1) MySQL数据库相关错题本
1、存储引擎相关
1、MySql的存储引擎的不同
MySQL存储引擎主要有InnoDB, MyISAM, Memory, 这三个区别在于:
Memory是内存数据引擎, 会断电重启(在双M或者主从架构下会产生较多异常), 且不支持行级锁. 默认索引是数组索引, 支持B+索引
InnoDB和MyISAM的区别: 事务(日志), 索引(主键, 外键索引,文件组织结构), 锁级别,
事务处理方面:MyISAM强调的是性能,查询的速度比InnoDB更快,但是,不支持事务,InnoDB是支持事务的。
外键:InnoDB支持外键,MyISAM不支持。
锁:InnoDB支持行锁和表锁,默认会使用行锁,而MyISAM只是支持表锁。由于行锁是能更好的支持并发操作,因此,InnoDB更加适合插入和更新操作较多的情况,而MyISAM适用于频繁查询操作。
全文索引:MyISAM支持全文索引,InnoDB不支持。但是,在5.6版本开始InnoDB也开始支持全文索引。
表主键:MyISAM允许没有主键的表存在,而InnoDB如果不存在主键,会自动生成一个6字节的主键。
查询表的行数[count(*)]差异:InnoDB不保存表的函数信息,因此,select count(*)时会扫描整个表来进行计算;MyISAM内置了计数器,只需要简单的读取保存好的行数即可。
2 简单说一下存储引擎做了什么?
存储引擎主要负责的是数据的存储和提取.
3. InnoDB是否有hash索引
InnoDB没有Hash索引, MySQL的其他数据引擎,如Memory就支持Hash索引.
4.InnoDB使用delete删除一条数据后, 数据什么时候从硬盘上真正消失? 什么时候页合并
数据在删除后, 会产生标志位, 会形成数据空洞. 然后数据不会被删除,只会被覆盖. 如果一个页上所有的数据都被删除了, 那么整页将会被认为可重用, 不会被删除.
所以如果delete删除所有表数据, 数据文件的size不会变小.
-- TODO
5. InnoDB在没有主键时, 会帮我们创建主键, 这个主键我们可以作为查询条件吗?
不可以, 因为这个主键对用户不可见, 所以如果没有主键的话, 就无法使用主键索引了.
InnoDB建议我们自己建表时声明一个主键,如果没有会找到第一个非空唯一索引作为主键,如果没有才会自己生成一个6字节的主键,并且这个主键是由MySQL提供下一位主键的值, 多表会产生竞争, 总之InnoDB强烈建议一定要有自增的主键.
6. 一张有自增id的表,当数据记录到了20之后,删除了第18,19,20条记录,再把MySQL重启,再插入一条记录,这条记录的id是21还是18呢?
当表的引擎采用MyISAM时,是21,当表的引擎采用InnoDB时是18。
MyISAM引擎会把表自增主键的最大id记录到数据文件中,做了持久化,重启后也不会消失,而InnoDB是将自增主键的最大id记录在内存中,重启后,会丢失。
2 Mysql事务相关问题
1、事务的四个特性,并发事务可能出现的问题, 以及MySQL(InnoDB)具体落地的相关措施
ACID, 核心就是一致性, 它是通过MVCC解决脏读和不可重复读问题, 通过nextKeyLock中的行锁和间隙锁避免幻读,通过redoLog和MySQL的binLog来保证事务的可回滚.
PS: 丢失修改是由锁处理,幻读是通过next-key-lock来解决的.
2. 为什么批量插入建议使用手动提交事务
因为每条sql语句都是一个单独的事务, 而开启事务和提交事务都需要消耗资源, 使用手动提交, 可以大大减少开启和提交事务造成的损耗.
事务相关的代码:
start transaction;-- 开启事务
rollback;
commit;3. 为什么有很多公司不使用默认的RR级别, 而是用RC级别呢?(和行锁范围和MVCC有关)
3.1 MySQL默认RR隔离级别的原因
主要和MySQL主从复制相关,因为MySQL在主从复制过程中是通过binlog进行数据同步的,而MySQL早期只有statement这种binlog格式,这种格式下,binlog记录的是SQL语句的原文。事务之间可能存在强制的前后关系, 但是原语无法完美回放,这就会导致备库在进行SQL回放之后,结果和主库不一致。
为了解决这个问题,MySQL采用了RR这种隔离级别,因为在RR中,会在更新数据的时候增加记录锁的同时增加间隙锁,可以避免事务乱序的情况发生。
后续版本中提供了row 和mix的binlog格式, 如果需要修改隔离级别为RC, 需要把statement改为row格式.
3.2 为什么大厂要将隔离级别修改成RC?
3.2.1 与MVCC的开启有关
在RC中,每次读取都会重新生成一个快照,不使用MVCC, 总是读取行的最新版本。
在RR中,使用MVCC, 快照会在事务中第一次查询语句执行时生成,是看不到其它事务所提交的更改。
在RC级别中,支持半一致读,一条update语句,如果where条件匹配到的记录已经加锁,那么InnoDB会返回记录最近提交的版本,由MySQL上层判断此是否真的需要加锁。
3.2.2 与间隙锁有关
在RC中,只会对索引增加行锁,不会添加另外两种锁。
在RR中,为了解决幻读问题,三种锁都支持。
3.2.3 与主从同步有关
MySQL的binlog主要支持三种格式,分别是statement、row和mixed。
在RC中,只支持row格式的binlog。如果指定了mixed作为binlog格式,那么如果使用RC,服务器会自动使用基于row格式的日志记录。
在RR中,可以同时支持三种格式的binlog。
3.2.4 为什么选择RC?
大厂之所以使用RC,主要原因有二,其一是提升并发,其二是减少死锁。
为什么RC要比RR并发度好?
因为RC在加锁过程中,是不需要添加Gap Lock和Next-Key Lock的,只需要对要修改的记录添加行级锁就行了。另外,RC还支持半一致读,可以大大的减少了更新语句时行锁的冲突。对于不满足更新条件的记录,可以提前释放锁,提升并发度。
为什么RC可以减少死锁发生?
因为RR会增加Gap Lock和Next-Key Lock,这就使得锁的粒度变大了,那么就容易导致死锁的概率增大(占地太宽了,别人占不到地方了)。
4. 为什么redoLog+binLog才能回滚事务, 一个binLog不可以吗? 为什么?
4.1 redo Log和binLog的区别:
redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
redo log 是物理日志,记录的是“在某个数据页上做了什么修改,实现 crash-safe,即使数据库发生异常重启,之前提交的记录都不会丢失。而 binlog 是逻辑日志,记录的是写入性操作(不包括查询)信息,比如“给 ID=5 这一行的 c 字段加 1 ”,保证数据的一致性。
redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
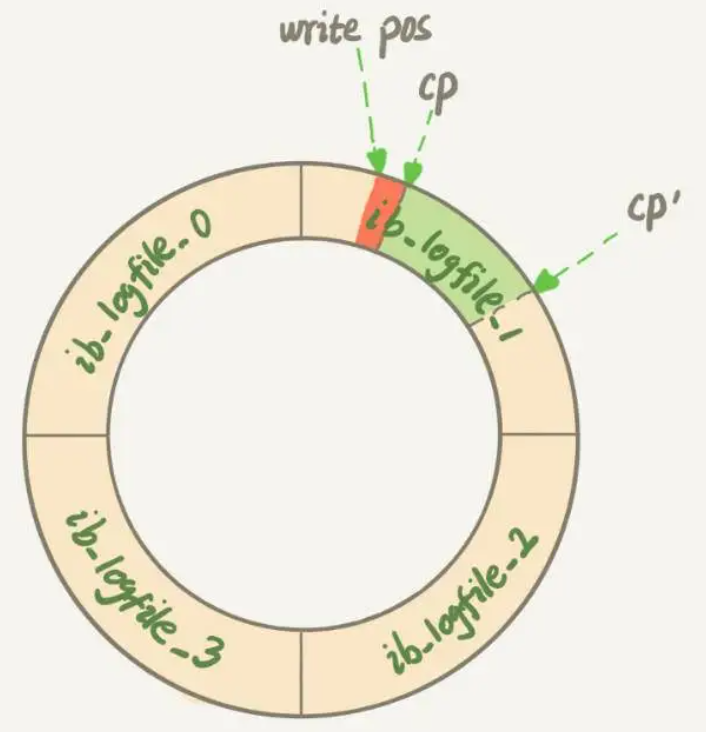
binlog 仅在事务提交时记录,并且对于每一个事务,仅包含对应事务的一个日志。而对于 redo log,由于其记录的是物理操作日志,因此每个事务对应多个日志条目。
4.2 两阶段提交
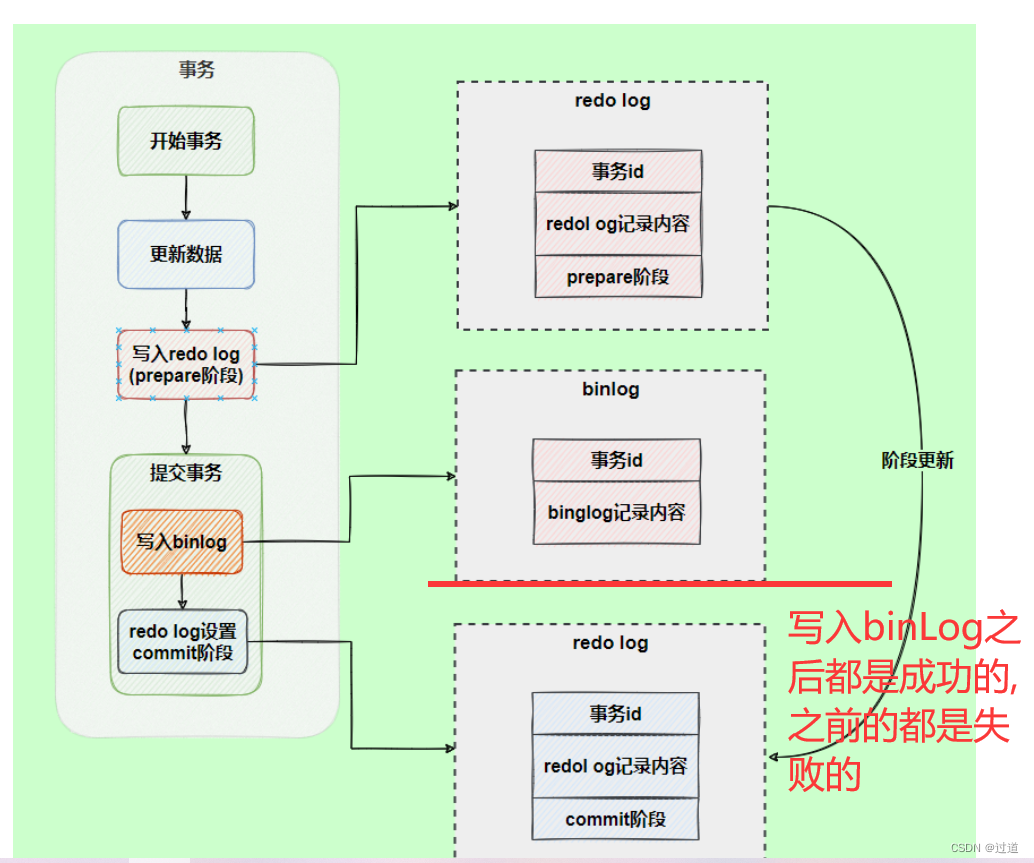
4.3 为什么需要redoLog才能做到crash-safe.
由于 binlog 记录的是写入性操作,如果想用 binlog 来恢复数据,我们必须知道现在得从哪里开始,因为一条语句多执行几次会带来数据上的错误。但是 binlog 虽然保存了所有的历史操作,但是它没有标识每条操作是否已经写入磁盘,所以我们确定从哪开始。
而 redo log 记录的是数据页的更改,并且刷盘完成的数据会从 redo log 中删除。
5. innodb里,为什么不采用MyISAM的count(*)的计数方案?
因为InnoDB支持事务, 需要在事务中手动更新count的值。 不能再采用同一变量的方案了。
3. 查询优化相关问题
1.创建索引, 查看索引,删除索引的语句
创建索引一共有三种方案, 一种是建表时, 一种是修改表结构(以索引为主,以表结构为主).
# 主键索引, 索引 CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX [indexName] (username(length)) );
# 修改表结构 ALTER TABLE table_name ADD INDEX index_name(column_name);
# 创建index在表上. CREATE INDEX index_name ON table_name (column_name)
查看索引
SHOW INDEX FROM [表名] FROM [库名]
删除索引
DROP INDEX [索引名] ON [表名]
ALTER TABLE [表名] DROP (INDEX index_name)/(PRIMARY KEY)/(FOREIGN KEY fk_name);
2. 对于逻辑上保证唯一的列, 唯一索引和普通索引,如何选择.
选择普通索引, 因为唯一索引会使ChangeBuffer优化无效. ChangeBuffer 能合并对磁盘的操作, 从而减少IO消耗.
但是阿里的规范里推荐使用唯一索引, 因为'逻辑上保证唯一'这一点往往无法实现, 使用唯一索引可以避免污染数据, 在重复问题产生时就可以发现而不是等到之后.
3. 字符串不加引号会使索引失效吗? 为什么
因为发生了隐式转化, 相当于Java调用了toString函数, 调用了函数所以无法使用索引.
4.where a = 1 or b =2如果a有索引, b没有, 会使索引失效吗?
会使索引失效. 因为就算a使用了索引, b依然会触发全表扫描, 那么使用a索引就显得多此一举. 如果b有索引,那么就会Using sort union(a_idx,b_idx)
5. 在一个大表上, 这个表只有四个字段(id, username, password, status); sql如下, 如何优化?
SELECT id, username , password FROM user WHERE username='abcd';建立username前缀索引.
6. 说一下索引的设计原则, 不少于四条
选择性越大越好, 低于0.2的建议不建立索引.
读操作比例越大的越适合建立索引
一般一个表不建议建5个索引以上
组合索引的建立原则: 能够尽可能的用上索引覆盖的顺序建立组合索引
在小表上不建议建立索引, 因为mysql可能会认为全表扫描代价更大, 从而全表扫描,浪费空间.
**7. 简单说一下你知道的主键的设计原则 **
主键最好是不要用uuid这种只保证唯一而不保证有序的列作为主键, 会产生较多的页分裂.
一般建议使用自增索引, 或者业务能保证递增,唯一的列.
分布式情况下, 可以使用推特的雪花算法或者美团的leaf算法.
8. 如果需要建立一个组合索引, a 列升序,B 列降序, 语法应该怎么写?
ALTER TABLE ADD INDEX a_asc_b_des (a asc, b dec);
9. 说一下 Using filesort 和 Using index 的区别.
fileSort重点不是file,而是调用了排序算法, 如果需要排序的内容比较多, MySQL内存可能不够用的话,那么会把中间结果存到临时表里, 这种排序操作会很浪费内存和CPU资源, 所以一般建议使用索引的有序性来解决.
10. limit语句如何优化? sql如下
select * from user order by user_id limit 60000,10 ;(100w数据耗时 0.19s)
# 首先分析下, 拖慢性能的原因是因为limit 需要跳过前2000000条, 所以就需要先便利前面的数据
# 1. limit要求需要按照索引顺序从前往后扫描60000行, 所以比较慢
# 2. select * 和 select 某一列,主要的区别在于MySQL的内存在读一列或几列时, 能够读取更多的数据, select * 会扫描所有数据, 所以会读磁盘更多次.
# 3. select 非索引和selct 索引的区别在于"索引覆盖"
所以第一步先只使用id定位到目标第一行,然后再让id > 目标id, limit 10即可
select * from choice where choice_id>=(select choice_id from choice limit 60000,1) limit 10;(100w数据耗时 0.02s)11. count(*), count(id),count(column(not null)),count(column),count(1),count(100)的区别
count本质上就是取括号里的内容,然后判断是否为null.
所以如果列数越好, 并且没有null的可能, 那么一定是最快的. 按照这个结论可以排序如下:
count(column) < count(*) < count(column(not null)) ≈ count(id) < count(1) = count(100)
然后 MySQL在这里做了一个优化: count(*) 优化为count(1).
12. 为什么建议每列都有默认值,最好是加上not null约束
NULL列需要行中的额外空间来记录它们的值是否为NULL。每个NULL列需要额外一位,向上舍入到最近的字节。

3. SQL性能分析, 你怎么去做?
慢查询日志, mysql 会将执行时间大于某一个阈值的sql记录到慢查询日志里面.
profile, 通过'SET profiling = 1'开启 profile分析,通过命令查看所有操作花费的时间:show profiles;;通过上一步得到的Query_id,查询指定Query_id的SQL语句的各个阶段花费的时间: show profile for query query_id;
explain, 分析sql执行具体情况.
4. 如何查看慢查询日志?
启用慢查询日志配置: set global slow_query_log=’ON’; 可以更新long_query_time的值, 如默认为10.000, 那么大于10s的会被记录
设置打印格式: set global log_output=’FILE’;
插入执行时间大于我们设定的值的慢查询sql : select * from mysql.slow_log;
5. limit 语句如何优化?
回表查询优化分页,
# 原sql:
select id, name from tableName limit 1000,10
# 优化sql:
# 主要通过利用普通索引加速全表扫描来进行优化, (回表IO相对于全表扫描可以忽略不记)
select g1.id, g1,name inner join (select id from tableName order by column limit 1000,10) t1 on g1.id=t1.id;
select id, name from tableName where id in (select id from tableName order by column limit 1000,10);
# inner join和in的区别.
# 主要就是inner join, MySQL更会优化一些, 一般建议用Inner join, 只有少数特殊情况, 如子集中的个数有限且较少时.6. order by是如何排序的, 如何优化
全字段排序, 就是直接全表扫描所有需要返回的字段.
如果一行的全字段长度大于max_length_for_sort_data, 会使用row_id排序, 就是只让order By的条件列参与排序,这样好处就是减少对sort_buffer大小的依赖, 坏处就是增加了回表次数
使用索引, 直接有序, 然后回表
使用组合索引, 产生索引覆盖, 来解决索引产生的回表问题,.
优化:
排序的字段增加索引(类似从sort()变成TreeList.)
增大 sort buffer 的大小 ,
不要用 * 作为查询列表,只返回需要的列, 尽可能减少参与sort的列, 以及之后使用索引的话, 尽可能使用索引覆盖.
7. order by 列, 这一列有索引就一定会用吗?
不会, 因为MySQL可能认为回表代价太大, 一般来说我们都是通过limit一个较小值, 这样回表代价较小, InnoDB就更可能走索引,
8. count(*) 在innodb 中有哪些优化.
建议自己使用变量计数, 因为innodb计数需要进行全表扫描, 不想myisam有一个变量记录, 主要原因就是innodb支持了事务, 而因为同一时刻可能有多条事务未提交或已提交, 所以InnoDB认为有必要重新计数.
解决方案也很简单, 就是自己在数据库里维护一个变量, 这样这个变量也会通过MVCC维护历史版本, 每次count(*)的时候,就会利用MVCC的机制来得到正确的count值.
当然InnoDB对count(*)还有一格优化, 就是尽可能使用普通索引树, 这是因为非主键索引的叶子节点更少, 能通过更少的磁盘IO得到结果.
此外, count(*)≈count(1)>count(主键) > count(普通索引) > count(字段), OceanBase 推荐使用count(*)进行计数
9. 建立索引的原则
最左前缀匹配原则,MySQL会遇到范围查询停止匹配,所以会导致组合索引失效。
索引列不进行函数运算。
注意一个表建立索引的数量,不是索引建的越多越好,维护索引也会有很大的开销。
尽量选择区分度高的字段作为索引。
where语句中,经常使用的字段应该考虑建立索引。
分组和排序语句中,经常使用的字段应该考虑建立索引。
两个表关联字段考虑建立索引。
like模糊查询中,只有右模糊查询才会使用索引。
在varchar 字段上建立索引时,必须指定索引长度。
禁止建立超过3个字段的联合索引。
尽量采用覆盖索引,避免回表查询。
索引优化的目标:至少要达到range级别,要求是ref级别,如果可以是consts最好。
索引失效的情况
使用组合索引,没有满足最左匹配原则,导致失效。
or语句所有字段必须都有索引,否则失效。
like以%开头,索引失效。
需要类型转换。
where中索引列有运算。
where中索引列使用了函数。
如果mysql觉得全表扫描更快时(数据少)。
身份证建立索引的话, 如何存储读取最快呢?,
倒排取前六位即可
4. Mysql锁的问题
1、MySQL的锁级别都有哪些?
全表锁->备份用, 只读, 在主从时很危险.
表级锁->元数据锁, 表锁.
0行级锁->行锁, 间隙锁, nextKeyLock.
2. Mysql有那些锁? 作用场景是什么? 为什么?
意向锁在保证并发性的前提下,实现了行锁和表锁共存且满足事务隔离性的要求.
因为如果需要加表排他锁, 就需要保证本表中不存在任何行锁.
需要加表共享锁的话, 需要保证本表中只存在行共享锁. 我们不可能在加表锁前逐行判断, 所以有意向锁这个东西, 主要是为了保证加表锁之前能够快速判断是否有行锁存在.
3. next-key lock算法是怎么避免幻读问题的.
通过间隙锁, 锁住行之间的间隙,能够阻塞其他插入数据的事务, 从而规避掉多次读取产生的数据增加问题.
4. InnoDB什么时候是行锁?
有索引, 并且sql语句的筛选条件是索引, 那么会用到行锁,.
比如: WHERE id = 1;
5. 说说悲观锁和乐观锁
悲观锁是指在数据处理过程中,从一开始就使数据处于锁定状态,直到更改完成才释放。
MySQL中悲观锁使用以下方式:select...for update
例如:
select name from item where id = 200 for update;
insert into orders(id,item_id) values(null,100)
update item set count = count - 1 where id = 100;我们使用select name from item where id = 200 for update;对id为200的数据进行了锁定,其他要对该条数据进行修改,必须等到该事务提交之后,否则无法修改。这样就保证了并发的安全性。
需要注意的是:select...for update语句必须在事务中使用。
悲观锁虽然能够解决并发安全的问题,但是,这种锁定会导致性能降低,加锁时间过长,并发性不好,影响系统的整体性能。因此,这种方式在实际的开发中用的很少。
乐观锁是相对悲观锁而言的,认为数据一般情况下不会出现冲突,所以在数据进行更新的时候,才会将数据锁定。
乐观锁的实现方式
使用数据版本(version)机制实现
该方式是在每次更新数据的时候,都要对更新的数据进行version版本+1操作。
其具体原理是:读取数据时,将此版本一同读出,之后,更新数据时,对此版本+1,每次提交数据时,如果提交的数据版本大于或等于数据库表中的版本,则可以更新,说明是最新数据,否则,不予更新,说明数据已经过期。
使用时间戳实现
该机制和version是类似的,也是需要再表中增加一个字段,类型使用时间类型即可。
原理:在更新数据时,检查数据库中当前的时间戳和更新前取到的时间戳,如果对比一致,就予以更新,否则不更新。
悲观锁可以在并发量不大的情况下使用,并发量大的情况下,使用乐观锁,大多数情况下都建议使用乐观锁。
6. InnoDB 行锁锁住了谁?
InnoDB的行锁,就是通过锁住索引来实现的 // TODO
5. MySQL 体系常见问题.
1. MySQL体系结构, 简述一下
连接器 : 对接JDBC. navicat等连接. 在这里登陆后就授权, 此次授权不可被踢下.
分析器 : 词法分析,语法分析生成sql语法树, 负责编译sql,
优化器 : 执行计划生成,选择索引. 优化器选择多种方案中较优的一种.
执行器 : 判断权限,调用存储引擎.
存储引擎: 提供读写接口 说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。
2. 为啥缓存被弃用?
MySQL的缓存不适应多核环境, 因为在多核机器上,大量查询会导致大量的互斥锁争用.
3. 判断是否有查询权限, 在那一层判断的.
执行器上判断连接器获得的权限是否可以执行sql.
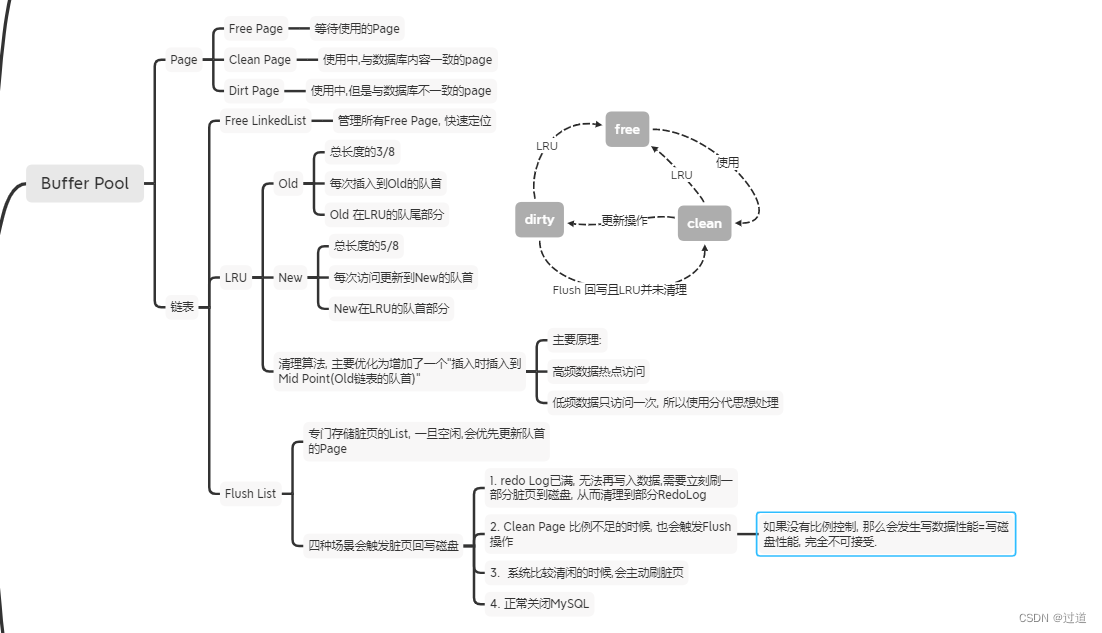
4. Buffer Pool中的Page有哪些状态? 有哪些链表?分别有什么作用?
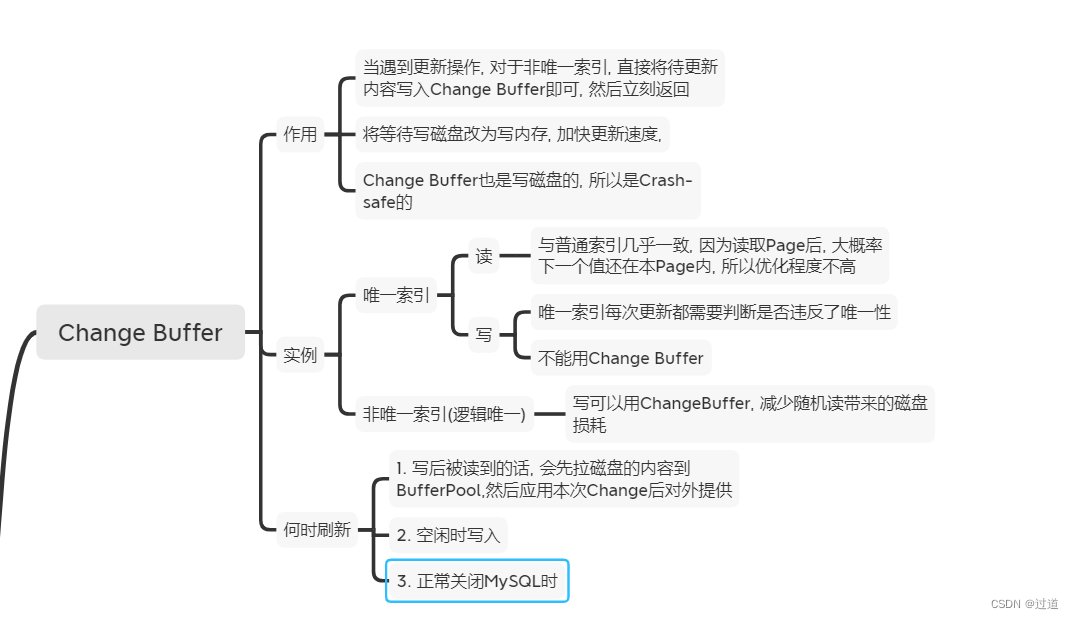
5. Change Buffer的意义是什么?
ChangeBuffer有效的减少随机读的代价.
redoLog减少随机写的代价.
6. MVCC和ReadView介绍一下.
MVCC全称:Multi-Version Concurrency Control , 多版本并发控制. 当事务开启的时候, 会生成时间戳, 对于其读所需要访问的列, 主要起到逻辑全表备份的作用, 从而减少加锁带来的开销. 主要作用于RC级别和RR级别, 在RU和S级别用不到,因为RU不加锁, S级别对所有读到的数据都加锁.
ReadView是事务在快照读的时候生成的一致性快照. 当事务执行快照读的那一刻,会生成一份当前数据库的快照. 他由当前未提交的事务id数组和已创建的最大事务id组成, 查询的数据结果需要跟read view 做对比得到结果.
7. 存储过程少用? 为什么
用sql写逻辑业务, 对程序员要求较高; 一旦出现问题,调试起来比较困难;一旦需求变更/扩展, sql更改困难.
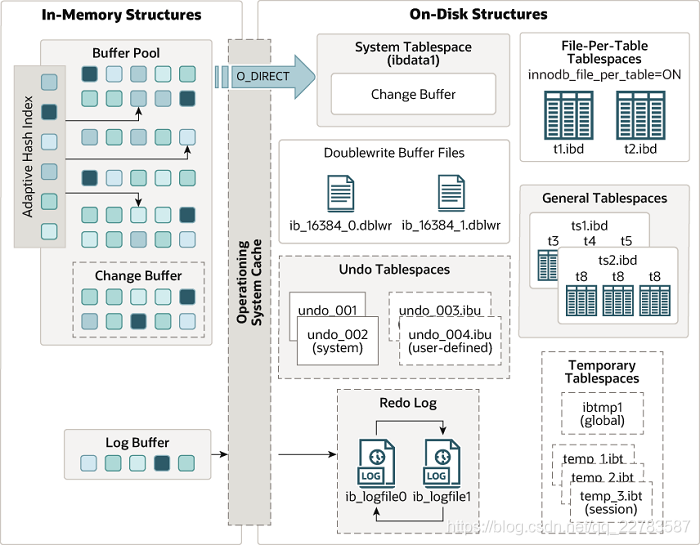
8. Mysql的 磁盘架构
9. 空洞是什么? 有哪些操作会造成空洞。
空洞即没有值的数据槽. 比如一行数据被删除后就会产生一条空洞; 删除数据, 新增和更新都可能产生页分裂, 页分裂也会产生空洞.
空洞对应用层最大的影响应该就是删除表数据,但idb文件大小不会缩减, 即使你删除表大部分数据, 也不会减小文件占用大小, 这种情况一般需要使用turncate或者重建表结构..
10. truncate和delete有什么区别?
truncate table:删除内容、不删除定义、释放空间
delete table:删除内容、不删除定义、不释放空间
drop table:删除内容、删除定义、释放空间
具体来说,有以下区别:
truncate table 只能删除表中全部数据,delete from 可以删除表中的全部数据也可以部分删除。
delete from记录是一条条删除的,删除的每一行记录都会进日志,而truncate一次性删除整个页,日志只会记录页的释放。
truncate删除后不能回滚,delete则可以。
truncate的删除速度比delete快。
delete删除后,删除的数据占用的存储空间还存在,可以恢复数据;truncate则空间不存在,同时不能恢复数据。
总的来说,其差别在于,truncate删除是不可恢复的,同时空间也不存在,不支持回滚,而delete删除正好相反。
分表之后想让一个id多个表是自增的,效率实现
使用单独的数据库或者使用Redis来生成, 前者有性能瓶颈, 后者引入了其他中间件. 还有一些常规的解决方案如Twitter的雪花算法和美团的叶子分布式算法.
group by 如何禁止排序.
Mysql怎么分表,以及分表后如果想按条件分页查询怎么办(如果不是按分表字段来查询的话,几乎效率低下,无解)
MySql的主从实时备份同步的配置,以及原理(从库读主库的binlog),读写分离
"You have an error in your SQL syntax" 是在那一层报出的.
分析器, 语法编译时报错
6. 基础语法问题
1. EXISTS关键词的使用方法
EXISTS表示是否存在,使用EXISTS时,如果内存查询语句查询到符合条件的值,就返回一个true,否则,将返回false。
例如:
SELECT * FROM user
where EXISTS
(SELECT name FROM employee WHERE id=100)如果employee表中存在id为100的员工,内层查询就会返回一个true,外层查询接收到true后,开始查询user表中的数据,因为where没有设置其他查询条件,所以,将查询出user的全部数据。
2. 内连接(inner join)和外连接的区别?
内连接:只会查询出两表连接符合条件的记录。
SELECT * FROM user1 u1 INNER JOIN user2 u2 ON u1.id = u2.id;如上sql所示,只会查询到user1和user2关联符合条件的记录。
外连接分为左外连接、右外连接和全外连接。
左外连接
它的原理是:以左表为基准,去右表匹配数据,找不到匹配的用NULL补齐。其显示左表的全部记录和右表符合连接条件的记录。
右外连接
它的原理是:以右表为基准,去左表匹配数据,找不到匹配的用NULL补齐。其显示右表的全部记录和左表符合连接条件的记录。这正好与左外连接相反。
全外连接
除了显示符合连接条件的记录之外,两个表的其他数据也会显示出来。
inner join 和 left join性能谁优谁劣?
外查询是在内查询的基础上,进而进行查询操作的。因此,我们从理论上可以得出,内连接的执行效率是更好一些的。
但是,外连接也是会进行优化操作的,在编译优化阶段,如果左连接的结果和内连接一样,左连接查询会转换成内连接查询,但这也表明编译优化器也认为内连接的效率是更高的。
虽然从查询的结果来看一般不会有太大的区别,但是,如果左右表之间的数据差别很大,内连接的效率是明显更高的,因为左连接以左表为基准,并且会进行回表操作。
最后,给出一个结论:在外连接和内连接都可以实现需求时,建议使用内连接进行操作。
3. 存储过程是什么,优势是什么,为什么不建议使用?
存储过程:为了完成特定功能的SQL语句集,存储在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。在数据量特别庞大的情况下利用存储过程能达到倍速的效率提升。
优势
存储过程是预编译的,因此执行速度较快;
存储过程在服务端执行,减少客户端的压力;
减少网络流量,客户端只需要传递存储过程名称和参数即可进行调用,减少了传输的数据量;
一次编写,任意次执行,复用的思想简单便捷;
安全性较高,因为在服务端执行,管理员可以对存储过程进行权限限制,能够避免非法的访问,保证数据的安全性。
缺点
调试麻烦,可移植性查。
这一个缺点也是存储过程在实际开发中用的不多的原因,现在开发的理念是简便。
4. sql语句应该考虑哪些安全性
防止sql注入,对sql语句尽量进行过滤同时使用预编译的sql语句绑定变量
查询错误信息不要返回给用户,将错误记录到日志
最小用户权限设置,最好不要使用root用户连接数据库
定期做数据备份,避免数据丢失
27. 视图中允许存在函数或者分组吗?
不允许.
28.视图有哪些作用
1.使用简单,
2.数据安全,不被授权的不会被修改,
3,逻辑数据独立(屏蔽真实表结构变化)
mysql用的是TCP还是UDP
TCP和Socket(前者是跨机器, 后者是统一机器内交互)
其他问题
阿里一面:查询操作方法需要使用事务吗
在RR级别, 需要开事务, read-only的事务.
1. 两阶段锁协议是什么? 什么是两阶段提交呢? 这两者区别是啥?
两阶段锁是指所有的事务必须分两个阶段对数据项加锁和解锁;
两阶段提交的经典实例就是redoLog个binLog, 他也是保证数据强一制的算法.
2. WAL技术是啥?
WAL(Write Ahead Log)预写日志,是数据库系统中常见的一种手段,用于保证数据操作的原子性和持久性; 在使用 WAL 的系统中,所有的修改在提交之前都要先写入 log 文件中。
比如, 写数据表之前, 会先写入binLog, 然后binLog执行






![[Android]Shape Drawable](https://img-blog.csdnimg.cn/f4b2bbd2aa4d45d6b0a21575b8bdb9b1.png)