在模型基本结构构建完成之后,接下来我们开始讨论如何进行逻辑回归的参数估计。所谓参数估计,其实就是模型参数求解的更加具有统计学风格的称呼。根据逻辑回归的基本公式:
y
=
1
1
+
e
−
(
w
^
T
⋅
x
^
)
y = \frac{1}{1+e^{-(\hat w^T \cdot \hat x)}}
y=1+e−(w^T⋅x^)1
由于只有一个特征,因此可以构建逻辑回归模型为:
y
=
s
i
g
m
o
i
d
(
w
x
+
b
)
=
1
1
+
e
−
(
w
x
+
b
)
y=sigmoid(wx+b)=\frac{1}{1+e^{-(wx+b)}}
y=sigmoid(wx+b)=1+e−(wx+b)1
我们将模型输出结果视作概率,则分别带入两条数据可得模型输出结果为:
p
(
y
=
1
∣
x
=
1
)
=
1
1
+
e
−
(
w
+
b
)
p(y=1|x=1)=\frac{1}{1+e^{-(w+b)}}
p(y=1∣x=1)=1+e−(w+b)1
p
(
y
=
1
∣
x
=
3
)
=
1
1
+
e
−
(
3
w
+
b
)
p(y=1|x=3)=\frac{1}{1+e^{-(3w+b)}}
p(y=1∣x=3)=1+e−(3w+b)1
其中
p
(
y
=
1
∣
x
=
1
)
p(y=1|x=1)
p(y=1∣x=1) 表示
x
x
x 取值为 1 时
y
y
y 取值为 1 的条件概率。
两条数据的真实情况为第一条数据
y
y
y 取值为 0,而第二条数据
y
y
y 取值为 1,因此我们可以计算
p
(
y
=
0
∣
x
=
1
)
p(y=0|x=1)
p(y=0∣x=1) 如下:
p
(
y
=
0
∣
x
=
1
)
=
1
−
p
(
y
=
1
∣
x
=
1
)
=
1
−
1
1
+
e
−
(
w
+
b
)
=
e
−
(
w
+
b
)
1
+
e
−
(
w
+
b
)
p(y=0|x=1) = 1-p(y=1|x=1)=1-\frac{1}{1+e^{-(w+b)}}=\frac{e^{-(w+b)}}{1+e^{-(w+b)}}
p(y=0∣x=1)=1−p(y=1∣x=1)=1−1+e−(w+b)1=1+e−(w+b)e−(w+b)
即:
sepal_length
species
1-predict
0-predict
1
0
1
1
+
e
−
(
w
+
b
)
\frac{1}{1+e^{-(w+b)}}
1+e−(w+b)1
e
−
(
w
+
b
)
1
+
e
−
(
w
+
b
)
\frac{e^{-(w+b)}}{1+e^{-(w+b)}}
1+e−(w+b)e−(w+b)
3
1
1
1
+
e
−
(
3
w
+
b
)
\frac{1}{1+e^{-(3w+b)}}
1+e−(3w+b)1
e
−
(
3
w
+
b
)
1
+
e
−
(
3
w
+
b
)
\frac{e^{-(3w+b)}}{1+e^{-(3w+b)}}
1+e−(3w+b)e−(3w+b)
此处如果我们希望模型预测结果尽可能准确,就等价于希望
p
(
y
=
0
∣
x
=
1
)
p(y=0|x=1)
p(y=0∣x=1) 和
p
(
y
=
1
∣
x
=
1
)
p(y=1|x=1)
p(y=1∣x=1) 两个概率结果越大越好。该目标可以统一在求下式最大值的过程中:
p
(
y
=
0
∣
x
=
1
)
⋅
p
(
y
=
1
∣
x
=
3
)
p(y=0|x=1)\cdot p(y=1|x=3)
p(y=0∣x=1)⋅p(y=1∣x=3)
即我们希望 x 取 1 时 y 取 0 和 x 取 3 时 y 取 1 的同时发生的概率越大越好。
此外,考虑到损失函数一般都是求最小值,因此可将上式求最大值转化为对应负数结果求最小值,同时累乘也可以转化为对数相加结果,因此上式求最大值可等价于下式求最小值:
L
o
g
i
t
L
o
s
s
(
w
,
b
)
=
−
l
n
(
p
(
y
=
1
∣
x
=
3
)
)
−
l
n
(
p
(
y
=
0
∣
x
=
1
)
)
=
−
l
n
(
1
1
+
e
−
(
3
w
+
b
)
)
−
l
n
(
e
−
(
w
+
b
)
1
+
e
−
(
w
+
b
)
)
=
l
n
(
1
+
e
−
(
3
w
+
b
)
)
+
l
n
(
1
+
1
e
−
(
w
+
b
)
)
=
l
n
(
1
+
e
−
(
3
w
+
b
)
+
e
(
w
+
b
)
+
e
−
2
w
)
\begin{aligned} LogitLoss(w, b)&=-ln(p(y=1|x=3))-ln(p(y=0|x=1)) \\ &=-ln(\frac{1}{1+e^{-(3w+b)}})- ln(\frac{e^{-(w+b)}}{1+e^{-(w+b)}}) \\ &=ln(1+e^{-(3w+b)})+ln(1+\frac{1}{e^{-(w+b)}}) \\ &=ln(1+e^{-(3w+b)}+e^{(w+b)}+e^{-2w}) \end{aligned}
LogitLoss(w,b)=−ln(p(y=1∣x=3))−ln(p(y=0∣x=1))=−ln(1+e−(3w+b)1)−ln(1+e−(w+b)e−(w+b))=ln(1+e−(3w+b))+ln(1+e−(w+b)1)=ln(1+e−(3w+b)+e(w+b)+e−2w)
至此我们即构建了一个由两条数据所构成的逻辑回归损失函数。
注意,在上述损失函数的构建过程中有两个关键步骤,需要再次提醒。
(1) 是在将模型高准确率的诉求具象化为
p
(
y
=
0
∣
x
=
1
)
⋅
p
(
y
=
1
∣
x
=
3
)
p(y=0|x=1)\cdot p(y=1|x=3)
p(y=0∣x=1)⋅p(y=1∣x=3) 参数的过程,此处我们为何不能采用类似 SSE 的计算思路取构建损失函数,即进行如下运算:
∣
∣
y
−
y
h
a
t
∣
∣
2
2
=
∣
∣
y
−
1
1
+
e
−
(
w
^
T
⋅
x
^
)
∣
∣
2
2
||y-yhat||_2^2=||y-\frac{1}{1+e^{-(\hat w^T \cdot \hat x)}}||_2^2
∣∣y−yhat∣∣22=∣∣y−1+e−(w^T⋅x^)1∣∣22
我们一般不会采用该方法构建损失函数,其根本原因在于,在数学层面上我们可以证明,对于逻辑回归,当 y 属于 0-1 分类变量时,
∣
∣
y
−
y
h
a
t
∣
∣
2
2
||y-yhat||_2^2
∣∣y−yhat∣∣22 损失函数并不是凸函数,而非凸的损失函数将对后续参数最优解求解造成很大麻烦。而相比之下,概率连乘所构建的损失函数是凸函数,可以快速求解出全域最小值。
从数学角度可以证明,按照上述构成构建的逻辑回归损失函数仍然是凸函数,此时我们仍然可以通过对 LogitLoss(w,b) 求偏导然后令偏导函数等于 0、再联立方程组的方式来对参数进行求解。
∂
L
o
g
i
t
L
o
s
s
(
w
,
b
)
∂
w
=
0
\frac{\partial LogitLoss(w,b)}{\partial w}=0
∂w∂LogitLoss(w,b)=0
∂
L
o
g
i
t
L
o
s
s
(
w
,
b
)
∂
b
=
0
\frac{\partial LogitLoss(w,b)}{\partial b}=0
∂b∂LogitLoss(w,b)=0
逻辑回归模型:
y
=
1
1
+
e
−
(
w
^
T
⋅
x
^
)
y = \frac{1}{1+e^{-(\hat w^T \cdot \hat x)}}
y=1+e−(w^T⋅x^)1
其中:
w
^
=
[
w
1
,
w
2
,
.
.
.
w
d
,
b
]
T
,
x
^
=
[
x
1
,
x
2
,
.
.
.
x
d
,
1
]
T
\hat w = [w_1,w_2,...w_d, b]^T, \hat x = [x_1,x_2,...x_d, 1]^T
w^=[w1,w2,...wd,b]T,x^=[x1,x2,...xd,1]T
我们知道,对于逻辑回归来说,当
w
^
\hat w
w^ 和
x
^
\hat x
x^ 取得一组之后,既可以有一个概率预测输出结果,即:
p
(
y
=
1
∣
x
^
;
w
^
)
=
1
1
+
e
−
(
w
^
T
⋅
x
^
)
p(y=1|\hat x;\hat w) = \frac{1}{1+e^{-(\hat w^T \cdot \hat x)}}
p(y=1∣x^;w^)=1+e−(w^T⋅x^)1
而对应
y
y
y 取 0 的概率为:
1
−
p
(
y
=
1
∣
x
^
;
w
^
)
=
1
−
1
1
+
e
−
(
w
^
T
⋅
x
^
)
=
e
−
(
w
^
T
⋅
x
^
)
1
+
e
−
(
w
^
T
⋅
x
^
)
1-p(y=1|\hat x;\hat w) =1- \frac{1}{1+e^{-(\hat w^T \cdot \hat x)}}=\frac{e^{-(\hat w^T \cdot \hat x)}}{1+e^{-(\hat w^T \cdot \hat x)}}
1−p(y=1∣x^;w^)=1−1+e−(w^T⋅x^)1=1+e−(w^T⋅x^)e−(w^T⋅x^)
我们可以令
p
1
(
x
^
;
w
^
)
=
p
(
y
=
1
∣
x
^
;
w
^
)
p_1(\hat x;\hat w)=p(y=1|\hat x;\hat w)
p1(x^;w^)=p(y=1∣x^;w^)
p
0
(
x
^
;
w
^
)
=
1
−
p
(
y
=
1
∣
x
^
;
w
^
)
p_0(\hat x;\hat w)=1-p(y=1|\hat x;\hat w)
p0(x^;w^)=1−p(y=1∣x^;w^)
因此,第
i
i
i 个数据所对应的似然项可以写成:
p
1
(
x
^
;
w
^
)
y
i
⋅
p
0
(
x
^
;
w
^
)
(
1
−
y
i
)
p_1(\hat x;\hat w)^{y_i} \cdot p_0(\hat x;\hat w)^{(1-y_i)}
p1(x^;w^)yi⋅p0(x^;w^)(1−yi)
其中,
y
i
y_i
yi 表示第
i
i
i 条数据对应的类别标签。不难发现,当
y
i
=
0
y_i=0
yi=0 时,代表的是
i
i
i 第条数据标签为 0,此时需要带入似然函数的似然项是
p
0
(
x
^
;
w
^
)
p_0(\hat x;\hat w)
p0(x^;w^)(因为希望
p
0
p_0
p0 的概率更大)。
反之,当
y
i
=
1
y_i=1
yi=1 时,代表的是
i
i
i 第条数据标签为 1,此时需要带入似然函数的似然项是
p
1
(
x
^
;
w
^
)
p_1(\hat x;\hat w)
p1(x^;w^)。上述似然项可以同时满足这两种不同的情况。
(2) 构建似然函数
接下来,通过似然项的累乘计算极大似然函数:
∏
i
=
1
N
[
p
1
(
x
^
;
w
^
)
y
i
⋅
p
0
(
x
^
;
w
^
)
(
1
−
y
i
)
]
\prod^N_{i=1}[p_1(\hat x;\hat w)^{y_i} \cdot p_0(\hat x;\hat w)^{(1-y_i)}]
i=1∏N[p1(x^;w^)yi⋅p0(x^;w^)(1−yi)]
(3) 进行对数转换
然后即可在似然函数基础上对其进行(以 e 为底的)对数转换,为了方便后续利用优化方法求解最小值,同样我们考虑构建负数对数似然函数:
L
(
w
^
)
=
−
l
n
(
∏
i
=
1
N
[
p
1
(
x
^
;
w
^
)
y
i
⋅
p
0
(
x
^
;
w
^
)
(
1
−
y
i
)
]
)
=
∑
i
=
1
N
[
−
y
i
⋅
l
n
(
p
1
(
x
^
;
w
^
)
)
−
(
1
−
y
i
)
⋅
l
n
(
p
0
(
x
^
;
w
^
)
)
]
=
∑
i
=
1
N
[
−
y
i
⋅
l
n
(
p
1
(
x
^
;
w
^
)
)
−
(
1
−
y
i
)
⋅
l
n
(
1
−
p
1
(
x
^
;
w
^
)
)
]
\begin{aligned} L(\hat w) &= -ln(\prod^N_{i=1}[p_1(\hat x;\hat w)^{y_i} \cdot p_0(\hat x;\hat w)^{(1-y_i)}]) \\ &= \sum^N_{i=1}[-y_i \cdot ln(p_1(\hat x;\hat w))-(1-y_i) \cdot ln(p_0(\hat x;\hat w))] \\ &= \sum^N_{i=1}[-y_i \cdot ln(p_1(\hat x;\hat w))-(1-y_i) \cdot ln(1-p_1(\hat x;\hat w))] \end{aligned}
L(w^)=−ln(i=1∏N[p1(x^;w^)yi⋅p0(x^;w^)(1−yi)])=i=1∑N[−yi⋅ln(p1(x^;w^))−(1−yi)⋅ln(p0(x^;w^))]=i=1∑N[−yi⋅ln(p1(x^;w^))−(1−yi)⋅ln(1−p1(x^;w^))]
尽管最终损失函数构建结果和极大似然估计相同,但该过程所涉及到的关于信息熵(entropy)、相对熵等概念却是包括 EM 算法、决策树算法等诸多机器学习算法的理论基础。
1. 熵(entropy)的基本概念与计算公式
通常我们用熵(entropy)来表示随机变量不确定性的度量,或者说系统混乱程度、信息混乱程度。熵的计算公式如下:
H
(
X
)
=
−
∑
i
=
1
n
p
(
x
i
)
l
o
g
(
p
(
x
i
)
)
H(X) = -\sum^n_{i=1}p(x_i)log(p(x_i))
H(X)=−i=1∑np(xi)log(p(xi))
其中,
p
(
x
i
)
p(x_i)
p(xi) 表示多分类问题中第
i
i
i 个类别出现的概率,
n
n
n 表示类别总数,通常来说信息熵的计算都取底数为 2,并且规定
l
o
g
0
=
0
log0=0
log0=0。举例说明信息熵计算过程,假设有二分类数据集 1 标签如下:
数据集1
index
labels
1
0
2
1
3
1
4
1
则信息熵的计算过程中
n
=
2
n=2
n=2,令
p
(
x
1
)
p(x_1)
p(x1) 表示类别 0 的概率,
p
(
x
2
)
p(x_2)
p(x2) 表示类别 1 的概率(反之亦然),则
p
(
x
1
)
=
1
4
p(x_1)=\frac{1}{4}
p(x1)=41
p
(
x
2
)
=
3
4
p(x_2)=\frac{3}{4}
p(x2)=43
则该数据集的信息熵计算结果如下:
H
(
X
)
=
−
(
p
(
x
1
)
l
o
g
(
p
(
x
1
)
)
+
p
(
x
2
)
l
o
g
(
p
(
x
2
)
)
)
=
−
(
1
4
)
l
o
g
(
1
4
)
−
(
3
4
)
l
o
g
(
3
4
)
\begin{aligned} H(X) &= -(p(x_1)log(p(x_1))+p(x_2)log(p(x_2))) \\ &=-(\frac{1}{4})log(\frac{1}{4})-(\frac{3}{4})log(\frac{3}{4}) \end{aligned}
H(X)=−(p(x1)log(p(x1))+p(x2)log(p(x2)))=−(41)log(41)−(43)log(43)
defentropy(p):if p ==0or p ==1:
ent =0else:
ent =-p * np.log2(p)-(1-p)* np.log2(1-p)return ent
简单测试函数性能:
entropy(1/4)#0.8112781244591328
同时,在二分类问题中,
n
=
2
n=2
n=2 且
p
(
x
1
)
+
p
(
x
2
)
=
1
p(x_1)+p(x_2)=1
p(x1)+p(x2)=1,我们也可推导二分类的信息熵计算公式为:
H
(
X
)
=
−
p
(
x
)
l
o
g
(
p
(
x
)
)
−
(
1
−
p
(
x
)
)
l
o
g
(
1
−
p
(
x
)
)
H(X) = -p(x)log(p(x))-(1-p(x))log(1-p(x))
H(X)=−p(x)log(p(x))−(1−p(x))log(1−p(x))
对于该数据集,我们可以计算信息熵为
H
1
(
X
)
=
−
(
1
2
)
l
o
g
(
1
2
)
−
(
1
2
)
l
o
g
(
1
2
)
H_1(X) = -(\frac{1}{2})log(\frac{1}{2})-(\frac{1}{2})log(\frac{1}{2})
H1(X)=−(21)log(21)−(21)log(21)
entropy(1/2)#1.0
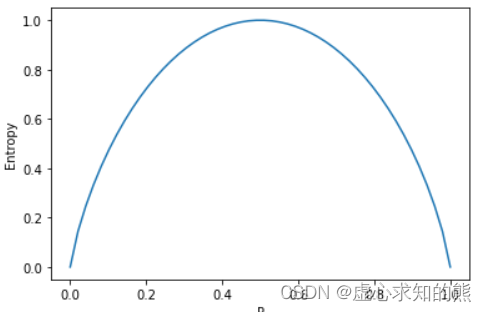
此时信息熵达到最高值,也就代表对于上述二分类的数据集,标签随机变量的不确定性已经达到峰值。
进一步我们计算下列数据集 3 的信息熵:
数据集3
index
labels
1
1
2
1
3
1
4
1
信息熵计算可得:
H
1
(
X
)
=
−
(
4
4
)
l
o
g
(
4
4
)
−
(
0
4
)
l
o
g
(
0
4
)
=
0
H_1(X) = -(\frac{4}{4})log(\frac{4}{4})-(\frac{0}{4})log(\frac{0}{4})=0
H1(X)=−(44)log(44)−(40)log(40)=0
这里需要注意的是,信息熵计算中规定
l
o
g
0
=
0
log0=0
log0=0。
entropy(0)#0
此时信息熵取得最小值,也就代表标签的取值整体呈现非常确定的状态,系统信息规整。
值得一提的是,此时标签本身的信息量也为 0,并没有进一步进行预测的必要。
结合上述三个数据集,不难看出,当标签取值不均时信息熵较高,标签取值纯度较高时信息熵较低。
假设 p 为未分类数据集中1样本所占比例,则数据集信息熵随着 p 变化为变化趋势如下:
p = np.linspace(0,1,50)
ent_l =[entropy(x)for x in p]
plt.plot(p, ent_l)
plt.xlabel('P')
plt.ylabel('Entropy')
假设对同一个随机变量 X,有两个单独的概率分布 P(x) 和 Q(x),当 X 是离散变量时,我们可以通过如下相对熵计算公式来衡量二者差异:
D
K
L
(
P
∣
∣
Q
)
=
∑
i
=
1
n
P
(
x
i
)
l
o
g
(
P
(
x
i
)
Q
(
x
i
)
)
D_{KL}(P||Q)=\sum ^n_{i=1}P(x_i)log(\frac{P(x_i)}{Q(x_i)})
DKL(P∣∣Q)=i=1∑nP(xi)log(Q(xi)P(xi))
和信息熵类似,相对熵越小,代表 Q(x) 和 P(x) 越接近。
从交叉熵的计算公式不难看出,这其实是一种非对称性度量,也就是
D
K
L
(
P
∣
∣
Q
)
≠
D
K
L
(
Q
∣
∣
P
)
D_{KL}(P||Q)≠D_{KL}(Q||P)
DKL(P∣∣Q)=DKL(Q∣∣P)。
从本质上来说,相对熵刻画的是用概率分布 Q 来刻画概率分布 P 的困难程度,而在机器学习领域,我们一般令 Q 为模型输出结果,而 P 为数据集标签真实结果,以此来判断模型输出结果是否足够接近真实情况。
Q 为拟合分布 P 为真实分布,也被称为前向 KL 散度(forward KL divergence)。
当然,上述相对熵公式等价于:
D
K
L
(
P
∣
∣
Q
)
=
∑
i
=
1
n
P
(
x
i
)
l
o
g
(
P
(
x
i
)
Q
(
x
i
)
)
=
∑
i
=
1
n
P
(
x
i
)
l
o
g
(
P
(
x
i
)
)
−
∑
i
=
1
n
P
(
x
i
)
l
o
g
(
Q
(
x
i
)
)
=
−
H
(
P
(
x
)
)
+
[
−
∑
i
=
1
n
P
(
x
i
)
l
o
g
(
Q
(
x
i
)
)
]
\begin{aligned} D_{KL}(P||Q)&=\sum ^n_{i=1}P(x_i)log(\frac{P(x_i)}{Q(x_i)}) \\ &=\sum ^n_{i=1}P(x_i)log(P(x_i))-\sum ^n_{i=1}P(x_i)log(Q(x_i)) \\ &=-H(P(x))+[-\sum ^n_{i=1}P(x_i)log(Q(x_i))] \end{aligned}
DKL(P∣∣Q)=i=1∑nP(xi)log(Q(xi)P(xi))=i=1∑nP(xi)log(P(xi))−i=1∑nP(xi)log(Q(xi))=−H(P(x))+[−i=1∑nP(xi)log(Q(xi))]
而对于给定数据集,信息熵
H
(
P
(
X
)
)
H(P(X))
H(P(X)) 是确定的,因此相对熵的大小完全由
−
∑
i
=
1
n
P
(
x
i
)
l
o
g
(
Q
(
x
i
)
)
-\sum ^n_{i=1}P(x_i)log(Q(x_i))
−∑i=1nP(xi)log(Q(xi)) 决定。
该式计算结果也被称为交叉熵(cross entropy)计算。
c
r
o
s
s
_
e
n
t
r
o
p
y
(
P
,
Q
)
=
−
∑
i
=
1
n
P
(
x
i
)
l
o
g
(
Q
(
x
i
)
)
cross\_entropy(P,Q) = -\sum ^n_{i=1}P(x_i)log(Q(x_i))
cross_entropy(P,Q)=−i=1∑nP(xi)log(Q(xi))
我们用相对熵
D
K
L
(
P
∣
∣
Q
)
D_{KL}(P||Q)
DKL(P∣∣Q)来表示模型拟合分布Q和数据真实分布P之间的差距,相对熵越小拟合效果越好;
根据计算公式,
D
K
L
(
P
∣
∣
Q
)
=
−
H
(
P
(
x
)
)
+
[
−
∑
i
=
1
n
P
(
x
i
)
l
o
g
(
Q
(
x
i
)
)
]
D_{KL}(P||Q)=-H(P(x))+[-\sum ^n_{i=1}P(x_i)log(Q(x_i))]
DKL(P∣∣Q)=−H(P(x))+[−∑i=1nP(xi)log(Q(xi))],相对熵=交叉熵-信息熵;
其中 A、B 表示每条样本可能所属的类别。围绕该数据集,第一条数据的交叉熵计算过程如下:
c
r
o
s
s
_
e
n
t
r
o
p
y
=
−
0
∗
l
o
g
(
0.2
)
−
1
∗
l
o
g
(
0.8
)
cross\_entropy = -0 * log(0.2)-1*log(0.8)
cross_entropy=−0∗log(0.2)−1∗log(0.8)
-np.log2(0.8)#0.3219280948873623
再次理解交叉熵计算公式中的叠加是类别的叠加。
上述数据集标签由 0-1 转化为 A、B,也被称为名义型变量的独热编码。
2. 多样本交叉熵计算
而对于多个数据集,整体交叉熵实际上是每条数据交叉熵的均值。例如上述数据集,整体交叉熵计算结果为:
−
1
∗
l
o
g
(
0.8
)
−
1
∗
l
o
g
(
0.7
)
−
1
∗
l
o
g
(
0.6
)
−
1
∗
l
o
g
(
0.7
)
4
\frac{-1 * log(0.8)-1 * log(0.7)-1 * log(0.6)-1 * log(0.7)}{4}
4−1∗log(0.8)−1∗log(0.7)−1∗log(0.6)−1∗log(0.7)
据此,我们可以给出多样本交叉熵计算公式如下:
c
r
o
s
s
_
e
n
t
r
o
p
y
=
−
1
m
∑
j
m
∑
i
n
p
(
p
i
j
)
l
o
g
(
q
i
j
)
cross\_entropy = -\frac{1}{m}\sum ^m_j \sum^n_ip(p_{ij})log(q_{ij})
cross_entropy=−m1j∑mi∑np(pij)log(qij)
其中 m 为数据量,n 为类别数量。
3. 对比极大似然估计函数
围绕上述数据集,如果考虑采用极大似然估计来进行计算,我们发现基本计算流程保持一致:
L
(
w
^
)
=
∑
i
=
1
N
[
−
y
i
⋅
l
n
(
p
1
(
x
^
;
w
^
)
)
−
(
1
−
y
i
)
⋅
l
n
(
1
−
p
1
(
x
^
;
w
^
)
)
]
L(\hat w)= \sum^N_{i=1}[-y_i \cdot ln(p_1(\hat x;\hat w))-(1-y_i) \cdot ln(1-p_1(\hat x;\hat w))]
L(w^)=i=1∑N[−yi⋅ln(p1(x^;w^))−(1−yi)⋅ln(1−p1(x^;w^))]
带入数据可得:
−
l
n
(
0.8
)
−
l
n
(
0.7
)
−
l
n
(
0.6
)
−
l
n
(
0.7
)
-ln(0.8)-ln(0.7)-ln(0.6)-ln(0.7)
−ln(0.8)−ln(0.7)−ln(0.6)−ln(0.7)
据此,我们也可最终推导二分类交叉熵损失函数计算公式,结合极大似然估计的计算公式和交叉熵的基本计算流程,二分类交叉熵损失函数为:
b
i
n
a
r
y
C
E
(
w
^
)
=
−
1
n
∑
i
=
1
N
[
y
i
⋅
l
o
g
(
p
1
(
x
^
;
w
^
)
)
+
(
1
−
y
i
)
⋅
l
o
g
(
1
−
p
1
(
x
^
;
w
^
)
)
]
binaryCE(\hat w)= -\frac{1}{n}\sum^N_{i=1}[y_i \cdot log(p_1(\hat x;\hat w))+(1-y_i) \cdot log(1-p_1(\hat x;\hat w))]
binaryCE(w^)=−n1i=1∑N[yi⋅log(p1(x^;w^))+(1−yi)⋅log(1−p1(x^;w^))]
![LeetCode[947]移除最多的同行或同列石头](https://img-blog.csdnimg.cn/img_convert/e8773a7c78ca4c0b8ae387fafe098a3b.png)
![LeetCode[765]情侣牵手](https://img-blog.csdnimg.cn/img_convert/6c966814fff54c3daab795aab4c20321.png)