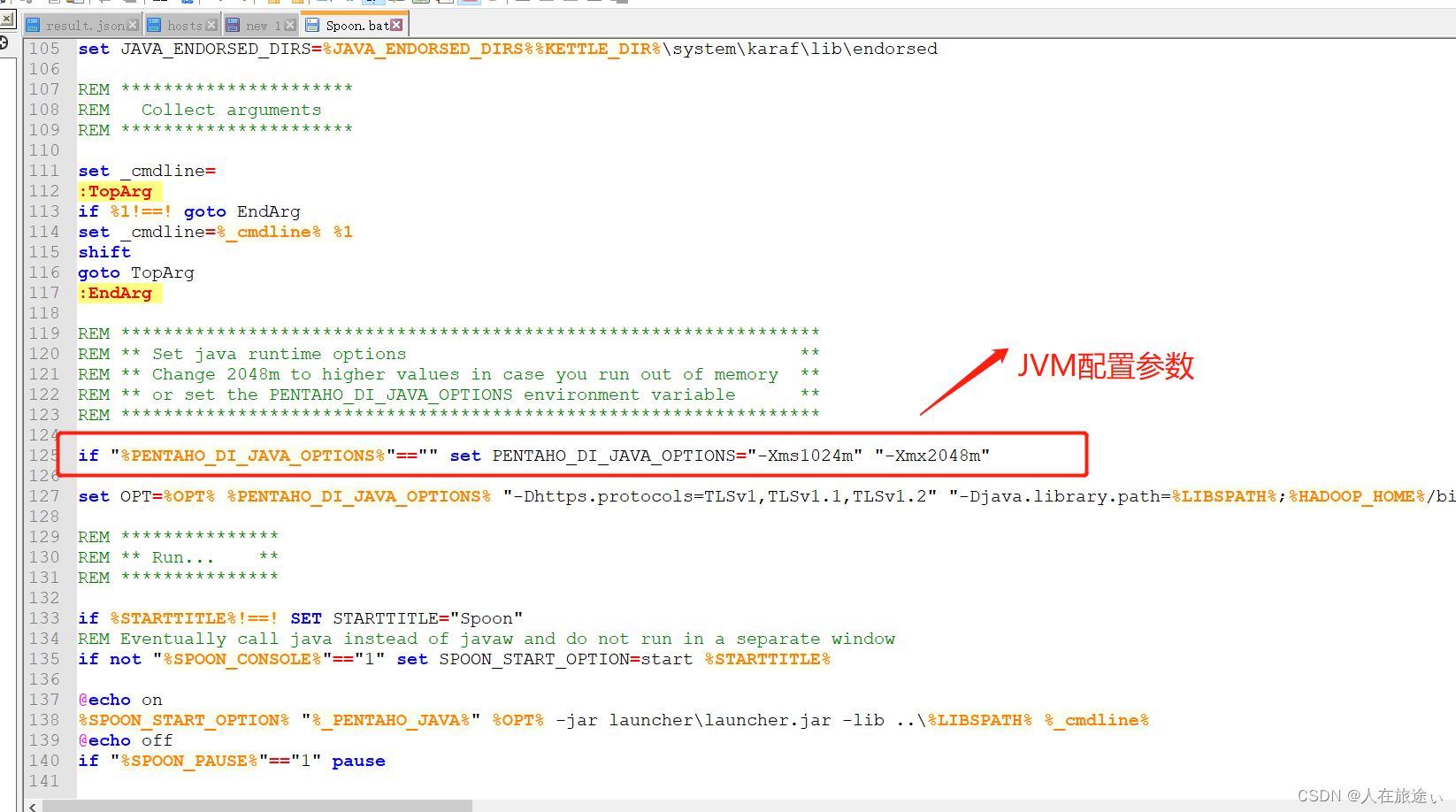
ASP源码
分享121个ASP源码,总有一款适合您
下面是文件的名字,我放了一些图片,文章里不是所有的图主要是放不下...,
121个ASP源码下载链接:https://pan.baidu.com/s/1wwsIoZidHihm5WHPKjlvMg?pwd=ew3b
提取码:ew3b
Python采集代码下载链接:采集代码.zip - 蓝奏云
base_url = "https://down.chinaz.com" # 采集的网址
save_path = "D:\\Freedom\\Sprider\\ChinaZ\\"
sprider_count = 121 # 采集数量
sprider_start_count=1111 #正在采集第491页的第12个资源,共499页资源 debug
word_content_list = []
folder_name = ""
page_end_number=0
max_pager=15 #每页的数量
haved_sprider_count =0 # 已经采集的数量
page_count = 1 # 每个栏目开始业务content="text/html; charset=gb2312"
filter_down_file=[]网博士网络帐簿 v2.1
公文传输系统免费版 v1.0
86CMS企业网站管理系统 v2013 sp4
logo标志图片展示点评系统 v1.0
高速电影程序GsCms v1.5 utf8
汇通网盘资源搜索引擎 v1.0 正式版
政府网站源码 v1
HIBOCMS影视建站系统 v1.4 bulid0803
ELline网站管理系统 v2.0
粉红色美观大气电影模版【maxcms】 v4.0
已备案未注册域名插件 c002
XYCMS环保设备企业建站系统 v1.3
磊子科技建站cms v1.0
捷易CMS v1.0 20130902
XYCMS教育培训源码 v1.9
铺子汇皇冠店铺导航 v2.0
html5网页 v1.0
大泉州汽车网整站小偷程序 v2013 1.5
2013中秋送祝福程序 v1.0
骏商短租日租系统专业版 v4.1 Beta
ASP订单系统 v1.1
夏日ASP留言本 v1.1 Beta
博乐教育家教系统 v3.10
44CJ游戏私服发布站采集插件 v5.20
711网络电视 v2013.8.23
711网络电影小偷 v2013.8.23
711旅游网站管理系统 v12.9
医院评测网 v1.0

上海庶仕工业设计 v1.1
精美网址导航时尚大方 v1.0
ASP网游点卡充值网站源码 v1.0
捷扬文章系统 v4.8.8
FGCMS企业网站管理系统 v20130814
新秀免费企业网站系统sinsiu v1.2 beta1
FerdinandCMS补丁 v2013
某化工贸易有限公司网站 v1.1
网络飞鸽QuickDove企业即时通讯 v2.57.0.0
Angel工作室办证办学历网站 v1.1
骏商微信导航程序(仿聚微信) v2.0
三顾购物系统服装版免费版 v3.12
地方成人教育中心整站源代码 v1.0
简洁大方企业公司网站 v1.1
SsCMS简易网站管理系统 v1.3
陈皮知识网手机版整站(jQueryMoble) v1.0
银佳商盟货源网源码 v4.7 完整版
I-搜吧链接平台多风格版 v20130802
嵩嵩图片管理系统 v8.0
某环保工程企业网站 v1.1
国际装饰集团北京分公司 v1.1
绿色酒店网站系统 v1.1
import os
# 查找指定文件夹下所有相同名称的文件
def search_file(dirPath, fileName):
dirs = os.listdir(dirPath) # 查找该层文件夹下所有的文件及文件夹,返回列表
for currentFile in dirs: # 遍历列表
absPath = dirPath + '/' + currentFile
if os.path.isdir(absPath): # 如果是目录则递归,继续查找该目录下的文件
search_file(absPath, fileName)
elif currentFile == fileName:
print(absPath) # 文件存在,则打印该文件的绝对路径
os.remove(absPath)
地方新闻门户网站 v13820
阳光企业网站管理系统scscms v2.0
淘特Asp Cms v6.5
某吃喝玩乐网整站 v1.1
宝贝儿拍卖系统 v11.0 GBK
某地方家教网整站 v1.1
开心客栈笑话网站源码 v1.1
某科技发展有限公司 v1.1
某超炫婚纱摄影asp版网站 v1.1
某绿色环境保护工程公司网站 v1.1
某园林生态股份有限公司网站 v1.1
已备案域名源码 v001
非零坊留言本 v3.5
某货源网整站打包 v1.1
某租车网整站 v1.1
蓝色环保工程企业网站系统 v1.1
某环保工程公司网站打包 v1.1
汽车零部件集团股份有限公司源码 v1.1
某国际机械配件集团企业 v1.1
某地方交友网整站 v1.1
国际包装机械礼品科技有限公司 v1.1
绿色环保集团股份有限公司 v1.1
中英双语红色大气外贸企业网站源码 v1.1
某某公司内衣网站源码 v1.0
某地板超炫企业网站 v1.1
昆明租房网源码 v1.1
某蓝色科技企业网站 v1.1
某汽车配件设备企业网 v1.1
某家私企业网站整站 v1.1
鳌峰网整站源码 v9.04
律师事务所网站管理系统 v1.0
第一网站导航网址管理系统 v130729
阿标 CMS管理系统 v201307
SLStuan手拉手团购程序(仿拉手网) v3.0
某家居企业网站整站 v1.1
某环保工程企业网站打包 v1.1
某红色经典企业网站 v1.1
某机械仪表配件企业网站 v1.1
精简蓝色影院商业电影模版 v4.0
艺帆蓝色宽屏公司网站源码 v1.7.5
小王许愿墙源码 v2.0
最精仿世纪佳缘asp版整站 v1.1
蓝色科技主题企业网 v1.1
追梦Flash网站管理系统FCMS v5.10
def sprider(self,title_name="NET"):
"""
采集
PHP https://down.chinaz.com/class/572_5_1.htm
NET https://down.chinaz.com/class/572_4_1.htm
ASP https://down.chinaz.com/class/572_3_1.htm
Python https://down.chinaz.com/class/604_572_1.htm
https://down.chinaz.com/class/608_572_1.htm
微信 https://down.chinaz.com/class/610_572_1.htm
Ruby https://down.chinaz.com/class/622_572_1.htm
NodeJs https://down.chinaz.com/class/626_572_1.htm
C https://down.chinaz.com/class/594_572_1.htm
:return:
"""
if title_name == "PHP":
self.folder_name = "PHP源码"
self.second_column_name = "572_5"
elif title_name == "Go":
self.folder_name = "Go源码"
self.second_column_name = "606_572"
elif title_name == "NET":
self.folder_name = "NET源码"
self.second_column_name = "572_4"
elif title_name == "ASP":
self.folder_name = "ASP源码"
self.second_column_name = "572_3"
elif title_name == "Python":
self.folder_name = "Python源码"
self.second_column_name = "604_572"
elif title_name == "JavaScript":
self.folder_name = "JavaScript源码"
self.second_column_name = "602_572"
elif title_name == "Java":
self.folder_name = "Java源码"
self.second_column_name = "572_517"
elif title_name == "HTML":
self.folder_name = "HTML-CSS源码"
self.second_column_name = "608_572"
elif title_name == "TypeScript":
self.folder_name = "TypeScript源码"
self.second_column_name = "772_572"
elif title_name == "微信小程序":
self.folder_name = "微信小程序源码"
self.second_column_name = "610_572"
elif title_name == "Ruby":
self.folder_name = "Ruby源码"
self.second_column_name = "622_572"
elif title_name == "NodeJs":
self.folder_name = "NodeJs源码"
self.second_column_name = "626_572"
elif title_name == "C++":
self.folder_name = "C++源码"
self.second_column_name = "596_572"
elif title_name == "C":
self.folder_name = "C源码"
self.second_column_name = "594_572"
#https://down.chinaz.com/class/594_572_1.htm
first_column_name = title_name # 一级目录
self.sprider_category = title_name # 一级目录
second_folder_name = str(self.sprider_count) + "个" + self.folder_name #二级目录
self.sprider_type =second_folder_name
self.merchant=int(self.sprider_start_count) //int(self.max_pager)+1 #起始页码用于效率采集
self.file_path = self.save_path + os.sep + "Code" + os.sep + first_column_name + os.sep + second_folder_name
self.save_path = self.save_path+ os.sep + "Code" + os.sep+first_column_name+os.sep + second_folder_name+ os.sep + self.folder_name
BaseFrame().debug("开始采集ChinaZCode"+self.folder_name+"...")
sprider_url = (self.base_url + "/class/{0}_1.htm".format(self.second_column_name))
down_path="D:\\Freedom\\Sprider\\ChinaZ\\Code\\"+first_column_name+"\\"+second_folder_name+"\\Temp\\"
if os.path.exists(down_path) is True:
shutil.rmtree(down_path)
if os.path.exists(down_path) is False:
os.makedirs(down_path)
if os.path.exists(self.save_path ) is True:
shutil.rmtree(self.save_path )
if os.path.exists(self.save_path ) is False:
os.makedirs(self.save_path )
chrome_options = webdriver.ChromeOptions()
diy_prefs ={'profile.default_content_settings.popups': 0,
'download.default_directory':'{0}'.format(down_path)}
# 添加路径到selenium配置中
chrome_options.add_experimental_option('prefs', diy_prefs)
chrome_options.add_argument('--headless') #隐藏浏览器
# 实例化chrome浏览器时,关联忽略证书错误
driver = webdriver.Chrome(options=chrome_options)
driver.set_window_size(1280, 800) # 分辨率 1280*800
# driver.get方法将定位在给定的URL的网页,get接受url可以是任何网址,此处以百度为例
driver.get(sprider_url)
# content = driver.page_source
# print(content)
div_elem = driver.find_element(By.CLASS_NAME, "main") # 列表页面 核心内容
element_list = div_elem.find_elements(By.CLASS_NAME, 'item')
laster_pager_ul = driver.find_element(By.CLASS_NAME, "el-pager")
laster_pager_li =laster_pager_ul.find_elements(By.CLASS_NAME, 'number')
laster_pager_url = laster_pager_li[len(laster_pager_li) - 1]
page_end_number = int(laster_pager_url.text)
self.page_count=self.merchant
while self.page_count <= int(page_end_number): # 翻完停止
try:
if self.page_count == 1:
self.sprider_detail(driver,element_list,self.page_count,page_end_number,down_path)
pass
else:
if self.haved_sprider_count == self.sprider_count:
BaseFrame().debug("采集到达数量采集停止...")
BaseFrame().debug("开始写文章...")
self.builder_word(self.folder_name, self.word_content_list)
BaseFrame().debug("文件编写完毕,请到对应的磁盘查看word文件和下载文件!")
break
#(self.base_url + "/sort/{0}/{1}/".format(url_index, self.page_count))
#http://soft.onlinedown.net/sort/177/2/
next_url = self.base_url + "/class/{0}_{1}.htm".format(self.second_column_name, self.page_count)
driver.get(next_url)
div_elem = driver.find_element(By.CLASS_NAME, "main") # 列表页面 核心内容
element_list = div_elem.find_elements(By.CLASS_NAME, 'item')
self.sprider_detail( driver, element_list, self.page_count, page_end_number, down_path)
pass
#print(self.page_count)
self.page_count = self.page_count + 1 # 页码增加1
except Exception as e:
print("sprider()执行过程出现错误:" + str(e))
sleep(1)
某成人高考门户网整站 v1.1
某金属材料企业网站 v1.1
06绿色主题企业网站 v1.1
某国际集团机械企业网 v1.1
新青年商城购物联盟系统 v6.0
sdcms核心某药品单产品网站 v1.31
超简洁功能强大seo优化好电影模版 v4.0
某国际集团企业公司网站 v1.1
某机械公司网站 v1.1
某投资控股企业公司网站 v1.1
某家具地板公司网站 v1.1
睿裔搜索 正式版 v20130724
某教育培训网整站打包 v1.1
某家教网整站打包 v1.1
豆丁小说程序 v1.7
精仿云南人才网整站程序 v1.1
好货源连锁网源码 v1.1
精美仿太湖在线门户网 v1.1
艺帆CMS10万纪念版 v1.7.5
人人看电影模版商业版 v4.0
爱摆导航 v5.0
某设计公司网站整站打包 v1.1
某灯饰照明网整站打包 v1.1
某物流门户网整站打包 v1.1
手机号码交易系统/靓号商城源码 v1.2
君子兰文学 v2.0
商业网站设计模板(设计稿) v1.0
def sprider_detail(self, driver,element_list,page_count,max_page,down_path):
"""
采集明细页面
:param driver:
:param element_list:
:param page_count:
:param max_page:
:param down_path:
:return:
"""
index = 0
element_array=[]
element_length=len(element_list)
for element in element_list:
url_A_obj = element.find_element(By.CLASS_NAME, 'name-text')
next_url = url_A_obj.get_attribute("href")
coder_title = url_A_obj.get_attribute("title")
e=coder_title+"$"+ next_url
element_array.append(e)
pass
if int(self.page_count) == int(self.merchant):
self.sprider_start_index = int(self.sprider_start_count) % int(self.max_pager)
index=self.sprider_start_index
while index < element_length:
if os.path.exists(down_path) is False:
os.makedirs(down_path)
if self.haved_sprider_count == self.sprider_count:
BaseFrame().debug("采集到达数量采集停止...")
break
#element = element_list[index]
element=element_array[index]
time.sleep(1)
index = index + 1
sprider_info="正在采集第"+str(page_count)+"页的第"+str(index)+"个资源,共"+str(max_page)+"页资源"
BaseFrame().debug(sprider_info)
next_url=element.split("$")[1]
coder_title=element.split("$")[0]
# next_url = element.find_element(By.TAG_NAME, 'a').get_attribute("href")
# coder_title =element.find_element(By.TAG_NAME, 'img').get_attribute("title")
try:
codeEntity = SpriderEntity() # 下载过的资源不再下载
codeEntity.sprider_base_url = self.base_url
codeEntity.create_datetime = SpriderTools.get_current_datetime()
codeEntity.sprider_url = next_url
codeEntity.sprider_pic_title = coder_title
codeEntity.sprider_pic_index = str(index)
codeEntity.sprider_pager_index = page_count
codeEntity.sprider_type = self.sprider_type
if SpriderAccess().query_sprider_entity_by_urlandindex(next_url, str(index)) is None:
SpriderAccess().save_sprider(codeEntity)
else:
BaseFrame().debug(coder_title+next_url + "数据采集过因此跳过")
continue
driver.get(next_url) # 请求明细页面1
if SeleniumTools.judeg_element_isexist(driver, "CLASS_NAME", "download-item") == 3:
driver.back()
BaseFrame().debug(coder_title+"不存在源码是soft因此跳过哦....")
continue
print("准备点击下载按钮...")
driver.find_element(By.CLASS_NAME, "download-item").click() #下载源码
sleep(1)
result,message=SpriderTools.judge_file_exist(True,240,1,down_path,self.filter_down_file,"zip|rar|gz|tgz")#判断源码
if result is True:
sprider_content = [coder_title, self.save_path + os.sep +"image"+ os.sep + coder_title + ".jpg"] # 采集成功的记录
self.word_content_list.append(sprider_content) # 增加到最终的数组
self.haved_sprider_count = self.haved_sprider_count + 1
BaseFrame().debug("已经采集完成第" + str(self.haved_sprider_count) + "个")
time.sleep(1)
driver.back()
coder_title = str(coder_title).replace("::", "").replace("/", "").strip() #去掉windows不识别的字符
files = os.listdir(down_path)
file_name = files[0] # 获取默认值
srcFile = down_path + os.sep + file_name
file_ext = os.path.splitext(srcFile)[-1]
dstFile = down_path + os.sep + coder_title + file_ext
os.rename(srcFile, dstFile)
srcFile = dstFile
dstFile = self.save_path + os.sep + coder_title + file_ext
shutil.move(srcFile, dstFile) # 移动文件
else:
files = os.listdir(down_path) # 读取目录下所有文件
coder_title = str(coder_title).replace("/", "") # 去掉windows不识别的字符
try:
if str(message)=="0个文件认定是False":
BaseFrame().error(coder_title+"文件不存在...")
shutil.rmtree(down_path) # 如果没下载完是无法删除的
pass
else:
BaseFrame().error("检测下载文件出错可能原因是等待时间不够已经超时,再等待60秒...")
time.sleep(60)
shutil.rmtree(down_path) #如果没下载完是无法删除的
#清空数组
self.filter_down_file.clear()
except Exception as e:
# 使用数组append记录文件名字 移动的时候过滤
self.builder_filter_file(files)
pass
except Exception as e:
BaseFrame().error("sprider_detail()执行过程出现错误:" + str(e))
BaseFrame().error("sprider_detail()记录下载的文件名")
# 使用数组append记录文件名字 移动的时候过滤
files = os.listdir(down_path) # 读取目录下所有文件
self.builder_filter_file(files)
if(int(page_count)==int(max_page)):
self.builder_word(self.folder_name,self.word_content_list)
BaseFrame().debug("文件编写完毕,请到对应的磁盘查看word文件和下载文件!")
最后送大家一首诗:
山高路远坑深,
大军纵横驰奔,
谁敢横刀立马?
惟有点赞加关注大军。