第九章 链表
目录
第九章 链表
●前言
●一、链表是什么?
1.简要介绍
2.具体情况
●二、链表操作的关键代码段
1.类型定义
2.常用操作
●总结
前言
简单来说,数据结构是一种辅助程序设计并且进行优化的方法论,它不仅讨论数据的存储与处理的方法,同时也考虑到了数据彼此之间的关系与运算,从而极大程度的提高程序执行的效率,减少对内存空间的占用等。不同种类的数据结构适用于不同的程序应用,选择合适正确的数据结构,可以让算法发挥出更大的性能,给设计的程序带来更高效率的算法。
一、链表是什么?
1.简要介绍
链表也被称为动态数据结构,它使用不连续的内存空间来存储数据元素,由许多相同数据类型的数据项按特定顺序排列而成的线性表。链表中的各个数据在计算机的内存中是不连续且随机存放的,所以对它进行插入和删除操作不需要移动大量的数据,因此是相当方便的。如果要有新的元素加入链表,那么就需要向系统去申请内存空间。如果数据被删除后,就把这块内存空间释放还给系统。但是在代码中对其数据结构进行设计时较为麻烦,以及查询数据元素时不能像静态数据结构那样按索引值去直接进行访问,而是需要从前到后依次遍历查找,直到找到该数据元素为止。
2.具体情况
在日常生活中,链表有许多抽象概念的运用。例如以前的火车,当乘坐的人多时就添加一些车厢;而当人少时就减少一些车厢;这就很像一个典型的单向链表的抽象运用。生活中还有很多链表这类抽象概念的运用。

在动态分配内存空间的时候,单向链表是我们经常使用到的。每个单向链表由多个结点组成的,每个结点又是由数据域和指针域组成的。数据域中存储数据,指针域中放着指向下一个元素在内存中的地址。在单向链表中第一个结点是链表的头结点,并且头指针指向头结点。最后一个结点是该链表的尾结点。具体情况如下图所示:
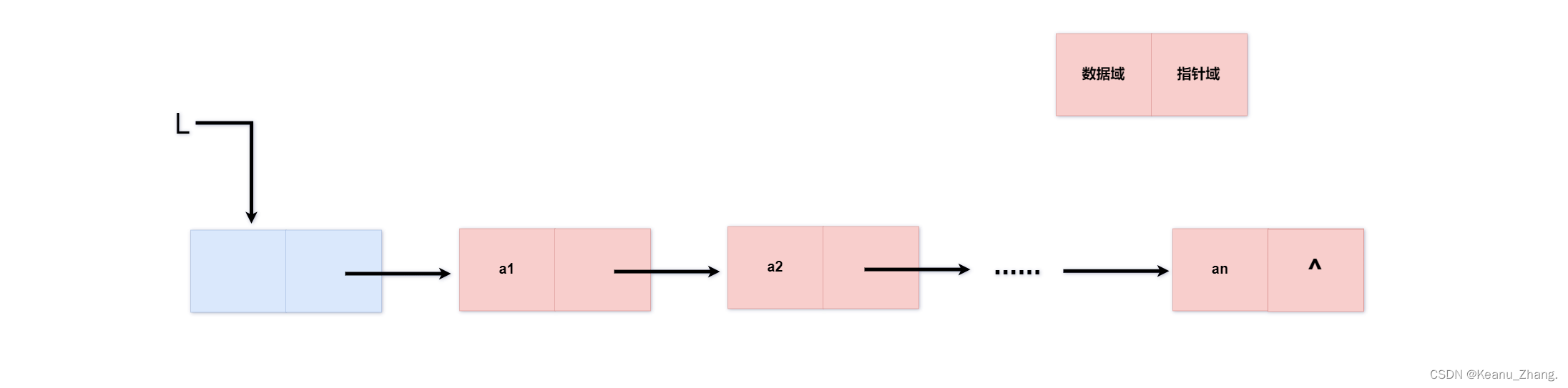
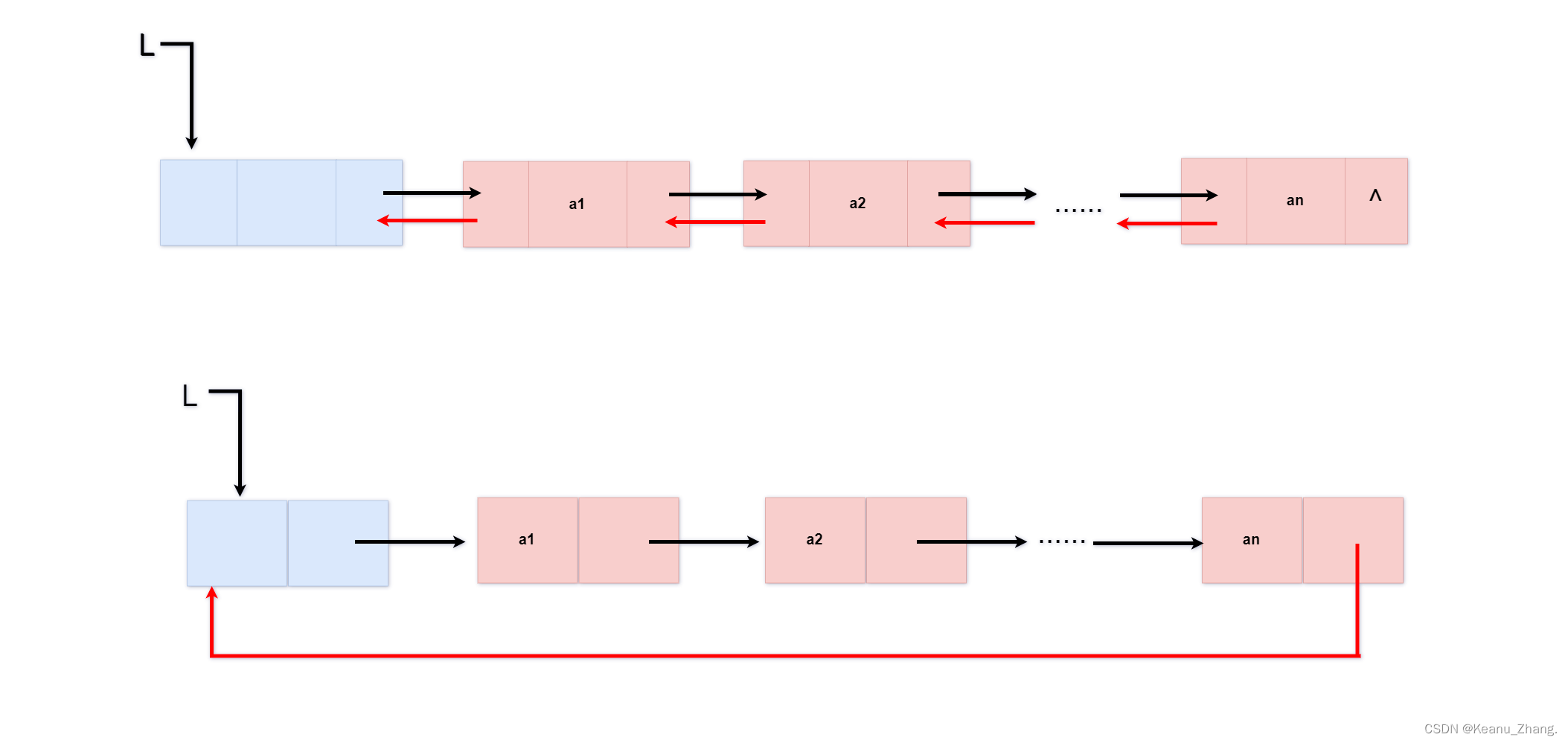
因为在单链表中,所有结点都知道自己下一个结点在哪个位置。但前一个的结点信息确无法得知,所以头指针L在链表的各项操作中就显得非常重要。只要链表中头指针存在就可以访问遍历整个链表的具体情况,并且进行一系列相关的操作。单链表是我们在数据结构中比较常用的,用它就可以去解决绝大部分的链表类程序设计的题型。但是链表中除了单链表,还有双向链表和循环链表这两类相对于单向链表是不常用的两种链表数据结构。具体如下图所示:
二、链表操作的关键代码段
1.类型定义
①单链表存储结构的定义(重点)
typedef struct lnode{
elemtype data; //数据域
struct lnode *next; //指针域
}lnode,*linklist;
//lnode *p 结点指针定义
//linklist &L 单链表L定义②双向链表存储结构的定义
typedef struct lnode {
elemtype data; 数据域
struct lnode* prior, * next; 前后指针域
}lnode,*linklist;
//lnode *p 结点指针定义
//linklist &L 单链表L定义③循环链表存储结构的定义
(将单链表的头尾用指针进行相连)
typedef struct lnode {
elemtype data;
struct lnode* next;
}lnode,*linklist;
linklist connect(linklist ta,linklist tb) //ta为头 tb为尾
{
lnode* p;
p = ta->next; //将头结点的指针域保存
ta->next=tb->next->next; //将尾结点指针域的下一个区域连接到头结点的指针域
delete tb->next; //将尾结点的指针域删除,因为他将连接到头结点那里
tb->next = p; //将头结点的指针再次绑定到已经循环回来的tb上
return tb;
}2.常用操作
①链表初始化
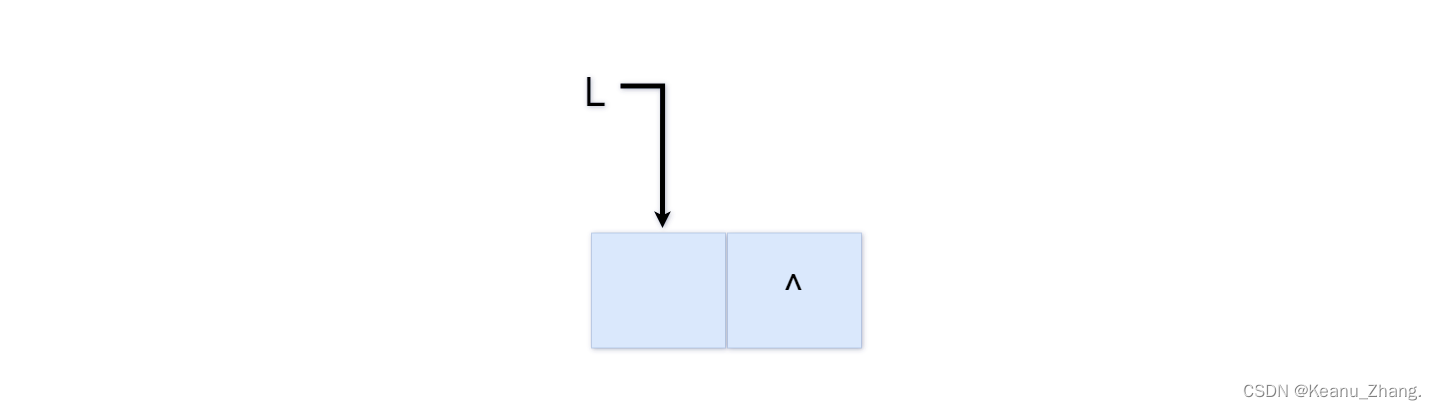
void initlist(linklist& L)
{
L = new lnode; //创建一块新的结点区域
L->next = NULL; //将这个结点区域的指针域赋为空
}②判断链表是否为空
bool listempty(linklist& L)
{
//常规判断
if (L->next)
return true;
else
return false;
}③ 链表的清空
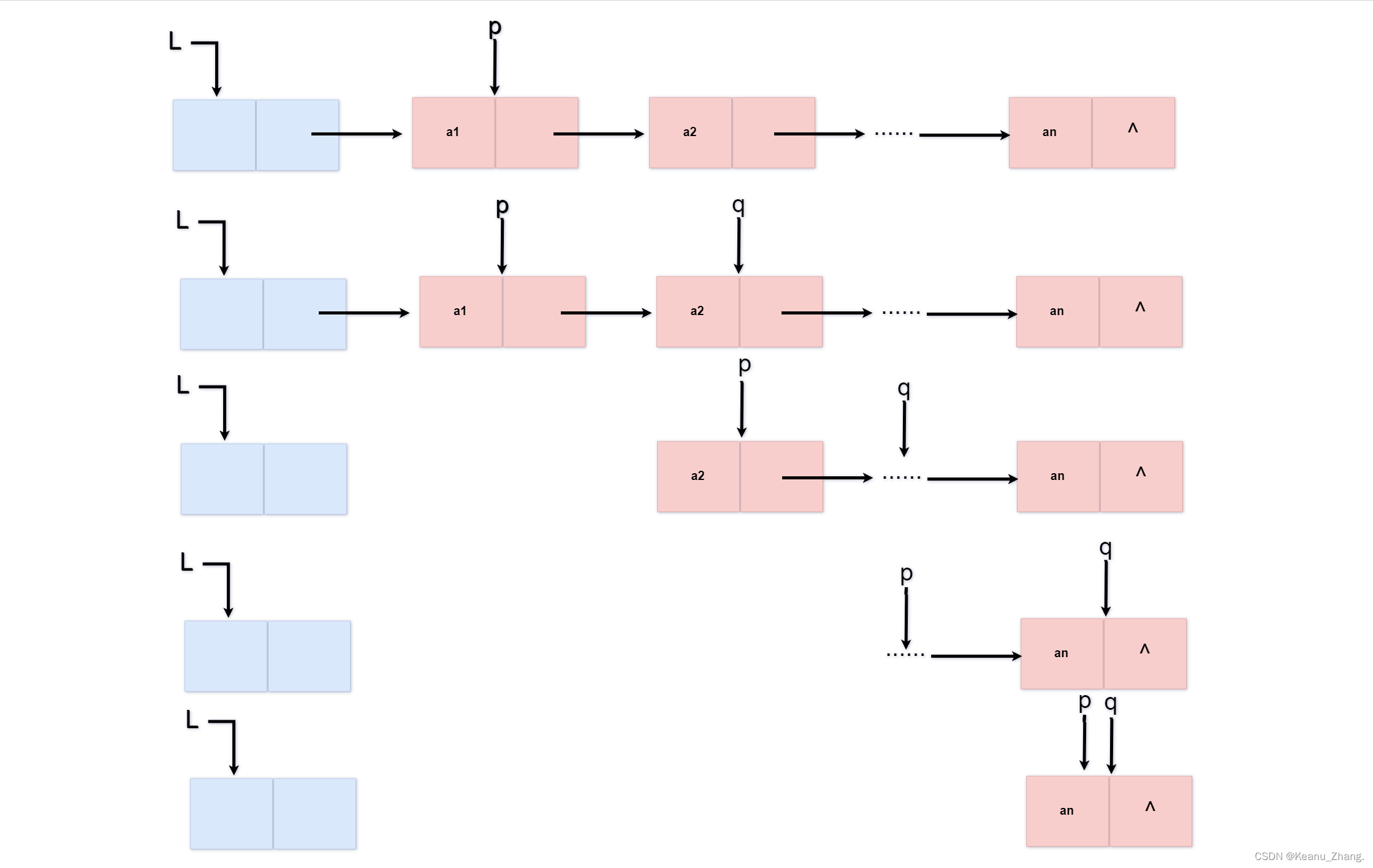

void clearlist(linklist& L)
{
lnode* p;
lnode* q; //定义两个结点指针
p=L->next; //将链表头结点的指针域指向的下个结点赋给指针p
while (p) //如果指针p存在,则开始循环判断
{
q = p->next; //循环中事先将p的再下一个指针域指向的元素赋给指针q
delete p; //删除此时的指针p,此时p将无内容
p = q; //再将q中的内容赋给p,进行继续的循环判断即可
}
L->next = NULL; //将链表修改成了初始化下的状态
}④链表的销毁
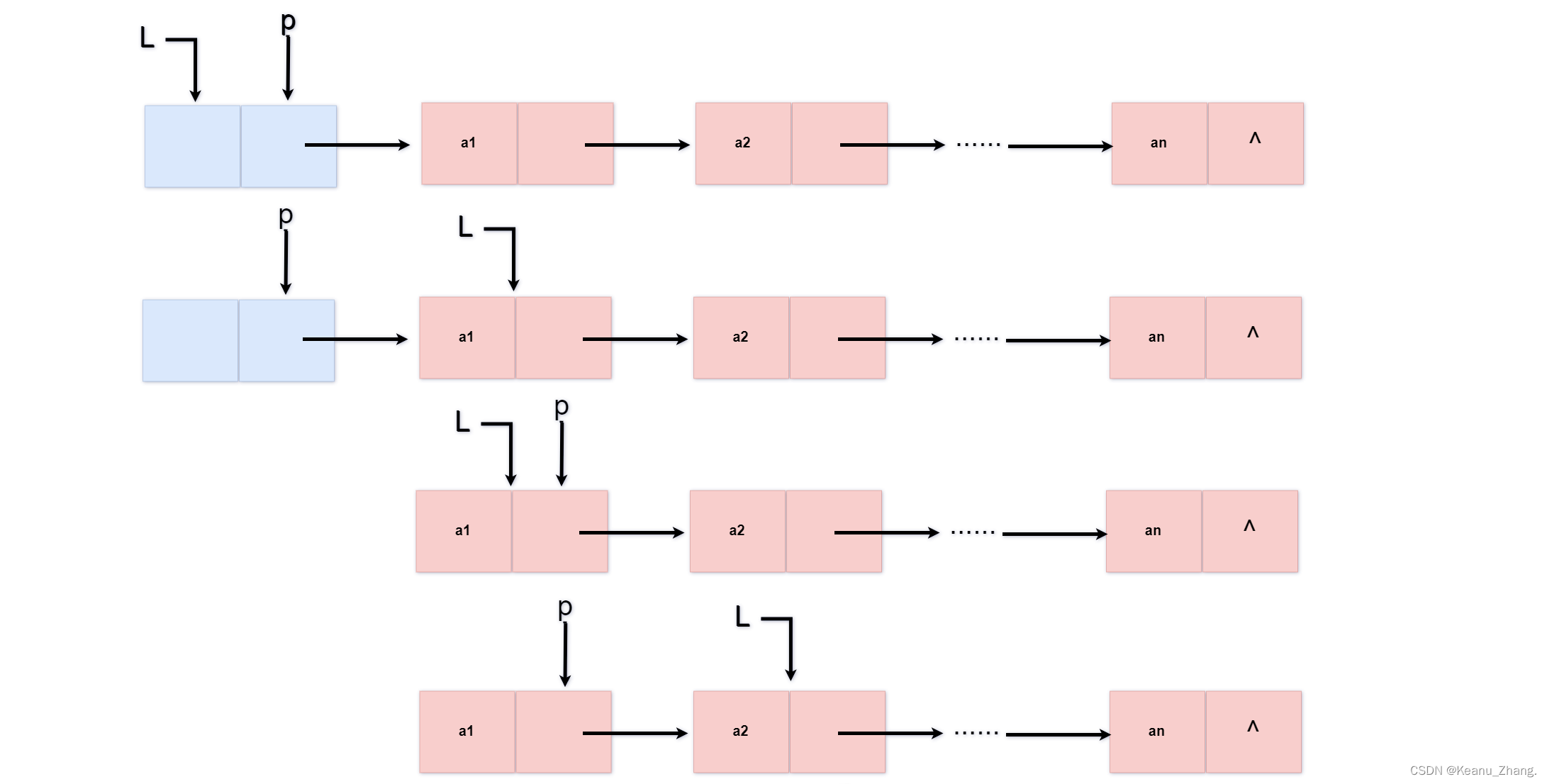
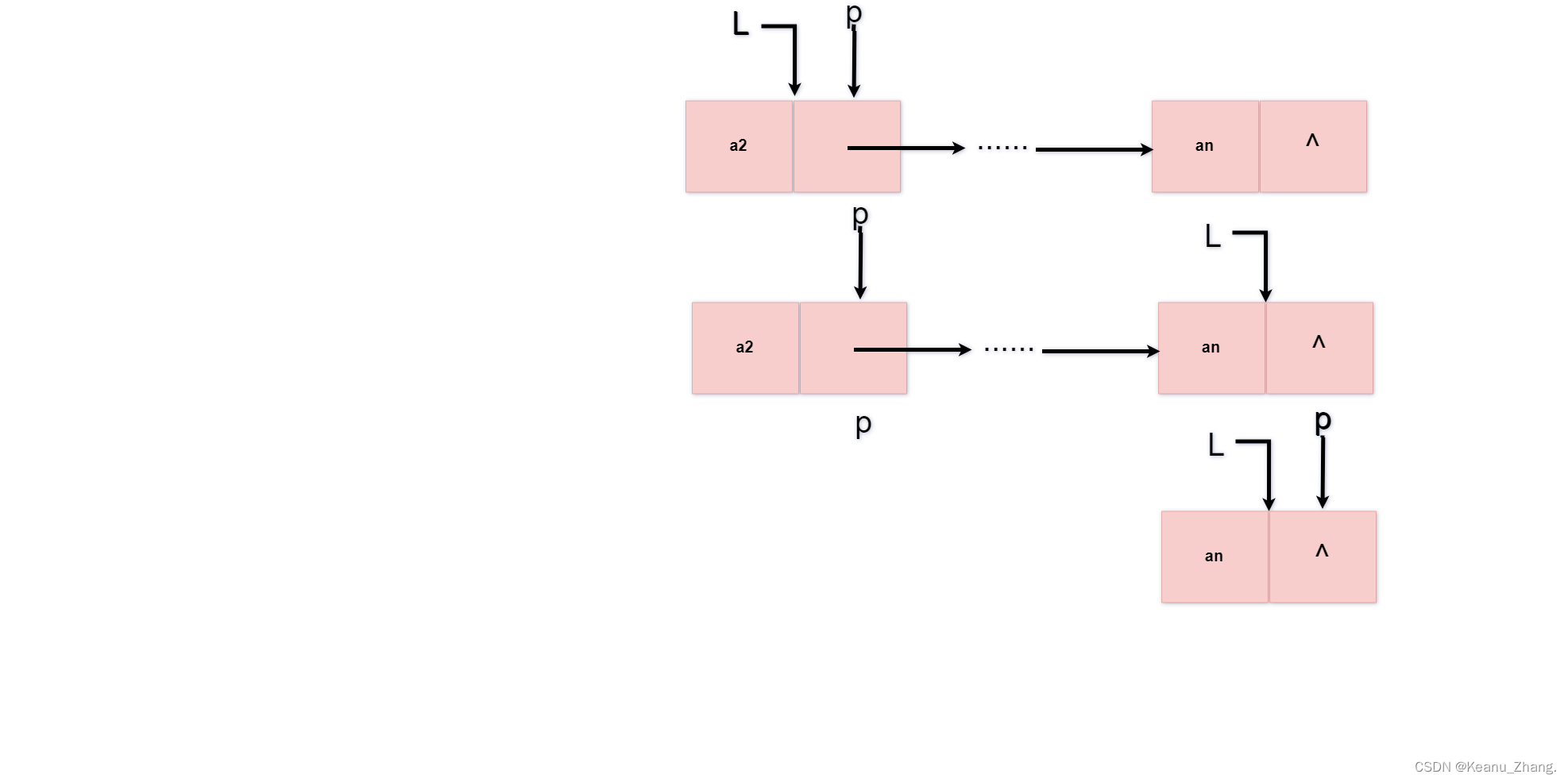
void destorylist(linklist& L)
{
lnode* p;
L=L->next;
while (L != NULL) //循环判断,直到链表的结点被删除为空为止
{
p = L;
L = L->next;
delete p; //删除结点
}
}⑤ 链表的表长

int lengthlist(linklist& L)
{
lnode* p;
p=L->next;
int i = 0; //将用来展示链表的长度
while (p) //如果结点存在,从前到后遍历循环判断
{
i++; //进行计数
p = p->next; //指针继续向后指向链表后面的指针域,用于循环的下一次判断
}
return 1;
}⑥取链表中的第i个数据域的内容
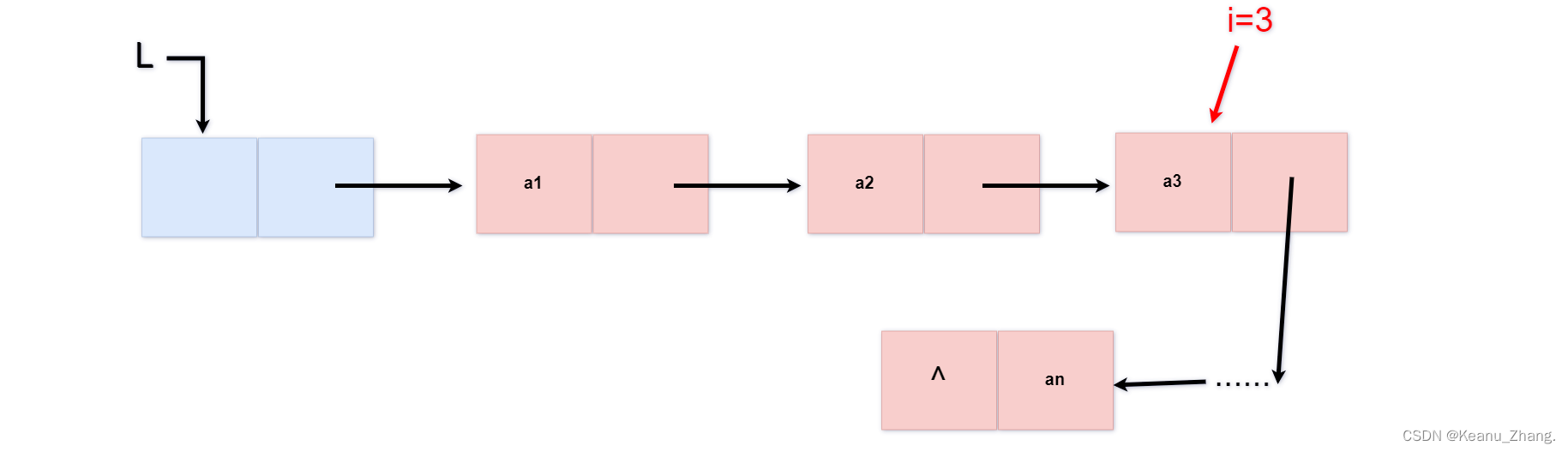
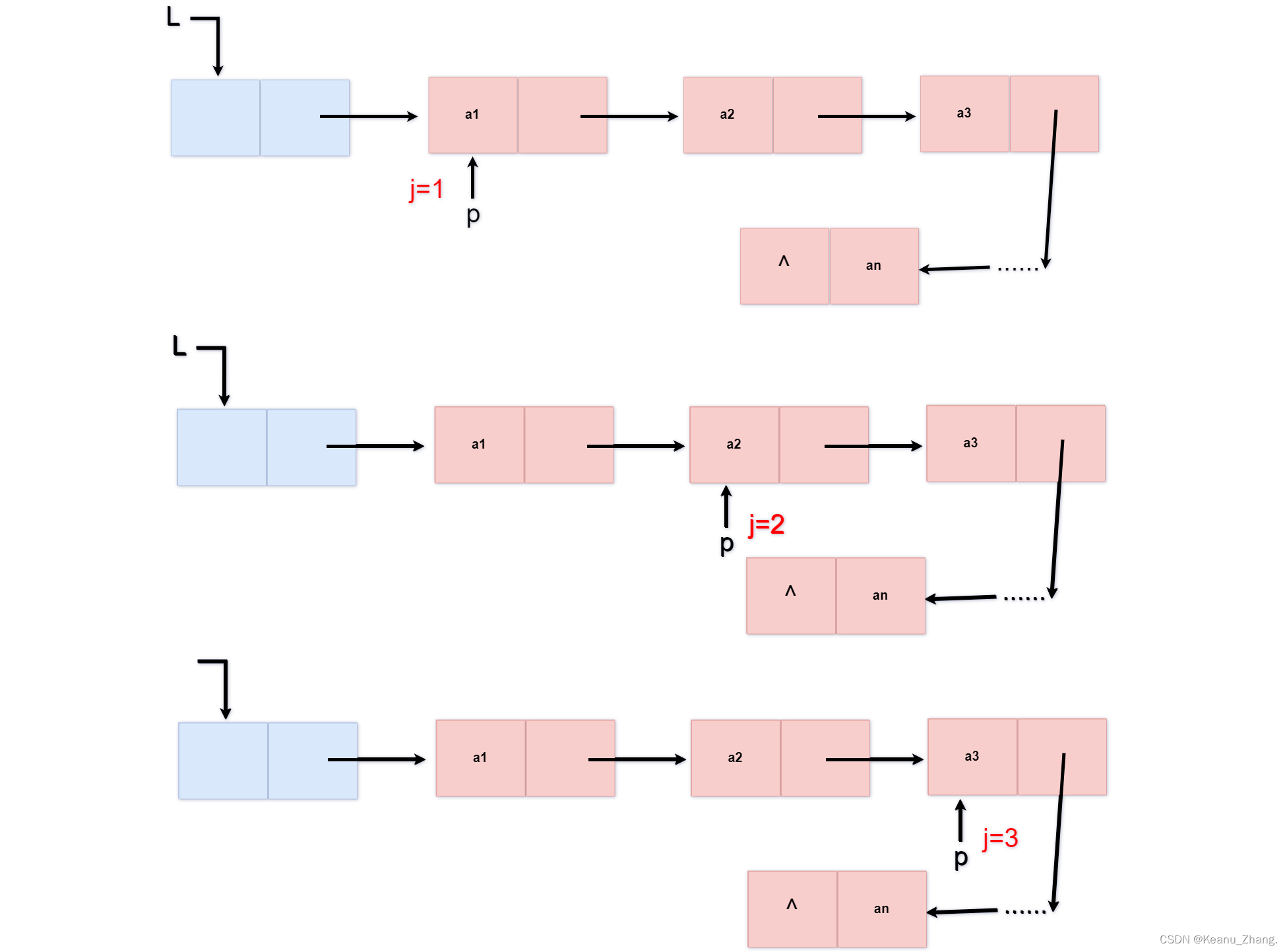
int getelem(linklist& L,int i,elemtype e)
{
lnode* p;
p = L->next;
int j = 1;
//要取第i个元素的内容,首先进行循环判断,让指针p从前向后移动,移动i次
while (p && j < i) //两个条件:p存在,计数的j小于i
{
p = p->next;
j++;
}
//进行一个判断,判断循环完的p是否存在,j是否满足条件
if (!p || j > i) {
return 0;
}
else {
e = p->data;
return 1;
}
}⑦在第i个结点前插入值为e的新结点
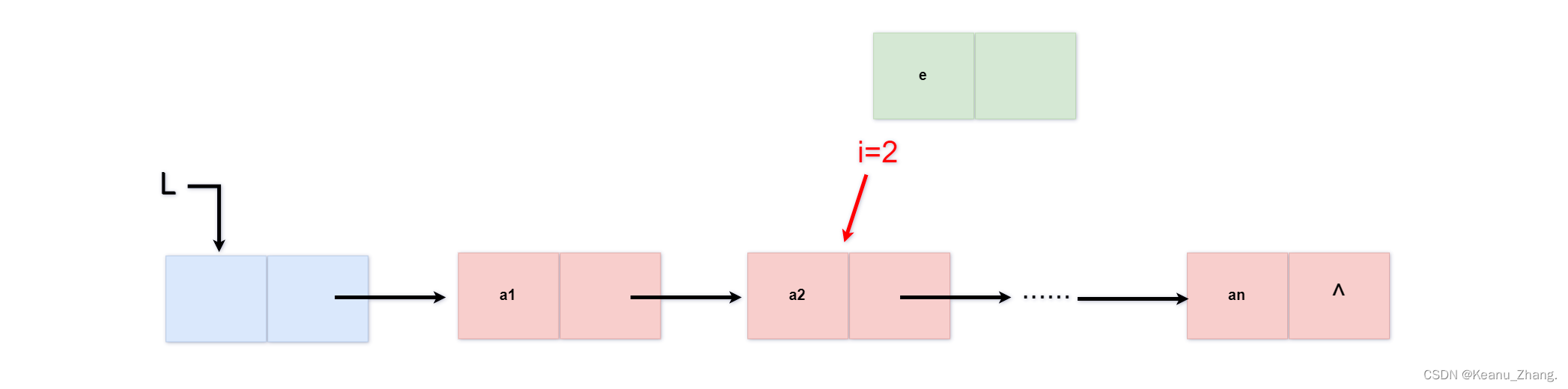
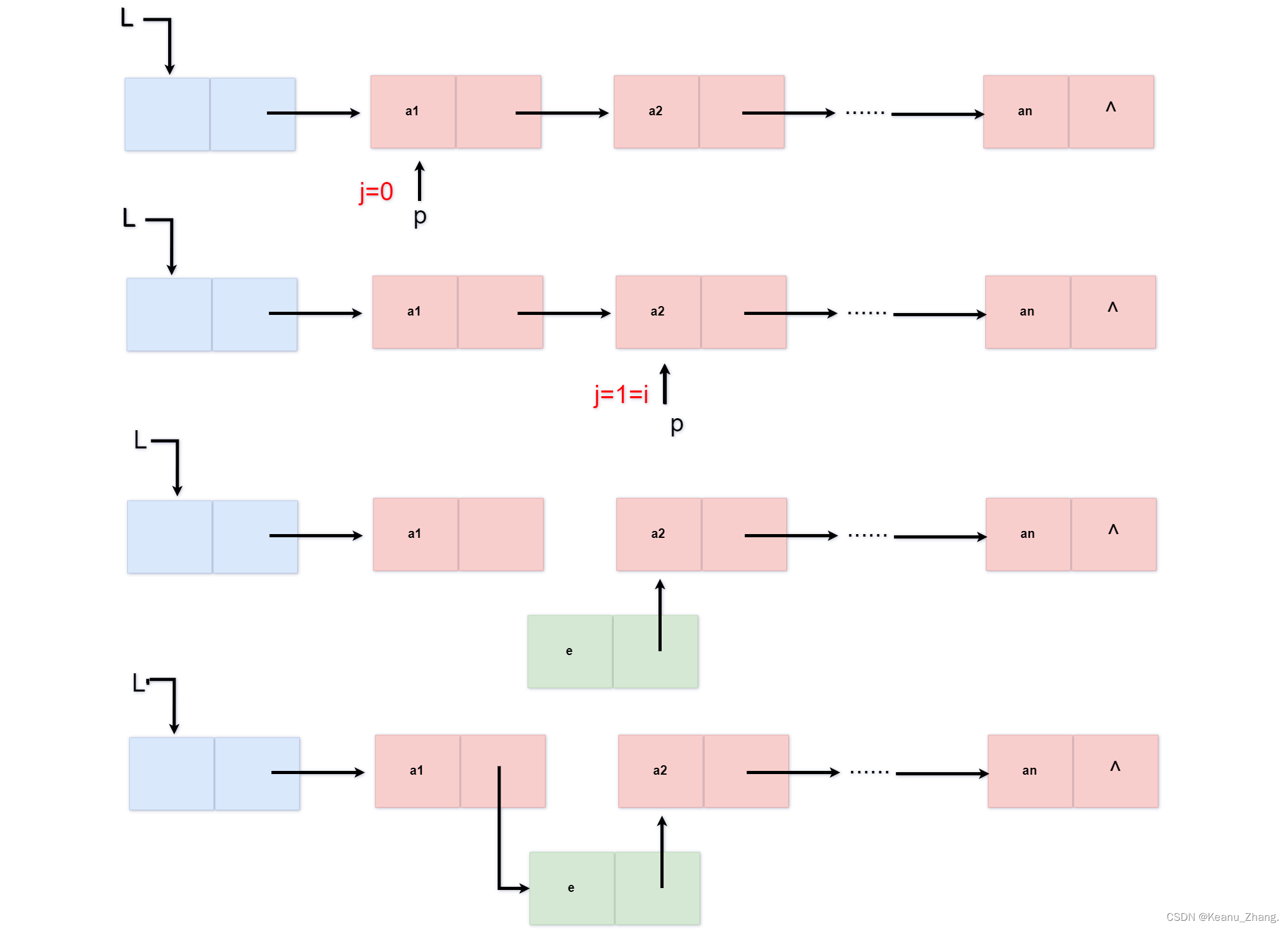
int insertlist(linklist& L,int i,elemtype e)
{
lnode* p;
p = L->next;
int j = 0;
while (p&&j<i-1)
{
p = p->next;
j++;
}
if (!p || j > i - 1) {
return 0;
}
else {
linklist s;//因为需要重新添加一个结点信息,所以需要new一块新的结点区域
s = new lnode;
s->data = e; //将数据元素插入该结点的数据域
s->next=p->next; //将最初p结点的下一个结点的地址赋给新的结点s的指针域
p->next = s;//直接将s的地址,赋给p的指针域
return 1;
}
}⑧ 删除第i个结点
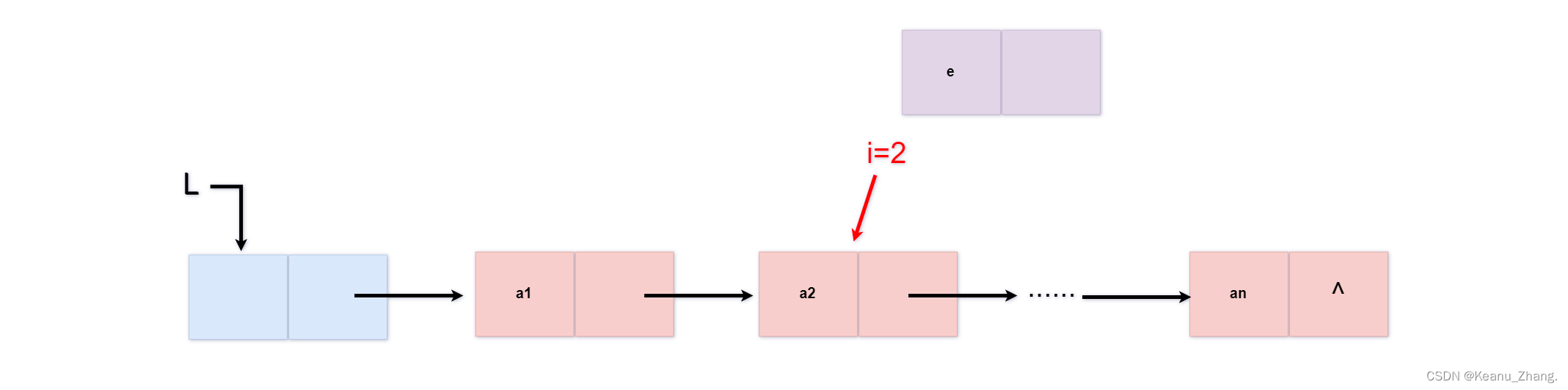
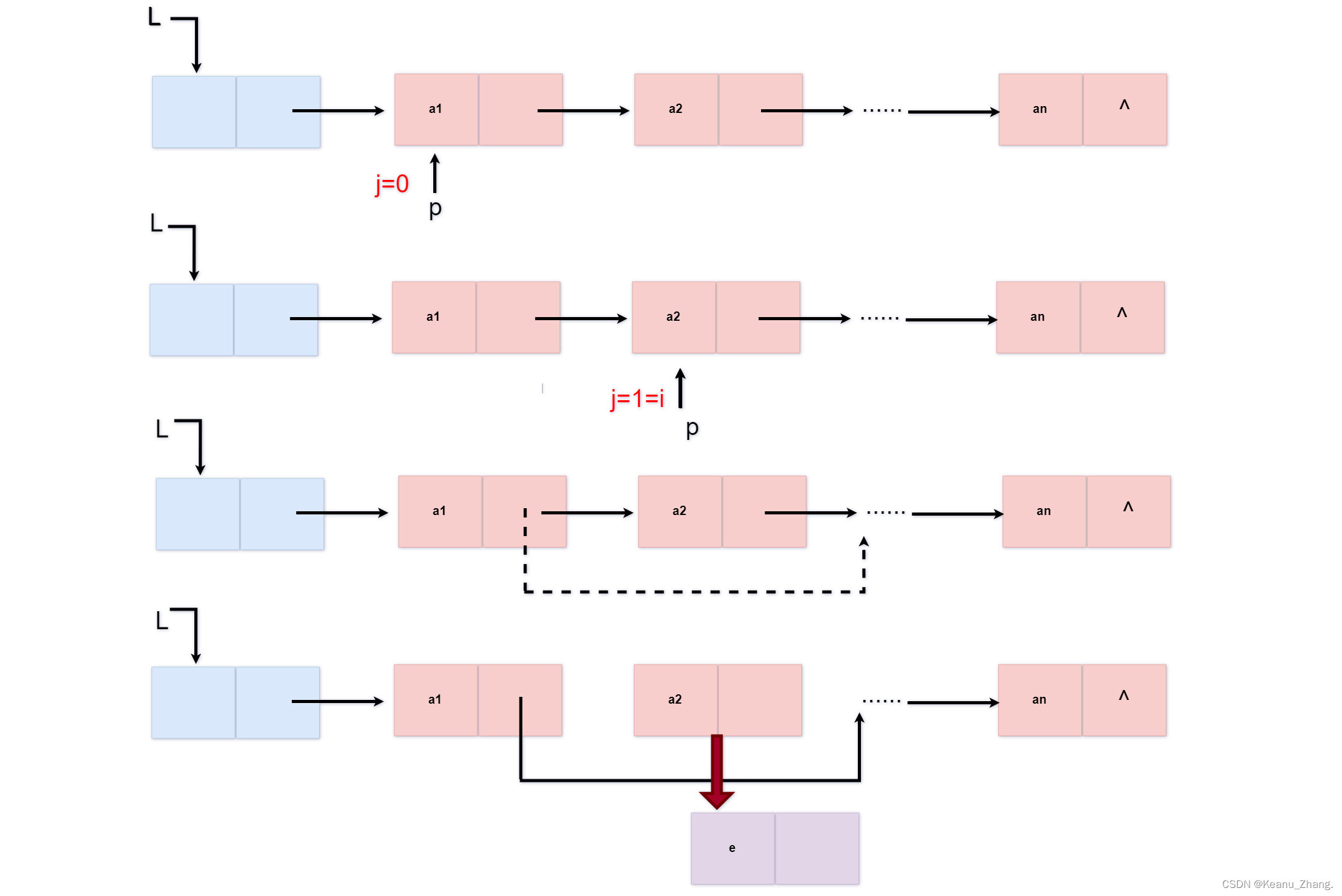
int deletelist(linklist& L, int i, elemtype e)
{
lnode* p;
lnode* q;
p = L->next;
int j = 0;
while (p && j< i - 1)
{
p = p->next;
j++;
}
if (!p || j > i - 1) {
return 0;
}
else {
q = p->next; //此时结点p的下一个结点就是要去删除的结点,将这个位置赋给指针q
p->next=q->next;//将要删除的前后结点连起来,不去影响该链表
e=q->data; //用e先将要删除结点中的数据元素保存下来
delete q; //删除要删除的结点
return 1;
}
}⑨头插法(前提是已经通过初始化创建了一个空链表)
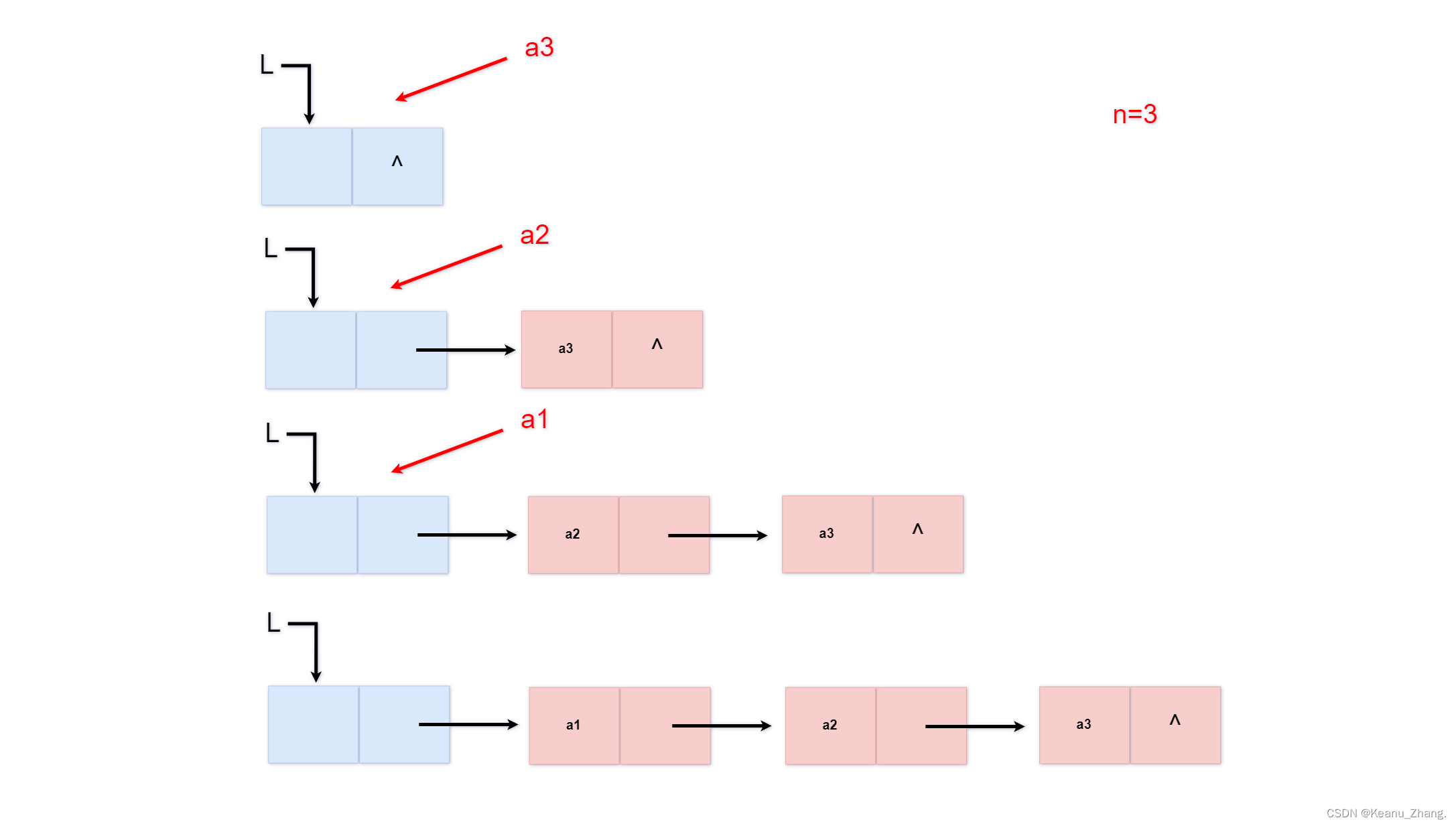
void insertlist_head(linklist& L,int n)
{
linklist head_s;
for (int i = n; i > 0; i--)
{
head_s = new lnode; //创建新的结点
cin >> head_s->data; //输入数据域的数据
head_s->next=L->next; //进行结点间的连接
L->next = head_s; //进行结点间的连接
}
}⑩尾插法(前提是已经通过初始化创建了一个空链表)
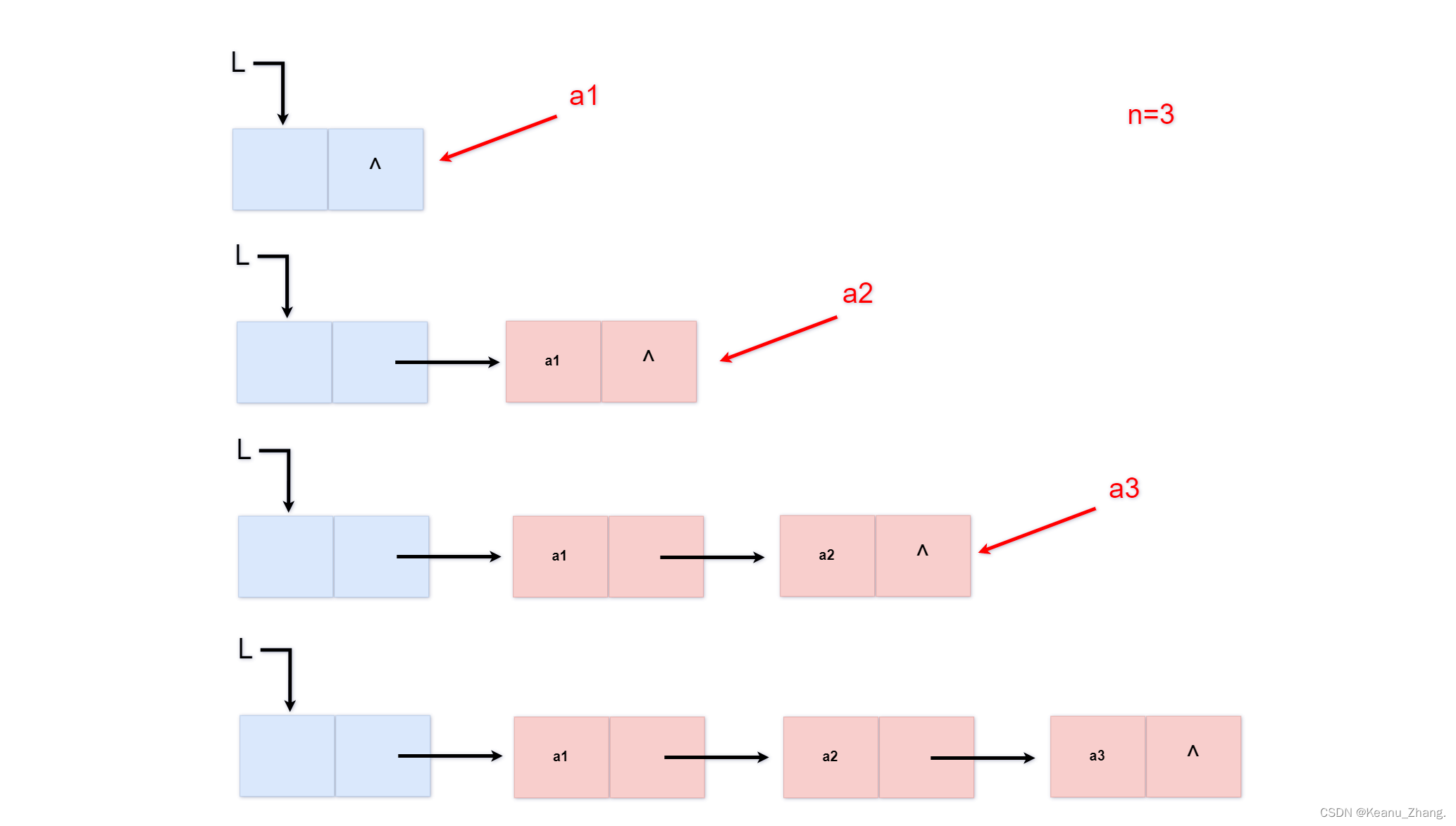
void insertlist_tail(linklist& L, int n)
{
linklist tail_s;
lnode* p;
p = L;
for (int i = 1; i <= n; i++)
{
tail_s = new lnode;
cin >> tail_s->data;
tail_s->next = NULL; //每次都将新创建结点的指针域置为空
p->next = tail_s;
p = tail_s;
}
}总结
以上就是我们对链表关键操作代码段的讲解。如果你可以完全掌握上面的代码段,那么你就可以利用这些数据结构算法来解决关于链表这一类的相关问题了,并且如果你能够在一些其他类的程序设计问题中巧用链表,那么你就可以更快、更好、更方便的去解决你所要去解决的问题。
<您的三连和关注是我最大的动力>
🚀 文章作者:Keanu Zhang 分类专栏:算法之美(C++系列文章)



![LeetCode[128]最长连续序列](https://img-blog.csdnimg.cn/img_convert/4a9c21f5065a408b9d734535377699c0.png)


![LeetCode[947]移除最多的同行或同列石头](https://img-blog.csdnimg.cn/img_convert/e8773a7c78ca4c0b8ae387fafe098a3b.png)
![LeetCode[765]情侣牵手](https://img-blog.csdnimg.cn/img_convert/6c966814fff54c3daab795aab4c20321.png)