,ID:2) (姓名:王强,年龄:19,ID:3)
2.边视图
//查看所有信息
userGraph.edges.collect.foreach(println)
Edge(1,3,15) Edge(2,1,10) Edge(2,3,21) Edge(2,4,22) Edge(3,6,10) Edge(4,5,17) Edge(5,6,20)
//过滤
userGraph.edges.filter{
case Edge(src,dst,attr) =>
src > dst
}.collect.foreach(println)
Edge(2,1,10)
//索引查看
userGraph.edges.map{
v => ("源点ID:" + v.srcId,
",目的点ID:" + v.dstId,
",边属性:" + v.attr)
}.collect.foreach(println)
(源点ID:1,,目的点ID:3,,边属性:15) (源点ID:2,,目的点ID:1,,边属性:10) (源点ID:2,,目的点ID:3,,边属性:21) (源点ID:2,,目的点ID:4,,边属性:22) (源点ID:3,,目的点ID:6,,边属性:10) (源点ID:4,,目的点ID:5,,边属性:17) (源点ID:5,,目的点ID:6,,边属性:20)
3.边点三元组视图
//直接查看顶点,边信息
userGraph.triplets.collect.foreach(println)
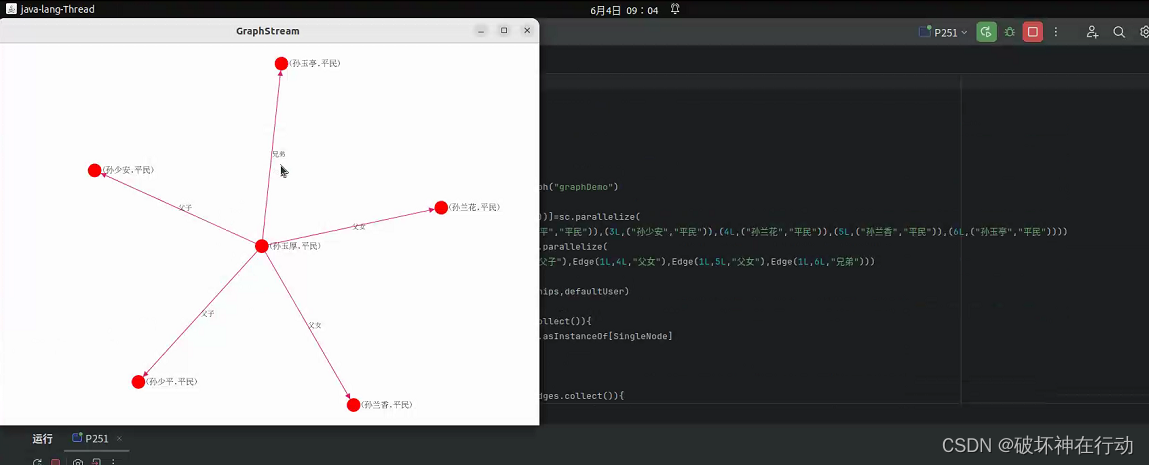
实训项目:《平凡的世界》中部分人物关系图分析
- 开发本地项目
创建Idea项目(方法见实验8)
下载第三方库GraphStream和BreezeViz,解压GraphStream中的core和ui压缩文件中所有的文件,包括其中所有的包。
建立stylesheet.css
代码:P251
- 使用sbt项目完成(可选)
build.sbt的参考内容如下:
name := "P251"
version := "0.1"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.5"
libraryDependencies += "org.apache.spark" %% "spark-graphx" % "2.4.5"
// Graph Visualization
// https://mvnrepository.com/artifact/org.graphstream/gs-core
libraryDependencies += "org.graphstream" % "gs-core" % "1.2"
// https://mvnrepository.com/artifact/org.graphstream/gs-ui
libraryDependencies += "org.graphstream" % "gs-ui" % "1.2"
// https://mvnrepository.com/artifact/org.scalanlp/breeze_2.10
libraryDependencies += "org.scalanlp" % "breeze_2.11" % "0.12"
// https://mvnrepository.com/artifact/org.scalanlp/breeze-viz_2.11
libraryDependencies += "org.scalanlp" % "breeze-viz_2.11" % "0.12"
// https://mvnrepository.com/artifact/org.jfree/jcommon
libraryDependencies += "org.jfree" % "jcommon" % "1.0.24"
// https://mvnrepository.com/artifact/org.jfree/jfreechart
libraryDependencies += "org.jfree" % "jfreechart" % "1.0.19"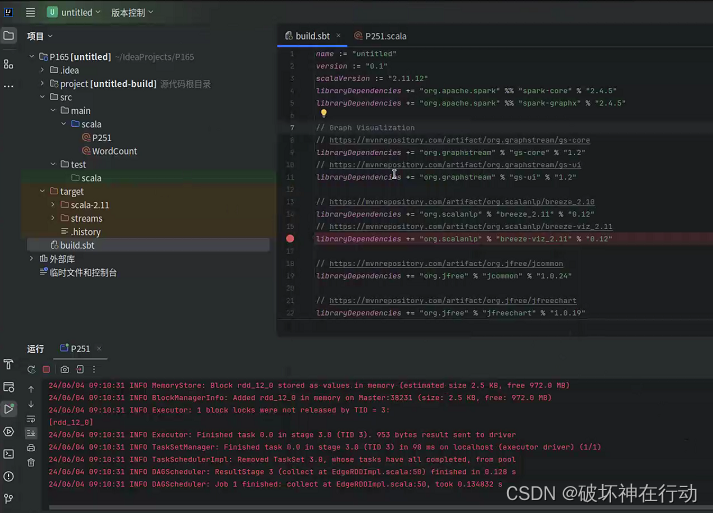
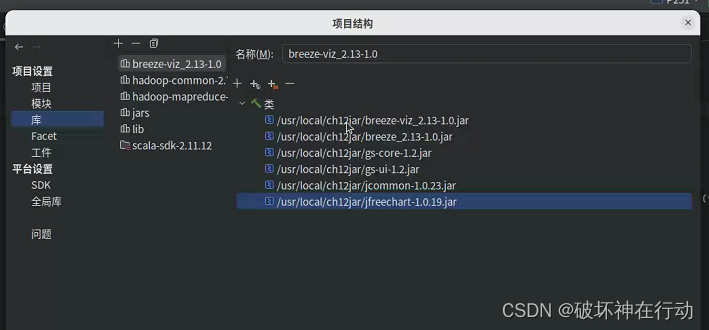
ps:注意引用库(模块设置)
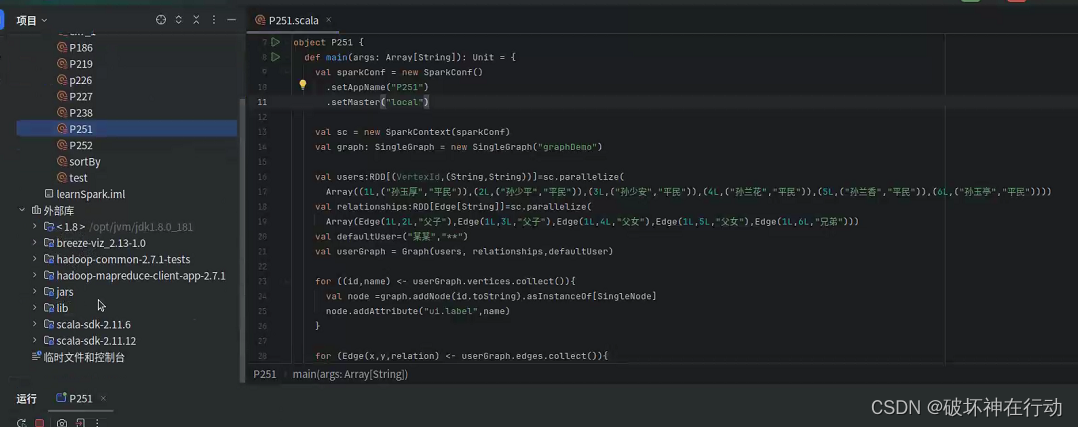
代码内容:
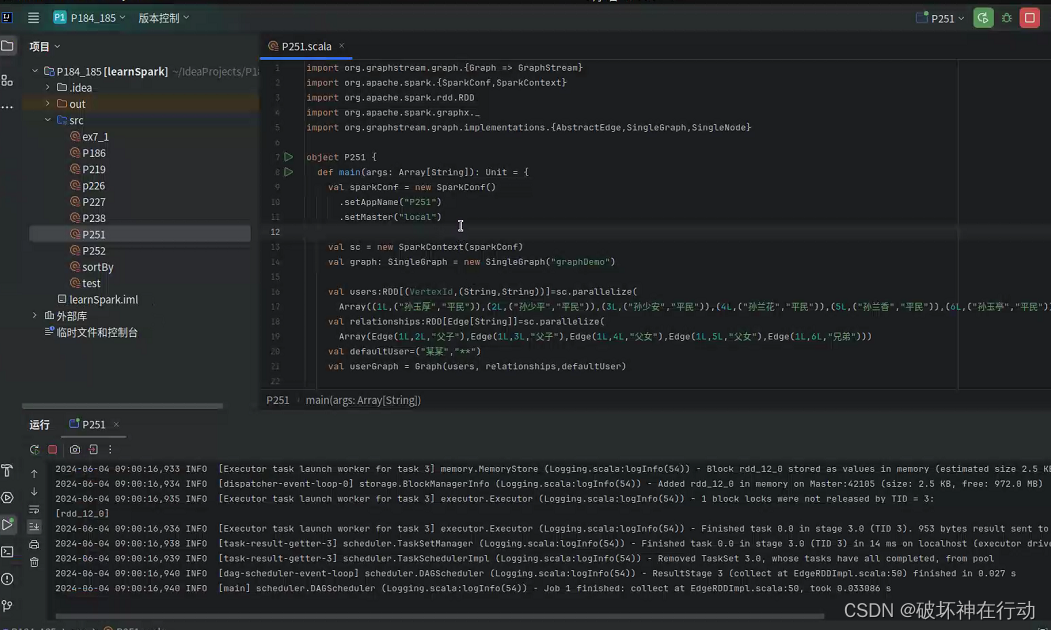
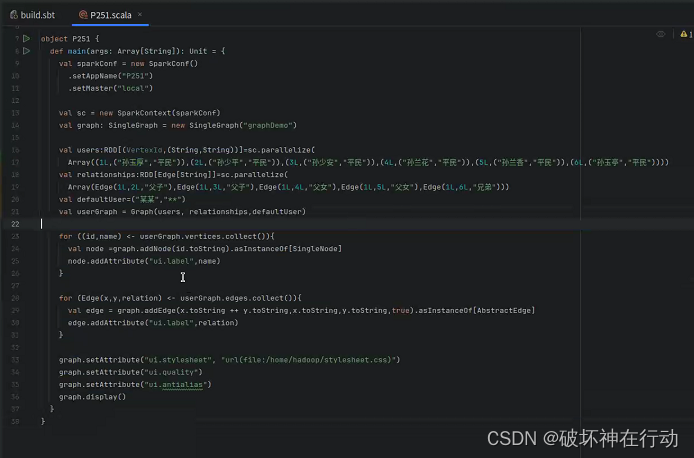
运行结果: