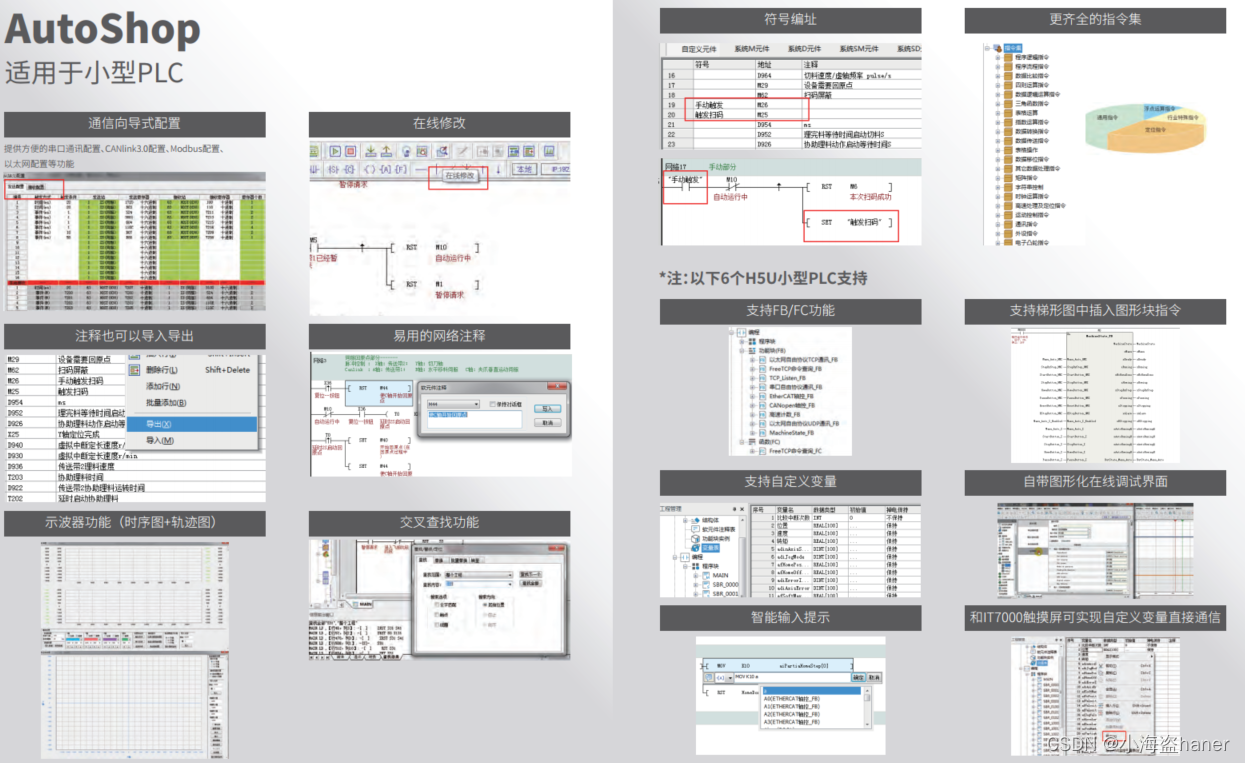
系列文章目录
这是本周期内系列打卡文章的所有文章的目录
- 《Go 并发数据结构和算法实践》学习笔记 Day 1_jahentao的博客-CSDN博客
文章目录
- 系列文章目录
- 前言
- 一、Skiplist是什么?(What)
- Skiplist的基本接口
- 查找元素
- 插入元素
- 删除元素
- 二、并行化改造
- 1.并发查找
- 2.并发删除
- 总结
- 参考
前言
提示:这里可以添加本文要记录的大概内容:
提示:以下是本篇文章正文内容,下面案例可供参考
一、Skiplist是什么?(What)
Skiplist 出现自1989年,由美国计算机科学家 William Pugh 发明的,最早出现在他 1990 年发表的论文《Skip Lists: A Probabilistic Alternative to Balanced Trees》1,俗称“跳表”。典型使用:用来加速链表的查找。复杂度介于常见的查找数据结构:数组、平衡树。
跳表名字的由来,指除了最下层原始链表外,它会产生多层冗余、稀疏的链表。
可以看极客时间视频介绍2快速入门。
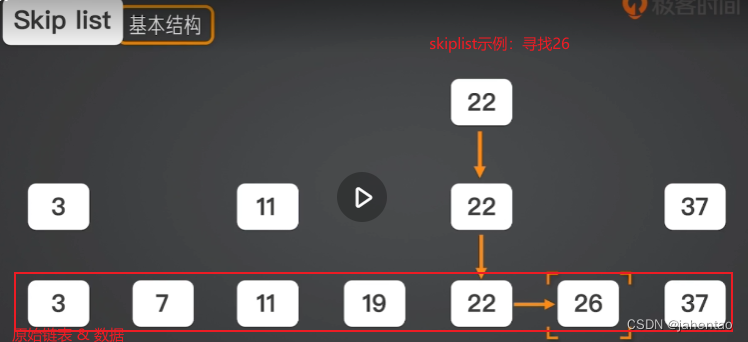
跳表是在已有链表的结构上,增加上层索引节点链表,不改变原有的数据结构。在查找场景,数据量很大的情况下,上层链表查找能够跳过大量节点,极大加快查找速度。上述过程类似二分查找,时间复杂度可以降低到O(lnN) (复杂度经过时间证明)。
我们遇到某种业务场景,先是get到功能:如查找。然后就要往经典数据结构上套,能否改造现有数据结构。
Skiplist的基本接口
Skiplist的基本接口,原始文献中已经列出,后续文献有所补充3。我们先从简单的开始:
- search,
- insertion,
- deletion
查找元素
步骤:
插入元素
Skiplist的插入(或者说Skiplist的构造),采用随机层数插入。插入节点,不需要对其他节点的层数进行调整,使得Skiplist的插入性能大大优于传统的平衡二叉树。
步骤:
删除元素
步骤:
二、并行化改造
1.并发查找
2.并发删除
总结
提示:这里对文章进行总结:
跳表对比其他查找数据结构:
| 对比项 | 跳表 | 数组 | 平衡二叉树 |
|---|---|---|---|
| 插入特点 | |||
| 查找 | |||
| 查找时间复杂度 |
参考
William Pugh, Skip Lists: A Probabilistic Alternative to Balanced Trees, Proceedings of the Workshop on Algorithms and Data Structures, Ottawa Canada, August 1989 (to appear in Comm. ACM). ↩︎
一文带你熟悉跳表 ↩︎
A Skip List Cookbook ↩︎