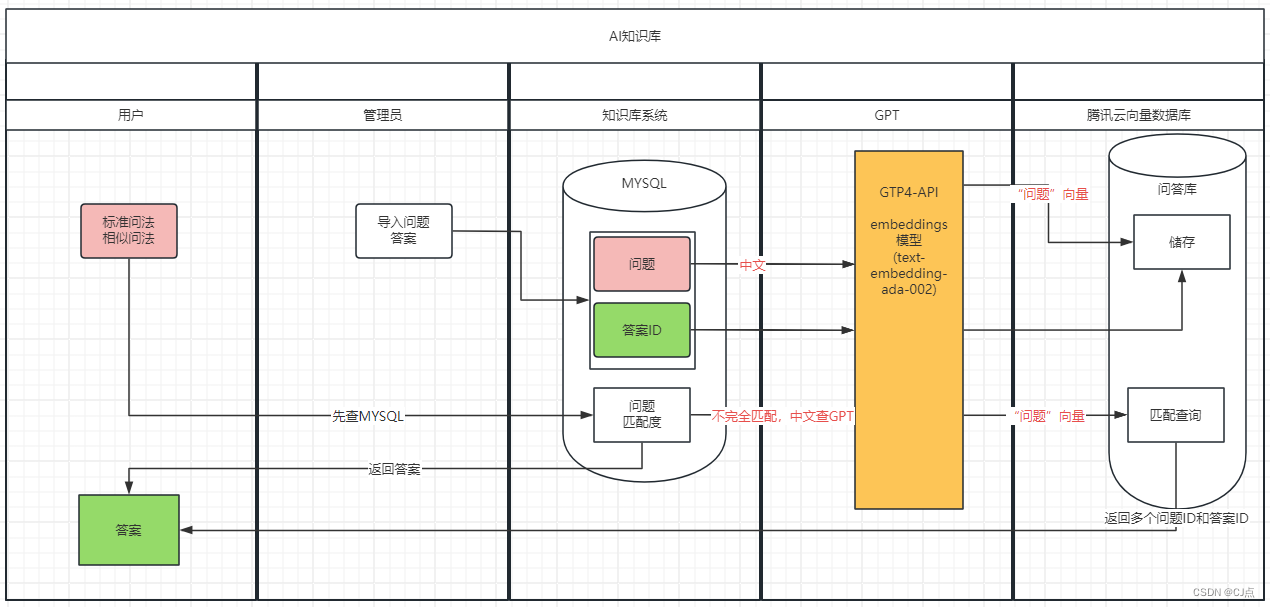
Tip: 如果你在进行深度学习、自动驾驶、模型推理、微调或AI绘画出图等任务,并且需要GPU资源,可以考虑使用UCloud云计算旗下的Compshare的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡2.6元,月卡只需要1.7元每小时,并附带200G的免费磁盘空间。通过链接注册并联系客服,可以获得20元代金券(相当于6-7H的免费GPU资源)。欢迎大家体验一下~
0. 简介
本文介绍了一种基于高斯喷洒的密集视觉同时定位与地图构建(VSLAM)新框架。最近基于高斯喷洒的SLAM取得了有希望的结果,但依赖于RGB-D输入且在跟踪方面较弱。为了解决这些局限性,《MGS-SLAM: Monocular Sparse Tracking and Gaussian Mapping with Depth Smooth Regularization》首次独特地将先进的稀疏视觉里程计与密集高斯喷洒场景表示相结合,从而消除了基于高斯喷洒的SLAM系统对深度图的依赖并增强了跟踪的鲁棒性。在这里,稀疏视觉里程计在RGB流中跟踪相机姿态,而高斯喷洒负责地图重建。这些组件通过多视图立体(MVS)深度估计网络相互连接。我们提出了一种深度平滑损失,以减少估计深度图的负面影响。此外,稀疏视觉里程计和密集高斯地图之间的尺度一致性通过稀疏-密集调整环(SDAR)得以保持。相关代码已经在Github开源了
1. 主要贡献
所提出系统的关键贡献总结如下:
- 首次引入结合稀疏视觉里程计和三维高斯喷洒的SLAM系统,实现仅使用RGB图像作为输入构建密集高斯地图。
- 开发了一种预训练的多视图立体(MVS)深度估计网络,该网络利用稀疏里程计关键帧及其姿态来估计先验深度图,从而为高斯地图重建提供关键的几何约束。
- 提出了一种几何深度平滑损失方法,以最小化估计的先验深度图不准确性对高斯地图的不利影响,并指导其对准到正确的几何位置。
- 提出了一种稀疏-密集调整环(SDAR)策略,以统一稀疏视觉里程计和密集高斯地图的尺度一致性。
2. 方法
我们的方法使用RGB图像作为输入,并行执行相机姿态估计和逼真的密集地图构建。正如图2所示,该方法的核心思想是使用预训练的多视图立体(MVS)网络将单目稀疏视觉里程计与密集高斯喷洒地图相结合,并通过稀疏-密集调整环(SDAR)保持稀疏点云地图与密集高斯地图之间的尺度一致性。

图2. 系统流程。系统以RGB视频流作为输入,并行运行前端和后端处理。在前端,稀疏视觉里程计从图像中提取特征块以估计姿态。这些估计的姿态和图像作为输入被传递到预训练的多视图立体(MVS)网络,该网络估计先验深度图。在后端,估计的先验深度图和图像结合前端提供的姿态被用作监督信息来构建高斯地图。前端和后端通过稀疏-密集调整环(SDAR)策略保持尺度一致性。
具体来说,在前端部分,通过跟踪RGB图像为后端提供粗略的相机姿态和先验深度图(参见III-A节)。在后端部分,使用高斯表示密集地图,并联合优化地图和前端提供的粗略姿态(参见III-B节)。在系统组件部分,报告系统初始化、系统关键帧选择以及通过SDAR策略校正稀疏点云地图与密集高斯地图之间的尺度(参见III-C节)。
3. 稀疏视觉里程计前端
为了实现更精确的相机姿态跟踪并在后端映射之前提供密集深度几何信息,我们的框架前端基于深度特征块视觉里程计(Deep Patch Visual Odometry, DPVO)算法【25】构建。DPVO是一种基于学习的稀疏单目视觉里程计方法,通过在特征块图上构建和优化误差来估计相机姿态并构建稀疏点云地图。
给定输入的RGB视频流,场景表示为一组相机姿态 T ∈ S E ( 3 ) N T \in SE(3)^N T∈SE(3)N 和一系列从图像中提取的方形图像特征块 P P P,并将它们添加到双向特征块图中,该图将特征块与帧连接起来。方形特征块 k k k 从帧 i i i 在帧 j j j 中的重投影可以表示为:
p j = K T i j p i \mathbf{p}_j = \mathbf{K} \mathbf{T}_{ij} \mathbf{p}_i pj=KTijpi
其中, K \mathbf{K} K 是相机内参矩阵, T i j \mathbf{T}_{ij} Tij 是从帧 i i i 到帧 j j j 的变换矩阵, p i \mathbf{p}_i pi 和 p j \mathbf{p}_j pj 分别是特征块在帧 i i i 和帧 j j j 中的坐标。
通过这种方式,DPVO 在特征块图上优化重投影误差,从而精确估计相机的姿态,并为后端的密集映射提供稀疏的几何深度信息。
P k i j ∼ K T j T i − 1 K − 1 P k i \begin{equation} \mathbf{P}_k^{ij} \sim \mathbf{K} \mathbf{T}_j \mathbf{T}_i^{-1} \mathbf{K}^{-1} \mathbf{P}_k^i \end{equation} Pkij∼KTjTi−1K−1Pki
其中, K \mathbf{K} K 是相机内参矩阵, P k i = [ u , v , 1 , d ] T \mathbf{P}^i_k = [u, v, 1, d]^T Pki=[u,v,1,d]T 表示帧 i i i 中的特征块 k k k,[u, v] 表示图像中的像素坐标,(d) 表示逆深度。
DPVO 的核心是一个更新算子,用于计算每条边 ( k , i , j ) ∈ ϵ (k, i, j) \in \epsilon (k,i,j)∈ϵ 的隐藏状态。它通过优化特征块图上的重投影误差来预测一个二维校正向量 δ i j k ∈ R 2 \delta_{ij}^k \in \mathbb{R}^2 δijk∈R2 和置信权重 ψ i j k ∈ R 2 \psi_{ij}^k \in \mathbb{R}^2 ψijk∈R2。通过光流校正作为约束执行捆绑调整(Bundle Adjustment,BA),使用非线性最小二乘法进行迭代更新和相机姿态以及特征块深度的细化。捆绑调整的代价函数如下:
∑ ( k , i , j ) ∈ ϵ ∥ K T j T i − 1 K − 1 P k i − [ P ˉ k i j + δ k i j ] ∥ ψ k i j 2 \begin{equation} \sum_{(k,i,j) \in \epsilon} \left\| \mathbf{K} \mathbf{T}_j \mathbf{T}_i^{-1} \mathbf{K}^{-1} \mathbf{P}_k^i - \left[ \mathbf{\bar{P}}_k^{ij} + \delta_k^{ij} \right] \right\|^2_{\psi_k^{ij}} \end{equation} (k,i,j)∈ϵ∑ KTjTi−1K−1Pki−[Pˉkij+δkij] ψkij2
其中, ∥ ⋅ ∥ ψ \| \cdot \|_{\psi} ∥⋅∥ψ 表示马氏距离, P ˉ \mathbf{\bar{P}} Pˉ 表示特征块的中心。
3.1 多视图先验深度估计
后端的密集高斯映射需要几何深度图的监督。不同于之前的方法【26】,我们使用预训练的多视图立体(MVS)网络在DPVO的关键帧窗口上估计先验深度图,如图3所示。受单目深度估计方法【27】的启发,我们的MVS网络完全由二维卷积组成,采用由粗到细的结构逐步细化估计的先验深度图,以减少MVS网络的运行时间。
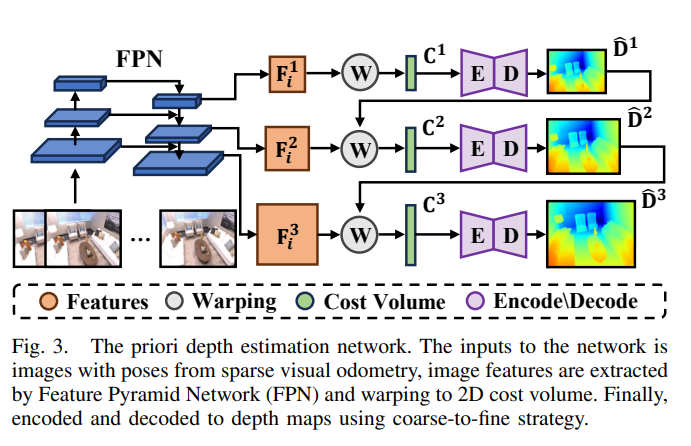
图3. 先验深度估计网络。网络的输入是来自稀疏视觉里程计的图像及其相机姿态。通过特征金字塔网络(Feature Pyramid Network, FPN)提取图像特征,并通过变形操作转换为二维代价体积。最后,采用由粗到细的策略对特征进行编码和解码,生成深度图。
具体来说,当前由稀疏视觉里程计跟踪的帧被用作参考图像 I 0 I^0 I0。此外,我们使用之前的 N N N 个关键帧作为一系列原始图像 I n ∈ 1 , … , N I^{n \in 1, \ldots, N} In∈1,…,N。这些图像及其相应的相机姿态作为MVS网络的输入。利用特征金字塔网络(FPN)模块,我们为每个图像提取三层图像特征 F i s F^s_i Fis,其中 s s s 表示层索引, i i i 表示图像索引。每一层包含的图像特征是上一层长度和宽度的两倍。在每一层中,原始图像的图像特征通过可微分的变形操作与参考图像的图像特征点对点相乘,得到维度为 D × H s × W s D \times H^s \times W^s D×Hs×Ws 的代价体积,并通过二维卷积编码和解码获得每一层的先验深度图。上一层估计的深度图被上采样作为下一层的参考深度图,以减少下一层的深度样本数量。每一层都进行类似的编码和解码操作,最终深度图在三层之后估计完成,以实现由粗到细的效果。我们的MVS深度估计网络在ScanNet数据集【28】上进行训练,采用尺度不变的损失函数以适应稀疏视觉里程计的相对姿态:
L s i s = 1 H s W s ∑ i , j ( g i , j s ) 2 − λ ( H s W s ) 2 ( ∑ i , j g i , j s ) 2 \begin{equation} \mathcal{L}^{s}_{si} = \sqrt{\frac{1}{H^s W^s} \sum_{i,j} \left(g^{s}_{i,j}\right)^2 - \frac{\lambda}{\left(H^s W^s\right)^2} \left(\sum_{i,j} g^{s}_{i,j}\right)^2} \end{equation} Lsis=HsWs1i,j∑(gi,js)2−(HsWs)2λ(i,j∑gi,js)2
其中,$g^s_{i,j} = \uparrow_{\text{gt}}(\log \hat{D}^s_{i,j} - \log D^{\text{gt}}{i,j}) 。 。 。D^{\text{gt}}{i,j}$ 表示一个真实的深度图,通过上采样操作 ↑ gt \uparrow_{\text{gt}} ↑gt 对齐到预测深度 D ^ i , j s \hat{D}^s_{i,j} D^i,js 的大小。常数 λ \lambda λ 为 0.85。
此外,损失函数中还添加了多视图损失和法线损失,以保持深度估计的几何一致性:
L m v s = 1 N H s W s ∑ n , i , j ∣ ↑ g t log T 0 n ( D ^ i , j s ) − log D n , i , j g t ∣ (4) L n o r m a l s = 1 2 H s W s ∑ i , j ( 1 − N ^ i , j s ⋅ N i , j s ) (5) \mathcal{L}_{mv}^{s}=\frac{1}{NH^{s}W^{s}}\sum_{n,i,j}\left|\uparrow_{gt}\log\mathbf{T}_{0n}(\hat{D}_{i,j}^{s})-\log D_{n,i,j}^{gt}\right|\text{(4)}\\\mathcal{L}_{normal}^{s}=\frac{1}{2H^{s}W^{s}}\sum_{i,j}(1-\hat{N}_{i,j}^{s}\cdot N_{i,j}^{s})\text{(5)} Lmvs=NHsWs1n,i,j∑ ↑gtlogT0n(D^i,js)−logDn,i,jgt (4)Lnormals=2HsWs1i,j∑(1−N^i,js⋅Ni,js)(5)
其中, T 0 n T_{0n} T0n 表示从参考图像到原始图像 n n n 的变换矩阵。 N ^ i , j s \hat{N}^s_{i,j} N^i,js 和 N i , j s N^s_{i,j} Ni,js 分别表示预测的法向量和真实的法向量。最终的多视图立体(MVS)深度估计网络损失函数如下:
L = ∑ s = 0 l 1 2 s ( λ s i L s i s + λ m v L m v s + λ n o r m a l L n o r m a l s ) ( 6 ) \mathcal{L}=\sum_{s=0}^l\frac1{2^s}(\lambda_{si}\mathcal{L}_{si}^s+\lambda_{mv}\mathcal{L}_{mv}^s+\lambda_{normal}\mathcal{L}_{normal}^s)\quad(6) L=s=0∑l2s1(λsiLsis+λmvLmvs+λnormalLnormals)(6)
其中 l l l 为2,我们将损失权重 λ s i \lambda_{si} λsi、 λ m v \lambda_{mv} λmv 和 λ n o r m a l \lambda_{normal} λnormal 分别设置为1.0、0.2和1.0。
4. 三维高斯喷洒映射后端(核心)
后端的主要职责是进一步优化前端提供的粗略姿态并映射高斯场景。这个部分的关键在于可微渲染和深度平滑正则化损失,通过计算渲染结果与真实值之间的损失,并通过反向梯度传播调整粗略姿态和高斯地图。
4.1 可微高斯地图表示
我们使用三维高斯喷洒作为场景的密集表示。三维高斯喷洒是一种高效的三维空间表示方法,它以类似点云的方式映射场景,避免了像NeRF那样在空间的空白区域进行采样,并且能够实时渲染。单个三维高斯 p i ∈ R 3 p_i \in \mathbb{R}^3 pi∈R3 在三维场景中的影响如下:
f ( p i ) = σ ( o i ) ⋅ exp ( − 1 2 ( p i − μ i ) T Σ − 1 ( p i − μ i ) ) ( 7 ) f(p_i)=\sigma(o_i)\cdot\exp(-\frac{1}{2}(p_i-\mu_i)^T\Sigma^{-1}(p_i-\mu_i))\quad(7) f(pi)=σ(oi)⋅exp(−21(pi−μi)TΣ−1(pi−μi))(7)
其中, o i ∈ R o_i \in \mathbb{R} oi∈R 表示高斯分布的透明度, μ i ∈ R 3 \mu_i \in \mathbb{R}^3 μi∈R3 是高斯分布的中心, Σ = R S S T T T ∈ R 3 , 3 \Sigma = RSS^TT^T \in \mathbb{R}^{3,3} Σ=RSSTTT∈R3,3 是协方差矩阵,由 S ∈ R 3 S \in \mathbb{R}^3 S∈R3 缩放分量和 R ∈ R 3 , 3 R \in \mathbb{R}^{3,3} R∈R3,3 旋转分量计算得出。三维高斯分布投影到图像平面的表达式如下:
μ I = π ( T C W ⋅ μ W ) Σ I = J W Σ W W T J T \begin{align} \mu_I &= \pi (\mathbf{T}_{CW} \cdot \mu_W) \tag{8} \\ \Sigma_I &= J W \Sigma_W W^T J^T \tag{9} \end{align} μIΣI=π(TCW⋅μW)=JWΣWWTJT(8)(9)
其中, π ( ⋅ ) \pi(\cdot) π(⋅) 表示三维高斯中心的投影, T C W ∈ S E ( 3 ) T_{CW} \in SE(3) TCW∈SE(3) 是从世界坐标到相机坐标的三维空间变换矩阵, J J J 是投影变换的雅可比矩阵的线性近似, W W W 是 T C W T_{CW} TCW 的旋转分量。方程 (8) 和 (9) 是可微分的,这确保了高斯地图可以使用一阶梯度下降来连续优化地图的几何和光度,使地图能够渲染为逼真的图像。一个像素颜色 C p C_p Cp 是通过喷洒和混合来自 N N N 个高斯的结果:
C p = ∑ i ∈ N c i o i ∏ j = 1 i − 1 ( 1 − o j ) \begin{equation} C_p = \sum_{i \in N} c_i o_i \prod_{j=1}^{i-1} (1 - o_j) \tag{10} \end{equation} Cp=i∈N∑cioij=1∏i−1(1−oj)(10)
其中, c i c_i ci 是高斯 i i i 的颜色, o i o_i oi 是高斯 i i i 的透明度。
4.2 映射优化损失
我们修改了原始三维高斯喷洒的损失函数,并添加了更多几何约束,使其更适合像 SLAM 这样的在线映射系统。具体来说,我们的损失函数由四个部分组成:光度损失、深度几何损失、深度平滑正则化损失和各向同性损失。
在光度损失中,计算当前相机姿态 T C W T_{CW} TCW 下渲染的彩色图像与真实彩色图像之间的 L1 损失:
L p h o = ∥ I ( G , T C W ) − I g t ∥ 1 \begin{equation} \mathcal{L}_{pho} = \left\| I(\mathcal{G}, \mathbf{T}_{CW}) - I^{gt} \right\|_1 \tag{11} \end{equation} Lpho= I(G,TCW)−Igt 1(11)
其中, I ( G , T C W ) I(\mathcal{G}, T_{CW}) I(G,TCW)是从高斯分布 G \mathcal{G} G 渲染的彩色图像, I g t I_{gt} Igt 是真实的彩色图像。
D p = ∑ i ∈ N z i o i ∏ j = 1 i − 1 ( 1 − o j ) \begin{equation} D_p = \sum_{i \in N} z_i o_i \prod_{j=1}^{i-1} (1 - o_j) \tag{12} \end{equation} Dp=i∈N∑zioij=1∏i−1(1−oj)(12)
为了提高高斯地图的几何精度,我们同样渲染了深度图,类似于方程 (10):
L g e o = ∥ D ( G , T C W ) − D ˉ d ∥ 1 \begin{equation} \mathcal{L}_{geo} = \left\| D(\mathcal{G}, \mathbf{T}_{CW}) - \bar{D}_d \right\|_1 \tag{13} \end{equation} Lgeo= D(G,TCW)−Dˉd 1(13)
其中, D ( G , T C W ) D(G, T_{CW}) D(G,TCW) 是从高斯分布 G \mathcal{G} G 渲染的深度图, D ‾ d \overline{D}_d Dd 是通过 SDAR 策略优化的先验深度图。优化过程见第 III-C 节。
从 MVS 网络获得的先验深度图可能并不完全准确。如图 4 所示,直接使用这些深度图会在高斯地图的几何重建中导致错误的引导。因此,我们引入了深度平滑正则化损失:
L s m o o t h = ∥ d i , j − 1 − d i , j ∥ 2 + ∥ d i + 1 , j − d i , j ∥ 2 \begin{equation} \mathcal{L}_{smooth} = \left\| d_{i,j-1} - d_{i,j} \right\|_2 + \left\| d_{i+1,j} - d_{i,j} \right\|_2 \tag{14} \end{equation} Lsmooth=∥di,j−1−di,j∥2+∥di+1,j−di,j∥2(14)
其中, d i , j d_{i,j} di,j 表示渲染深度图中像素坐标 ( i , j ) (i, j) (i,j) 的深度值。通过对渲染深度图中相邻像素进行正则化,它减少了先验深度图误差的影响。





![[ue5]建模场景学习笔记(5)——必修内容可交互的地形,交互沙(2)](https://img-blog.csdnimg.cn/direct/fb477df0bdae48f48100a38f630431b9.png)