一、Kettle基本介绍
Kettle(现更名为Pentaho Data Integration-Pentaho)是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装。它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,功能强大可以对多种数据源进行抽取(Extraction)、加载(Loading)、数据落湖(Data Lake Injection)、对数据进行各种清洗(Cleaning)、转换(Transformation)、混合(Blending),并支持多维联机分析处理(OLAP)和数据挖掘(Data mining)。
其主要有两种脚本文件,transformation(转换)和job(作业),transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Github源码地址:https://github.com/pentaho/pentaho-kettle
Kettle各版本下载地址:https://sourceforge.net/projects/pentaho/files/
二、Kettle的体系架构
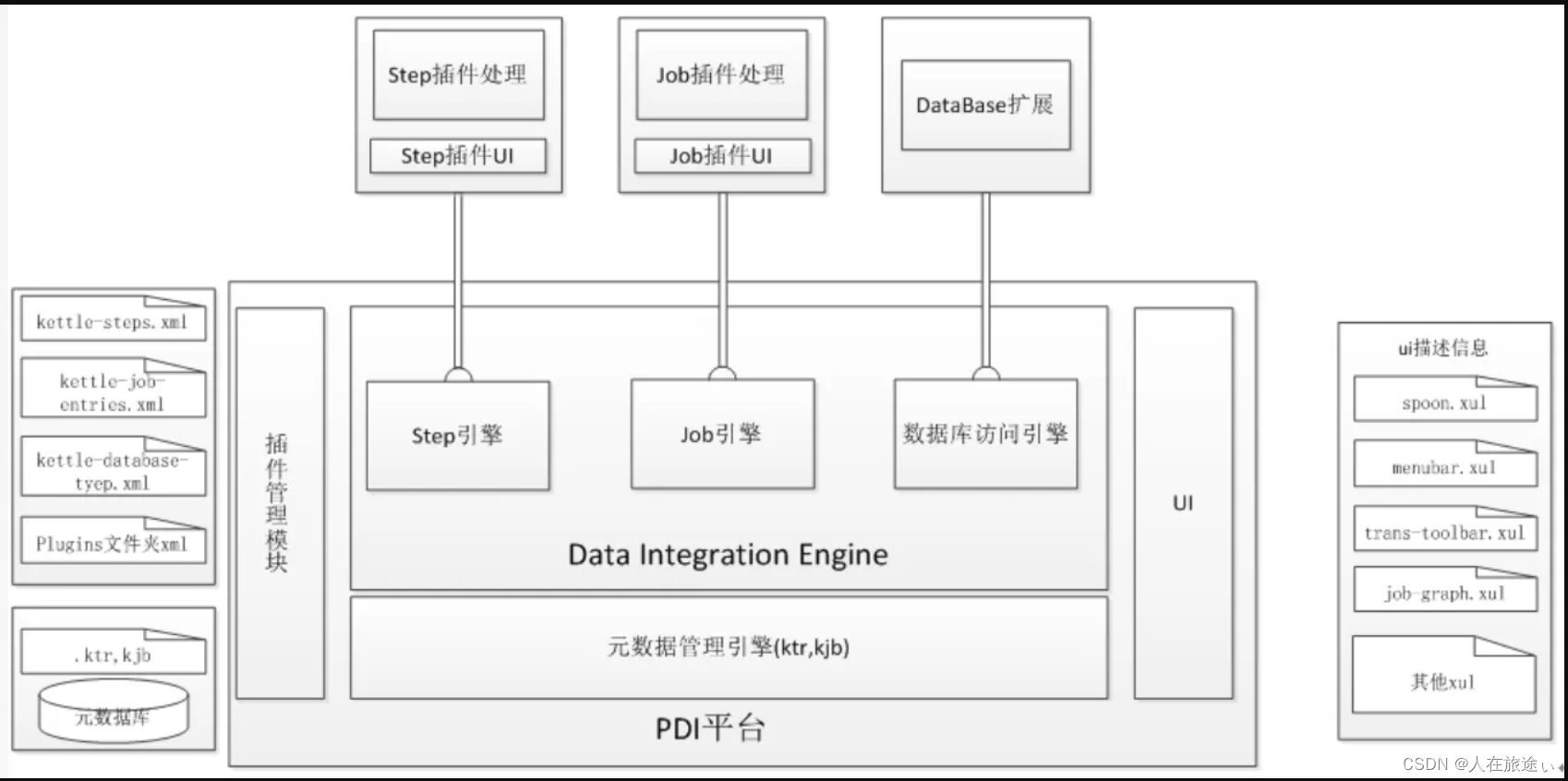
Kettle分为Kettle平台和各类插件(Setp插件、Job插件、Database插件、Partitioner插件),其中Kettle平台是整个系统的基础,包括UI、插件管理、元数据管理和数据集成引擎。UI显示Spoon这个核心组件的界面,通过xul实现菜单栏、工具栏的定制化,显示插件界面接口元素。元数据管理引擎管理ktr、kjob或者元数据库、插件通过该引擎获取基本信息。插件管理引擎主要负责插件的注册、数据集成引擎负责调用插件、并返回响应信息。
三、Kettle的设计模块
3.1 转换
转换(transformation)是ETL解决方案中最主要的部分,它处理抽取、转换、加载各阶段各,种对数据行的操作。转换包括一个或多个步骤(step),如读取文件、过滤输出行、数据清洗或将数据加载到数据库。转换里的步骤通过跳(hop)来连接,跳定义了一个单向通道,允许数据从一个步骤向另一个步骤流动。在Kettle 里,数据的单位是行,数据流就是数据行从一个步骤到另一个步骤的移动。数据流的另一个同义词就是记录流。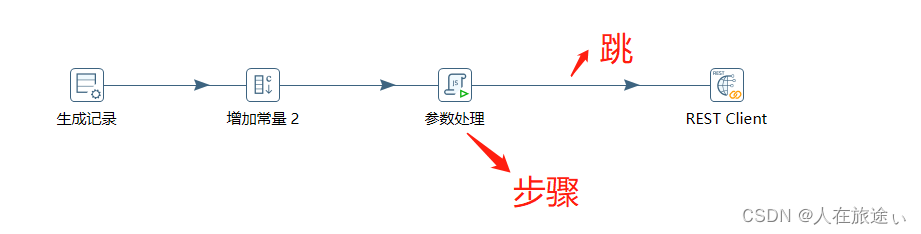
3.1.1 转换的步骤
步骤是转换里的基本组成部分。它以图标的方式图形化地展现,上图有四个步骤分别为生成记录、增加常量、参数处理、REST Client。
一个步骤有如下几个关键特性:
- 步骤需要有一个名字,这个名字在转换范围内唯一。
- 每个步骤都会读、写数据行(唯一例外是“生成记录”步骤,该步骤只写数据)。
- 步骤将数据写到与之相连的一个或多个输出跳(outgoing hops),再传送到跳的另一端的步骤。对另一端步骤来说这个跳就是一个输人跳(incoming hops),步骤通过输人跳接收数据。
- 大多数的步骤都可以有多个输出跳。一个步骤的数据发送可以被设置为轮流发送和复制发送。轮流发送是将数据行依次发给每一个输出跳(这种方式也称为round robin),复制发送是将全部数据行发送给所有输出跳。
- 在运行转换时,一个线程运行一个步骤和步骤的多份拷贝,所有步骤的线程几平同时运行,数据行连续地流过步骤之间的跳。
3.1.2 转换的跳
跳 (hop)就是步骤之间带箭头的连线,跳定义了步骤之间的数据通路。跳实际上是两个步骤之间的被称为行集(row set)的数据行缓存(行集的大小可以在转换的设置里定义)。满了,向行集写数据的步骤将停止写入,直到行集里又有了空间。当行集空了,从行集读取数据的步骤停止读取,直到行集里又有可读的数据行。
注意:当创建新跳的时候,需要记住跳在转换里不能循环。因为在转换里每个步骤都依赖前一个步骤获取字段值。
3.1.3 并行
跳的这种基于行集缓存的规则允许每个步骤都由一个独立的线程运行,这样并发程度最高。这一规则也允许数据以最小消耗内存的数据流的方式来处理。在数据仓库里,我们经常要处理大量数据,所以这种并发低耗内存的方式也是ETL工具的核心需求。
对于 Kettle,不可能定义一个执行顺序,不可能也没有必要确定一个起点和终点。因为所有步骤都以并发方式执行:当转换启动后,所有步骤都同时启动,从它们的输入跳中读取数据,并把处理过的数据写到输出跳,直到输入跳里不再有数据,就中止步骤的运行。当所有的步骤都中止了,整个转换就中止了。也就是说,从功能的角度来看,转换也有明确的起点和终点。**需要明确的是每个转换都必须要有一个输入步骤来激活任务,否则整个任务重没有数据输入,启动就意味着结束。**如果想要一个任务沿着指定的顺序执行,就需要用到作业。
3.1.4 数据行
数据以数据行的形式沿着步骤移动。一个数据行是零到多个字段的集合,字段包括下面几种数据类型。
- String:字符类型数据。
- Number:双精度浮点数。
- Integer:带符号长整型(64位)。
- BigNumber:任意精度数值。
- Date:带毫秒精度的日期时间值。
- Boolean:取值为true和false的布尔值。
- Binary:二进制字段可以包括图形、声音、视频及其他类型的二进制数据。
每个步骤在输出数据行时都有对字段的描述,这种描述就是数据行的元数据,通常包括下面一些信息。
- 名称:行里的字段名应该是唯一的。
- 数据类型:字段的数据类型。
- 长度:字符串的长度或BigNumber类型的长度
- 精度:BigNumber数据类型的十进制精度。
- 掩码:数据显示的格式(转换掩码)。如果要把数值型(Number、Integer、BigNumber),或日期类型转换成字符串类型就需要用到掩码。例如在图形界面中预览数值型、日期型数据,或者把这些数据保存成文本或XML格式就需要用到这种转换。
- 小数点:十进制数据的小数点格式。不同文化背景下小数点符号是不同的,一般是点(.)或逗号(,)。
- 分组符号:数值类型数据的分组符号,不同文化背景下数字里的分组符号也是不同的,一般是逗号 (,)或点(.)或单引号()。 (译者注:分组符号是数字里分制符号,便于阅读,如123,456,789。)
- 初始步骤:Kettle 在元数据里还记录了字段是由哪个步骤创建的。可以让你快速定位字段是由转换里的哪个步骤最后一次修改或创建。
当设计转换时有几个数据类型的规则需要注意:
- 行级里的所有行都应该有同样的数据结构。就是说:当从多个步骤向一个步骤里写数据时,多个步骤输出的数据行应该有相同的结构,即字段相同、字段数据类型相同、字段顺序相同。
- 字段元数据不会在转换中发生变化。就是说:字符串不会自动截去长度以适应指定的长度,浮点数也不会自动取整以适应指定的精度。这些功能必须通过一些指定的步骤来完成。
- 默认情况下,空字符串(“”)被认为与NULL相等。可以通过数KETTLE_EMPTY_STRING_DIFFERS_FROM_NULL参数设置空字符串和NULL是否相等
3.2 作业
一个作业包括一个或多个作业项,这些作业项以某种顺序来执行。作业执行顺序由作业项之间的跳 (job hop)和每个作业项的执行结果来决定。因为作业顺序执行作业项,所以必须定义一个起点。有一个叫“开始”的作业项就定义了这个起点。一个作业只能定义一个开始作业项。。
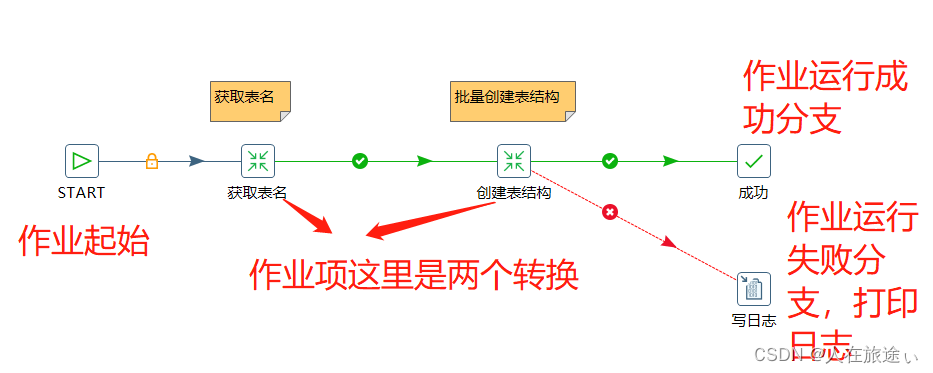
3.2.1 作业项
作业项是作业的基本构成部分。如同转换的步骤,作业项也可以使用图标的方式图形化展示。
- 在作业项之间可以传递一个结果对象(result object)。这个结果对象里包含了数据行它们不是以流的方式来传递的。而是等一个作业项执行完了,再传递给下一个作业项。
- 默认情况下,所有的作业项都是以串行方式执行的,只是在特殊的情况下,以并行方式执行。
3.2.2 作业跳
作业的跳是作业项之间的连接线,它定义了作业的执行路径。作业里每个作业项的不同运行结果决定了作业的不同执行路径。对作业项的运行结果的判断如下。
-
无条件执行:不论上一个作业项执行成功还是失败,下一个作业项都会执行。这是一种黑色的连接线,上面有一个锁的图标。 -
当运行结果为真时执行:当上一个作业项的执行结果为真时,执行下一个作业项。通常在需要无错误执行的情况下使用。这是一种绿色的连接线,上面有一个对钩号的图标。 -
当运行结果为假时执行:当上一个作业项的执行结果为假或没有成功执行时,执行下一个作业项。这是一种红色的连接线,上面有一个红色的停止图标。 点击跳的小图标的可以设置上面这几种判断方式
3.2.3 多路径和回溯
Ketle 使用一种回溯算法来执行作业里的所有作业项,而且作业项的运行结果(直或假)决定执行路径。回溯算法就是:假设执行到了图里的一条路径的某个节点时,要依次执行这个节点的所有子路径,直到没有再可以执行的子路径,就返回该节点的上一节点,再反复这个过程。
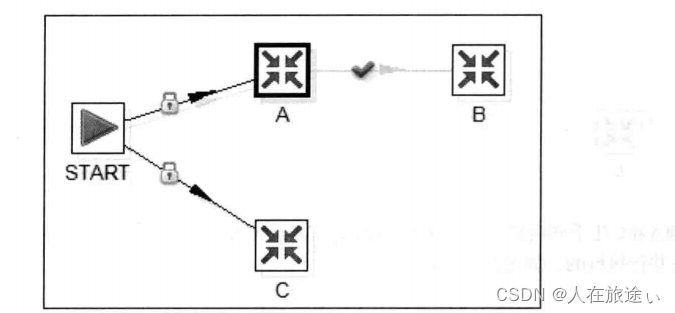
A、B、C三个作业项的执行顺序如下:
- 首先“开始”作业项搜索所有下一个节点作业项,找到了“A”和“C”
- 执行“A”
- 搜索“A”后面的作业项,发现了“B”
- 执行“B”
- 搜索“B”后面的作业项,没有找到任何作业项
- 到“A”,也没有发现其他作业项。
- 回到Start ,发现另一个要执行的作业项“C”
- 执行“C”
- 搜索“C”后面的作业项,没有找到任何作业项。
- 回到Start ,没有找到任何作业项。
- 作业结束
因为没有定义执行顺序,所以上面例子的执行顺序除了ABC,还可以有 CAB。这主要看hop跳的连接顺序。
3.2.4 并行执行
有时候需要将作业项并行执行。这种并行执行也是可以的。一个作业项可以并发的方式执行它后面的所有作业项。右击作业项选择Run Next Entries in Parallel就可以并发执行当前作业后边的作业项:如图:!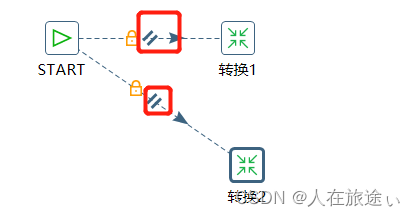
此时转换1和转换2就是并发执行。
3.2.5 作业项结果
作业执行结果不仅决定了作业的执行路径,而且还向下一个作业项传递了一个结果对象。
结果对象包括了下面一些信息。
- 一组数据行:在转换里使用“复制行到结果”步骤可以设置这组数据行。与之对应,使用“从结果获取行”步骤可以获取这组数据行。在一些作业项里,如“Shell脚本”“转换”、“作业”的设置里有一个选项可以循环这组数据行,这样可以通过参数化来控制转换和作业。
- 一组文件名:在作业项的执行过程中可以获得一些文件名(通过步骤的选项:“添加到结果文件”)。这组文件名是所有与作业项发生过交的文件的名称。例如,一个转换读取和处理了10个XML文件,这些文件名就会保留在结果对象里。使用转换里的“从结果获取文件”步骤可以获取到这些文件名,除了文件名还能获取到文件类型。“一般”类型是指所有的输入输出文件,“日志”类型是指Kettle日志文件。
- 读、写、输入、输出、更新、删除、拒绝的行数和转换里的错误数
- 脚本作业项的退出状态:根据脚本执行后的状态码,判断脚本的运行状态,再执行不同的作业流程。
3.3 转换或作业的原数据
转换和作业是Kettle的核心组成部分。它们可以用XML格式来表示,可以保存在资源库里,可以用Java API的形式来表示。它们的这些表示方式,都依赖于下面的这些元数据。
名字:转换或作业的名字,尽管名字不是必要的,但应该使用名字,不论是在一个ETL工程内还是在多个 ETL工程内,都应尽可能使用唯一的名字。这样在远程执行时或多个ETL工程共用一个资源库时都会有帮助。文件名: 转换或作业所在的文件名或URL。只有当转换或作业是以XML文件的形式存储时,才需要设置这个属性。当从资源库加载时,不必设置这个属性。目录:这个目录,是指在Kettle资源库里的目录,当转换或作业保存在资源库里时设置。当保存为XML文件时,不用设置。描述:这是一个可选属性,用来设置作业或转换的简短的描述信息。如果使用了资源库,这个描述属性会出现在资源库浏览窗口的文件列表中。扩展描述:也是一个可选属性,用来设置作业或转换的详细的描述信息。
3.4 数据库连接
Kettle 里的转换和作业使用数据库连接来连接到关系型数据库。Kettle数据库连接实际是数据库连接的描述:也就是建立实际连接需要的参数。实际连接只是在运行时才建立,定义一个Kettle的数据库连接并不真正打开一个到数据库的连接。由于不同数据库的行为并不相同,所以Kettle定义了许多数据库连接类型,包括通用的数据库连接类型
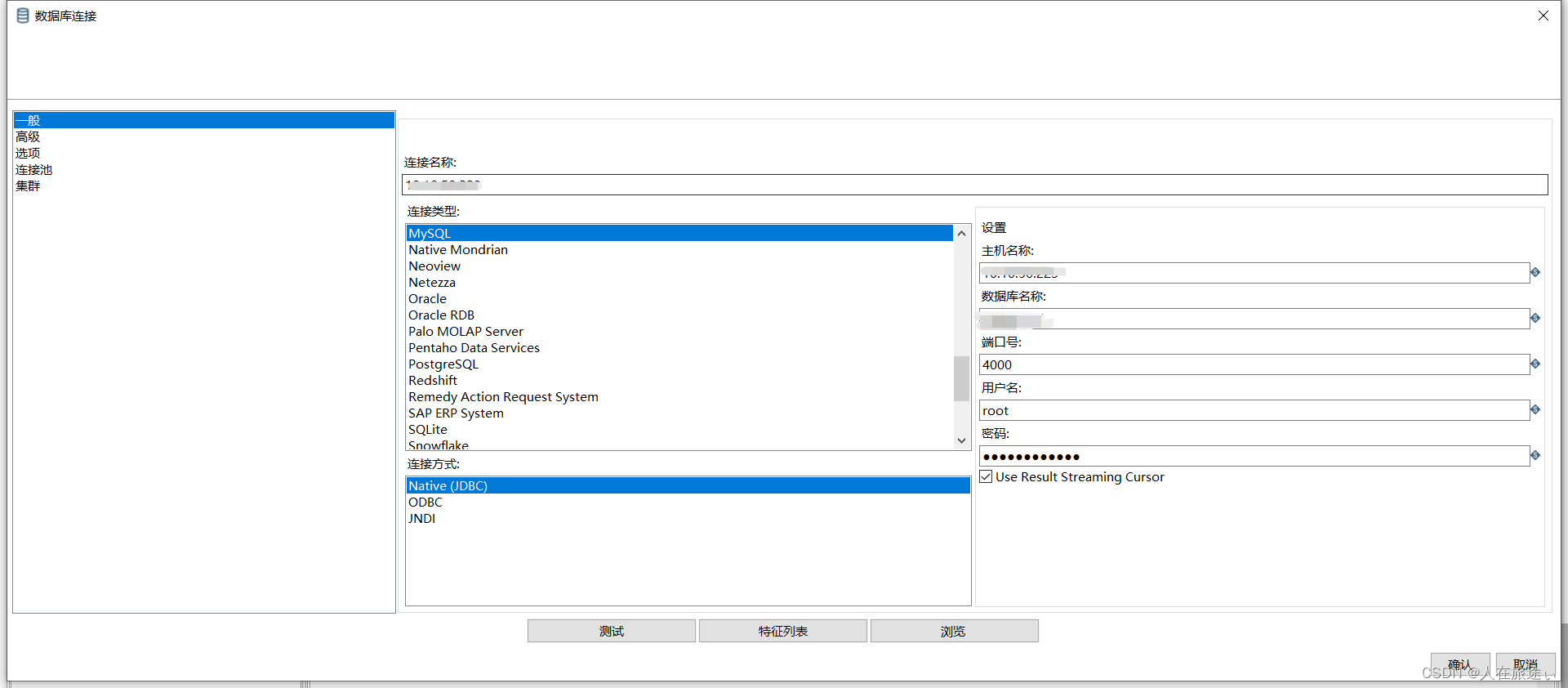
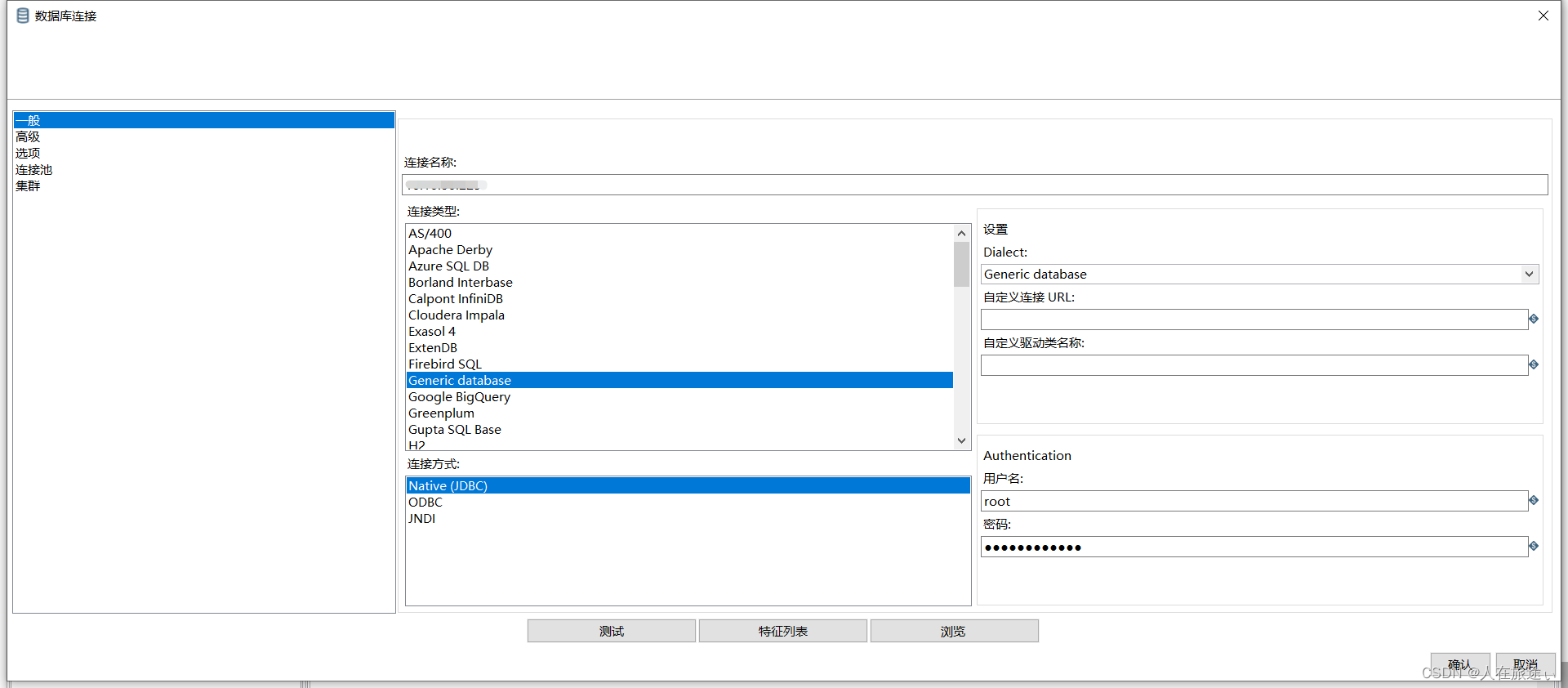
在数据库连接窗口中主要设置下面3个选项:
连接名称:设定一个在作业或转换范围内唯一的名称。连接类型:从数据库列表中选择要连接的数据库类型。根据选中数据库的类型不同,要设置的访问方式和连接参数设置也不同。某些Kettle步骤或作业项生成SOL 语句时使用的方言也不同。访问方式:在列表里可以选择可用的访问方式,一般都使用JDBC连接。不过也可以使用ODBC数据源、JNDI数据源、Oracle的OCI连接(使用Oracle 命名服务)。
根据选择的数据库不同,右侧面板的连接参数设置也不同。般常用的连接参数如下:
主机名:数据库服务器的主机名或IP地址数据库名:要访问的数据库名。端口号:默认是选中的数据库服务器的默认端口号。用户名和密码:数据库服务器的用户名和密码。
在左上角的高级选项中可以设置一些特定的配置(基本用不到),例如执行一些预处理SQL等。
除了这些高级选项,在连接对话框的“选项”标签下,还可以设置数据库特定的参数,如些连接参数。为便于使用,对于某些数据库(如MySOL),Kettle提供了一些默认的连接参数和值。各个数据库详细的参数列表,参考数据库JDBC 驱动手册。有几种数据库类型,Kettle 还提供了连接参数的帮助文档,通过单击“选项”标签中的“帮助”按钮可以打开对应数据库的帮助页面。
最后,还可以选择 Apache的通用数据库连接池的选项(不建议使用,有点问题)。
3.5 工具
Spoon:kettle图形设计工具(GUI),快速设计和维护复杂的ETL工作流。Pan:运行转换的命令行工具(.ktr结尾的文件)。Kitchen:运行作业的命令行工具(.kjb结尾的文件)。Carte:轻量级的Web服务器,用来远程执行转换和作业。一个运行有Carte进程的机器可以作为从服务器,从服务器是Carte集群的一部分(正式环境Kettle通常以Carte服务的方式启动)。
3.6 资源库
当你的ETL项目规模比较大,有很多ETL开发人员在一起工作,开发人员之间的合作就显得很重要。Kettle 以插件的方式灵活地定义不同种类的资源库,但不论是哪种资源库,它们的基本要素是相同的:这些资源库都使用相同的用户界面、存储相同的元数据。目前有3种常见资源库:数据库资源库、Pentaho资源库和文件资源库。
数据库资源库:数据库资源库是把所有的ETL信息保存在关系型数据库中,这种资源库比较容易创建,只要新建一个数据库连接即可。可以使用“数据库资源库”对话框来创建资源库里的表和索引。Pentaho资源库:Pentaho 资源库是一个插件,在Kettle的企业版中有这个插件。这种资源库实际是一个内容管理系统(CMS),它具备一个理想的资源库的所有特性,包括版本控制和依赖完整性检查。文件资源库:文件资源库是在一个文件目录下定义一个资源库。因为Kettle 使用的是虚拟文件系统(Apache VFS,所以这里的文件目录是一个广泛的概念,包括了zip文件、Web服务、FTP服务等。
文件资源库应该是最常用的资源库类型
3.7 虚拟文件系统
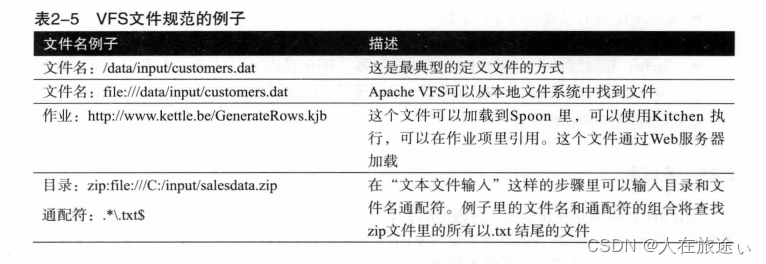
灵活而统一的文件处理方式对ETL工具来说非常重要。所以Kettle支持URL形式的文件名,Kettle 使用Apache的通用 VFS 作为文件处理接口,替你解决各种文件处理方面的复杂情况。例如,使用Apache VFS可以选中zip压缩包内的多个文件,和在一个本地目录下选择多个文件一样方便。关于VFS的更多信息,请访问 http://commons.apache.org/vfs/。
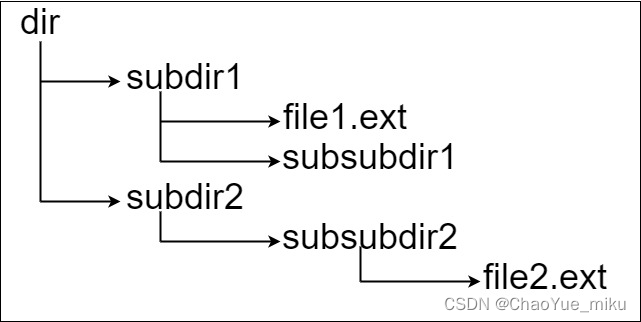
四、Kettle文件目录介绍
在https://sourceforge.net/projects/pentaho/files/上下载Kettle并解压到本地,解压后的目录如下:
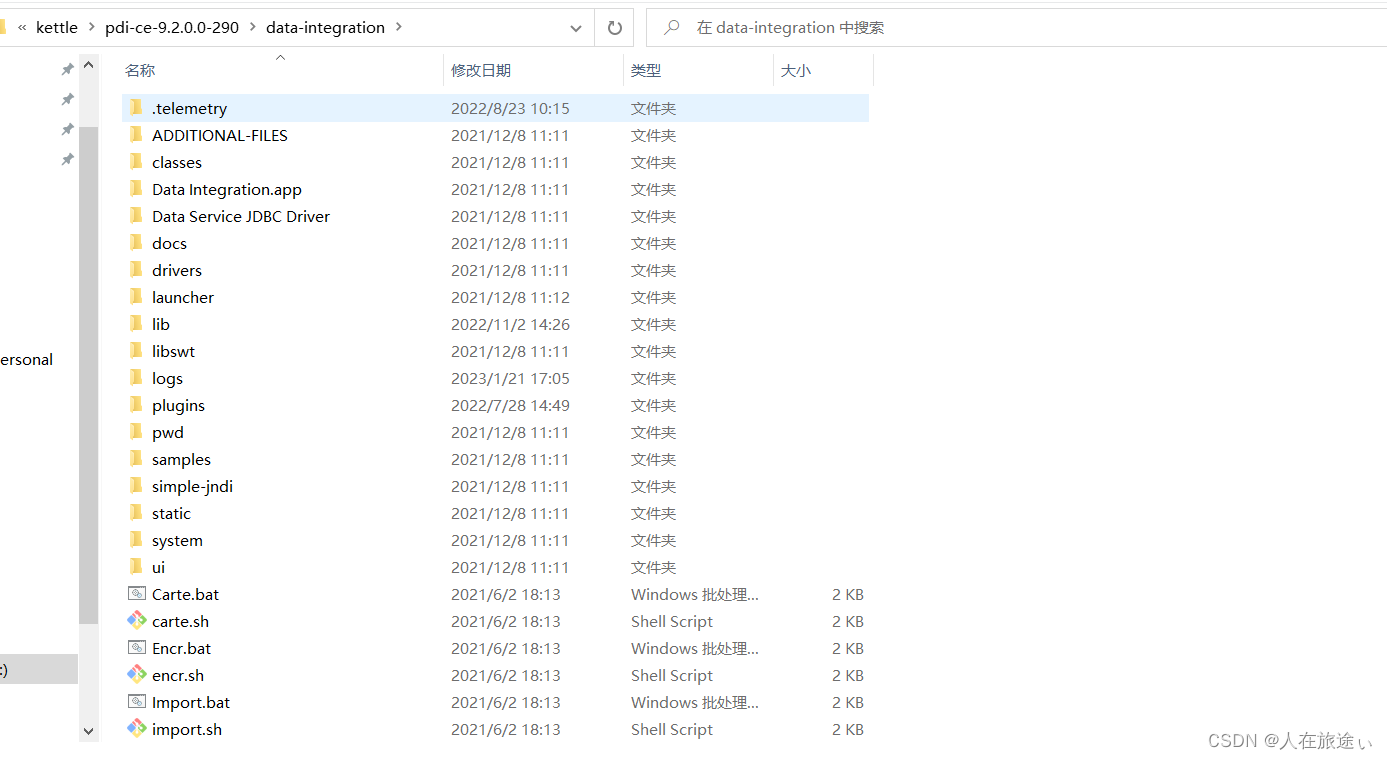
在当前data-integration目录下包含了许多的bat脚本以及sh脚本,bat即在windows上的执行脚本,sh即在Linux上的执行脚本,在3.5工具中介绍的四种工具在当前目录下都有其在Windows和Linux上的启动脚本。
4.2 Kettle文件目录介绍
classes目录:生命周期监听、注册表扩展、日志的配置文件Data Integration.app:数据集成应用Data Service JDBC Driver: JDBC驱动程序的数据服务docs:文档launcher:Kettle的启动配置log: Kettle的全局运行日志(通常我们会给每个作业或转换配置各自的日志)lib:支持库 jar包,需要使用到的第三方Jar包依赖(例如数据库驱动)就需要放在此目录下libswt:Kettle图形库jarplugins:Kettle插件pwd:kettle集群配置文件以Cater方式启动Kettle就需要执行pwd下的配置samples:自带例子simple-jndi:jndi连接配置system:系统目录ui:软件界面
其中lib、Plugins、pwd目录下的内容需要重点了解
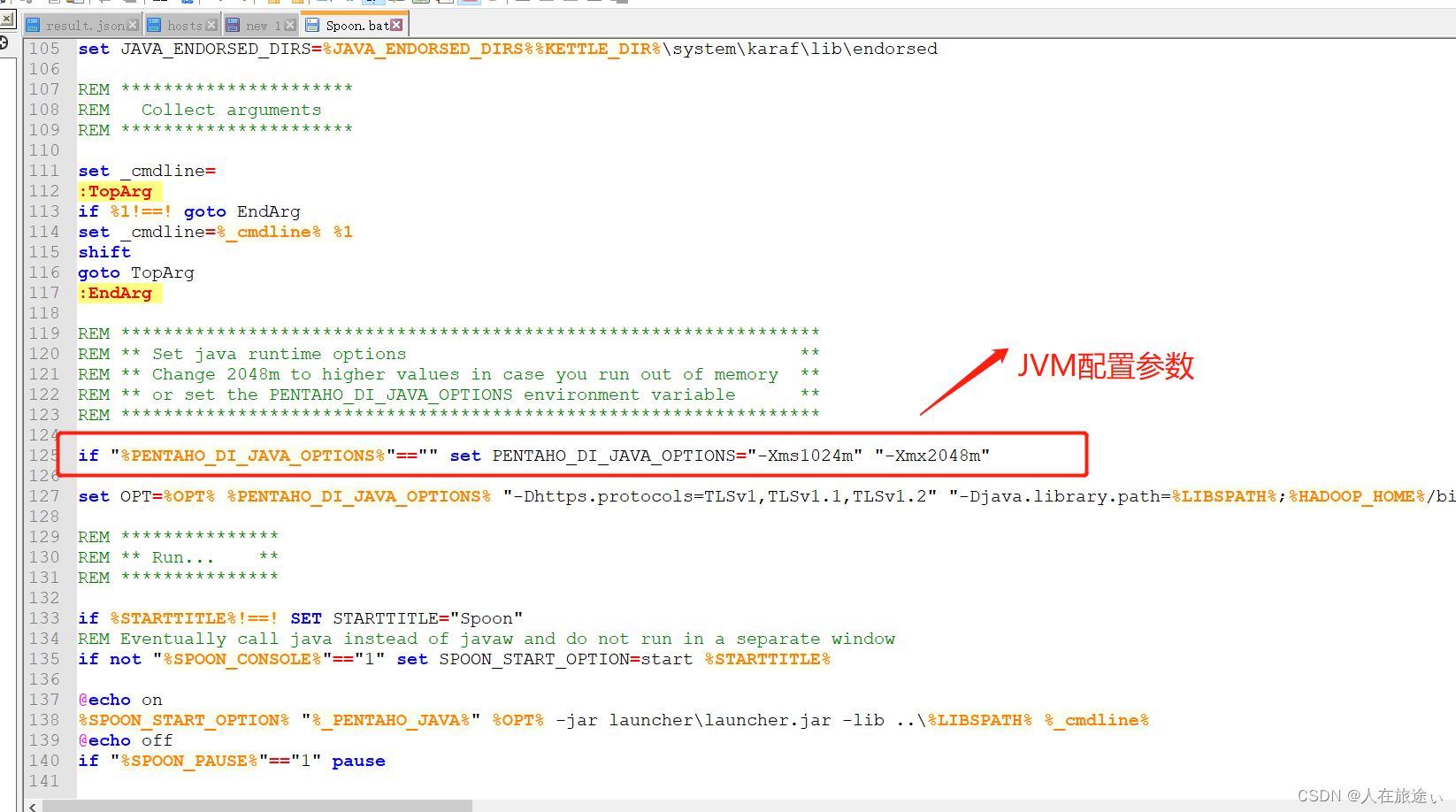
Spoon脚本是Kettle的启动脚本也是最重要的脚本,无论是Pan、Kitchen还是Carte最终都是通过调用Spoon脚本来启动,Spoon可以配置Kettle的启动参数以及JVM参数。